B+树在磁盘存储中的应用
欢迎探讨,如有错误敬请指正
如需转载,请注明出处 http://www.cnblogs.com/nullzx/
我们首先提一个问题, B+树比平衡二叉树在索引数据方面要快么?
大多数人可能认为肯定还是B+树快,毕竟存储同样多的数据,100阶的B+树肯定比平衡二叉树的高度要低的多。但是别忘了B树在一个结点可能需要比较很多次才能找到下一层的结点,但是平衡二叉树只要比较一次就可以向下走一层。所以综合起来,其实两者索引的速度几乎(甚至说就是)是一样的。最简单的道理,一颗4阶B树就是一颗红黑树,比较的次数完全一样(如果不明白这个道理,请参考我关于红黑树的三篇技术博客)。那么我们为什么还要使用B+树呢?这是因为上面说索引速度相当的前提是两者的数据结构都位于内存中,当我们要在磁盘上索引一个记录时,将磁盘中的数据传输到内存中才是花费时间的大头,而在内存中的索引过程所花的时间基本是可以忽略不计的。在磁盘中以B+树的形式组织数据就有着天然的优势。要解释这个道理,我们必须先强调一个概念,主存和磁盘之间的数据交换不是以字节为单位的,而是以n个扇区为单位的(一个扇区有512字节),通常是4KB(8个扇区),8KB(16个扇区),16KB,……64KB为单位的。假设,我们现在选择4KB作为内存和磁盘之间的传输单位,那么我们在设计B+树的时候,不论是索引结点还是叶子结点都使用4KB作为结点的大小。我们这时不妨再假设一个记录的大小是1KB,那么一个叶子结点可以存4个记录。而对于索引结点(大小也是4KB),由于只需要存key值和相应的指针,所以一个索引结点可能可以存储100~150个分支,我们不妨就取100吧。当然这和上面第2节和第三节中的情况不太一样,因为现在索引结点的阶数是100,而叶子结点的阶数是4,两者并不一致,但这并没有什么问题。
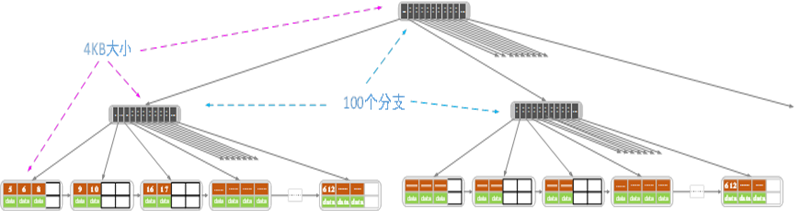
我们考虑如上图所示的B+树,下面的B+树有三层,两层是索引结点,最后一层是叶子结点。那么这个三层的B+树最多可以存400万个记录。如果这个B+树存储到硬盘中,我们怎么根据记录的key找到对应的记录呢?首先我们要读取这个B+树的根结点到内存(花费一个IO的时间)然后在内存中进行索引,然后根据key找到对应的分支,再将这个分支所指向的第二层索引结点读取到内存中(花费第二个IO时间)然后在内存中进行索引,同样根据key找到对应的分支,而这个分支指向的就是叶子结点,我们最后将这个叶子结点读取到内存中(花费的第三个IO时间)判断是否存在这个记录。这样我们只需要通过三次IO时间就从400万个记录中找到了对应的key记录,可以说是非常快了。快速的原因是,索引结点中不存数据,只存键和指针,所以一个索引结点就可以存储大量的分支,而一个索引结点只需要一次IO即可读取到内存中。
我们现在再考虑一个问题,当记录的大小可变时,叶子结点中记录该如何存储?
这个时候有两种极限情况。
1)假设叶子结点的阶数仍然为4,但每个记录仅仅有100个字节,显然当叶子结点中存满4个记录后,叶子结点中仍然有大量的剩余空间。这个时候我们能不能直接向该叶子结点中插入数据,而不必分裂这个叶子结点(分裂指在磁盘中的分裂)?答案是可以,有人一定会说,这不就违反B+树的定义了么?的确违反了,但是B+树之所以定义阶数的目的是为了平衡(或者说增强)每一个分支的索引效率,不过这个优点仅当整个B+树都位于内存时才能体现出来。当B+树存储在磁盘中的情况时,IO效率才是第一要考虑的因素。CPU在某个结点内部多比较几次或少比较几次和IO花费的时间相比就不值得一提了。而不分裂反而能提升B+树的IO效率,因为分裂需要更多的IO次数。综合起来了说就是,文件系统及数据库中的B+树是不考虑阶数这一个概念的,结点(即包括叶子结点,也包括索引结点)中仅遵行一个规则,如果剩余空间够大那么就存入数据,如果剩余空间不够,只能分裂后再存入。
2)如果某条记录太大,即使叶子结点中还剩余一多半的空间但仍然存不下怎么办?这个时候MySql称之为行溢出,简单的解决方式就是把记录存储在溢出页(磁盘的其它空闲地方)中,然后叶子结点中存储的是这个记录的指针。
补充:如果按照key值的大小顺序插入,按照B+树定义的方式进行分裂时,每个叶子结点的存储效率只有50%,为了解决这个问题,我们可以采取这样的分裂方式:原叶子结点中的数据不动,创建一个新的空叶子结点,记录插入到新叶子节点中。这样磁盘的插入效率就很高,而且每个叶子结点的利用率也很高。但这种分裂方式仅仅对按key的大小将记录顺序插入才有效,随机插入条件反而不如50%分裂的方式。
参考内容
[1] B+树介绍
[2] 从MySQL Bug#67718浅谈B+树索引的分裂优化
[3] B+树的几点总结
B+树在磁盘存储中的应用的更多相关文章
- MySQL索引(二)B+树在磁盘中的存储
MySQL索引(二)B+树在磁盘中的存储 回顾  上一篇文章<MySQL索引为什么要用B+树>讲了MySQL为什么选择用B+树来作为底层存储结构,提了两个知识点: B+树索引并不能直接找 ...
- (新人的第一篇博客)树状数组中lowbit(i)=i&(-i) 的简单文字证明
第一次写博好激动o(≧v≦)o~~初一狗语无伦次还请多多指教 先了解树状数组http://blog.csdn.net/int64ago/article/details/7429868感觉这个前辈写 ...
- python利用Trie(前缀树)实现搜索引擎中关键字输入提示(学习Hash Trie和Double-array Trie)
python利用Trie(前缀树)实现搜索引擎中关键字输入提示(学习Hash Trie和Double-array Trie) 主要包括两部分内容:(1)利用python中的dict实现Trie:(2) ...
- B+树在数据库中的应用
B+树在数据库中的应用 flyfish 2015-7-6 B+树在数据库中的应用重要是实现索引 应用方式一 ID为表的主键,利用主键建立一棵B+树 叶子结点存储记录的地址 应用方式二 ID为表的主键. ...
- PyQt(Python+Qt)学习随笔:QTreeWidget树型部件中的QTreeWidgetItem项构造方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTreeWidget树型部件的项是单独的类对象,这个类就是QTreeWidgetItem. QTr ...
- F9 开发之左树右表中的左树
1 首先在前端应用树树控件 <div class="fui-left"> <div role="head" title="地区选择& ...
- 数据结构-C语言递归实现树的前中后序遍历
#include <stdio.h> #include <stdlib.h> typedef struct tree { int number ; struct tree *l ...
- 浅谈左偏树在OI中的应用
Preface 可并堆,一个听起来很NB的数据结构,实际上比一般的堆就多了一个合并的操作. 考虑一般的堆合并时,当我们合并时只能暴力把一个堆里的元素一个一个插入另一个堆里,这样复杂度将达到\(\log ...
- LeetCode刷题总结-树篇(中)
本篇接着<LeetCode刷题总结-树篇(上)>,讲解有关树的类型相关考点的习题,本期共收录17道题,1道简单题,10道中等题,6道困难题. 在LeetCode题库中,考察到的不同种类的树 ...
随机推荐
- requests.post发送字典套字典
import requests import json a = { "data": { "project": { "url": " ...
- hdu1568 Fibonacci---前4位
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=1568 题目大意: 求斐波那契数列第i项的前四位.i<1e8 思路: 由于数据范围大,不可能打表 ...
- 处理异常、常用类、反射、类加载与垃圾回收、java集合框架
异常处理概述 检查异常:检查异常通常是用户错误或者不能被程序员所预见的问题.(cheched) 运行时异常:运行时异常是一个程序在运行过程中可能发生的.可以被程序员避免的异常类型.(Unchecked ...
- 合并css 合并图片 合并js
1:合并css 如:index.html 中的代码 <!DOCTYPE html><html lang="en"><head> <me ...
- Ubuntu16.04开机引导缺失Win10
Ubuntu正常开机的情况下: sudo update-grub # 如果grub丢失, 就先sudo apt install grub Ubuntu不能正常开下: 进入Ubuntu引导, 不要正常进 ...
- 学习linux的一些指令
简单说一下我对linux的理解,linux只有一个根目录,所有目录都挂在该根目录上,磁盘进行分区,然后生成文件系统,挂到目录上,/etc/fstab用于记录系统配置,比如分区挂载点,开机自动挂载等等. ...
- [LeetCode] Range Addition II 范围相加之二
Given an m * n matrix M initialized with all 0's and several update operations. Operations are repre ...
- 众说纷纭的ul、ol、li
(1)提到ul ol li,大家都知道,就是三个列表标签,ul表示无需列表(unordered list),ol表示有序列表(oredr list), li 表示列表项(list item),之前我也 ...
- python入门编程之三级菜单编程
菜单实现功能输入一层显示下一层菜单不论在哪层输入b返回上一层不论在哪层输入q退出菜单此代码通过利用字典的知识可以实现_Author_ = 'jc'data = { '北京':{ '昌平':{ '沙河' ...
- mysql事务,视图,权限管理,索引,存储引擎(胖胖老师)
1: 视图什么是视图 视图是一个虚拟表, 它的内容来源于查询的实表, 本身没有真正的数据;视图的作用 对于复杂的查询时,每次查询时都需要编写一些重复的查询代码让编写sql的效率低下, 为了 ...