Python入妖5-----正则的基本使用
什么是正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是 事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符”,这个“规则字符” 来表达对字符的一种过滤逻辑。
正则并不是python独有的,其他语言也都有正则
python中的正则,封装了re模块
python正则的详细讲解
常用的匹配模式
\w 匹配字母数字及下划线
\W 匹配f非字母数字下划线
\s 匹配任意空白字符,等价于[\t\n\r\f]
\S 匹配任意非空字符
\d 匹配任意数字
\D 匹配任意非数字
\A 匹配字符串开始
\Z 匹配字符串结束,如果存在换行,只匹配换行前的结束字符串
\z 匹配字符串结束
\G 匹配最后匹配完成的位置
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开头
$ 匹配字符串的末尾
. 匹配任意字符,除了换行符,re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符
[....] 用来表示一组字符,单独列出:[amk]匹配a,m或k
[^...] 不在[]中的字符:[^abc]匹配除了a,b,c之外的字符
* 匹配0个或多个的表达式
+ 匹配1个或者多个的表达式
? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
{n} 精确匹配n前面的表示
{m,m} 匹配n到m次由前面的正则表达式定义片段,贪婪模式
a|b 匹配a或者b
() 匹配括号内的表达式,也表示一个组
re.match()
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配的话,match()就会返回None
语法格式:
re.match(pattern,string,flags=0)
最常规的匹配
import re content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello\s\d\d\d\s\d{4}\s\w{10}.*Demo$',content)
print(result)
print(result.group())
print(result.span())
结果如下:

result.group() 获取匹配的结果
result.span() 获去匹配字符串的长度范围
泛匹配
其实相对来说上面的方式并不是非常方便,其实可以将上述的正则规则进行更改
import re content= "hello 123 4567 World_This is a regex Demo"
result = re.match("^hello.*Demo$",content)
print(result)
print(result.group())
print(result.span())
匹配目标
如果为了匹配字符串中具体的目标,则需要通过()括起来,例子如下:
import re
content= "hello 1234567 World_This is a regex Demo"
result = re.match('^hello\s(\d+)\sWorld.*Demo$',content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())
这里需要说一下的是通过re.group()获得结果后,如果正则表达式中有括号,则re.group(1)获取的就是第一个括号中匹配的结果
贪婪匹配
先看下面代码:
import re content= "hello 1234567 World_This is a regex Demo"
result= re.match('^hello.*(\d+).*Demo',content)
print(result)
print(result.group(1))
从结果中可以看出只匹配到了7,并没有匹配到1234567,出现这种情况的原因是前面的.* 给匹配掉了, .*在这里会尽可能的匹配多的内容,也就是我们所说的贪婪匹配,
如果我们想要匹配到1234567则需要将正则表达式改为:
result= re.match('^he.*?(\d+).*Demo',content)
这样结果就可以匹配到1234567
匹配模式
很多时候匹配的内容是存在换行的问题的,这个时候的就需要用到匹配模式 re.S 来匹配换行的内容
import re content = """hello 123456 world_this
my name is zhaofan
""" result =re.match('^he.*?(\d+).*?zhaofan$',content,re.S)
print(result)
print(result.group())
print(result.group(1))

转义
当我们要匹配的内容中存在特殊字符的时候,就需要用到转移符号\,例子如下:
import re
content= "price is $5.00"
result = re.match('price is \$5\.00',content)
print(result)
print(result.group())
对上面的一个小结:
尽量使用泛匹配,使用括号得到匹配目标,尽量使用非贪婪模式,有换行符就用re.S
强调re.match是从字符串的起始位置匹配一个模式
re.search
re.search扫描整个字符串返回第一个成功匹配的结果
import re
content = "extra things hello 123455 world_this is a Re Extra things"
result = re.search("hello.*?(\d+).*?Re",content)
print(result)
print(result.group())
print(result.group(1))
结果:

其实这个时候我们就不需要在写^以及$,因为search是扫描整个字符串
注意:所以为了匹配方便,我们会更多的用search,不用match,match必须匹配头部,所以很多时候不是特别方便
匹配演练
例子1:
import re html = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
# <li data-view="4" class="active">
# <a href="/3.mp3" singer="齐秦">往事随风</a>
# </li>
<li data-view="6" class="active"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君">但愿人长久</a>
</li>
</ul>
</div>''' result = re.search('<li.*?active.*?singer="(.*?)">(.*?)</a>',html,re.S)
print(result)
print(result.groups())
print(result.group(1))
print(result.group(2))
结果为:

re.findall
搜索字符串,以列表的形式返回全部能匹配的子串
代码例子如下:
import re html = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君">但愿人长久</a>
</li>
</ul>
</div>''' results = re.findall('<li.*?href="(.*?)".*?singer="(.*?)">(.*?)</a>', html, re.S)
print(results)
print(type(results))
for result in results:
print(result)
print(result[0], result[1], result[2])

例子2:
import re html = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君">但愿人长久</a>
</li>
</ul>
</div>''' results = re.findall('<li.*?>\s*?(<a.*?>)?(\w+)(</a>)?\s*?</li>',html,re.S) # ?(\w+) 匹配到歌名 ?\s*? 匹配标签之间的任意空白字符
print(results)
for result in results:
print(result[1])

其实这里我们就可以看出
\s*? 这种用法其实就是为了解决有的有换行,有的没有换行的问题
(<a.*?>)? 这种用法是因为html中有的有a标签,有的没有的,?表示匹配一个或0个,正好可以用于匹配
re.sub
替换字符串中每一个匹配的子串后返回替换后的字符串
re.sub(正则表达式,替换成的字符串,原字符串)
例子1
import re
content = "Extra things hello 123455 World_this is a regex Demo extra things"
content = re.sub('\d+','',content)
print(content)
结果会讲数字替换为为空:

例子2,
在有些情况下我们替换字符的时候,还想获取我们匹配的字符串,然后在后面添加一些内容,可以通过下面方式实现:
import re
content = "Extra things hello 123455 World_this is a regex Demo extra things"
content = re.sub('(\d+)',r'\1 7777890',content)
print(content)
这里需要注意的一个问题是\1是获取第一个匹配的结果,为了防止转义字符的问题,我们需要在前面加上r

re.compile
将正则表达式编译成正则表达式对象,方便复用该正则表达式
import re
content= """hello 12345 world_this
fan
""" pattern =re.compile("hello.*fan",re.S) result = re.match(pattern,content)
print(result)
print(result.group())
结果

正则的综合练习
获取豆瓣网书籍的页面的书籍信息,通过正则实现
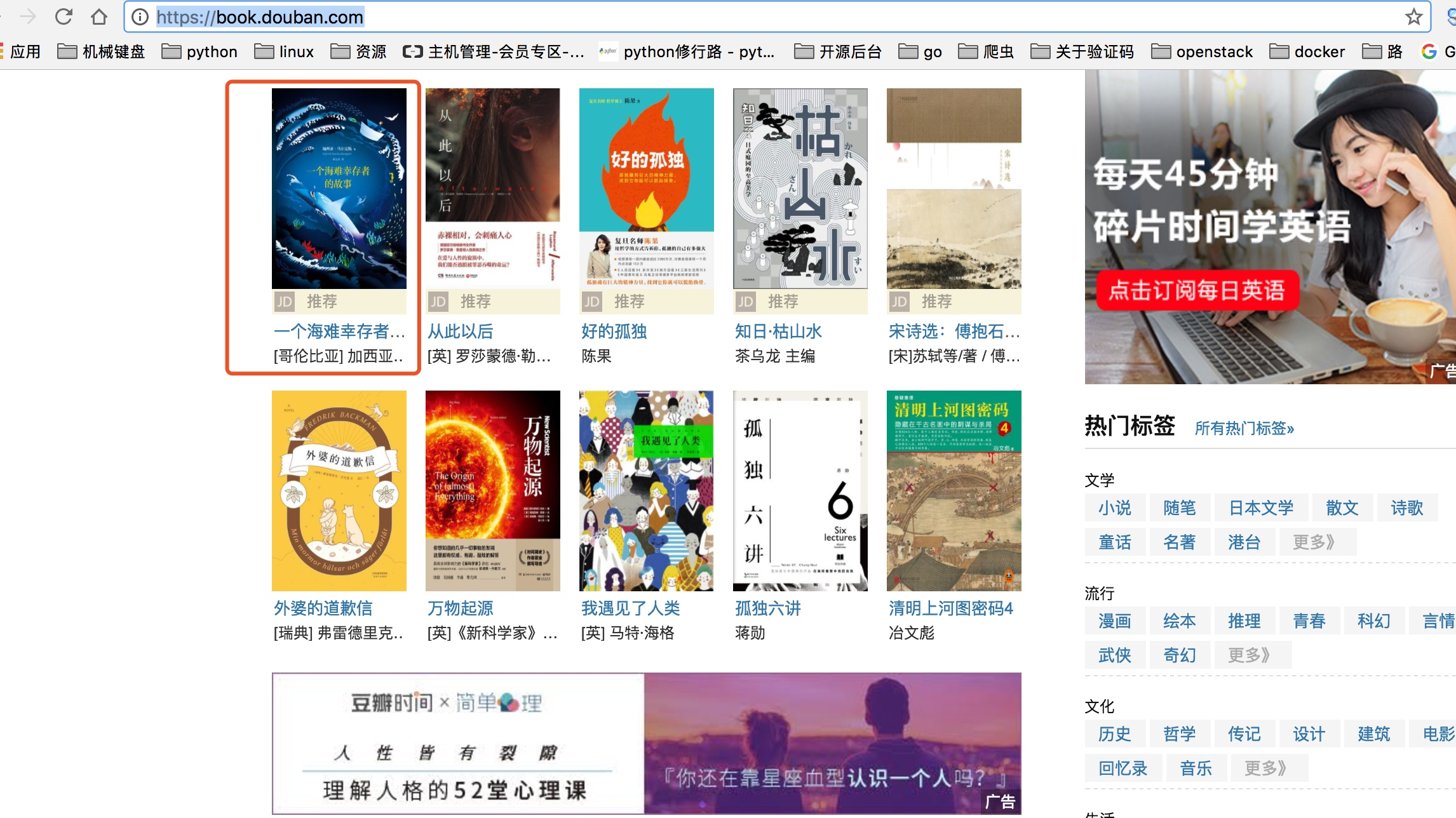
import requests
import re
content = requests.get('https://book.douban.com/').text
pattern = re.compile('<li.*?cover.*?href="(.*?)".*?title="(.*?)".*?more-meta.*?author">(.*?)</span>.*?year">(.*?)</span>.*?</li>', re.S)
results = re.findall(pattern, content)
print(results) for result in results:
url,name,author,date = result
author = re.sub('\s','',author)
date = re.sub('\s','',date)
print(url,name,author,date)
结果:

Python入妖5-----正则的基本使用的更多相关文章
- Python入妖4-----Request库的基本使用
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- Python入门神图
国外某小哥制作的Python入门神图
- 【ZZ】Python入门神图
http://mp.weixin.qq.com/s?__biz=MzA3OTIxNTA0MA==&mid=401383338&idx=1&sn=73009cce06d58656 ...
- python——re模块(正则表达)
python——re模块(正则表达) 两个比较不错的正则帖子: http://blog.csdn.net/riba2534/article/details/54288552 http://blog.c ...
- 【python】版本35 正则-非库-爬虫-读写xlw文件
#交代:代码凌乱,新手一个,论坛都是高手,我也是鼓了很大勇气,发出来就是被批评和进步的 #需求:需要对某网站的某id子标签批量爬取,每个网页的id在xlw里,爬取完,再批量存取到这xlw里的第6行 ...
- <automate the boring stuff with python>---第七章 正则实例&正则贪心&匹配电话号码和邮箱
第七章先通过字符串查找电话号码,比较了是否使用正则表达式程序的差异,明显正则写法更为简洁.易扩展.模式:3 个数字,一个短横线,3个数字,一个短横线,再是4 个数字.例如:415-555-4242 i ...
- [Python基础知识]正则
import re str4 = r"^http://qy.chinahr.com/cvm/preview\?cvid=\w{24,25}&from=sou>id=\w{ ...
- Python使用re模块正则式的预编译及pickle方案
项目上线要求当中有言论和昵称的过滤需求, 客户端使用的是python脚本, python脚本中直接利用re模块来进行正则匹配, 一开始的做法是开启游戏后, 每帧编译2条正则式, 无奈运营需求里面100 ...
- 「Python」数据清洗常用正则
对爬虫数据进行自然语言清洗时用到的一些正则表达式 标签中的所有属性匹配(排除src,href等指定参数) 参考链接 # \b(?!src|href)\w+=[\'\"].*?[\'\&quo ...
随机推荐
- SpringBoot04 日志框架之Logback
1 日志框架选择 日志门面:SLF4J 日志实现:Logback 2 实现控制台的日志打印输出01 2.1 在需要实现日志信息打印的类中实例化Logger对象 坑01:springBoot项目默认使用 ...
- 算法Sedgewick第四版-第1章基础-003一封装日期
1. package ADT; import algorithms.util.StdOut; /**************************************************** ...
- WarTransportation TopCoder - 8404
传送门 分析 我们高兴的发现数据范围特别小,所以我们可以随便搞.因为一共只砍掉一条路,所以我们先算出对于任意一个点如果将它的出边割掉一条则它到达终点的最坏情况的最短距离是多少,然后我们从终点向起点反着 ...
- SDUT 3342 数据结构实验之二叉树三:统计叶子数
数据结构实验之二叉树三:统计叶子数 Time Limit: 1000MS Memory Limit: 65536KB Submit Statistic Problem Description 已知二叉 ...
- Java之命令模式(Command Pattern)
转自:http://www.cnblogs.com/devinzhang/archive/2012/01/06/2315235.html 1.概念 将来自客户端的请求传入一个对象,从而使你可用不同的请 ...
- HTTP 协议 -- 状态码
HTTP 协议状态码(Http Status Code) 使用ASP.NET/PHP/JSP 或者javascript都会用到http的不同状态,一些常见的状态码为: 200 – 服务器成功返回网页 ...
- 入门GitHub
Step 1: 创建一个我们自己的账号 我们先登录https://github.com,然后单击sign up for Github,我们输入用户名,密码和邮箱就可以有一个 属于我们自己的Github ...
- #学习笔记# VALSE 2019.01.09 朱俊彦 --- Learning to Synthesize Images, Videos, and 3D Objects
视频类型:VALSE-webinar 报告时间:2019年01月09日 报告人:MIT朱俊彦 报告题目:Learning to Synthesize Images, Videos, and 3D Ob ...
- STL_ALGORITHM_H
sort_unique_copy /////////////////////////////////////////////////////////// // Copyright (c) 2013, ...
- 快速莫比乌斯变换(FMT)
快速莫比乌斯变换(FMT) 原文出处:虞大的博客.此仅作蒟蒻本人复习用~ 给定两个长度为n的序列 \(a_0, a_1, \cdots, a_{n-1}\)和\(b_0, b_1, \cdots, b ...