爬虫初识和request使用
一.什么是爬虫
爬虫的概念:
通过编写程序,模拟浏览器上网,让其去互联网上爬取数据的过程.
爬虫的工作流程:
模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中
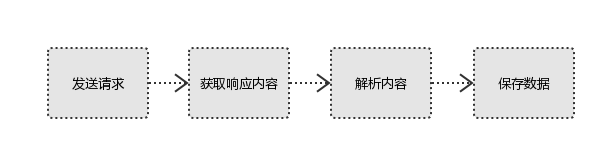
爬虫的分类:
- 通用爬虫:爬取全部的页面数据.
- 聚焦爬虫: 抓取页面中局部的页面数据
- 增量式爬虫:爬取网站中更新出的数据
反爬机制
门户网站会通过制定相关的技术手段阻止爬虫程序进行数据的爬取
反反爬策略:
- robots.txt协议: 防君子不防小人的协议
- UA检测 ----->用户表示(通过什么样的代理发起的请求)
- cookie ------>访问记录
- 验证码 ------>打码平台
- 动态加载数 ---->捕获ajax包
- reference ---->跳转过来的地址
二.requests模块
1.requests请求过程涉及的协议
#1、请求方式:
常用的请求方式:
GET:请求数据
POST:提交数据
PUT:更新数据
DELETE:删除数据 post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
post请求的参数放在请求体内:
可用浏览器查看,存放于form data内
get请求的参数直接放在url后 #2、请求url
url全称统一资源定位符,如一个网页文档,一张图片
一个视频等都可以用url唯一来确定 url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码) 网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
#3、请求协议格式: 请求首行:
协议格式:HTTP/HTTPS
请求方式:GET/POST
请求主机:
请求头:
空行:
请求体:
#4、请求头
User-agent:告诉它这是浏览器发过来的请求(请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户)务必加上
host: 请求主机(服务器)
cookies:cookie用来保存登录信息
Referer:由哪一个网址跳转过来的,如果直接访问是这个值是空的(用来做防盗链和广告的作用的判断) 一般做爬虫都会加上请求头
content-type:content-type:"urlencoded"/jason--->告诉服务器我提交数据的类型(psot请求才有的) #5、请求体
如果是get方式,请求体没有内容
如果是post方式,请求体是format data
ps: 1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
关于contentype详解
浏览器------------------>服务器
1 针对post请求(post请求才有请求体)
2 向服务器发送post请求有哪些形式:
form表单 (urlencoded编码格式)
user=yuan
pwd=123
Ajax(urlencoded编码格式)
a=1
b=2 请求协议格式字符串
发送urlencoded编码格式数据
'''
请求首行
请求头
content-type:"urlencoded"
空行
请求体 # user=yuan&pwd=123 urlencoded编码格式
'''
发送json数据
'''
请求首行
请求头
content-type:"json"
空行
请求体 # {"user":"yuan","pwd":123} json编码格式
'''
2.request爬取数据的流程
requests使用流程:
-pip install requests
- 指定url
- 发起请求
- 获取响应回来的页面数据
- 持久化存储
import requests
#爬取搜狗首页的页面数据
#1.指定url
url = 'https://www.sogo.com/'
#2.发起请求:get方法会返回一个响应对象
response = requests.get(url=url)
#3.获取页面数据
page_text = response.text
#4.持久化存储
with open('sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
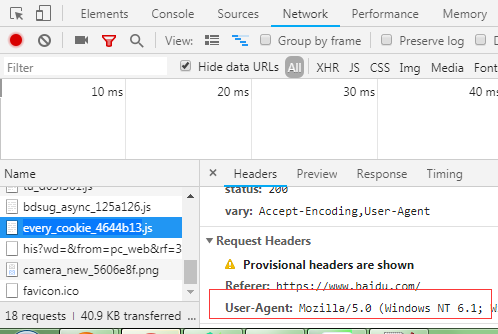
3.带User-Agent的请求
- User-Agent:请求载体的身份标识
- 反爬机制:浏览器会请求头的UA来检测是用户请求还是机器请求
- 反反爬策略:获取UA作为request的参数传进去,模拟一个正常的用户(浏览器)
例子:
url = 'https://www.qiushibaike.com/text/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
#手动设定请求的请求头信息
response = requests.get(url=url,headers=headers)
print(response.text)
拿UA:
4.带参数的request
某些网站会带着我们输入的参数进行请求:
看一个实例:
import requests
kw=input('请输入一个词语')
params={
'wd':kw
}
url='https://www.baidu.com/s'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
response=requests.get(url=url,params=params,headers=headers) page_content=response.content #响应体的content是二进制的内容,text是文本内容 filename=kw+'.html'
with open(filename,'wb') as f:
f.write(response.content)
5.带coockies的请求
import uuid
import requests url = 'http://httpbin.org/cookies' #这个网址可以做测试使用
cookies = dict(sbid=str(uuid.uuid4())) res = requests.get(url, cookies=cookies)
print(res.text)
6.带session对象的请求(比cookies好用)
#实例化一个是session对象,session对象包含着cookies
session=request.session()
#session对象可以直接发起请求的
session.get()
session.post()
7.request的post请求
1. post请求和get请求大致相同:post(url,headers,data/jason)就是参数的名字不一样而已,get请求参数是在params字典里面,
post请求参数在data或者jsaon里面(psot请求也可以有params参数,用来做跳转?next=)
形式: requests.post(url="/login/",headers={},cookies={},params={"next":"index"},data={},json={}) 2.来看一个例子,爬取百度翻译的结果
import requests
import json
url='https://fanyi.baidu.com/sug'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
kw=input('请输入一个词')
data={
'kw':kw
}
response=requests.post(url=url,headers=headers,data=data)
print(response.json()) 3,看一下jason和contentype的区别
import requests
res1=requests.post(url='http://httpbin.org/post', data={'name':'yuan'}) #没有指定请求头,#默认的请求头:application/x-www-form-urlencoed
print(res1.json()) res2=requests.post(url='http://httpbin.org/post',json={'age':"22",}) #默认的请求头:application/json
print(res2.json())
{'args': {}, 'data': '', 'files': {}, 'form': {'name': 'yuan'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Content-Length': '9', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.21.0'}, 'json': None, 'origin': '121.35.181.66, 121.35.181.66', 'url': 'https://httpbin.org/post'}
{'args': {}, 'data': '{"age": "22"}', 'files': {}, 'form': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Content-Length': '13', 'Content-Type': 'application/json', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.21.0'}, 'json': {'age': '22'}, 'origin': '121.35.181.66, 121.35.181.66', 'url': 'https://httpbin.org/post'}
8.request值ajax请求
import requests #url和参数,直接用抓包工具去请求头和Query String ParamMetres抓取
url='https://movie.douban.com/j/chart/top_list'
#因为是ajax发起的get请求,所以数据用params
params={
'type':'',
'interval_id':'100:90',
'action':'',
'start': '',
'limit':''
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
#从response看到Content-Type: application/json; charset=utf-8,说明是支持中文显示的
jason_text=requests.get(url=url,headers=headers,params=params).text
print(jason_text)
9.request的ajax的post请求
import requests
kw=input('请输入一个城市')
#这边要记住,这是post请求,post请求不能不会把参数直接拼接在路径后面,所有网址拷过来就不要动了
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
# post请求用的是data,记得啊
data={
'cname':'',
'pid': '',
'keyword': kw,
'pageIndex': '',
'pageSize': ''
}
#抓包工具能看到他是text类型,utf-8吧编码的,支持中文显示
page_text=requests.post(url=url,headers=headers,data=data).text
print(page_text)
10.基于ajax的动态加载网址
import requests url='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
#做循环作用的拿到所有页码的
for i in range(100): data={
'on': 'true',
'page': '',
'pageSize': '',
'productName':'',
'conditionType': i,
'applyname': '',
'applysn': ''
}
# #json()方法:返回是一个序列化号的json对象
jason_text=requests.post(url=url,data=data,headers=headers).json()
jason_list=jason_text['list']
#拿到所有企业的id(ajax发出的post请求是根据企业id返回结果的)
id_list=[]
for dic in jason_list:
id_list.append(dic['ID'])
#发出第二次请求,带上企业id就能拿到具体的值了
url1='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
data1={
'id': id
}
json_text=requests.post(url=url1,data=data1,headers=headers).text
print(json_text)
11.带有代理的请求
import requests
res=requests.get('http://httpbin.org/ip', proxies={'http':'111.177.177.87:9999'}).json()
三.reponse的属性
1.常见属性
import requests
response=requests.get('https://www.jd.com/')
print(response.status_code)
print(response.text) #文本内容
print(response.content) #二进制内容
print(response.headers) #响应头
print((response.cookies)) #响应的cookie
print(response.cookies.get_dict())
print(response.cookies.items())
print(response.url) #响应的url
print(response.history) #如果有重定向重定向之前相应的数据
print(response.encoding) #响应体的编码
2.编码问题
import requests
response=requests.get('http://www.autohome.com/news')
response.encoding='gbk' #汽车之家网站返回的页面内容为gb2312编码的,而requests的默认编码为ISO-8859-1,如果不设置成gbk则中文乱码
with open("res.html","w") as f: #解码过程是在拿text过程中执行的
f.write(response.text)
3.下载二进制内容
import requests
response=requests.get('http://bangimg1.dahe.cn/forum/201612/10/200447p36yk96im76vatyk.jpg')
with open("res.png","wb") as f:
# f.write(response.content) # 比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的
for line in response.iter_content(): #用迭代器可以一段一段,不知于把自己的硬盘搞垮了
f.write(line)
4,解析jason数据
import requests
import json response=requests.get('http://httpbin.org/get')
res1=json.loads(response.text) #太麻烦
res2=response.json() #直接获取json数据,和上面的同理
print(res1==res2)
5. Redirection and History
默认情况下,除了 HEAD, Requests 会自动处理所有重定向。可以使用响应对象的 history 方法来追踪重定向。Response.history 是一个 Response 对象的列表,
为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。
>>> r = requests.get('http://github.com')
>>> r.url
'https://github.com/'
>>> r.status_code
200
>>> r.history
[<Response [301]>]
另外,还可以通过 allow_redirects 参数禁用重定向处理:
>>> r = requests.get('http://github.com', allow_redirects=False)
>>> r.status_code
301
>>> r.history
[]
6.相应状态码
response.status_code
#正常情况下我们是通过判断相应的状态码是不是200 来判断是否请求成功
我们也可可以通过相应对象的方法来直接捕获状态码不是200的响应
1.相应状态码不是200的
import requests
bad_r = requests.get('http://httpbin.org/status/404')
bad_r.status_code #
bad_r.raise_for_status() #当响应的状态码不是200的时候调用这个接口,会抛出异常,哦我们呢捕获这个异常就好了
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "D:\python37\lib\site-packages\requests\models.py", line 941, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: NOT FOUND for url: http://httpbin.org/status/404
2.状态码是200
import requests
res=requests.get('https://www.baidu.com/')
res.status_code #
res.raise_for_status() #当响应的状态码是200的时候,调用这个接口的返回值的None
print(res.raise_for_status())
None
3.判断响应状态码中和请求的状态码中的ok(200)是不是相等的
importrequest
res=requests.get('https://www.baidu.com/')
res.status_code #
res.status_code==requests.codes.ok
True
所以通用的请求状态码判断这块可以这么写:
import requests try:
res=requests.get('https://www.baidu.com/')
res.raise_for_status() except requests.HTTPError as error:
print('status_error')
except:
print('other error')
爬虫初识和request使用的更多相关文章
- python爬虫如何POST request payload形式的请求
python爬虫如何POST request payload形式的请求1. 背景最近在爬取某个站点时,发现在POST数据时,使用的数据格式是request payload,有别于之前常见的 POST数 ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- 网络爬虫urllib:request之urlopen
网络爬虫urllib:request之urlopen 网络爬虫简介 定义:按照一定规则,自动抓取万维网信息的程序或脚本. 两大特征: 能按程序员要求下载数据或者内容 能自动在网络上流窜(从一个网页跳转 ...
- Python urllib2写爬虫时候每次request open以后一定要关闭
最近用python urllib2写一个爬虫工具,碰到运行一会程序后就会出现scoket connection peer reset错误.经过多次试验发现原来是在每次request open以后没有及 ...
- nodejs爬虫笔记(一)---request与cheerio等模块的应用
目标:爬取慕课网里面一个教程的视频信息,并将其存入mysql数据库.以http://www.imooc.com/learn/857为例. 一.工具 1.安装nodejs:(操作系统环境:WiN 7 6 ...
- 爬虫模块介绍--request(发送请求模块)
爬虫:可见即可爬 # 每个网站都有爬虫协议 基础爬虫需要使用到的三个模块 requests 模块 # 模拟发请求的模块 PS:python原来有两个模块urllib和urllib的升级urlli ...
- 爬虫之urllib.request基础使用(一)
urllib模块 urllib模块简介: urllib提供了一系列用于操作URL的功能.包含urllib.request,urllib.error,urllib.parse,urllib.robotp ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- Python爬虫--初识爬虫
Python爬虫 一.爬虫的本质是什么? 模拟浏览器打开网页,获取网页中我们想要的那部分数据 浏览器打开网页的过程:当你在浏览器中输入地址后,经过DNS服务器找到服务器主机,向服务器发送一个请求,服务 ...
随机推荐
- floyd路径记录
#include<cstdio> #include<cstring> #include<algorithm> #include<cstdlib> #in ...
- 华为2013年西安java机试题目:如何过滤掉数组中的非法字符。
这道题目为记忆版本: 题目2描述: 编写一个算法,过滤掉数组中的非法字符,最终只剩下正式字符. 示例:输入数组:“!¥@&HuaWei*&%123” 调用函数后的输出结果,数组:“Hu ...
- 3、PACBIO下机数据如何看
转载:http://www.cnblogs.com/jinhh/p/8328818.html 三代测序的下机数据都有哪些,以及他们具体的格式是怎么样的(以sequel 平台为主). 测序过程 SMRT ...
- Luogu 3479 [POI2009]GAS-Fire Extinguishers
补上了这一道原题,感觉弱化版的要简单好多. 神贪心: 我们设$cov_{x, i}$表示在$x$的子树中与$x$距离为$i$的还没有被覆盖到的结点个数,设$rem_{x, i}$表示在$x$的子树中与 ...
- WOJ 39 塌陷的牧场
感觉……做克老师的题,都很神仙…… 还有去年一个人坐在家里写挂60分算法的惨痛记忆,凭借着一点点记忆重新写这道题. 感觉这并查集真的很神仙,仍然不会算最后的α的复杂度……自己想感觉无论如何都要挂个lo ...
- 20169219 《Linux内核原理与分析》 第十周作业
进程地址空间 1.进程地址空间由进程可寻址的虚拟内存组成.Linux系统中的所有进程之间以虚拟方式共享内存. 2.进程只能访问有效内存区域内的内存地址. 内存区域可以包含各种内存对象: (1) 代码段 ...
- linux中的线程同步:生产者、消费者问题
#include <stdio.h> #include <semaphore.h> #include <unistd.h> #include <stdlib. ...
- 【C#】EF学习<二> DbFirst (先创建数据库,表及其关联关系)
工程压缩文件放到百度云盘---20181019001文件夹 1. 创建表的脚本 create table Teacher ( TID char(12) primary key, Tname char( ...
- 使用metasploit进行栈溢出攻击-2
基本的栈溢出搞明白了,真实攻击中一个很重要的问题是shellcode生成. 利用Metasploit提供的工具,可以方便的生成shellcode,然后可以使用第一篇中的代码进行验证. 先说一下如何生成 ...
- 选择性搜索(Selective Search)
1 概述 本文牵涉的概念是候选区域(Region Proposal ),用于物体检测算法的输入.无论是机器学习算法还是深度学习算法,候选区域都有用武之地. 2 物体检测和物体识别 物体识别是要分辨出图 ...