关于spark RDD trans action算子、lineage、宽窄依赖详解
这篇文章想从spark当初设计时为何提出RDD概念,相对于hadoop,RDD真的能给spark带来何等优势。之前本想开篇是想总体介绍spark,以及环境搭建过程,但个人感觉RDD更为重要
铺垫
- 在hadoop中一个独立的计算,例如在一个迭代过程中,除可复制的文件系统(HDFS)外没有提供其他存储的概念,这就导致在网络上进行数据复制而增加了大量的消耗,而对于两个的MapReduce作业之间数据共享只有一个办法,就是将其写到一个稳定的外部存储系统,如分布式文件系统。这会引入数据备份、磁盘I/O以及序列化,这些都会引起大量的开销,从而占据大部分的应用执行时间。所以我们发现如果在计算过程中如能共享数据,那将会降低集群开销同时还能减少任务执行时间。
- 而 spark中的RDDs让用户可以直接控制数据的共享。RDD具有可容错和并行数据结构特征,可以指定数据存储到硬盘还是内存、控制数据的分区方法并在数据集上进行种类丰富的操作。
- 目前提出的基于集群的内存存储抽象,比如分布式共享内存(Distributed Shared Memory|DSM),键-值存储(Key-Value|Nosql),数据库(RDBMS)等提供了一个对内部状态基于细粒度更新的接口(例如,表格里面的单元)。而这样设计,提供容错性的方法:在主机之间复制数据,或者对各主机的更新情况做日志记录。但这两种方法对于数据密集型的任务来说代价很高,因为它们需要在带宽远低于内存的集群网络间拷贝大量的数据,同时还将产生大量的存储开销。但RDD提供一种基于粗粒度变换(如 map,filter,join)的接口,该接口会将相同的操作应用到多个数据集上。这使得他们可以通过记录用来创建数据集的变换(lineage),而不需存储真正的数据,进而达到高效的容错性。当一个RDD的某个分区丢失的时候,RDD记录有足够的信息记录其如何通过其他的RDD进行计算,且只需重新计算该分区。因此,丢失的数据可以被很快的恢复,而不需要昂贵的复制代价。
主角
首先我们来思考一个问题吧:Spark的计算模型是如何做到并行的呢?如果你有一箱香蕉,让三个人拿回家吃完(好吧,我承认我爱吃香蕉,哈哈),如果不拆箱子就会很麻烦对吧,哈哈,一个箱子嘛,当然只有一个人才能抱走了。这时候智商正常的人都知道要把箱子打开,倒出来香蕉,分别拿三个小箱子重新装起来,然后,各自抱回家去啃吧。
Spark和很多其他分布式计算系统都借用了这种思想来实现并行:把一个超大的数据集,切分成N个小堆,找M个执行器(M < N),各自拿一块或多块数据慢慢玩,玩出结果了再收集在一起,这就算执行完啦。那么Spark做了一项工作就是:凡是能够被我算的,都是要符合我的要求的,所以spark无论处理什么数据先整成一个拥有多个分块的数据集再说,这个数据集就叫RDD。
好了,那现在就详细介绍下RDD吧
1.概念
RDD(Resilient Distributed Datasets,弹性分布式数据集)是一个分区的只读记录的集合。RDD只能通过在稳定的存储器或其他RDD的数据上的确定性操作来创建。我们把这些操作称作变换以区别其他类型的操作。例如 map,filter和join。
RDD在任何时候都不需要被”物化”(进行实际的变换并最终写入稳定的存储器上)。实际上,一个RDD有足够的信息描述着其如何从其他稳定的存储器上的数据生成。它有一个强大的特性:从本质上说,若RDD失效且不能重建,程序将不能引用该RDD。而用户可以控制RDD的其他两个方面:持久化和分区。用户可以选择重用哪个RDD,并为其制定存储策略(比如,内存存储)。也可以让RDD中的数据根据记录的key分布到集群的多个机器。 这对位置优化来说是有用的,比如可用来保证两个要jion的数据集都使用了相同的哈希分区方式。
2.spark 编程接口
对编程人员通过对稳定存储上的数据进行变换操作(如map和filter).而得到一个或多个RDD。然后可以调用这些RDD的actions(动作)类的操作。这类操作的目是返回一个值或是将数据导入到存储系统中。动作类的操作如count(返回数据集的元素数),collect(返回元素本身的集合)和save(输出数据集到存储系统)。spark直到RDD第一次调用一个动作时才真正计算RDD。
还可以调用RDD的persist(持久化)方法来表明该RDD在后续操作中还会用到。默认情况下,spark会将调用过persist的RDD存在内存中。但若内存不足,也可以将其写入到硬盘上。通过指定persist函数中的参数,用户也可以请求其他持久化策略(如Tachyon)并通过标记来进行persist,比如仅存储到硬盘上或是在各机器之间复制一份。最后,用户可以在每个RDD上设定一个持久化的优先级来指定内存中的哪些数据应该被优先写入到磁盘。
PS:
缓存有个缓存管理器,spark里被称作blockmanager。注意,这里还有一个误区是,很多初学的同学认为调用了cache或者persist的那一刻就是在缓存了,这是完全不对的,真正的缓存执行指挥在action被触发。
说了一大堆枯燥的理论,我用一个例子来解释下吧:
现在数据存储在hdfs上,而数据格式以“;”作为每行数据的分割:
"age";"job";"marital";"education";"default";"balance";"housing";"loan"
30;"unemployed";"married";"primary";"no";1787;"no";"no"
33;"services";"married";"www.jxbaxi.com/ secondary";"no";4789;"yes";"yes"scala代码如下:
//1.定义了以一个HDFS文件(由数行文本组成)为基础的RDD
val lines = sc.textFile("/data/spark/bank/bank.csv")
//2.因为首行是文件的标题,我们想把首行去掉,返回新RDD是withoutTitleLines
val withoutTitleLines = lines.filter(!_.www.vboyl130.cn contains("age"))
//3.将每行数据以;分割下,返回名字是lineOfData的新RDD
val lineOfData = withoutTitleLines.map(_.www.089188.cn/ www.feifanyule.cn split(";"))
//4.将lineOfData缓存到内存到,并设置缓存名称是lineOfData
lineOfData.setName("lineOfData")
lineOfData.persist
//5.获取大于30岁的数据,返回新RDD是gtThirtyYearsData
val gtThirtyYearsData = lineOfData.filter(line => line(0).toInt > 30)
//到此,集群上还没有工作被执行。但是,用户现在已经可以在动作(action)中使用RDD。
//计算大于30岁的有多少人
gtThirtyYearsData.count
//返回结果是3027OK,我现在要解释两个概念NO.1 什么是lineage?,NO.2 transformations 和 actions是什么?
lineage:
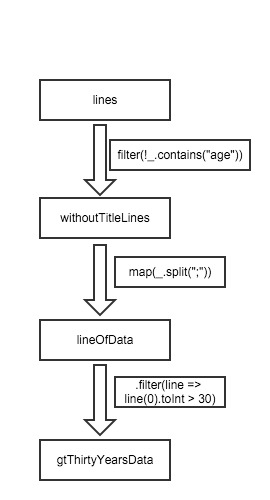
在上面查询大于30岁人查询里,我们最开始得出去掉标题行所对应的RDD lines,即为withTitleLines,接着对withTitleLines进行map操作分割每行数据内容,之后再次进行过滤age大于30岁的人、最后进行count(统计所有记录)。Spark的调度器会对最后的那个两个变换操作流水线化,并发送一组任务给那些保存了lineOfData对应的缓存分区的节点。另外,如果lineOfData的某个分区丢失,Spark将只在该分区对应的那些行上执行原来的split操作即可恢复该分区。
所以在spark计算时,当前RDD不可用时,可以根据父RDD重新计算当前RDD数据,但如果父RDD不可用时,可以可以父RDD的父RDD重新计算父RDD。
transformations 和 actions
transformations操作理解成一种惰性操作,它只是定义了一个新的RDD,而不是立即计算它。相反,actions操作则是立即计算,并返回结果给程序,或者将结果写入到外存储中。
下面我以示例解释下:
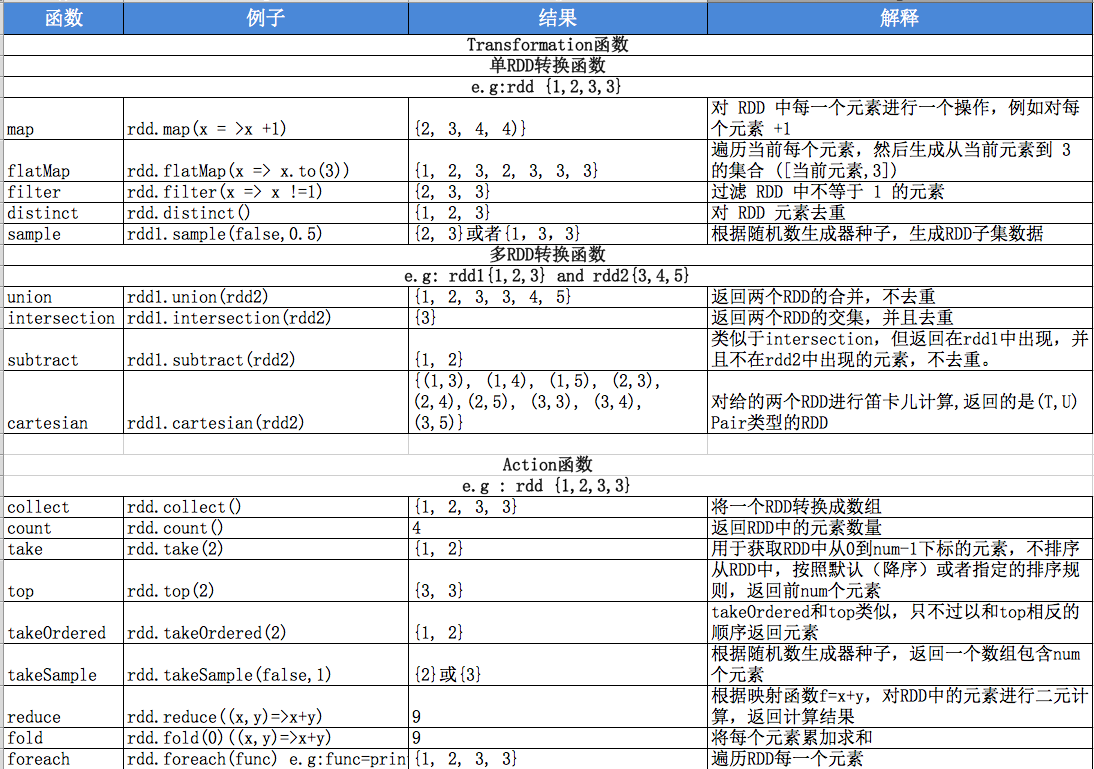
先简单介绍这些吧,稍后文章我会详细介绍每个方法的使用,感兴趣可以看spark官方文档
3.RDDs接口5个特性
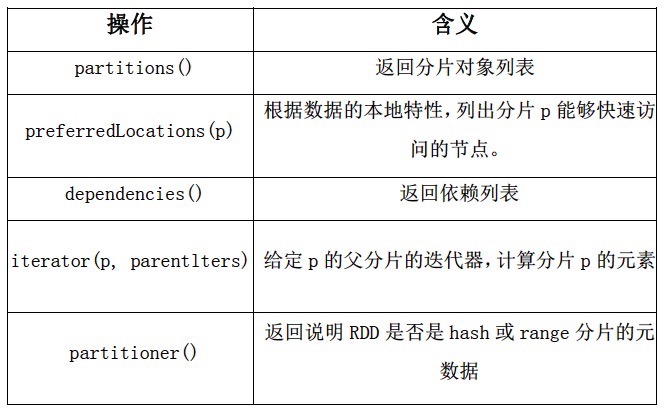
简单概括为:一组分区,他们是数据集的最小分片;一组 依赖关系,指向其父RDD;一个函数,基于父RDD进行计算;以及划分策略和数据位置的元数据。例如:一个表现HDFS文件的RDD将文件的每个文件块表示为一个分区,并且知道每个文件块的位置信息。同时,对RDD进行map操作后具有相同的划分。当计算其元素时,将map函数应用于父RDD的数据。
4.RDDs依赖关系
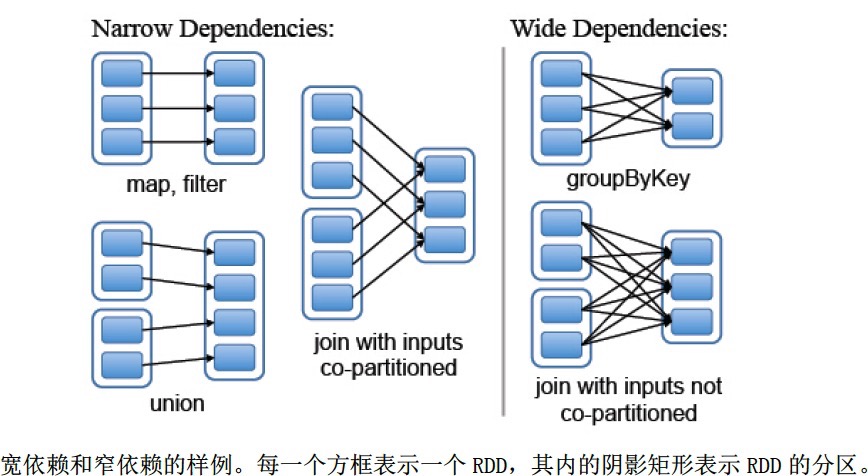
- 在spark中如何表示RDD之间的依赖关系分为两类:
窄依赖:每个父RDD的分区都至多被一个子RDD的分区使用,即为OneToOneDependecies;
宽依赖:多个子RDD的分区依赖一个父RDD的分区,即为OneToManyDependecies。
例如,map操作是一种窄依赖,而join操作是一种宽依赖(除非父RDD已经基于Hash策略被划分过了) - 详细介绍:
首先,窄依赖允许在单个集群节点上流水线式执行,这个节点可以计算所有父级分区。例如,可以逐个元素地依次执行filter操作和map操作。相反,宽依赖需要所有的父RDD数据可用并且数据已经通过类MapReduce的操作shuffle完成。
其次,在窄依赖中,节点失败后的恢复更加高效。因为只有丢失的父级分区需要重新计算,并且这些丢失的父级分区可以并行地在不同节点上重新计算。与此相反,在宽依赖的继承关系中,单个失败的节点可能导致一个RDD的所有先祖RDD中的一些分区丢失,导致计算的重新执行。
对于hdfs:HDFS文件作为输入RDD。对于这些RDD,partitions代表文件中每个文件块的分区(包含文件块在每个分区对象中的偏移量),preferredLocations表示文件块所在的节点,而iterator读取这些文件块。
对于map:在任何一个RDD上调用map操作将返回一个MappedRDD对象。这个对象与其父对象具有相同的分区以及首选地点(preferredLocations),但在其迭代方法(iterator)中,传递给map的函数会应用到父对象记录。
再一个经典的RDDs依赖图吧
5.作业调度
当用户对一个RDD执行action(如count 或save)操作时, 调度器会根据该RDD的lineage,来构建一个由若干阶段(stage) 组成的一个DAG(有向无环图)以执行程序,如下图所示。
每个stage都包含尽可能多的连续的窄依赖型转换。各个阶段之间的分界则是宽依赖所需的shuffle操作,或者是DAG中一个经由该分区能更快到达父RDD的已计算分区。之后,调度器运行多个任务来计算各个阶段所缺失的分区,直到最终得出目标RDD。
调度器向各机器的任务分配采用延时调度机制并根据数据存储位置(本地性)来确定。若一个任务需要处理的某个分区刚好存储在某个节点的内存中,则该任务会分配给那个节点。否则,如果一个任务处理的某个分区,该分区含有的RDD提供较佳的位置(例如,一个HDFS文件),我们把该任务分配到这些位置。
“对应宽依赖类的操作 {比如 shuffle依赖),会将中间记录物理化到保存父分区的节点上。这和MapReduce物化Map的输出类似,能简化数据的故障恢复过程。
对于执行失败的任务,只要它对应stage的父类信息仍然可用,它便会在其他节点上重新执行。如果某些stage变为不可用(例如,因为shuffle在map阶段的某个输出丢失了),则重新提交相应的任务以并行计算丢失的分区。
若某个任务执行缓慢 (即”落后者”straggler),系统则会在其他节点上执行该任务的拷贝,这与MapReduce做法类似,并取最先得到的结果作为最终的结果。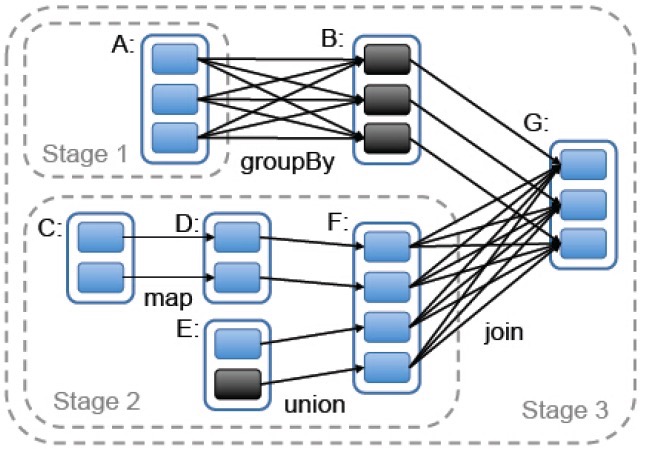
实线圆角方框标识的是RDD。阴影背景的矩形是分区,若已存于内存中则用黑色背景标识。RDD G 上一个action的执行将会以宽依赖为分区来构建各个stage,对各stage内部的窄依赖则前后连接构成流水线。在本例中,stage 1 的输出已经存在RAM中,所以直接执行 stage 2 ,然后stage 3。
6.内存管理
Spark提供了三种对持久化RDD的存储策略:未序列化Java对象存于内存中、序列化后的数据存于内存及磁盘存储。第一个选项的性能表现是最优秀的,因为可以直接访问在JAVA虚拟机内存里的RDD对象。在空间有限的情况下,第二种方式可以让用户采用比JAVA对象图更有效的内存组织方式,代价是降低了性能。第三种策略适用于RDD太大难以存储在内存的情形,但每次重新计算该RDD会带来额外的资源开销。
对于有限可用内存,Spark使用以RDD为对象的LRU回收算法来进行管理。当计算得到一个新的RDD分区,但却没有足够空间来存储它时,系统会从最近最少使用的RDD中回收其一个分区的空间。除非该RDD便是新分区对应的RDD,这种情况下,Spark会将旧的分区继续保留在内存,防止同一个RDD的分区被循环调入调出。因为大部分的操作会在一个RDD的所有分区上进行,那么很有可能已经存在内存中的分区将会被再次使用。
7.检查点支持(checkpoint)
虽然lineage可用于错误后RDD的恢复,但对于很长的lineage的RDD来说,这样的恢复耗时较长。因此,将某些RDD进行检查点操作(Checkpoint)保存到稳定存储上,是有帮助的。
通常情况下,对于包含宽依赖的长血统的RDD设置检查点操作是非常有用的,在这种情况下,集群中某个节点的故障会使得从各个父RDD得出某些数据丢失,这时就需要完全重算。相反,对于那些窄依赖于稳定存储上数据的RDD来说,对其进行检查点操作就不是有必要的。如果一个节点发生故障,RDD在该节点中丢失的分区数据可以通过并行的方式从其他节点中重新计算出来,计算成本只是复制整个RDD的很小一部分。
Spark当前提供了为RDD设置检查点(用一个REPLICATE标志来持久化)操作的API,让用户自行决定需要为哪些数据设置检查点操作。
最后,由于RDD的只读特性使得比常用的共享内存更容易做checkpoint,因为不需要关心一致性的问题,RDD的写出可在后台进行,而不需要程序暂停或进行分布式快照。
序幕
好了,讲了一大堆RDD理论上概念,现在,问问自己什么是RDD呢?我用最简单几句话概括下吧。
RDD是spark的核心,也是整个spark的架构基础,RDD是弹性分布式集合(Resilient Distributed Datasets)的简称,是分布式只读且已分区集合对象。这些集合是弹性的,如果数据集一部分丢失,则可以对它们进行重建。具有自动容错、位置感知调度和可伸缩性,而容错性是最难实现的,大多数分布式数据集的容错性有两种方式:数据检查点和记录数据的更新。对于大规模数据分析系统,数据检查点操作成本高,主要原因是大规模数据在服务器之间的传输带来的各方面的问题,相比记录数据的更新,RDD也只支持粗粒度的转换,也就是记录如何从其他RDD转换而来(即lineage),以便恢复丢失的分区。
简而言之,特性如下:
1. 数据结构不可变
2. 支持跨集群的分布式数据操作
3. 可对数据记录按key进行分区
4. 提供了粗粒度的转换操作
5. 数据存储在内存中,保证了低延迟性
由于篇幅有限,我就介绍这些吧~,下篇整体介绍下spark架构&spark环境搭建&测试
关于spark RDD trans action算子、lineage、宽窄依赖详解的更多相关文章
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- 58、Spark Streaming: DStream的output操作以及foreachRDD详解
一.output操作 1.output操作 DStream中的所有计算,都是由output操作触发的,比如print().如果没有任何output操作,那么,压根儿就不会执行定义的计算逻辑. 此外,即 ...
- [spark]-Spark2.x集群搭建与参数详解
在前面的Spark发展历程和基本概念中介绍了Spark的一些基本概念,熟悉了这些基本概念对于集群的搭建是很有必要的.我们可以了解到每个参数配置的作用是什么.这里将详细介绍Spark集群搭建以及xml参 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 对于maven创建spark项目的pom.xml配置文件(图文详解)
不多说,直接上干货! http://mvnrepository.com/ 这里,怎么创建,见 Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版 ...
- Spark Sort-Based Shuffle具体实现内幕和源码详解
为什么讲解Sorted-Based shuffle?2方面的原因:一,可能有些朋友看到Sorted-Based Shuffle的时候,会有一个误解,认为Spark基于Sorted-Based Shuf ...
- Dynamic CRM 2013学习笔记(三十八)流程1 - 操作(action)开发与配置详解
CRM 2013 里流程有4个类别:操作(action).业务流程(business process flow).对话(dialog)和工作流(workflow).它们都是从 setting –> ...
- Spark Shell启动时遇到<console>:14: error: not found: value spark import spark.implicits._ <console>:14: error: not found: value spark import spark.sql错误的解决办法(图文详解)
不多说,直接上干货! 最近,开始,进一步学习spark的最新版本.由原来经常使用的spark-1.6.1,现在来使用spark-2.2.0-bin-hadoop2.6.tgz. 前期博客 Spark ...
- Spark Structured Streaming框架(4)之窗口管理详解
1. 结构 1.1 概述 Structured Streaming组件滑动窗口功能由三个参数决定其功能:窗口时间.滑动步长和触发时间. 窗口时间:是指确定数据操作的长度: 滑动步长:是指窗口每次向前移 ...
随机推荐
- spring-mybatis整合项目 异常处理
java.lang.reflect.InvocationTargetException at java.base/jdk.internal.reflect.NativeMethodAccessorIm ...
- 腾讯云负载均衡CLB
负载均衡 使用场景: ①购买一个负载均衡LB实例 ②一级.二级域名都解析到VIP上 ③创建HTTP/HTTPS监听器 ④绑定云主机 在nginx中只需要配置好伪静态和相关设置就ok了
- Linux apt & yum 及 常用命令
yum yum 语法 yum [options] [command] [package ...] options:可选,选项包括-h(帮助),-y(当安装过程提示选择全部为"yes" ...
- 39条常见的Linux系统简单面试题
39条常见的Linux系统简单面试题 本文主要分享39条常见的Linux系统简单面试题,其中包括如何看当前Linux系统有几颗物理CPU和每颗CPU的核数.如何实时查看网卡流量为多少等等,希望对你有所 ...
- 《Redis设计与实现》- 复制
在分布式系统中为了解决单点问题,通常会把数据复制多个副本部署到其他机器,满足故障恢复和负载均衡灯需求.Redis提供了复制功能,实现了相同数据多个副本,复制功能作是高可用Redis的基础,深入理解复制 ...
- 《Redis设计与实现》- RDB持久化
Redis RDB持久化功能可以将Redis内存中的数据库状态保存到磁盘里面,避免数据意外丢失. 1. 手动生成 RDB 文件 有两个Redis命令可以用于生成RDB文件: SAVE,该命令会阻塞Re ...
- iOS-修改modal出来的控制器的大小
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{ static BOOL sh ...
- 003---wsgi和wsgiref模块
WSGI: 全称:Web Server Gatway Interface ,web服务网关接口,独立的,与django无关,他们俩只是遵循一个约定,是一个协议. wsgiref模块: 实现了WSGI协 ...
- 关于原生JS获取class,ID等属性的一些封装
一.传统上获取是通过document.getElementById获取元素的ID属性,通过总结与学习总结一下获取元素class以及id属性的一些封装; 1.创建构造函数,这里面不需要多解释什么:(主要 ...
- Android面试收集录16 Android动画总结
一.Android 动画分类 总的来说,Android动画可以分为两类,最初的传统动画和Android3.0 之后出现的属性动画: 传统动画又包括 帧动画(Frame Animation)和补间动画( ...