02 Django REST Framework 序列化
01-创建序列化类
# 方式一:
publish_list = models.Publish.objects.all()
# 导入序列化组件
from django.core import serializers serializers.serialize("json", publish_list)
# 方式二:
# 为queryset和model对象做序列化 class PublishSerializers(serializers.Serializer):
# 添加做序列化的字段
name = serializers.CharField()
email = serializers.CharField() publish_list = models.Publish.objects.all() PublishSerializers(publish_list, many=True) PublishSerializers(model_obj)
Response
from rest_framework.response import Response
# 序列化 一对多 多对多 class BookSerializers(serializers.Serializer):
# 添加做序列化的字段
title = serializers.CharField()
price = serializers.CharField()
# 一对多
publish = serializers.CharField(source="publish.name") # 多对多
authors = serializers.SerializerMethodField() def get_authors(self, obj):
temp = []
for obj in obj.authors.all():
temp.append(obj.name)
02-ModelSerializer
# 等同于上面的 from rest_framework.views import APIView class BookModelSerializers(serializers.ModelSerializer):
class Meta:
model = Book # 表名
fields = "__all__" class BookView(APIView):
def get(self, request):
book_list = Book.objects.all()
bs = BookModelSerializers(book_list, many=True) return Response(bs.data) def post(self):
pass
03-提交post请求
class BookView(APIView):
def get(self, request):
'''
获取书籍
:param request:
:return:
'''
book_list = Book.objects.all()
bs = BookModelSerializers(book_list, many=True) return Response(bs.data) def post(self, request):
'''
添加书籍
:return:
'''
# post请求的数据
bs = BookModelSerializers(data=request.data)
if bs.is_valid():
bs.save() # 调用的是create方法
# 返回的是添加的数据
return Response(bs.data)
else:
# 错误的数据
return HttpResponse(bs.errors)
04-重写save中create方法
class BookModelSerializers(serializers.ModelSerializer):
class Meta:
model = Book # 表名
fields = "__all__" publish = serializers.CharField(source="publish.pk)
# 针对一对多字段publish,会报错,所以重写create方法
def create(self, validated_data):
book = Book.objects.create(title=validated_data["title"], price = validated_data["price"], pub_date = validated_data["pub_date"])
book.authors.add(*validated_data["authors"]) return book
05-自定义方法

class UserInfoSerializer(serializers.ModelSerializer):
type = serializers.CharField(source="get_user_type_display")
group = serializers.CharField(source="group.title")
rls = serializers.SerializerMethodField() def get_rls(self, row):
# 获取用户所有的角色
role_obj_list = row.roles.all()
ret = []
# 获取角色的id和名字
# 以字典的键值对方式显示
for item in role_obj_list:
ret.append({"id": item.id, "title": item.title})
return ret class Meta:
model = models.UserInfo
fields = ['id','username','password','type','group','rls']
06-自动序列化连表(depth)
class UserInfoSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
#fields = "__all__"
fields = ['id','username','password','group','roles']
#表示连表的深度
depth = 1
07-生成url
# urls.py urlpatterns = [
re_path('(?P<version>[v1|v2]+)/group/(?P<pk>\d+)/', GroupView.as_view(),name = 'gp') #序列化生成url
]
class UserInfoSerializer(serializers.ModelSerializer):
# 获取url
group = serializers.HyperlinkedIdentityField(view_name='gp',lookup_field='group_id',lookup_url_kwarg='pk')
class Meta:
model = models.UserInfo
#fields = "__all__"
fields = ['id','username','password','group','roles']
#表示连表的深度
depth = 0
效果:
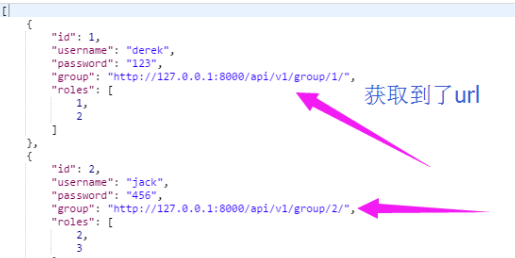
08-自定义数据验证规则
# 自定义验证规则
class GroupValidation(object):
def __init__(self,base):
self.base = base def __call__(self, value):
if not value.startswith(self.base):
message = "标题必须以%s为开头"%self.base
raise serializers.ValidationError(message) class UserGroupSerializer(serializers.Serializer):
title = serializers.CharField(validators=[GroupValidation('以我开头'),]) class UserGroupView(APIView):
def post(self,request,*args, **kwargs):
ser = UserGroupSerializer(data=request.data)
if ser.is_valid():
print(ser.validated_data['title'])
else:
print(ser.errors) return HttpResponse("用户提交数据验证")
09-序列化外键用嵌套的方法来实现
示例:
# 轮播图
class GoodsImageSerializer(serializers.ModelSerializer):
class Meta:
model = GoodsImage
fields = ("image",) # 商品列表页
class GoodsSerializer(serializers.ModelSerializer):
# 覆盖外键字段
category = CategorySerializer()
# images是数据库中设置的related_name="images",把轮播图嵌套进来
images = GoodsImageSerializer(many=True)
class Meta:
model = Goods
fields = '__all__'
10-添加自定义字段 不在model字段内
class ForgetPWDSerializers(serializers.ModelSerializer):
re_password = serializers.CharField(write_only=True) class Meta:
model = UserModel
fields = ('username', 'password', 're_password')
原理:create最后在返回response体的时候,传递的参数serializer.data,其实做的是一个序列化的工作,它会依据你在class Meta里面设置的fields,去做序列化,将里面所有字段进行序列化,这个时候就会报错!
解决方法:write_only 设置这个属性为true,去确保create/update的时候这个字段被用到,序列化的时候,不被用到!
11-

12-获取choice的值
# 指定 source="get_category_display" CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux"))
category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True)
13-设定不需要校验字段
# required=False id = serializers.IntegerField(required=False)
14-序列化字段与反序列化字段
# 前端 传 w_category 字段,序列化用category,反序列化用 w_category category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True)
w_category = serializers.ChoiceField(choices=CHOICES, write_only=True)
read_only=True 序列化字段;
write_only=True 反序列化字段;
book_obj = {
"title": "Alex的使用教程",
"w_category": 1,
"pub_time": "2018-10-09",
"publisher_id": 1,
"author_list": [1, 2]
}
class BookSerializer(serializers.Serializer):
id = serializers.IntegerField(required=False)
title = serializers.CharField(max_length=32, validators=[my_validate])
CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux"))
category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True)
w_category = serializers.ChoiceField(choices=CHOICES, write_only=True)
pub_time = serializers.DateField()
publisher = PublisherSerializer(read_only=True)
publisher_id = serializers.IntegerField(write_only=True)
author = AuthorSerializer(many=True, read_only=True)
author_list = serializers.ListField(write_only=True)
def create(self, validated_data):
book = Book.objects.create(title=validated_data["title"], category=validated_data["w_category"],
pub_time=validated_data["pub_time"], publisher_id=validated_data["publisher_id"])
book.author.add(*validated_data["author_list"])
return book
def update(self, instance, validated_data):
instance.title = validated_data.get("title", instance.title)
instance.category = validated_data.get("category", instance.category)
instance.pub_time = validated_data.get("pub_time", instance.pub_time)
instance.publisher_id = validated_data.get("publisher_id", instance.publisher_id)
if validated_data.get("author_list"):
instance.author.set(validated_data["author_list"])
instance.save()
return instance
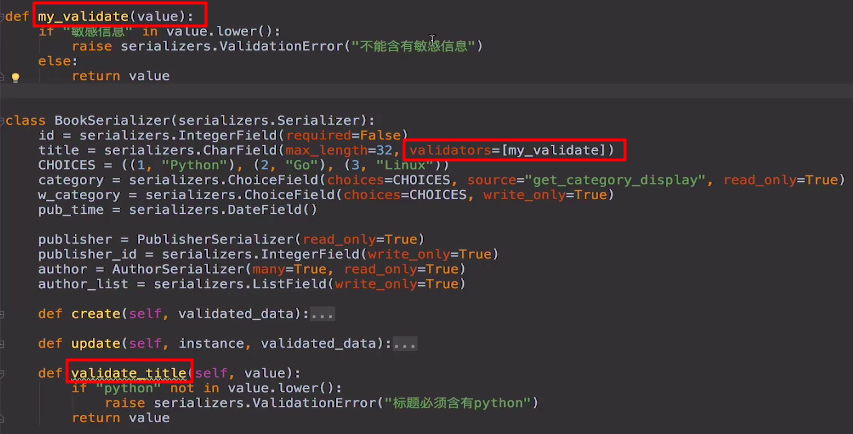
def validate_title(self, value):
if "python" not in value.lower():
raise serializers.ValidationError("标题必须含有python")
return value
def validate(self, attrs):
if attrs["w_category"] == 1 and attrs["publisher_id"] == 1:
return attrs
else:
raise serializers.ValidationError("分类以及标题不符合要求")
第一版
class BookSerializer(serializers.ModelSerializer):
category_display = serializers.SerializerMethodField(read_only=True)
publisher_info = serializers.SerializerMethodField(read_only=True)
authors = serializers.SerializerMethodField(read_only=True) def get_category_display(self, obj):
return obj.get_category_display() def get_authors(self, obj):
authors_query_set = obj.author.all()
return [{"id": author_obj.id, "name": author_obj.name} for author_obj in authors_query_set] def get_publisher_info(self, obj):
# obj 是我们序列化的每个Book对象
publisher_obj = obj.publisher
return {"id": publisher_obj.id, "title": publisher_obj.title} class Meta:
model = Book
# fields = ["id", "title", "pub_time"]
fields = "__all__"
# depth = 1
extra_kwargs = {"category": {"write_only": True}, "publisher": {"write_only": True},
"author": {"write_only": True}}
第二版ModelSerializer
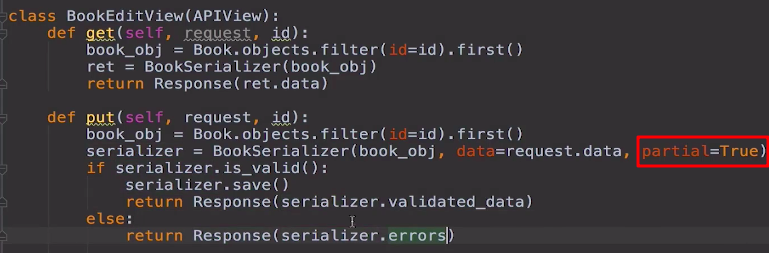
15-put允许部分更新字段:partial=True
16-自定义校验方法 my_validate
# 三种 校验数据的方式:
1. 校验全部字段
validate 2. 校验单个字段 如:title
validate_title 3. 自定义校验方法
my_validate def my_validate(value):
if "敏感信息" in value.lower():
raise serializers.ValidationError("不能含有敏感信息")
else:
return value
my_validate的权重 高于 validate_title
17-设置depth = 1,获取外键字段及多对多字段的值
class BookSerializer(serializers.ModelSerializer):
# 获取 category 字段的选择 的值,是数字对应的值,而不是数字
category = serializers.CharField(source="get_category_display") class Meta:
model = Book
# fields = ["id", "title", "pub_time"]
fields = "__all__"
depth = 1

18-SerializerMethodField 用于 外键字段 等,只获取想要的字段的值
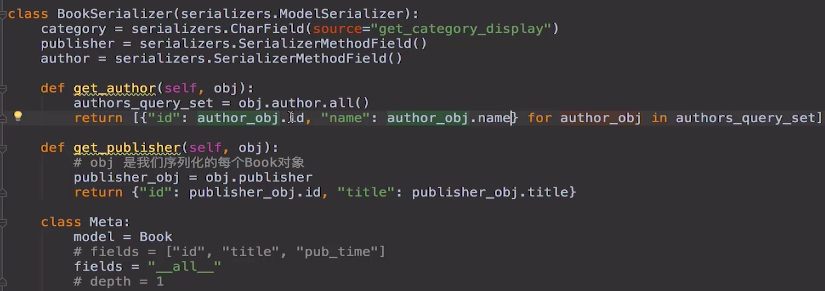
class BookSerializer(serializers.ModelSerializer):
category_display = serializers.SerializerMethodField(read_only=True)
publisher_info = serializers.SerializerMethodField(read_only=True)
authors = serializers.SerializerMethodField(read_only=True) def get_category_display(self, obj):
return obj.get_category_display() def get_authors(self, obj):
authors_query_set = obj.author.all()
return [{"id": author_obj.id, "name": author_obj.name} for author_obj in authors_query_set] def get_publisher_info(self, obj):
# obj 是我们序列化的每个Book对象
publisher_obj = obj.publisher
return {"id": publisher_obj.id, "title": publisher_obj.title} class Meta:
model = Book
# fields = ["id", "title", "pub_time"]
fields = "__all__"
# depth = 1
extra_kwargs = {"category": {"write_only": True}, "publisher": {"write_only": True},
"author": {"write_only": True}}
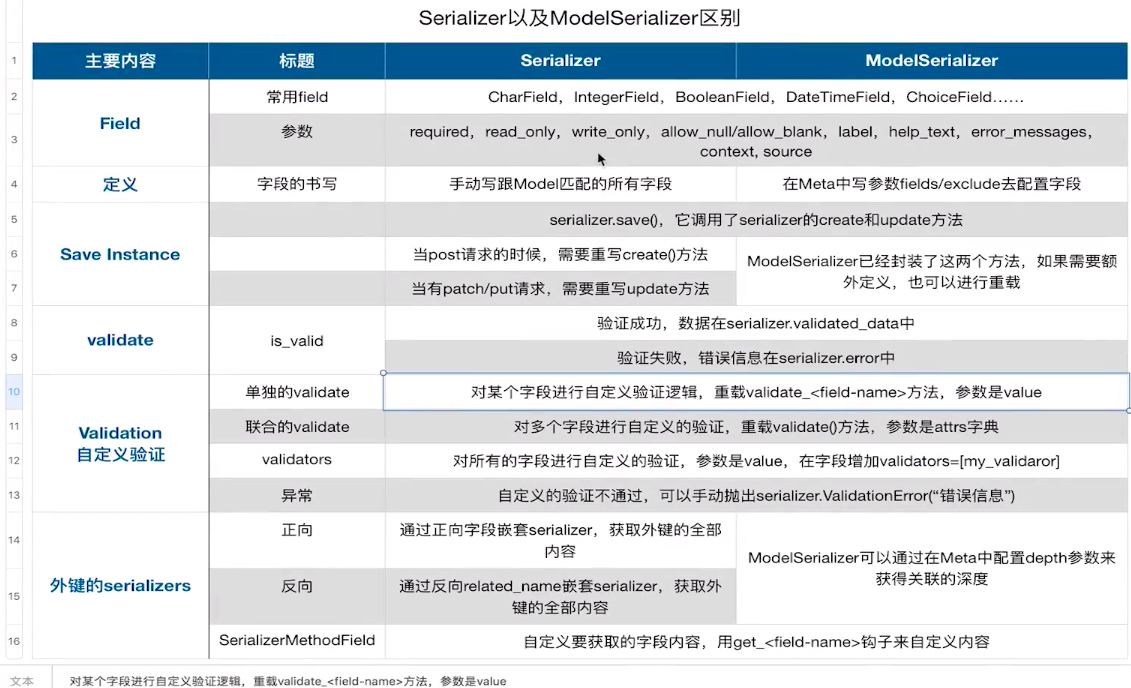
02 Django REST Framework 序列化的更多相关文章
- Django REST Framework序列化器
Django序列化和json模块的序列化 从数据库中取出数据后,虽然不能直接将queryset和model对象以及datetime类型序列化,但都可以将其转化成可以序列化的类型,再序列化. 功能需求都 ...
- [Django REST framework - 序列化组件、source、钩子函数]
[Django REST framework - 序列化组件.source.钩子函数] 序列化器-Serializer 什么是rest_framework序列化? 在写前后端不分离的项目时: 我们有f ...
- Django REST framework序列化
一.简介 Django REST framework是基于Django实现的一个RESTful风格API框架,能够帮助我们快速开发RESTful风格的API. 官网:https://www.djang ...
- Django Rest framework序列化流程
目录 一 什么是序列化 二 Django REST framework配置流程之Serializer 三 Django REST framework配置流程之ModelSerializer 一 什么是 ...
- python学习-- Django REST framework 序列化数据操作
一.为什么要返回json数据? 一般来说前端要用到从后台返回的数据来渲染页面的时候,这时候后台就需要向前端返回json类型的数据,简单直观便于理解 ,就类似于 {"xxx":{[& ...
- Django REST Framework 序列化和校验 知识点
DRF序列化 Django ORM对象 --> JSON格式的数据 序列化 JSON格式的数据 --> Django ORM数据 反序列化 需要两个工具: from rest_framew ...
- django rest framework 序列化组件总结
序列化组件总结 一. 序列化组件本质上为了实现前后端分离,而进行json序列化的一个组件形式,极大方便了解析数据的作用 二. 所有序列化是基于APIView 解析器实现的,通过内部的多继承关系方便实现 ...
- 在django restful framework中设置django model的property
众所周知,在django的model中,可以某些字段设置@property和setter deleter getter,这样就可以在存入数据的时候进行一些操作,具体原理请参见廖雪峰大神的博客https ...
- django restful framework 一对多方向更新数据库
目录 django restful framework 序列化 一 . 数据模型: models 二. 序列化: serializers 三, 视图: views 四, 路由: urls 五. 测试 ...
随机推荐
- Java集合-ArrayList源码解析-JDK1.8
◆ ArrayList简介 ◆ ArrayList 是一个数组队列,相当于 动态数组.与Java中的数组相比,它的容量能动态增长.它继承于AbstractList,实现了List, RandomAcc ...
- Oracle ASH报告生成和性能分析
我写的SQL调优专栏:https://blog.csdn.net/u014427391/article/category/8679315 对于局部的,比如某个页面列表sql,我们可以使用Oracle的 ...
- 【TensorFlow篇】--Tensorflow框架可视化之Tensorboard
一.前述 TensorBoard是tensorFlow中的可视化界面,可以清楚的看到数据的流向以及各种参数的变化,本文基于一个案例讲解TensorBoard的用法. 二.代码 设计一个MLP多层神经网 ...
- .NET Core微服务之基于MassTransit实现数据最终一致性(Part 2)
Tip: 此篇已加入.NET Core微服务基础系列文章索引 一.案例结构与说明 在上一篇中,我们了解了MassTransit这个开源组件的基本用法,这一篇我们结合一个小案例来了解在ASP.NET C ...
- OO Unit2多线程电梯总结博客
OO Unit2多线程电梯总结博客 传说中的电梯居然就这样写完了-撒花
- 从零开始搭建一个规范的vue-cli 3.0项目
在这一集我们将讲到如何从安装vue-cli开始,到新建一个本地项目,再到vscode中关于eslint的配置,以及本地项目关联公司远程项目的基本操作. 一,初始化本地项目 1,首先,全局安装vue-c ...
- python学习第四讲,python基础语法之判断语句,循环语句
目录 python学习第四讲,python基础语法之判断语句,选择语句,循环语句 一丶判断语句 if 1.if 语法 2. if else 语法 3. if 进阶 if elif else 二丶运算符 ...
- JDK源码分析(2)之 Array 相关
在深入了解 Array 之前,一直以为 Array 比较简单,但是深入了解后才发现其实挺复杂的.所以我把重要的写在最前面,但凡遇到和语言本身相关的问题,都可以查阅 Java Language and ...
- [转]Node.js 应用:Koa2 使用 JWT 进行鉴权
本文转自:https://www.cnblogs.com/linxin/p/9491342.html 前言 在前后端分离的开发中,通过 Restful API 进行数据交互时,如果没有对 API 进行 ...
- 折腾Java设计模式之迭代器模式
迭代器模式 Provide a way to access the elements of an aggregate object sequentially without exposing its ...