scrapy--json(喜马拉雅Fm)(二)
学习了对数据的储存,感觉还不够深入,昨天开始对储存数据进行提取、整合和图像化显示。实例还是喜马拉雅Fm,算是对之前数据爬取之后的补充。
明确需要解决的问题
- 1,蕊希电台全部作品的进行储存 --scrapy爬取:作品id(trackid),作品名称(title),播放量playCount
- 2,储存的数据进行提取,整合 --pandas运用:提取出trackid,playCount;对播放量进行排序,找出最高播放量(palyCount)的作品
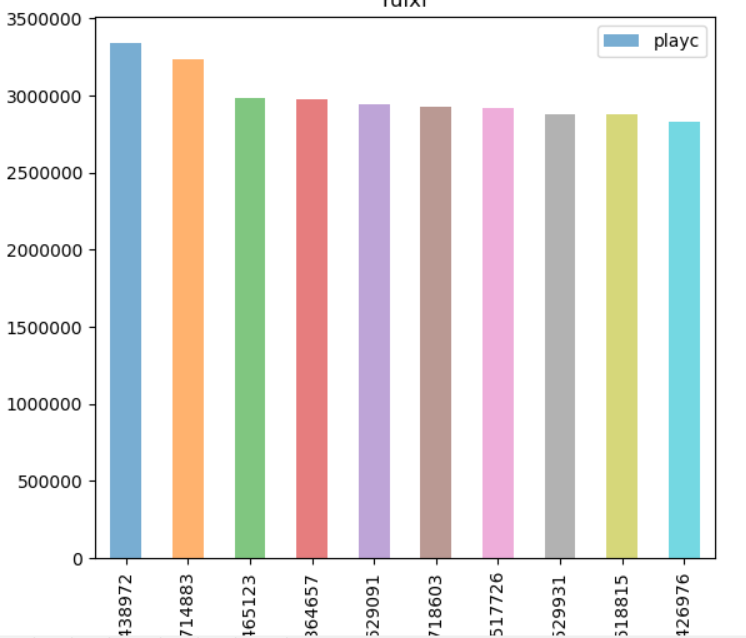
- 3.整合的数据图像化显示 --matplotlib图像化,清楚的查看哪些作品最受欢迎:trackid作为x轴,播放量(playCount)作为y轴
三、给大家看下成果
3.1_蕊希电台所有作品数(369)
3.2_全部储存到mongoDB数据库

3.3_导出csv文件:mongoexport -d ruixi -c ruixi -f trackid,playc --csv -o Desktop\ruixi.csv
3.4_图像化显示
二、items.py,middlewares.py就不讲了,可以看我之前的博客;重点说一下其他3个文件
2.1_爬虫文件:spiders/ruixi.py
- # -*- coding: utf-8 -*-
- import scrapy
- from Ruixi.items import RuixiItem
- import json
- from Ruixi.settings import USER_AGENT
- import re
- class RuixiSpider(scrapy.Spider):
- name = 'ruixi'
- allowed_domains = ['www.ximalaya.com']
- start_urls = ['https://www.ximalaya.com/revision/track/trackPageInfo?trackId=129503750']
- def parse(self, response):
- ruixi = RuixiItem()
- #使用json,提取需要文件
- ruixi['trackid'] = json.loads(response.body)['data']['trackInfo']['trackId']
- ruixi['title'] = json.loads(response.body)['data']['trackInfo']['title']
- ruixi['playc'] = json.loads(response.body)['data']['trackInfo']["playCount"]
- yield ruixi
- #对当前页面的trackid进行提取,生成新的url,跳转至下一链接,继续提取
- for each_item in json.loads(response.body)['data']["moreTracks"]:
- each_trackid = each_item['trackId']
- new_url = 'https://www.ximalaya.com/revision/track/trackPageInfo?trackId=' + str(each_trackid)
- yield scrapy.Request(new_url,callback=self.parse)
2.2_管道文件配置:pipelines.py
- # -*- coding: utf-8 -*-
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
- import scrapy
- import pymongo
- from scrapy.item import Item
- from scrapy.exceptions import DropItem
- import codecs
- import json
- from openpyxl import Workbook
- #储存之前,进行去重处理
- class DuplterPipeline():
- def __init__(self):
- self.set = set()
- def process_item(self,item,spider):
- name = item['trackid']
- if name in self.set():
- raise DropItem('Dupelicate the items is%s' % item)
- self.set.add(name)
- return item
- class RuixiPipeline(object):
- def process_item(self, item, spider):
- return item
- #存储到mongodb中
- class MongoDBPipeline(object):
- @classmethod
- def from_crawler(cls,crawler):
- cls.DB_URL = crawler.settings.get("MONGO_DB_URL",'mongodb://localhost:27017/')
- cls.DB_NAME = crawler.settings.get("MONGO_DB_NAME",'scrapy_data')
- return cls()
- def open_spider(self,spider):
- self.client = pymongo.MongoClient(self.DB_URL)
- self.db = self.client[self.DB_NAME]
- def close_spider(self,spider):
- self.client.close()
- def process_item(self,item,spider):
- collection = self.db[spider.name]
- post = dict(item) if isinstance(item,Item) else item
- collection.insert(post)
- return item
- #储存至.Json文件
- class JsonPipeline(object):
- def __init__(self):
- self.file = codecs.open('data_cn.json', 'wb', encoding='gb2312')
- def process_item(self, item, spider):
- line = json.dumps(dict(item)) + '\n'
- self.file.write(line.decode("unicode_escape"))
- return item
- #储存至.xlsx文件
- class XlsxPipeline(object): # 设置工序一
- def __init__(self):
- self.wb = Workbook()
- self.ws = self.wb.active
- def process_item(self, item, spider): # 工序具体内容
- line = [item['trackid'], item['title'], item['playc']] # 把数据中每一项整理出来
- self.ws.append(line) # 将数据以行的形式添加到xlsx中
- self.wb.save('ruixi.xlsx') # 保存xlsx文件
- return item
2.3_设置文件:settings.py
- MONGO_DB_URL = 'mongodb://localhost:27017/'
- MONGO_DB_NAME = 'ruixi'
- FEED_EXPORT_ENCODING = 'utf-8'
- USER_AGENT =[ #设置浏览器的User_agent
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
- "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
- "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
- "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
- "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
- "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
- "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
- "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
- "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
- ]
- FEED_EXPORT_FIELDS = ['trackid','title','playc']
- ROBOTSTXT_OBEY = False
- CONCURRENT_REQUESTS = 10
- DOWNLOAD_DELAY = 0.5
- COOKIES_ENABLED = False
- # Crawled (400) <GET https://www.cnblogs.com/eilinge/> (referer: None)
- DEFAULT_REQUEST_HEADERS =
{
'User-Agent': random.choice(USER_AGENT),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}- DOWNLOADER_MIDDLEWARES =
{- 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':543,
- 'Ruixi.middlewares.RuixiSpiderMiddleware': 144,
- }
- ITEM_PIPELINES =
{- 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':1,
- 'Ruixi.pipelines.DuplterPipeline': 290,
- 'Ruixi.pipelines.MongoDBPipeline': 300,
- 'Ruixi.pipelines.JsonPipeline':301,
- 'Ruixi.pipelines.XlsxPipeline':302,
- }
2.4_生成报表
- #-*- coding:utf-8 -*-
- import matplotlib as mpl
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import pdb
- df = pd.read_csv("ruixi.csv")
- df1= df.sort_values(by='playc',ascending=False)
- df2 = df1.iloc[:10,:]
- df2.plot(kind='bar',x='trackid',y='playc',alpha=0.6)
plt.xlabel("trackId")
plt.ylabel("playc")
plt.title("ruixi")
plt.show()
scrapy--json(喜马拉雅Fm)(二)的更多相关文章
- scrapy--json(喜马拉雅Fm)
已经开始听喜马拉雅Fm电台有2个月,听里面的故事,感觉能听到自己,特别是蕊希电台,始于声音,陷于故事,忠于总结.感谢喜马拉雅Fm陪我度过了这2个月,应该是太爱了,然后就开始对Fm下手了.QAQ 该博客 ...
- 喜马拉雅FM抓包之旅
一.概述 最近学院组织安排大面积实习工作,今天刚刚发布了喜马拉雅FM实习生招聘的面试通知.通知要求:公司采用开放式题目的方式进行筛选,申请的同学须完成如下题目 写程序输出喜马拉雅FM上与"卓 ...
- [HMLY]5.模仿喜马拉雅 FM
项目介绍: 文:HansRove(github)XiMaLaYa-by-HansRove- 仿做喜马拉雅, 对AVFoundation框架的一次尝试 软件环境: iOS9.1硬件环境: Mac O ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy基本使用(二)
scrapy基本使用(二) 参考链接: http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html#id5 scrapy基本使用(一 ...
- 喜马拉雅FM接入
最近有考虑接入,但是一方面由于沟通不畅等,另一方面没有浏览开发者协议,品牌规范等,多走了很多弯路,所以记下接入的注意事项和关键点 一. 接入前准备工作 喜马拉雅FM开放平台地址:http://open ...
- iOS涂色涂鸦效果、Swift仿喜马拉雅FM、抽屉转场动画、拖拽头像、标签选择器等源码
iOS精选源码 LeeTagView 标签选择控件 为您的用户显示界面添加美观的加载视图 Swift4: 可拖动头像,增加物理属性 Swift版抽屉效果,自定义转场动画管理器 Swift 仿写喜马拉雅 ...
- iOS仿喜马拉雅FM做的毕业设计及总结(含新手福利源码)
其实仿喜马拉雅FM很早就开始了,从我刚接触iOS开始,就开始仿做了一部分,眼尖的人都从我的github找到了那个项目.随着找到实习iOS工作,仿写就落下了,但唯一的收获就是给过去打了一个响亮的耳光,因 ...
- JY播放器【喜马拉雅FM电脑端,附带下载功能】
今天给大家带来一款神器----JY播放器.可以不用打开网页就在电脑端听喜马拉雅FM的节目,而且可以直接下载,对于我这种强迫症患者来说真的是神器.我是真的不喜欢电脑任务栏上面密密麻麻的. 目前已经支持平 ...
随机推荐
- SQL Server 创建用户
增加角色 role_for_nc 1.exec sp_addrole 'role_for_nc'; 创建一个 SQL Server 登录名wlzx,密码为"123",默认数据库为 ...
- XtraReport三动态数据绑定
代码还用上一节的,把Report的Datasource去掉.各个绑定的字段也去掉,有了第二节的基础,现在看这个就不难了,无非就是传到report一个数据集,在把这个数据集绑定到各控件里 清空detai ...
- Redis入门--(二)Redis的概述
1.Redis的由来 创始人觉得Mysql不好用,就自己写了: 国内使用Redis的网站有新浪微博,知乎: 国外GitHub: VMWare也支持redis的开发 2.Redis的概述 官方提供的测试 ...
- 计算Sn
求Sn=a+aa+aaa+…+aa…aaa(有n个a)之值,其中a是一个数字. 例如:2+22+222+2222+22222(n=5), 输入 输入两个数.第一个为a ,第二个为n(表示有多少个数相加 ...
- 如何查询mysql中date类型的时间范围记录?
java date类型 会不会自动转换 mysql date类型? 抹除掉后面 时间 ? 时间不是查询条件?
- 2018.9.8pat秋季甲级考试
第一次参加pat考试,结果很惨,只做了中间两道题,还有一个测试点错误,所以最终只得了不到50分.题目是甲级练习题的1148-1151. 考试时有些紧张,第一题第二题开始测试样例都运行不正确,但是调试程 ...
- 特殊矩阵的压缩存储(转自chunlanse2014)
对称矩阵 对于一个矩阵结构显然用一个二维数组来表示是非常恰当的,但在有些情况下,比如常见的一些特殊矩阵,如三角矩阵.对称矩阵.带状矩阵.稀疏矩阵等,从节约存储空间的角度考虑,这种存储是不太合适的.下面 ...
- VR社交软件测试-AltspaceVR
该VR社交软件中的主界面主要分为,Events:事件:Activities:多人游戏:Words:别人创建的虚拟世界.进入游戏后可以进入场景与世界各地的人进行交谈,以虚拟3D人物的方式显示用户,具有较 ...
- Axure 8 Tab制作
1 在[页面]面板中选中[page1] 2 在[元件库]中选中[动态面板],并拖拽到[设计区域]中 3 双[设计区域]中的动态面板,打开[动态面板管理]页面 4 在[动态面板管理]页面中输入动态面板的 ...
- NutDao配置多数据源
首先,我必须声明,这是一个非常简单的方法,很多小菜没做出来,是因为把nutz想得太复杂 数据源(或者是数据库连接池),在Nutz.Ioc看来,是一个普通的Bean,没任何特别之处. 再强调一点,除了$ ...