[ZooKeeper] 1 基本概念
ZooKeeper: A Distributed Coordination Service for Distributed Applications
ZooKeeper is a distributed, open-source coordination service for distributed applications. It exposes a simple set of primitives that distributed applications can build upon to implement higher level services for synchronization, configuration maintenance, and groups and naming. It is designed to be easy to program to, and uses a data model styled after the familiar directory tree structure of file systems. It runs in Java and has bindings for both Java and C.
Coordination services are notoriously hard to get right. They are especially prone to errors such as race conditions and deadlock. The motivation behind ZooKeeper is to relieve distributed applications the responsibility of implementing coordination services from scratch.
ZooKeeper :分布式应用的分布式协调服务
Design Goals
ZooKeeper is simple. ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchal namespace which is organized similarly to a standard file system. The name space consists of data registers - called znodes, in ZooKeeper parlance - and these are similar to files and directories. Unlike a typical file system, which is designed for storage, ZooKeeper data is kept in-memory, which means ZooKeeper can acheive high throughput and low latency numbers.
The ZooKeeper implementation puts a premium on high performance, highly available, strictly ordered access. The performance aspects of ZooKeeper means it can be used in large, distributed systems. The reliability aspects keep it from being a single point of failure. The strict ordering means that sophisticated synchronization primitives can be implemented at the client.
ZooKeeper is replicated. Like the distributed processes it coordinates, ZooKeeper itself is intended to be replicated over a sets of hosts called an ensemble.
The servers that make up the ZooKeeper service must all know about each other. They maintain an in-memory image of state, along with a transaction logs and snapshots in a persistent store. As long as a majority of the servers are available, the ZooKeeper service will be available.
Clients connect to a single ZooKeeper server. The client maintains a TCP connection through which it sends requests, gets responses, gets watch events, and sends heart beats. If the TCP connection to the server breaks, the client will connect to a different server.
ZooKeeper is ordered. ZooKeeper stamps each update with a number that reflects the order of all ZooKeeper transactions. Subsequent operations can use the order to implement higher-level abstractions, such as synchronization primitives.
ZooKeeper is fast. It is especially fast in "read-dominant" workloads. ZooKeeper applications run on thousands of machines, and it performs best where reads are more common than writes, at ratios of around 10:1.
设计目标
简单。ZooKeeper
允许各分布式进程之间可以通过一个共享的层次型命名空间来相互协调,该命名空间的组织就像一个标准的文件系统,包括若干注册的数据节点。这些节点在 ZooKeeper
中被称为 znodes,类似于文件和目录。与用于存储的传统文件系统不同的是,ZooKeeper
的数据是保存在内存当中的,意味着 ZooKeeper
可以实现高通量和低延迟。
ZooKeeper
的实现着重于高性能、高可用和严格的顺序访问。性能方面的特点决定了 ZooKeeper
可用于大型的分布式系统,从可靠性方面来书,它可以避免发生单点故障,严格的顺序访问控制则保证了可以在客户端实现复杂的同步原语。
复制。就像它所协调的分布式进程,ZooKeeper
本身也可以通过若干主机(称为集群)进行复制。
组成 ZooKeeper
服务的各个服务器之间必须可以相互通信。它们维护一个状态信息的内存映像,以及在持久化存储中维护着事务日志和快照。所以只要大部分服务器正常工作,这个
ZooKeeper 服务就是可用的。
多个客户端可以同时连接到一个
ZooKeeper 服务器。由客户端维护着这个 TCP
连接,通过这个连接,客户端可以发送请求、接收响应、获取监视事件以及发送心跳。如果这个连接断了,客户端就会连接到另一台 ZooKeeper
服务器。
顺序。ZooKeeper 会为每次更新标识一个数字,表示所有 ZooKeeper
事务的顺序。后续的操作可以利用这个顺序实现更高层次的抽象功能,比如同步原语。
高效。ZooKeeper 特别适合于以读取占主导的工作负载中。ZooKeeper
可以运行在数千台机器上,并且当读写比例接近10:1时性能最佳。
ZooKeeper
所提供的服务主要是通过:数据结构(znode)+原语(关于该数据结构的一些操作)+ watcher 机制 三个部分来实现的。
Data model and the hierarchical namespace
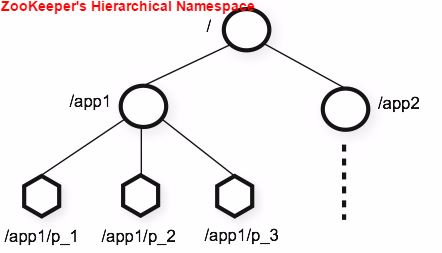
The name space provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/). Every node in ZooKeeper's name space is identified by a path.
数据模型和分层命名空间
ZooKeeper
的命名空间与标准的文件系统非常相似。一个命名空间就是一系列的由“/”分隔的路径。命名空间里的每个节点都是由一个路径(Unicode字符串)唯一标识的。
Nodes and ephemeral nodes
Unlike is standard file systems, each node in a ZooKeeper namespace can have data associated with it as well as children. It is like having a file-system that allows a file to also be a directory. (ZooKeeper was designed to store coordination data: status information, configuration, location information, etc., so the data stored at each node is usually small, in the byte to kilobyte range.) We use the term znode to make it clear that we are talking about ZooKeeper data nodes.
Znodes maintain a stat structure that includes version numbers for data changes, ACL changes, and timestamps, to allow cache validations and coordinated updates. Each time a znode's data changes, the version number increases. For instance, whenever a client retrieves data it also receives the version of the data.
The data stored at each znode in a namespace is read and written atomically. Reads get all the data bytes associated with a znode and a write replaces all the data. Each node has an Access Control List (ACL) that restricts who can do what.
ZooKeeper also has the notion of ephemeral nodes. These znodes exists as long as the session that created the znode is active. When the session ends the znode is deleted. Ephemeral nodes are useful when you want to implement [tbd].
节点和临时节点
与标准文件系统不同的是,ZooKeeper
命名空间中的每个节点都可以包含与本身相关或者与子节点相关的数据。兼具文件和目录两种特点。(ZooKeeper
是用来存储协调数据的,例如状态信息、配置、位置信息等,所以每个节点上存储的数据通常都很小,在字节到千字节之间。)为简单起见,下文我们将以 znode 表示 ZooKeeper 数据节点。
Znodes 维护着一个 stat 结构,包括数据修改、ACL 修改以及时间戳的版本号,用于缓存验证和协调更新。每一次的 znode
数据更新,版本号都会随之增加。当一个客户端接收数据的同时也会得到该数据的版本。
一个命名空间里,每个 znode
数据的读写都是原子性的。读取操作是获取所有与 znode 相关的数据字节,写入操作则是替换所有数据。另外,每个节点都有一个访问控制列表(Access
Control List,ACL),规定了特定用户的权限,限定特定用户对目标节点可以执行的操作。
ZooKeeper 也有临时节点(ephemeral
node)的概念,这些节点的生命周期依赖于创建它们的 session ,一旦 session
结束了,临时节点也将被自动删除。虽然每个临时节点都会绑定一个客户端会话,但是它们对所有客户端还是可见的。另外,临时节点不允许有子节点。
节点的类型在创建时就已经确定,并且不能改变。
持久化节点的生命周期不依赖于
session,只有在客户端显式执行删除操作时才能被删除。
顺序节点是在创建节点时,在请求的路径末尾添加一个递增的计数。该计数对于此节点的父节点是唯一的。格式为“%10d”。
监视器是客户端在节点上设置
watch,当节点状态发生改变时,将会触发 watch 所绑定的操作,且 watch 只能触发一次,之后就被删除掉。
☛ 每个
znode 由三部分组成:
- stat:状态信息,描述 znode 的版本、权限等信息;
- data:与该 znode 关联的数据;
- children:该 znode 下的子节点;
- PERSISTENT:持久化节点
- PERSISTENT_SEQUENTIAL:持久化顺序编号节点
- EPHEMERAL:临时节点
- EPHEMERAL_SEQUENTIAL:临时顺序编号节点
Conditional updates and watches
ZooKeeper supports the concept of watches. Clients can set a watch on a znodes. A watch will be triggered and removed when the znode changes. When a watch is triggered the client receives a packet saying that the znode has changed. And if the connection between the client and one of the Zoo Keeper servers is broken, the client will receive a local notification. These can be used to [tbd].
条件更新和监视点
ZooKeeper 支持 watches(监视点) 的概念。客户端可以在一个
znode 上设置一个监视点,当 znode 发生改变时,监视点将被触发并删除,是一次性的触发器。而当监视点被触发时,客户端就会收到 znode
发生改变的通知。并且,如果客户端与 ZooKeeper 服务器之间的连接中断了,客户端会收到一个本地通知。【待定】
ZooKeeper
可以为所有的读操作(exists、getChildren、etData)设置 watch。理论上,客户端接收 watch 事件的时间要快于其看到 watch
对象状态变化的时间。
watch 是由客户端所连接的
ZooKeeper 服务器在本地进行维护,因此 watch 很容易进行设置、管理和分派。watch 分为以下两种:
- data watches:当前节点数据的 watch,由 getData 和 exists
负责设置; - child watches:当前节点的子节点的 watch,由 getChildren
负责设置;
具有双重作用,注册触发事件和函数本身的功能。分别重载 process(Event event) 和 processResult() 来实现。
| 设置 watch |
watch 触发器 |
||||
| create | delete | setData | |||
| znode | child | znode | child | znode | |
| exists | NodeCreated | NodeDeleted | NodeDataChanged | ||
| getData | NodeDeleted | NodeDataChanged | |||
| getChildren | NodeChildrenChanged | NodeDeleted | NodeDeletedChanged | ||
Guarantees
ZooKeeper is very fast and very simple. Since its goal, though, is to be a basis for the construction of more complicated services, such as synchronization, it provides a set of guarantees. These are:
Sequential Consistency - Updates from a client will be applied in the order that they were sent.
Atomicity - Updates either succeed or fail. No partial results.
Single System Image - A client will see the same view of the service regardless of the server that it connects to.
Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update.
Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound.
保证
ZooKeeper
是非常高效简单的。因为它的目标是构建更加复杂服务(例如同步)的基础,所以它提供了一系列的保证:
- 顺序一致性 ——
来自客户端的更新,将会严格按照其发送的顺序被应用到 ZooKeeper 中。 - 原子性 ——
更新不管是成功还是失败,其结果都是一致的,没有部分的结果。即所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,要么整个集群中所有机器都成功应用了某一事务,要么都没有应用,一定不会出现部分机器应用了该事务,而另一部分机器没有应用的情况。 - 单系统映像 ——
不管客户端连接到哪台服务器,它们都将得到相同的服务,看到的数据模型都是一致的。 - 可靠性 ——
一旦服务器端应用了一个更新事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会一直保留下来,直到客户端再次覆盖更新。 - 实时性 ——
在一定时间范围内可以保证客户端获取的系统状态是最新的。即 ZooKeeper
并不是一种强一致性,只能保证顺序一致性和最终一致性,即伪实时性。
时间和版本
ZooKeeper 节点状态改变的每个操作都将使节点接收到一个 zxid 格式的时间戳,该时间戳是全局有序的,即是唯一标识。如果 zxid1 小于
zxid2,那么 zxid1 对应的事务应发生在 zxid2 对应的事务之前。
- czxid:节点创建时间对应的 zxid 格式时间戳
- mzxid:节点修改时间对应的 zxid 格式时间戳
- pzxid:该节点或其子节点的最近一次创建/删除时间对应的 zxid
格式时间戳
被选举出来,就会产生一个新的 epoch。低32位是个递增的计数。
(2)version
- version:节点数据版本号
- cversion:子节点版本号
- aversion:节点拥有的 ACL
版本号
节点属性
| 属性 | 描述 |
| czxid | 节点创建时间对应的 zxid 格式时间戳 |
| mzxid | 节点修改时间对应的 zxid 格式时间戳 |
| ctime | 节点创建时间 |
| mtime | 节点修改时间 |
| version | 节点数据版本号 |
| cversion | 子节点版本号 |
| aversion | 节点拥有的 ACL 版本号 |
| ephemeralOwner | 如果此节点为临时节点,该值表示节点拥有者的会话 id,否则为 0 |
| dataLength | 节点数据长度 |
| numChildren | 节点拥有的子节点个数 |
| pzxid | 该节点或其子节点的最近一次创建/删除时间对应的 zxid 格式时间戳 |
Simple API
One of the design goals of ZooKeeper is provide a very simple programming interface. As a result, it supports only these operations:
- create:creates a node at a location in the tree
- delete:deletes a node
- exists:tests if a node exists at a location
- get data:reads the data from a node
- set data:writes data to a node
- get children:retrieves a list of children of a node
- sync:waits for data to be propagated
简单的
API
的设计目标之一就是提供一组简单的编程接口,结果它就只支持如下操作:
| 方法 | 描述 |
| create | 在树中某个位置创建一个节点(父节点必须存在) |
| delete | 删除一个节点(znode 没有子节点) |
| exists | 在某个位置检查是否存在一个节点,并获取它的元数据 |
| get data | 从一个节点读取数据,getACL、getChildren、getData |
| set data | 设置一个节点数据,setACL、setData |
| get children | 获取一个节点的子节点列表 |
| sync | 等待数据传播(同步到其他节点) |
Implementation
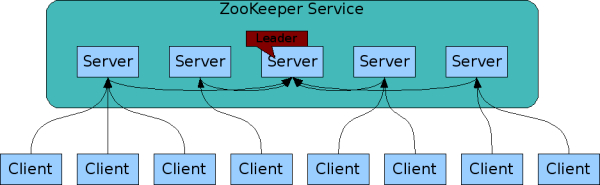
ZooKeeper Components shows the high-level components of the ZooKeeper service. With the exception of the request processor, each of the servers that make up the ZooKeeper service replicates its own copy of each of components.
The replicated database is an in-memory database containing the entire data tree. Updates are logged to disk for recoverability, and writes are serialized to disk before they are applied to the in-memory database.
Every ZooKeeper server services clients. Clients connect to exactly one server to submit irequests. Read requests are serviced from the local replica of each server database. Requests that change the state of the service, write requests, are processed by an agreement protocol.
As part of the agreement protocol all write requests from clients are forwarded to a single server, called the leader. The rest of the ZooKeeper servers, called followers, receive message proposals from the leader and agree upon message delivery. The messaging layer takes care of replacing leaders on failures and syncing followers with leaders.
ZooKeeper uses a custom atomic messaging protocol. Since the messaging layer is atomic, ZooKeeper can guarantee that the local replicas never diverge. When the leader receives a write request, it calculates what the state of the system is when the write is to be applied and transforms this into a transaction that captures this new state.
实现
下图显示了 ZooKeeper
服务的高层次组件。除了请求处理器(Request
Processor)外,构成 ZooKeeper
服务的每台服务器自己都有一份各个组件的备份。

复制数据库(Replicated
Database)是一个包含整个数据树的内存数据库。更新操作都会记录到磁盘以便恢复,而写入操作在应用到内存数据库之前会先被序列化到磁盘。
每个 ZooKeeper
服务器都可以为客户端提供服务,而客户端只会连接到一台服务器来提交请求。读取请求是由每个服务器数据库的本地副本提供服务,而对于会改变服务状态的请求 ——
写请求,则是由一个约定的协议进行处理。
该约定协议规定,所有客户端的写请求都统一发送到一台服务器上,该服务器称为 leader,其余的
ZooKeeper 服务器则称为 followers,follower 会从 leader 接收消息提议并同意实施。在 leader
发生故障时,协议的消息层(Messaging Layer)则会关注 leader 的更换,并同步到其他 followers。
ZooKeeper
采用了一个自定义的原子性消息协议。由于消息层是原子性的,所以 ZooKeeper 可以保证本地副本不会产生分歧。当 leader
接收一个写请求时,它会计算出写入操作实施后的系统状态,捕获该新状态并将其转换成一个事务。
Performance
性能
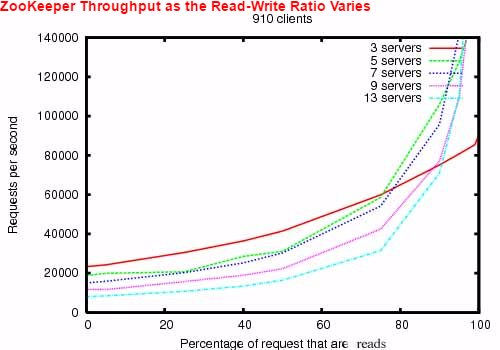
- ZooKeeper release 3.2
- 2Ghz Xeon + 2个 SATA 15K RPM 磁盘
- 一个磁盘用于 ZooKeeper 的日志记录,快照则写入 OS 设备
- “N
Servers”代表 ZooKeeper 集群中服务器的个数 - 大约30台服务器模拟客户端
- ZooKeeper 集群设置成 leader
不允许连接客户端
Reliability
可靠性
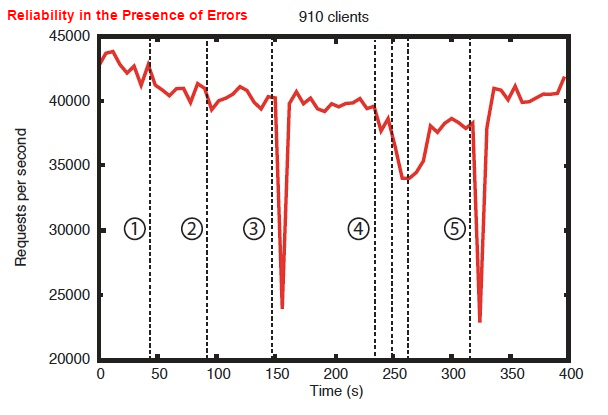
- 一台 follower
故障及恢复 - 另一台 follower
故障及恢复 - leader
故障 - 两台 followers
故障及恢复 - 另一台 leader
故障
ZooKeeper
安全机制
权限控制机制,包括三种模式:
- 权限模式,Schema,开发人员常用。
- IP:通过 ip
地址粒度进行权限控制,支持按网段分配权限,例如 192.168.1.* - Diges:最常用的权限控制模式,类似于"username:password"形式的权限标识,并对其进行
SHA-1 加密算法和 BASE64 编码两次编码处理。 - World:最开放的权限控制模式,作为一种特殊的
diges。 - Super:超级用户模式,可以进行任意操作。
- 权限对象:指的是权限赋予给用户或者一个指定的实体,例如 ip
地址或机器等。 - 权限:指那些通过权限检测后可以被允许执行的操作,包括 CREATE、DELETE、READ、WRITE 和
ADMIN。
参考说明
[ZooKeeper] 1 基本概念的更多相关文章
- [转帖]从0开始的高并发(一)--- Zookeeper的基础概念
从0开始的高并发(一)--- Zookeeper的基础概念 https://juejin.im/post/5d0bd358e51d45105e0212db 前言 前面几篇以spring作为主题也是有些 ...
- Zookeeper的核心概念以及java客户端使用
一.Zookeeper的核心概念 分布式配置中心(存储):disconf(zk).diamond(mysql+http) 1)znode ZooKeeper操作和维护的是一个个数据节点,称为 znod ...
- 大白话带你认识 ZooKeeper !重要概念一网打尽!
大家好,我是 「后端技术进阶」 作者,一个热爱技术的少年. 1. 前言 相信大家对 ZooKeeper 应该不算陌生.但是你真的了解 ZooKeeper 到底有啥用不?如果别人/面试官让你给他讲讲对于 ...
- ZooKeeper的基本概念(二)
第一篇博文,我们对Zookeeper有了一个简单的认识,而且比较浅显,易懂,这篇博文,我们了解它的基本概念,如下图所示: 了解它的基本概念,有助于我们后面的学习,虽然今天的文章都是概念性质的内容,但是 ...
- Zookeeper学习笔记-概念介绍
目录 概念 背景介绍 zookeeper一致性 使用建议 概念 ZooKeeper是一个开源的分布式协调服务,它为分布式应用提供了高效且可靠的分布式协调服务,提供的功能包括:配置维护.域名服务.分布式 ...
- Zookeeper分布式系统协同器概念快速学习
原文格式可以访问:https://www.rockysky.tech 分布式系统的基本操作 主节点选举:在绝大多数分布式系统中,都需要进行主节点选举.主节点负责管理协调其它节点或者同步集群中其它节点的 ...
- Zookeeper的基本概念
Reference: http://mp.weixin.qq.com/s?src=3×tamp=1477979201&ver=1&signature=bBZqNrN ...
- Zookeeper的基本概念和重要特性
目录 1. 什么是Zookeeper 2. Zookeeper集群角色 3. Zookeeper的数据模型 3.1 Znode的类型 3.2 Znode的结构 4. Zookeeper的事件监听机制 ...
- 第一章 zookeeper基础概念
1.ZooKeeper是什么 ZooKeeper为分布式应用提供了高效且可靠的分布式协调服务,提供了统一命名服务. 配置管理和分布式锁等分布式的基础服务.在解决分布式数据一致性方面, ZooKeepe ...
随机推荐
- 浅谈 JSON.stringify 方法
一.前言 最近项目中,遇到需要将对象转换成字符串进行传递,上次写过一篇文章关于json字符串转换成json对象,json对象转换成字符串,值转换成字符串,字符串转成值.当时主要是用在有时候处理字符串和 ...
- java排序算法(十):桶式排序
java排序算法(十):桶式排序 桶式排序不再是一种基于比较的排序方法,它是一种比较巧妙的排序方式,但这种排序方式需要待排序的序列满足以下两个特征: 待排序列所有的值处于一个可枚举的范围之类: 待排序 ...
- 定位bug的姿势对吗?
举个例子来说明 WEB页面上数据显示错误,本来应该显示38, 结果显示35,这个时候你怎么去定位这个问题出在哪里? 1.通过fiddler抓包工具(或者其他抓包工具), 分析接口返回的数据是35还是 ...
- C/C++生成随机数
一.rand和srand 在C++11标准出来之前,C/C++都依赖于stdlib.h头文件的rand或者srand来生成随机数. 其不是真正的随机数,是一个伪随机数,是根据一个数(我们可以称 ...
- 20162302 实验一《Java开发环境的熟悉》实验报告
实 验 报 告 课程:程序设计与数据结构 姓名:杨京典 班级:1623 学号:20162302 实验名称:Java开发环境的熟悉 实验器材:装有Ubuntu的联想拯救者80RQ 实验目的与要求:1.使 ...
- PTA题目的處理(四)
题目7-3 求交错序列前N项和 1.实验代码 #include <stdio.h> //#include <stdlib.h> int main() { ,N; double ...
- Apache的配置httpd.conf文件配置
(1) 基本配置: ServerRoot "/mnt/software/apache2" #你的apache软件安装的位置.其它指定的目录如果没有指定绝对路径,则目录是相对于该目录 ...
- 利用Node的chokidar 监听文件改变的文件。
最近维护一个项目.每次改完东西,都要上传到服务器.然后有时候就忘记一些东西,于是就想有没有可以方法能监听文件的改变.然后我再利用程序把更改的文件一键上传到服务器. 于是就找到了nodejs 的chok ...
- JAVA_SE基础——40.super关键字
只要this关键字掌握了,super关键字不在话下,因为他们原理都差不多的.. this&super 什么是this,this是自身的一个对象,代表对象本身,可以理解为:指向对象本身的一个指针 ...
- python django的ManyToMany简述
Django的多对多关系 在Django的关系中,有一对一,一对多,多对多的关系 我们这里谈的是多对多的关系 ==我们首先来设计一个用于示例的表结构== # -*- coding: utf-8 -*- ...