tarjan算法,一个关于 图的联通性的神奇算法
一.算法简介
Tarjan 算法一种由Robert Tarjan提出的求解有向图强连通分量的算法,它能做到线性时间的复杂度。
我们定义:
如果两个顶点可以相互通达,则称两个顶点强连通(strongly connected)。如果有向图G的每两个顶点都强连通,称G是一个强连通图。有向图的极大强连通子图,称为强连通分量(strongly connected components)。
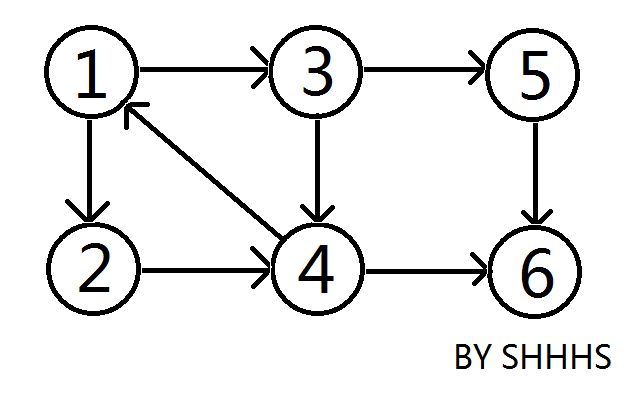
例如:在上图中,{1 , 2 , 3 , 4 } , { 5 } , { 6 } 三个区域可以相互连通,称为这个图的强连通分量。
Tarjan算法是基于对图深度优先搜索的算法,每个强连通分量为搜索树中的一棵子树。搜索时,把当前搜索树中未处理的节点加入一个堆栈,回溯时可以判断栈顶到栈中的节点是否为一个强连通分量。
再Tarjan算法中,有如下定义。
DFN[ i ] : 在DFS中该节点被搜索的次序(时间戳)
LOW[ i ] : 为i或i的子树能够追溯到的最早的栈中节点的次序号
当DFN[ i ]==LOW[ i ]时,为i或i的子树可以构成一个强连通分量。
二.算法图示
以1为Tarjan 算法的起始点,如图
顺次DFS搜到节点6
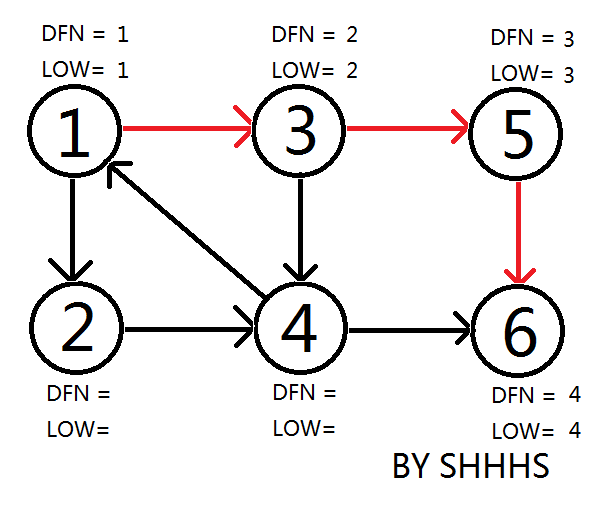
回溯时发现LOW[ 5 ]==DFN[ 5 ] , LOW[ 6 ]==DFN[ 6 ] ,则{ 5 } , { 6 } 为两个强连通分量。回溯至3节点,拓展节点4.
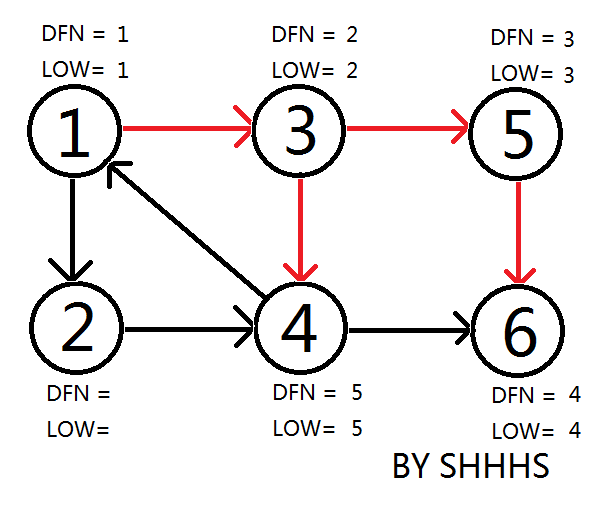
拓展节点1 , 发现1再栈中更新LOW[ 4 ],LOW[ 3 ] 的值为1
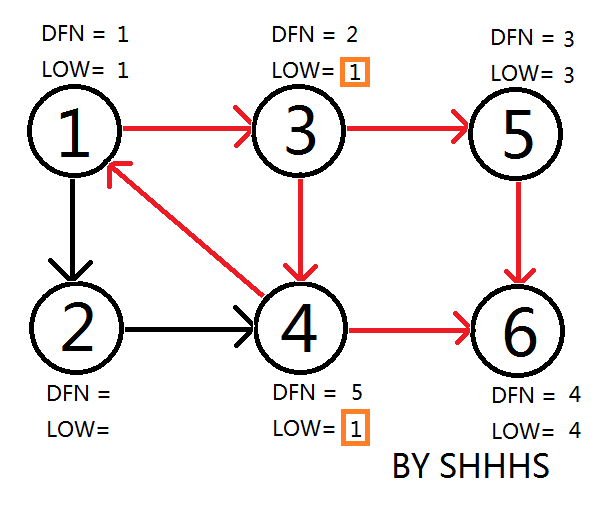
回溯节点1,拓展节点2
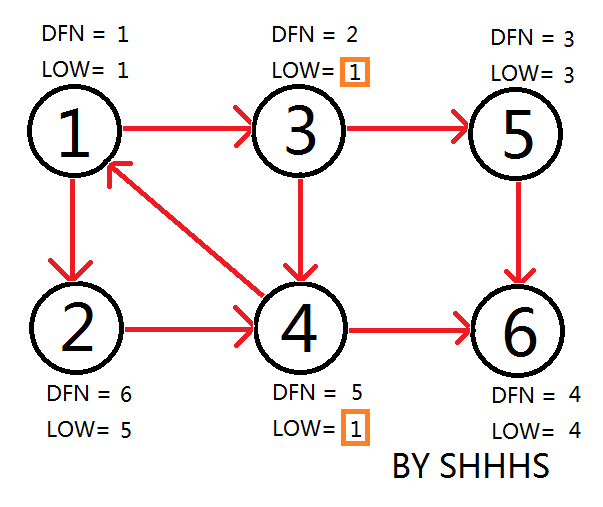
自此,Tarjan Algorithm 结束,{1 , 2 , 3 , 4 } , { 5 } , { 6 } 为图中的三个强连通分量。
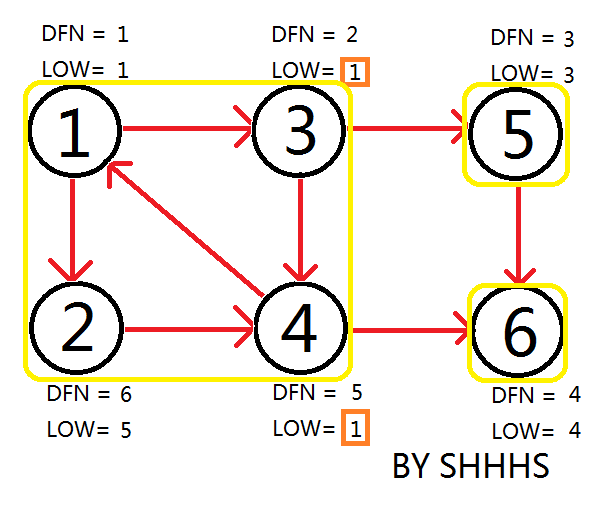
不难发现,Tarjan Algorithm 的时间复杂度为O(E+V).
模板:
void dfs(int u)
{
times++;//记录dfn顺序
dfn[u]=times;//赋值
low[u]=times;//先赋初值
vis[u]=true;//vis[i]用来判断i是否搜索过;
insta[u]=true;//表示是否在栈中,true为在栈中;
stack[top]=u;//栈顶
top++;
for(int i=head[u];i!=-;i=edge[i].next)// 以建图顺序枚举此点所连的边
{
int v=edge[i].to;//搜索到的点
if(!vis[v])//如果未搜索过即未入栈
{
dfs(v);//继续以此点进行深搜
low[u]=min(low[u],low[v]);//更新low值,此边为树枝边所以比较u此时的
} // low值(未更新时就是其dfn值)和v的low值
else
if(insta[v]==true)//如果搜索过且在栈中,说明此边为后向边或栈中横叉边
{
low[u]=min(low[u],dfn[v]);//更新low值,比较u此时的low值和v的dfn值
}
} if(low[u]==dfn[u])//相等说明找到一个强连通分量
{
while(top>&&stack[top]!=u)//开始退栈一直退到 u为止
{
top--;
insta[stack[top]]=false;
}
}
}
例题:
poj2186 - Popular Cows
题目大意:题目大意是:在一个牧群中,有N个奶牛,给定M对关系(A,B)表示A仰慕B,而且仰慕关系有传递性,问被所有奶牛(除了自己)仰慕的奶牛个数
解题思路:找出所有的连通分量,如果只有一个连通分量的出度为0,那么输出那个连通分量的点的个数即可,如果不唯一就输出0
因为连通分量的出度有两个的话,那么肯定至少存在一头牛不仰慕另外一头牛,所以我们至少保证要出度为0的连通分量唯一
解题思路:
1、用Tarjan求双连通分量然后缩成点。这些点会形成一棵树。
2、求树上的节点有多少个出度为零,如果有一个就输出那个点里包含的所有点(因为是缩点出来的树)。
注意:
1、给出的图会有不连通的可能,如果那样肯定输出零。因为不连通肯定不会有所有其他牛认为某只牛很牛的情况出现。
2、如果缩点后有多个出度为零的点,那么输出零。因为这样图虽然联通了,但是还是不会出现所有其他牛认为某只牛很牛的情况(自己画一下就知道啦)。
求强连通分量主要是为了简化图的构造,如果分量外的一个点能到达分量内的其中一个点,那么它必定能到达分量内的所有点,所以某种程度上,强连通分量可以简化成一个点。
#include <stdio.h>
#include <string.h>
const int MAXN = ;
const int MAXM = ;
struct node
{
int to,next;
} edge[MAXM];
int n,m,head[MAXN],dfn[MAXN],low[MAXN],stack1[MAXN],num[MAXN],du[MAXN],vis[MAXN],cnt,time,top,cut;
void init()
{
memset(dfn,,sizeof(dfn));
memset(low,,sizeof(low));
memset(head,-,sizeof(head));
memset(vis,,sizeof(vis));
memset(num,,sizeof(num));
memset(du,,sizeof(du));
cnt=;
time=;
top=;
cut=;
}
void addedge(int u,int v)
{
edge[cnt].to=v;
edge[cnt].next=head[u];
head[u]=cnt;
cnt++;
}
int min(int a,int b)
{
if(a>b)a=b;
return a;
}
void dfs(int u,int fa)
{
dfn[u]=time;
low[u]=time;
time++;
vis[u]=;
stack1[top]=u;
top++;
for(int i=head[u]; i!=-; i=edge[i].next)
{
int v=edge[i].to;
if(!vis[v])
{
dfs(v,u);
low[u]=min(low[u],low[v]);
}
else if(vis[v])
{
low[u]=min(low[u],dfn[v]);
}
}
if(low[u]==dfn[u])
{
cut++;
while(top>&&stack1[top]!=u)
{
top--;
vis[stack1[top]]=;
num[stack1[top]]=cut;
}
}
}
int main()
{
int i,u,v;
while(scanf("%d%d",&n,&m)!=EOF)
{
init();
for(i=; i<m; i++)
{
scanf("%d%d",&u,&v);
addedge(u,v);
}
for(int i=; i<=n; i++)
{
if(!vis[i])
{
dfs(i,);
}
}
for(i=; i<=n; i++)
{
for(int j=head[i]; j!=-; j=edge[j].next)
{
if(num[i]!=num[edge[j].to])
{
du[num[i]]++;
}
}
}
int sum=,x;
for(i=; i<=cut; i++)
{
if(!du[i])
{
sum++;
x=i;
}
}
if(sum==)
{
sum=;
for(i=; i<=n; i++)
{
if(num[i]==x)
{
sum++;
}
}
printf("%d\n",sum);
}
else
{
puts("");
}
}
return ;
}
tarjan算法,一个关于 图的联通性的神奇算法的更多相关文章
- 推荐一个算法编程学习中文社区-51NOD【算法分级,支持多语言,可在线编译】
最近偶尔发现一个算法编程学习的论坛,刚开始有点好奇,也只是注册了一下.最近有时间好好研究了一下,的确非常赞,所以推荐给大家.功能和介绍看下面介绍吧.首页的标题很给劲,很纯粹的Coding社区....虽 ...
- 笔试题&面试题:设计一个复杂度为n的算法找到单向链表倒数第m个元素
设计一个复杂度为n的算法找到单向链表倒数第m个元素.最后一个元素假定是倒数第0个. 提示:双指针查找 相对于双向链表来说,单向链表仅仅能从头到尾依次訪问链表的各个节点,所以假设要找链表的倒数第m个元素 ...
- 一个快速、高效的Levenshtein算法实现——代码实现
在网上看到一篇博客讲解Levenshtein的计算,大部分内容都挺好的,只是在一些细节上不够好,看了很长时间才明白.我对其中的算法描述做了一个简单的修改.原文的链接是:一个快速.高效的Levensht ...
- C++神奇算法库——#include<algorithm>
算法(Algorithm)为一个计算的具体步骤,常用于计算.数据处理和自动推理.C++ 算法库(Algorithms library)为 C++ 程序提供了大量可以用来对容器及其它序列进行算法操作的函 ...
- 一个简单文本分类任务-EM算法-R语言
一.问题介绍 概率分布模型中,有时只含有可观测变量,如单硬币投掷模型,对于每个测试样例,硬币最终是正面还是反面是可以观测的.而有时还含有不可观测变量,如三硬币投掷模型.问题这样描述,首先投掷硬币A,如 ...
- 如何用 js 实现一个类似微信红包的随机算法
如何用 js 实现一个类似微信红包的随机算法 js, 微信红包, 随机算法 "use strict"; /** * * @author xgqfrms * @license MIT ...
- 开源一个比雪花算法更好用的ID生成算法(雪花漂移)
比雪花算法更好用的ID生成算法(单机或分布式唯一ID) 转载及版权声明 本人从未在博客园之外的网站,发表过本算法长文,其它网站所现文章,均属他人拷贝之作. 所有拷贝之作,均须保留项目开源链接,否则禁止 ...
- 蚁群算法简介(part 1:蚁群算法之绪论)
群算法是Marco Dorigo在1992年提出的一种优化算法,该算法受到蚂蚁搜索食物时对路径的选择策略的启示.蚁群算法作为群体智能算法的一种利用分布式的种群搜索策略来寻找目标函数的最优解.蚁群算法与 ...
- EM算法(2):GMM训练算法
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(2):GMM训练算法 1. 简介 GMM模型全称为Ga ...
随机推荐
- OpenCV 官方工程报错(1) Couldn't load mixed_sample from loader
openCV/OpenCV-android-sdk/samples/tutorial-2-mixedprocessing 工程 - ::): Trying to get library list - ...
- 修改 linux 时区时间和 php 时区
问题:客户美国服务器时间不对第一步,先修改硬件时区. vim /etc/sysconfig/clock将 ZONE="America/New_York" 注释,加多一行 ZONE= ...
- ie7下z-index失效问题解决方法
绝对定位元素的“有定位属性(relative或absolute)的父元素”在渲染层次时起到了主要作用,前面的被后面的覆盖了.解决办法就是给有定位属性的父元素设置z-index 解决办法: 父级元素加上 ...
- js面试题知识点全解(一作用域)
问题: 1.说一下对变量提升的理解 2.说明this几种不同的使用场景 3.如何理解作用域 4.实际开发中闭包的应用 知识点: js没有块级作用域只有函数和全局作用域,如下代码: if(true){ ...
- cocos2d中setBlendFunc设置颜色混合方案
CCSprite有一个ccBlendFunc类型的blendFunc_结构体成员,可以用来设置描绘时的颜色混合方案.ccBlendFunc包含了一个src和一个dst,分别表示源和目标的运算因子. 如 ...
- 你可能不知道的pdf的功能
可以创建交互式的pdf,比如在pdf页面添加一个按钮, 添加一个文本框. 上篇文章说了pdf有可移植性,这是个非常重要的特性,我就想能否把3d模型放入到pdf中,这样即使对方电脑没有3d软件也可以查看 ...
- 内核文件ntoskrnl.exe,ntkrnlpa.exe的区别??
除了标题中说到的两个exe文件之外,还有另外两个ntkrnlmp.exe和ntkrpamp.exe.因为我目前用到的只是标题中的两个. 其中,我在网上搜索到的关于SSDT HOOK 的资料,举的例子, ...
- 第四章输入/输出(I/O)4.2PCL中I/O模块及类介绍
PCL中I/O库提供了点云文件输入输出相关的操作类,并封装了OpenNI兼容的设备源数据获取接口,可直接从众多感知设备获取点云图像等数据.I/O模块利用21个类和28个函数实现了对点云的获取.读入.存 ...
- Java50道经典习题-程序48 数字加密
题目:某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下:每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换.分析:例如原始 ...
- KindEditor 销毁与自动高度冲突解决
前提准备情况: KindEditor(KE) + easyUI 1.通过 EasyUI.Window 打开一个窗口,窗口中包含一个 KE编辑器:在次打开WIndow 的时候 KE会出现编辑器里面的 ...