Facebook TSDB论文Gorilla分析
Facebook TSDB论文Gorilla分析
背景
TSDB时序数据库用于存储时间相关的数据,常用于监控系统的数据存储,分布式的TSDB提供了海量的数据存储能力,如InfluxDB、OpenTSDB等。关于TSDB更多详情,可以参考该系列博客:时间序列数据的存储和计算。
随着监控数据量增长,对TSDB查询性能的要求越来越高,尤其是自动化运维系统,大量的查询操作让基于磁盘的TSDB系统难以满足。
Facebook基于此需求推出了TSDB论文,设计了一个基于内存的TSDB:Gorilla。并开源了Gorilla的原型项目beringei。
本文主要基于Facebook官方论文和相关解读分析Gorilla的架构和数据结构。
Gorilla架构
Gorilla是一个内存TSDB。它在监控数据写入HBase存储之前,起到一个write-through cache的作用。Gorilla的数据模型是一个简单的3元组,包括一个string类型的key、一个64-bit整型timestamp和一个双精度浮点类型value。Gorilla使用一种新的timeseries压缩算法,可以按照时间顺序将单条数据从16字节压缩到平均1.37字节,缩小12倍。Gorilla的内存数据结构设计使得在保持对单个时间序列进行时间段查找的同时也能快速和高效的进行全数据扫描。
Gorilla无状态的架构支持非常好的水平扩展能力。监控数据中定义的key用来唯一标识一个timeseries。根据key将timeseries数据进行shard(分片),每个timeseries数据集会被映射到一台单独的Gorilla主机上。因此扩展Gorilla主机时,可以通过调整分片算法将新的timeseries数据映射到新的主机上。
Gorilla支持高可用,通过将同一个timeseries数据写到2个不同地域的主机中,来应对单节点故障、网络切换、甚至是整个数据中心故障。在检测到故障时,所有读取操作会failed over到可用区域的主机,以确保用户不会感知到任何中断。
压缩算法
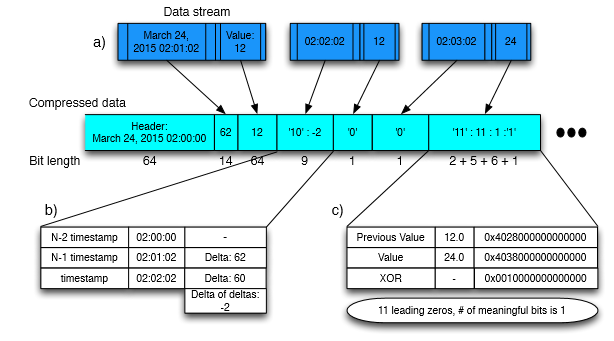
Gorilla引入了对timestamp和value的高压缩比算法,可大幅降低数据存储的大小。Timestamp根据时间关联的条目进行差值计算、以及差值的差值计算得到占用字节数非常小的数值并进行保存。同样Value使用XOR算法进行计算得到占用存储更小的数值进行保存。该算法在论文里描述的非常清楚,此处不再详述。
内存数据结构
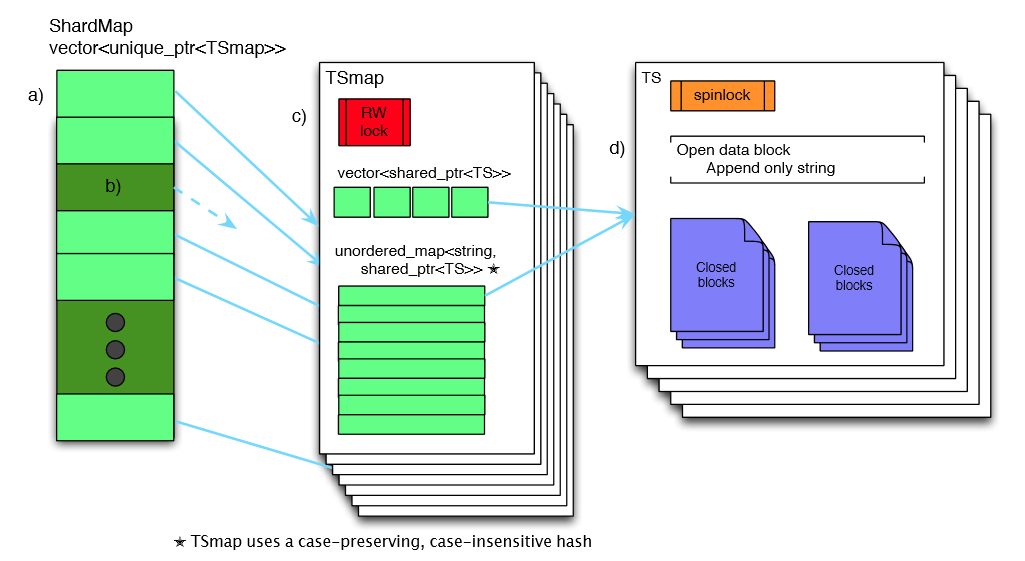
TSmap
Timeseries Map (TSmap)是Gorilla实现的主要数据结构。如上图所示,TSmap包括一个C++ Vector和一个map(unordered_map)。Vector里保存指向timeseries的指针(shared_ptr)。Map里保存timeseries name(key)到timeseries指针(value)的映射,该map大小写不敏感并保留原有大小写。
Vector用于高效的分页扫描所有数据(根据vector下标)。Map用于特定时间的timeseries查询。该设计既满足快速按时间查询的需求,又能提供高效的数据扫描。
C++的shared-pointers可以在几毫秒时间内扫描拷贝整个vector(或者几个pages),可以有效避免对新写入数据流的影响。删除的timeseries会将对应的vector设置为“墓碑状态”,即对应的内存不释放,而是标记为dead,并用于新的timeseries重复使用。
Map和vector的并行访问使用一个简单的读写spin lock进行保护。每个timeseries上使用一个1-byte的spin lock实行互斥。单个timeseries相关很少的写流量,因此读写的锁争用较少。
ShardMap
如上图所示,还有一个ShardMap用于保存shardId(分片ID)到TSmap的映射。Timeseries在保存的时候根据timeseries name哈希散列到不同shardId(0 ~ NumberOfShard)。该map也是使用大小写不敏感hash算法。系统中的Shard总数几千以内,因此存储空指针的额外开销可以忽略。同样ShardMap也使用一个读写spin lock实现并行。
由于数据根据shard进行了分区,单个map变得足够小(大约100万个条目),C++的unordered-map有足够的性能,没有锁争用的问题。
Timeseries data block
最终保存的Timeseries数据结构(图中TS)由一系列closed data blocks和一个open data block组成。每个data block保存2小时的数据,Closed data block用于保存2小时以前的数据,Open data block用于保存2小时内最近的数据。Open data block是一个append-only的string,新的压缩后的timestamps和values追加到该string后面。一旦Open data block写满2小时,则将其close。Closed data block不允许修改,直到将其从内存里删除。在closing过程中,数据将被拷贝到从large slabs里分配的内存以减少内存碎片。拷贝之后open data block可以直接用于新的数据写入,避免open data block经常改变size导致reallocate内存从而导致内存碎片。
根据时间范围查询时,将拷贝关联的data blocks数据给远程调用者。整个data block直接返回给Client,并由Client完成timestamp和value的解压缩。
Timeseries key string
一般TSDB的数据模型里通常有一个Metric(如CPU使用率)和一些TAG(如host=10.10.10.10,cluster=A),并提供针对Metric和TAG的查询、聚合等功能。而Gorilla每个timeseries都有一个key string字符串作为其唯一标识。论文中没有太多描述,只是提了一下依赖更高层的工具去抽象和定义这个key string。简单的实现可能就是MetricName+TAG1(key=value)+TAG2..组成一个string。
磁盘数据结构
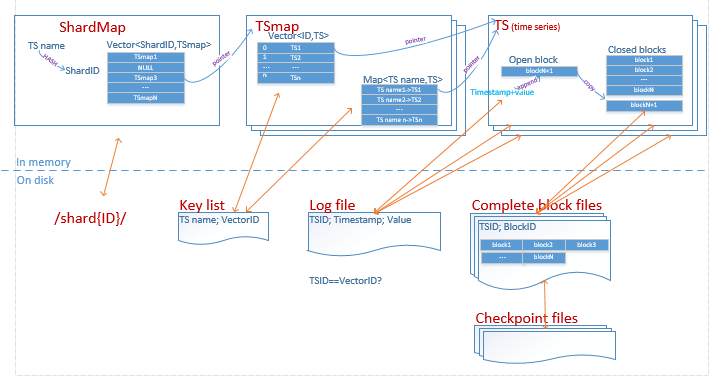
Gorilla使用GlusterFS存储持久化数据,以应对单机故障。GlusterFS是一个兼容POSIX的3副本分布式文件系统。之所以没有选择MySQL或者RocksDB,是因为Gorilla不需要提供一种数据库查询语言。
一个Gorilla主机上有多个shards的数据,每个shard有一个单独的目录,目录下包括4中类型的文件:Key list、append-only log、complete block files、checkpoint files。
- Key list是一个map用于保存timeseries string key到内存数据结构vector的ID的映射,新的key会被追加到当前key list文件尾,Gorilla会定期扫描每个shard里所有的keys并重写key list文件(猜测是为了保证一致性)。
- log file用于存储最新的数据流,包括压缩后的timestamps和values。每个shard只有一个log file,所以交替保存了多个timeseries的值。它和内存中的数据结构不同点在于每个timestamp-value pair都有一个32-bit整型ID标记,该ID应该就是key list里的vectorID,标记它属于哪个timeseries。log file并不是write-ahead-log(WAL),数据写入磁盘前会缓存64KB,因此宕机会导致几秒数据的丢失。不过Gorilla不需要提供ACID特性,相比WAL日志带来的收益,提供了更好的数据写入效率。
- complete block file存储压缩后的整个block数据,每隔2小时从内存中拷贝block数据并进行压缩,所以它比log file小了很多。该文件包含两个部分:一组连续的64KB slabs大小的block data;一个timeseriesID->data block指针pair的列表,用于标记block data属于哪个timeseries。这里timeseriesID应该和key list的vectorID是一个概念。
- checkpoint file用于标记某个时间的complete block file已经flush到磁盘。此时,对应的log file将被删除,数据流写入新的log file。宕机后接管该Shard的主机根据checkpoint file来确定从log file还是complete block file里读取数据。
总结
综上,Gorilla提供了一个对26小时内监控数据内存级分布式水平扩展的TSDB,在long-term分布式TSDB基础上提供了短时间(也是大部分查询需求时间段)内秒级快速查询的能力。
Facebook TSDB论文Gorilla分析的更多相关文章
- CVPR2018 关于视频目标跟踪(Object Tracking)的论文简要分析与总结
本文转自:https://blog.csdn.net/weixin_40645129/article/details/81173088 CVPR2018已公布关于视频目标跟踪的论文简要分析与总结 一, ...
- AlphaTensor论文阅读分析
AlphaTensor论文阅读分析 目前只是大概了解了AlphaTensor的思路和效果,完善ing deepmind博客在 https://www.deepmind.com/blog/discove ...
- Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读
文章链接: https://quinonero.net/Publications/predicting-clicks-facebook.pdf abstract Facebook日活跃度7.5亿,活跃 ...
- [源码分析] Facebook如何训练超大模型---(1)
[源码分析] Facebook如何训练超大模型---(1) 目录 [源码分析] Facebook如何训练超大模型---(1) 0x00 摘要 0x01 简介 1.1 FAIR & FSDP 1 ...
- [源码分析] Facebook如何训练超大模型 --- (2)
[源码分析] Facebook如何训练超大模型 --- (2) 目录 [源码分析] Facebook如何训练超大模型 --- (2) 0x00 摘要 0x01 回顾 1.1 ZeRO 1.1.1 Ze ...
- [源码分析] Facebook如何训练超大模型 --- (3)
[源码分析] Facebook如何训练超大模型 --- (3) 目录 [源码分析] Facebook如何训练超大模型 --- (3) 0x00 摘要 0x01 ZeRO-Offload 1.1 设计原 ...
- 计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践
计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践 2018年06月13日 16:38:11 轻春 阅读数 6004更多 分类专栏: 机器学习 机器学习荐货情报局 版 ...
- [论文翻译] 分布式训练 Parameter sharding 之 ZeRO
[论文翻译] 分布式训练 Parameter sharding 之 ZeRO 目录 [论文翻译] 分布式训练 Parameter sharding 之 ZeRO 0x00 摘要 0x01 综述 1.1 ...
- [论文翻译] 分布式训练 Parameter Sharding 之 Google Weight Sharding
[论文翻译] 分布式训练 Parameter sharding 之 Google Weight Sharding 目录 [论文翻译] 分布式训练 Parameter sharding 之 Google ...
随机推荐
- jmeter接口参数化获取tocken后保存批量保存在本地
jmeter目录结构如下: 1,读取文件配置的ID提取tocken 2,CSV 数据文件设置,第一个为文件目录,第二个为参数化的参数名. 3,正则表达式提取tocken 4,BeanShell Pos ...
- UIColor
UIColor.CIColor 和 CGColor 出现在不同的类库里面,其实就是颜色存储方式不同而已,比如 999 可以用 10 进制.2 进制.16 进制等存储.三者之间都是能够方便转换的,特别是 ...
- 自定义等高 Cell
1.介绍 1.1 代码自定义 cell(使用 frame) 创建一个继承自 UITableViewCell 的子类,比如 BookCell1. 在 initWithStyle:reuseIdentif ...
- [Groovy]Parse properties file in Groovy
def props = new Properties() new File("foo.properties").withInputStream { s -> props.lo ...
- freemarker 遍历树形菜单
<ul class="nav sidebar-menu"> <!--Dashboard--> <!-- 定义遍历方法 --> <#macr ...
- CSS基础(续)
老男孩第39天 老男孩 CSS CSS的常用属性 4 文本属性 font-size: 10px; text-align: center; 横向排列 line-height: 200px; 文本行 ...
- HDU - 1878 欧拉回路 (连通图+度的判断)
欧拉回路是指不令笔离开纸面,可画过图中每条边仅一次,且可以回到起点的一条回路.现给定一个图,问是否存在欧拉回路? Input 测试输入包含若干测试用例.每个测试用例的第1行给出两个正整数,分别是节点数 ...
- codeforces-777E Hanoi Factory (栈+贪心)
题目传送门 题目大意: 现在一共有N个零件,如果存在:bi>=bj&&bj>ai的两个零件i,j,那么此时我们就可以将零件j放在零件i上.我们现在要组成一个大零件,使得高度 ...
- 设置input的样式
css中的 ” 七层重叠法 ” :即网页内容先后顺序分别为:背景边框,负值z-index,display:block,浮动,display:inline-block,z-index:auto,正值z- ...
- HttpClient,Socket,URL知识
java中: tip/ip , udp 传输协议 网络编程有三大类:Socket,URL,datagram HTTP协议是建立在TCP协议之上的一种应用. 一:HttpClient HttpCli ...