爬虫学习(十三)——xpath基础学习
lxml的作用
lxml是HTML、xml的解析器,主要的功能是如何解析和提取HTML和xml数据
lxml和正则一样,也是使用C来实现的,是一款高性能的python HTML/xml解析器,我们可以使用xpath语法快速定位特定元素和节点信息
xpath的介绍
xpath(xml path language)是一门在xml文档之查找信息的语言,可用来在xml文档中对元素和属性进行遍历
路径表达式
最常用的路径表达式:
/ :表示从根节点选取
//:从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置
.:选取当前节点
..:选取当前节点的父节点
@:代表选取属性
常用路径表达式及其表达式结果
/bookstore:选取根元素bookstores,
注释:如果路径起始于正斜杠(/),则此路径始终代表到某元素的绝对路径
bookstore/book:选取属于bookstore的子元素的所有book元素
//book:选取所有book子元素,而不管他们在文档中的位置
bookstores//book:选取属于bookstores元素后代的所有book元素,而不管他们位于bookstores下的什么位置
//@lang:选取说有
谓语限制节点位置
谓语用来查找某个特定的节点,或者包含某个指定值的节点,被嵌在方括号中
xpath的索引是从1开始,切记不是从零开始
/bookstores/book[1]:选取bookstores中子元素的第一个book元素
/bookstores/book[last()]:选取bookstores中子元素的最后一个book元素
/bookstores/book[last-1]:选取bookstores中子元素的倒数第二个book元素
/bookstores/book[position<3]:选取bookstores中子元素的前两个book元素
//title[@lang]:选取所有含有名为lang属性的title元素
//title[@lang="eng"]:选取所有含有名为lang属性且属性值为“eng”的title元素
/bookstores/book[@preice>35.0]:选取bookstores元素的子元素属性price值大于35.0的book元素
/bookstores/book[@price>35.0]/title:选取bookstores元素的子元素属性值price值大于35.0的book元素的子元素title元素
选取未知元素
*:匹配任何元素节点
*@:匹配任何属性节点
/bookstores/*:选取bookstores元素的所有子节点
//*:选取文档中的所有元素
//title[@*]:选取文档中所有带有属性的title元素
选取若干路径
通过在路径表达式中使用“|”运算符,就可以选取若干个路径
//book/title|//book/price:选取子元素节点是price和title的所有book节点的路径
//book|//title:选取文档中所有的book元素和title元素节点
//bookstores/book/title|//price:先去文档中所有bookstores元素的book元素的title元素或是文档中所有的price元素
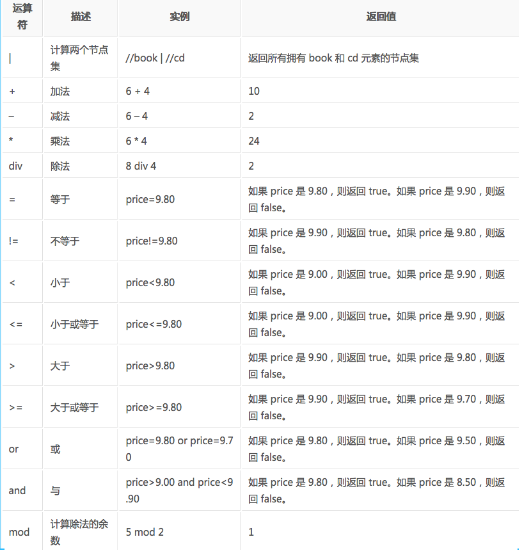
xpath的运算符
from lxml import etree # xml是str类型的数据
xml = '''<div>
<ul>
<li class="item-0">老王买刀<a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
# lxml中的etree的HTML方法是将str类型的数据转换成为HTML对象
tree = etree.HTML(xml)
# lxml中etree的tostring方法是将HTML对象再转换成为字符串,字符串格式是(不带xml申明的阿斯克码),并且在原标签基础上添加了<html>和<body>
print(etree.tostring(tree,encoding="utf8").decode("utf8"))
# 将转化成对象的HTML使用xpath进行解析
info =tree.xpath("./body/div/ul/li")
print(info)
# 使用属性进行限制,找到指定的li,返回的对象是一个列表
print(tree.xpath("//li[@class='item-inactive']/a"))
# 结果:[<Element a at 0x9fe8888>]
# 获取a标签中属性为href的值
print(tree.xpath("//li/a/@href"))
# 获取标签中的内容,使用text()用在路径中,使用text用在标签对象上,此时text变成了标签的属性
print(tree.xpath("//li/text()"))
# 获取标签li中的class属性,使用get()
print(tree.xpath("//div//li")[0].get("class")) # 批量获取标签的属性和标签内容
ret =tree.xpath("//div//li")
ree = [info.get("class") for info in ret ]
rea = [info.text for info in ret]
print(ree)
#输出结果:['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
print(rea)
#输出结果:['老王买刀', None, None, None, None]
xpath使用总结:
查找所有的元素://li
查找所有的属性://div/@href
查找所有的元素值://ul/text()
根据条件进行查找:[@id>="50"] 、[@id="50" and @class="haha"]、[contains(@class,"a")]、//li|//ul 元素e,e.get('attr'),e.text 获取元素的值
爬虫学习(十三)——xpath基础学习的更多相关文章
- [学习线路] 零基础学习hadoop到上手工作线路指导(初级篇)
about云课程最新课程Cloudera课程 零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.在刚接触云计算,曾经想过培训,但是培训机构的选择就让我很纠结.所以索性就自己学习了. ...
- Scala学习(一)--Scala基础学习
Scala基础学习 摘要: 在篇主要内容:如何把Scala当做工业级的便携计算器使用,如何用Scala处理数字以及其他算术操作.在这个过程中,我们将介绍一系列重要的Scala概念和惯用法.同时你还将学 ...
- Xpath基础学习
方法 获取文本 a/text() 获取a标签下的文本 a//text() 获取a标签下所有标签的文本 a[text()='xxx']获取文本为xxx的a标签 @符号 a/@href 获取a标签的hre ...
- java学习路线图-----java基础学习路线图(J2SE学习路线图)
安装JDK和开发软件跳过,网上太多了,不做总结,以下是我总结的学习路线图,欢迎补充. JAVA基础语法 注释,标识符命名规则及Java中的关键字 Java基本数据类型 Java运算符与表达式 Java ...
- Python学习---Django的基础学习
django实现流程 Django学习框架: #安装: pip3 install django 添加环境变量 #1 创建project django-ad ...
- C语言学习second--C语言基础学习
1.标准C语言 C语言诞生于20世纪70年代,年龄比我们自己还要大,期间产生了很多标准,但是各种编译器对标准的支持不尽相同. ANSI C是使用的最广泛的一个标准,也是第一个正式标准,被称为“标准C语 ...
- 零基础学习hadoop到上手工作线路指导(编程篇)
问题导读: 1.hadoop编程需要哪些基础? 2.hadoop编程需要注意哪些问题? 3.如何创建mapreduce程序及其包含几部分? 4.如何远程连接eclipse,可能会遇到什么问题? 5.如 ...
- 零基础学习hadoop到上手工作线路指导(初级篇)
零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.在刚接触云计算,曾经想过培训,但是培训机构的选择就让我很纠结.所以索性就自己学习了.整个过程整理一下,给大家参考,欢迎讨论,共同学习. ...
- Django基础学习二
今天继续学习django的基础 学习用户提交url如何获得返回值 1.首先需要在工程的urls文件定义指定的urls要路由给哪个函数 在这个例子中,我们定义home的urls路由给views里的tes ...
随机推荐
- [Silverlight]调用外部可执行程序
public void InvokeExternalExecutableApp() { if (Application.Current.HasElevatedPermissions) {using ( ...
- POJ 3694——Network——————【连通图,LCA求桥】
Network Time Limit:5000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u Submit Stat ...
- HDU 5371——Hotaru's problem——————【manacher处理回文】
Hotaru's problem Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) ...
- 同源策略引发对跨域jsonp跨域的理解
一,同源策略其实网络的安全基石,既:http://www.baidu.com:80协议(http或者HTTPS或者ws或者wss).域名(www.baidu.com).端口(默认80,可以不写 htt ...
- element中遇到的表格问题总结
1.列表表头的颜色自定义 <el-table :data="pageData" style="width: 100%;" height="500 ...
- Log4.Net日志记录解析
http://www.cnblogs.com/neekerss/archive/2011/01/04/1925171.html
- 微信小程序里使用 Redux 状态管理
微信小程序里使用 Redux 状态管理 前言 前阵子一直在做小程序开发,采用的是官方给的框架 wepy , 如果还不了解的同学可以去他的官网查阅相关资料学习:不得不说的是,这个框架确相比于传统小程序开 ...
- wpf 查找父元素、子元素方法
1 /// <summary> 2 /// 根据类型查找子元素 3 /// </summary> 4 /// <typeparam name="T"& ...
- DataGridView进度条列 C# WinForm
先看看效果,如果感兴趣,继续往下看…… 效果如下图所示: DataGridView里没有Pragress列,但有Image列,有了它我们可以自己绘图来实现进度条.其实实现起来并不困难. 首先在实体类增 ...
- UrShop 商城系统介绍
UrShop能够帮助企业快速构建个性.高效.稳定.安全的网上商城并减少二次开发带来的成本.对于网店来说,UrShop除了安装便捷,功能上强大以外,操作上也非常方便快捷.优社电商秉承设身处地为客户着想的 ...