爬虫基础-http请求的基础知识
百度百科上这么介绍爬虫:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
在开发爬虫时常用的工具:chrome浏览器,fiddler工具,postman插件。
有关fiddler知识的地址:http://kb.cnblogs.com/page/130367/
下面普及最基础的知识:Http请求。(下面知识来源于:http://www.runoob.com/http/http-intro.html)
定义:
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。TTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
工作原理:
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。
Web服务器有:Apache服务器,IIS服务器(Internet Information Services)等。
Web服务器根据接收到的请求后,向客户端发送响应信息。HTTP默认端口号为80,但是你也可以改为8080或者其他端口。
HTTP三点注意事项:
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
HTTP 消息结构:
HTTP是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议。
一个HTTP"客户端"是一个应用程序(Web浏览器或其他任何客户端),通过连接到服务器达到向服务器发送一个或多个HTTP的请求的目的。
一个HTTP"服务器"同样也是一个应用程序(通常是一个Web服务,如Apache Web服务器或IIS服务器等),通过接收客户端的请求并向客户端发送HTTP响应数据。
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。
一旦建立连接后,数据消息就通过类似Internet邮件所使用的格式[RFC5322]和多用途Internet邮件扩展(MIME)[RFC2045]来传送。
请求消息的结构图解:
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
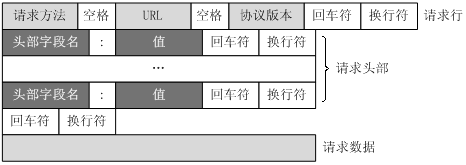
http请求头详解:(参考:https://kb.cnblogs.com/page/92320/)
| 请求头 | 请求头属性 |
| Cache-Control |
指定请求应遵循的缓存机制,其中缓存指令:no-cache、no-store、max-age、 max-stale、min-fresh、only-if-cached。 no-cache:表示请求的消息不可以缓存 no-store:在请求消息中,表示请求和响应的消息均不可以缓存,为了防止重要的消息被无意间泄露 max-age:表示客户机接收相应消息的最大时间(最大生存期) max-stale:表示客户机可以接受超时的消息,如果指定该值,表示可以接受超时之后指定值之内的消息 min-fresh:表示客户机可以接受当前时间加上指定值的时间之内的消息 only-if-cached:表示客户机只接受被缓存的内容 |
| Date | 表示消息发送的时间,时间的描述格式由rfc822定义。例如,Date:Mon,31Dec200104:25:57GMT。Date描述的时间表示世界标准时,换算成本地时间,需要知道用户所在的时区。 |
| Pragma | 反正页面被缓存,在http1.1版本中,与Cache-Control:no-cache,作用相同,在http1.0中没有实现Cache-Control.Pragma只有一个用法:Pragma:no-cache |
| Host | 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的。如果不是默认的80端口,会指定端口。如果不指定host,会报400错误 |
| Referer | 为服务器提供上下文信息,告诉服务器,我这个链接是从什么地方转过来的。 |
| Range |
只请求实体的一部分,服务器可以忽略此请求。 头500个字节:bytes=0-499。第二个500字节:bytes=500-999。最后500个字节:bytes=-500。500字节以后的范围:bytes=500-。第一个和最后一个字节:bytes=0-0,-1。同时指定几个范围:bytes=500-600,601-999 |
| User-Agent | 表示包含发送请求的用户信息。如果是浏览器发送的话,基本就是浏览器的信息 |
| Accept |
表示客户端能够接受的内容类型,例:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 如果想知道更多的MIME类型,去这个网站:http://www.w3school.com.cn/media/media_mimeref.asp |
| Accept-Charset | 表示浏览器可以接受的字符编码集。在国内最常用的就是utf8,gbk。想了解更多:https://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81 |
| Accept-Encoding | 指定浏览器可以支持的web服务器返回内容压缩编码类型。常用的:compress, gzip |
| Accept-Language | 指定浏览器可以接受的语言。常用的 en,zh |
| Accept-Ranges | 可以请求网页实体的一个或者多个子范围字段。例:Accept-Ranges: bytes |
| Authorization | http授权的授权证书 |
| Connection | 是否保持持久连接。close:表示不保持持久连接,keep-alive:保持持久连接。(HTTP 1.1默认进行持久连接) |
| Cookie | 存储的一些有关该客户机的信息,发送http请求时,会把该域名下的所有cookie,一起发送给服务器。 |
| Content-Length | 表示请求内容的长度 |
| Content-Type | 请求实体的MIME类型。如果想知道更多的MIME类型,去这个网站:http://www.w3school.com.cn/media/media_mimeref.asp |
| Expect | 请求的特定的服务器类型,不是太明白,有懂得可以帮我解释一下 |
| From | 发出请求的用户的Email |
| If-Match | 只有请求内容与实体相匹配才有效 |
| If-Modified-Since | 如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 |
| If-None-Match | 如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 |
| If-Range | 如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag |
| If-Unmodified-Since | 只在实体在指定时间之后未被修改才请求成功 |
| Max-Forwards | 限制信息通过代理和网关传送的时间 |
| Proxy-Authorization | 连接到代理的授权证书 |
| TE | 客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 |
| Upgrade | 向服务器指定某种传输协议以便服务器进行转换(如果支持) |
| Via | 通知中间网关或代理服务器地址,通信协议 |
| Warning | 关于消息实体的警告信息 |
http回应头详解:
| 请求头 | 请求头属性 |
| Cache- Control |
指定请求应遵循的缓存机制,其中缓存指令:no-cache、no-store、max-age、 max-stale、min-fresh、only-if-cached。 no-cache:表示请求的消息不可以缓存 no-store:在请求消息中,表示请求和响应的消息均不可以缓存,为了防止重要的消息被无意间泄露 max-age:表示客户机接收相应消息的最大时间(最大生存期) max-stale:表示客户机可以接受超时的消息,如果指定该值,表示可以接受超时之后指定值之内的消息 min-fresh:表示客户机可以接受当前时间加上指定值的时间之内的消息 only-if-cached:表示客户机只接受被缓存的内容 |
| Date | 原始服务器消息发出的时间,时间的描述格式由rfc822定义。例如,Date:Mon,31Dec200104:25:57GMT。Date描述的时间表示世界标准时,换算成本地时间,需要知道用户所在的时区。 |
| Expires | 响应过期的日期和时间 |
| Pragma | 不允许页面被缓存,在http1.1版本中,与Cache-Control:no-cache,作用相同,在http1.0中没有实现Cache-Control.Pragma只有一个用法:Pragma:no-cache |
| User-Agent | 表示包含发送请求的用户信息。如果是浏览器发送的话,基本就是浏览器的信息 |
| Accept-Ranges | 可以请求网页实体的一个或者多个子范围字段。例:Accept-Ranges: bytes |
| Age | 从原始服务器到代理缓存形成的估算时间(以秒计,非负) |
| Allow | 对某网络资源的有效的请求行为,不允许则返回405,请求行为:Get,Post,Head等,下面会重点介绍 |
| Content-Encoding | web服务器支持的返回内容压缩编码类型 |
| Content-Language | 响应体的语言 |
| Content-Location | 请求资源可替代的备用的另一地址 |
| Content-MD5 | 返回资源的MD5校验值 |
| Content-Range | 在整个返回体中本部分的字节位置 |
| Connection | 是否保持持久连接。close:表示不保持持久连接,keep-alive:保持持久连接。(HTTP 1.1默认进行持久连接) |
| Cookie | 存储的一些有关该客户机的信息,发送http请求时,会把该域名下的所有cookie,一起发送给服务器。 |
| Content-Length | 响应体内容的长度 |
| Content-Type | 返回内容的MIME类型。如果想知道更多的MIME类型,去这个网站:http://www.w3school.com.cn/media/media_mimeref.asp |
| Via | 通知中间网关或代理服务器地址,通信协议 |
| Warning | 关于消息实体的警告信息 |
| ETag | 请求变量的实体标签的当前值 |
| Last-Modified | 请求资源的最后修改时间 |
| Location | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 |
| Proxy-Authenticate | 它指出认证方案和可应用到代理的该URL上的参数 |
| refresh | 应用于重定向或一个新的资源被创造,在5秒之后重定向(由网景提出,被大部分浏览器支持) |
| Retry-After | 如果实体暂时不可取,通知客户端在指定时间之后再次尝试 |
| Server | web服务器软件名称 |
| Set-Cookie | 设置Http Cookie |
| Trailer | 指出头域在分块传输编码的尾部存在 |
| Transfer-Encoding | 文件传输编码 |
| Vary | 告诉下游代理是使用缓存响应还是从原始服务器请求 |
| WWW-Authenticate | 表明客户端请求实体应该使用的授权方案 |
关于请求头与回应头,更多的可以访问W3C官网:https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html
http请求方法:
(转自:http://www.runoob.com/http/http-methods.html)
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
| 请求方法 | 描述 |
| GET | 请求指定的页面信息,并返回实体主体。 |
| HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
http状态码:
(转自:http://www.runoob.com/http/http-status-codes.html)
| 分类 | 分类描述 |
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
爬虫基础-http请求的基础知识的更多相关文章
- Python爬虫(1):基础知识
爬虫基础知识 一.什么是爬虫? 向网站发起请求,获取资源后分析并提取有用数据的程序. 二.爬虫的基本流程 1.发起请求 2.获取内容 3.解析内容 4.保存数据 三.Request和Response ...
- 9.12/ css3拓展、js基础语法、程序基本知识、数据类型、运算符表达方式、语句知识点
css3拓展: <display:none> 将某个元素隐藏 <visibility:hidden> 也是将某个元素隐藏 <display:block&g ...
- httpWebRequest请求错误,基础连接已经关闭: 连接被意外关闭
win10下,C# 用httpWebRequest 执行post请求出现"请求错误,基础连接已经关闭: 连接被意外关闭",经测试设置 //Post请求方式 System.Net.H ...
- Flutter实战视频-移动电商-07.Dio基础_POST请求的使用
07.Dio基础_POST请求的使用 越界问题解决 容器越界的问题,越界是因为键盘弹起的问题.如果键盘不弹起是不会越界 我们加一个滚动组件就可以解决. 这是技术胖视频中出现的越界的截图效果 这是我自己 ...
- 053 01 Android 零基础入门 01 Java基础语法 05 Java流程控制之循环结构 15 流程控制知识总结
053 01 Android 零基础入门 01 Java基础语法 05 Java流程控制之循环结构 15 流程控制知识总结 本文知识点: 流程控制知识总结 流程控制知识总结 选择结构语句 循环结构语句 ...
- 020 01 Android 零基础入门 01 Java基础语法 02 Java常量与变量 14 变量与常量 知识总结
020 01 Android 零基础入门 01 Java基础语法 02 Java常量与变量 14 变量与常量 知识总结 本文知识点:变量与常量 知识总结 Java中的标识符 Java中的关键字 目前常 ...
- 夯实基础系列四:Linux 知识总结
前言 前三节内容传送门: 夯实基础系列一:Java 基础总结 夯实基础系列二:网络知识总结 夯实基础系列三:数据库知识总结 现在很多公司项目部署都使用的是 Linux 服务器,互联网公司更是如此.对于 ...
- 『动善时』JMeter基础 — 6、使用JMeter发送一个最基础的请求
目录 步骤1:创建一个测试计划 步骤2:创建线程组 步骤3:创建取样器 步骤4:创建监听器 步骤5:完善信息 步骤6:保存测试计划 步骤7:查看结果 总结:JMeter测试计划要素 当我们第一次打开J ...
- 网络请求的基本知识《极客学院 --AFNetworking 2.x 网络解析详解--1》学习笔记
网络请求的基本知识 我们网络请求用的是HTTP请求 Http请求格式:请求的方法,请求头,请求正文 Http请求的Request fields:请求的头部,以及被请求头部的一些设置 Http请求的 ...
随机推荐
- 7.27实习培训日志-Oracle SQL(三)
Oracle SQL(三) 视图 特性 简单视图 复杂视图 关联的表数量 1个 1个或多个 查询中包含函数 否 是 查询中包含分组数据 否 是 允许对视图进行DML操作 是 否 CREATE [OR ...
- vue 报错 Uncaught (in promise) error
可尝试在then()后加上catch() ps:该图来自网络
- Neutron网络研究
你将学到什么 虚拟机的Ping包是如何出外网的 DevStack环境准备 节点 硬件配置 网络配置 类型 操作系统 DevStack 4G 2CPU 50GB 2张网卡(NAT模式) VMWare虚拟 ...
- 【转】vs发布msi程序详解
源地址:http://wenku.baidu.com/link?url=MV1Mf7IukCZ0cab8AzXQoQ3MAXeUAHGz5b2IuUL4Kw-hCI90ZyBKXwKeQA3t3-SV ...
- 洛谷P2055 [ZJOI2009]假期的宿舍
P2055 [ZJOI2009]假期的宿舍 题目描述 学校放假了 · · · · · · 有些同学回家了,而有些同学则有以前的好朋友来探访,那么住宿就是一个问题.比如 A 和 B 都是学校的学生,A ...
- Scrapy框架中的Pipeline组件
简介 在下图中可以看到items.py与pipeline.py,其中items是用来定义抓取内容的实体:pipeline则是用来处理抓取的item的管道 Item管道的主要责任是负责处理有蜘蛛从网页中 ...
- 解决Eclipse导入Gradle项目时在 Building gradle project info 一直卡住
问题描述 在使用 Eclipse 导入 Gradle 项目时一直卡住,不能导入项目 问题解决 解决办法主要有两种:一是直接下载 gradle 离线包,二是修改项目的 ..\gradle\wrapp ...
- P4135 作诗
传送门 分块 设sum[ i ] [ j ] 存从左边到第 i 块时,数字 j 的出现次数 f [ i ] [ j ] 存从第 i 块,到第 j 块的一整段的答案 那么最后答案就是一段区间中几块整段的 ...
- flush logs时做的操作
flush logs时做的操作: 对于一般查询日志和慢日志,先关闭文件再打开 对于binlog,关闭当前的,开始用下一个新的 用错误日志文件的话,先关闭再打开flush logs可以对一般查询日 ...
- Linux如何用查看域名解析
方法/步骤 查看本地dns配置.确保能上网,dns配置正确.可以查看网卡配置文件和dns配置文件,网卡里配置优先. ping命令.第一行会返回域名及解析的ip. host命令.会返回域 ...