linux 出错 “INFO: task xxxxxx: 634 blocked for more than 120 seconds.”的3种解决方案(转)
linux 出错 “INFO: task xxxxxx: 634 blocked for more than 120 seconds.”的3种解决方案
1 问题描述
服务器内存满了,ssh登录失败 ,查看日志有以下报错。
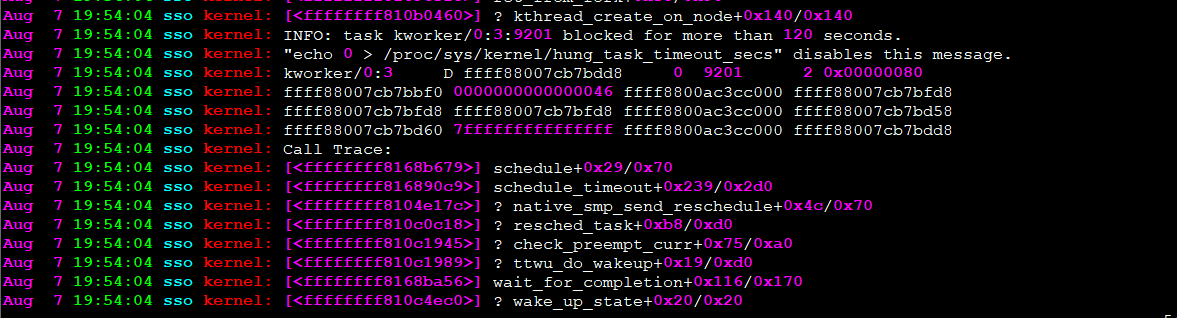
仔细阅读打印信息发现关键信息是“hung_task_timeout_secs”,第一次遇到这样的问题,首先百度…
通过翻看多个网友的博客,发现这是linux kernel的一个bug。大家对这个问题的解释也都比较一致,摘抄一段:
By default Linux uses up to 40% of the available memory for file system caching.
After this mark has been reached the file system flushes all outstanding
data to disk causing all following IOs going synchronous.
For flushing out this data to disk this there is a time limit of 120 seconds by default.
In the case here the IO subsystem is not fast enough to flush the data withing 120 seconds.
This especially happens on systems with a lot of memory.
The problem is solved in later kernels。
翻译过来就是:一般情况下,linux会把可用内存的40%的空间作为文件系统的缓存。当缓存快满时,文件系统将缓存中的数据整体同步到磁盘中。但是系统对同步时间有最大120秒的限制。如果文件系统不能在时间限制之内完成数据同步,则会发生上述的错误。这通常发生在内存很大的系统上。系统内存大,则缓冲区大,同步数据所需要的时间就越长,超时的概率就越大。
2 解决办法
网友们提供的解决方案大致有3种,分别对3种方案的效果进行验证测试。
2.1 缩小文件系统缓存大小
此种方案是降低缓存占内存的比例,比如由40%降到10%,这样的话需要同步到磁盘上的数据量会变小,IO写时间缩短,会相对比较平稳。
文件系统缓存的大小是由内核参数vm.dirty_ratio 和 vm.dirty_backgroud_ratio控制决定的。
vm.dirty_background_ratio指定当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入外存。
vm.dirty_ratio则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存),在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
通常情况下,vm.dirty_ratio的值要大于vm.dirty_background_ratio的值。
下面说一下修改这两个参数的流程及效果。
(1)首先查看系统当前的vm.dirty_ratio 和 vm.dirty_ background_ratio的值。
在shell命令行中输入如下指令:
sysctl -a | grep dirty- 1
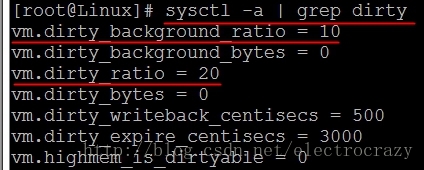
由上图可知,当前环境下,vm.dirty_ratio=20 ,vm.dirty_ background_ratio=10。在此情况下,会出现上述问题。
(2)修改vm.dirty_ratio和vm.dirty_ background_ratio的值。
把vm.dirty_ratio修改为10 ,vm.dirty_background_ratio修改为5。在命令行输入如下命令:
./sbin/sysctl -w vm.dirty_ratio=10
./sbin/sysctl -w vm.dirty_background_ratio=5- 1
- 2

(3)查看修改是否成功。
在命令行输入(1)中的指令即可。
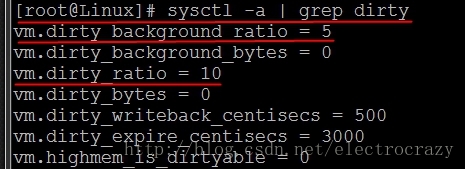
由上图可知,参数修改成功。
(4)使参数修改立即生效。
在命令行输入如下指令即可。
sysctl -p- 1
(5)观察测试结果。
经过以上操作,缩减文件系统缓存之后,上述问题成功解决。
2.2 修改系统IO调度策略
Linux的IO共有三种调度器:CFQ、noop、deadline。每个调度器都有其优点。
CFQ (Completely Fair Scheduler(完全公平调度器))(cfq):它是许多Linux 发行版的默认调度器;它将由进程提交的同步请求放到多个进程队列中,然后为每个队列分配时间片以访问磁盘。
Noop调度器(noop):基于先入先出(FIFO)队列概念的Linux内核里最简单的I/O调度器。此调度程序最适合于SSD。
截止时间调度器(deadline):尝试保证请求的开始服务时间。
Linux发行版的默认采用的是cfq调度器。此方案就是把cfq调度器修改为最简单的noop调度器。
下面说一下修改调度器的流程。
(1)查看当前采用的调度器。
在命令行中输入如下指令:
cat /sys/block/sda/queue/scheduler- 1

由内核返回信息可知,当前采用的是cfq调度器。
(2)修改调度器。
在命令行中输入如下指令:
echo noop >/sys/block/sda/queue/scheduler- 1
(3)查看修改是否成功。
在命令行中输入如(1)的指令。

由内核返回信息可知,调度器修改成功。
调度器的修改是立即生效的,不必重启内核。
(4)观察测试结果。
修改完成后,让系统继续运行一段时间。上述问题依然存在。所以此方案对本文的案例不起作用。对于其他案例是否起作用需要自己按照上述方式测试才能得知。
2.3 取消120秒时间限制
此方案就是不让系统有那个120秒的时间限制。文件系统把数据从缓存转到外存慢点就慢点,应用程序对此延时不敏感。就是慢点就慢点,我等着。实际上操作系统是将这个变量设为长整形的最大值。
下面说一下内核hung task检测机制由来。我们知道进程等待IO时,经常处于D状态,即TASK_UNINTERRUPTIBLE状态,处于这种状态的进程不处理信号,所以kill不掉,如果进程长期处于D状态,那么肯定不正常,原因可能有二:
1)IO路径上的硬件出问题了,比如硬盘坏了(只有少数情况会导致长期D,通常会返回错误);
2)内核自己出问题了。
这种问题不好定位,而且一旦出现就通常不可恢复,kill不掉,通常只能重启恢复了。
内核针对此种情况开发了一种hung task的检测机制,基本原理是:定时检测系统中处于D状态的进程,如果其处于D状态的时间超过了指定时间(默认120s,可以配置),则打印相关堆栈信息,也可以通过proc参数配置使其直接panic。
如何修改或者取消120秒的时间限值呢。120秒的时间限值由内存参数kernel.hung_task_timeout_secs决定的。直接像方案一那样修改此内核参数的值就可。如果kernel.hung_task_timeout_secs的值设置为0,那就是把此种设置为长整型的最大值。
下面说一下修改调度器的流程。
(1)查看当前hung_task_timeout_secs值。
在命令行中输入如下指令:
sysctl -a | grep hung_task_timeout_secs- 1

有内核返回信息,可知当前设置的hung_task超时时间为120秒。
(2)修改hung_task_timeout_secs值。
把hung_task_timeout_secs的值修改为0,在命令行中输入如下指令:
./sbin/sysctl -w kernel.hung_task_timeout_secs=0- 1
- 2

(3)查看修改是否成功。
在命令行输入(1)中的指令即可。

(4)使参数修改立即生效。
在命令行输入如下指令即可。
sysctl -p- 1
(5)观察测试结果。
经过以上操作,取消120秒时间限值之后,上述问题成功解决。
2.4 总结
经过上边的测试,可知对与本案例缩减文件系统缓冲大小和取消120秒时间限值均可以解决问题。但是取消120秒的时间限值会允许系统不可切换任务的出现。综合考虑决定采用方案1,即缩减文件系统的缓冲区大小。
3 永久修改内核参数
在上述方案中采用sysctl可以修改内核参数,但是这只是临时修改,上电重启后又会恢复回之前的参数。那么如何才能够永久修改内核参数呢?
可以修改系统信息配置文件sysctl.conf,此配置文件在/etc目录下。打开配置文件在最后添加如下两行代码:
vm.dirty_background_ratio=5
vm.dirty_ratio=10- 1
- 2

保存后重启系统,查看配置是否成功。
如果系统没有sysctl.conf文件,就像我的最小linux系统一样,则可以自己创建sysctl.conf。
在/etc目录下,采用vi指令:vi sysctl.conf新建sysctl.conf文件,然后输入如下代码后保存退出。
重启之后查看vm.dirty_ratio和vm.dirty_background_ratio的值,发现又恢复成之前的了。
这是因为开机启动时系统没有读取sysctl.conf文件进行配置。可以通过修改启动文件来解决。
以我使用的linux系统为例,启动文件是/etc/init.d/rcS。采用指令vi /etc/init.d/rcS打开rcS文件,在最末尾添加如下代码:./sbin/sysctl -p

保存后退出。reboot重启可以看到内核打印信息中有如下信息:

进入控制台后,查看vm.dirty_ratio和vm.dirty_background_ratio的值,可知内核参数永久修改成功。
【参考】
1、Linux Kernel Crash–hung_task_timeout_secs 作者:李子无为
http://blog.csdn.net/napolunyishi/article/details/17576739
2、How to fix hung_task_timeout_secs and blocked for more than 120 seconds problem 作者:skate
http://blog.csdn.net/wyzxg/article/details/44236263
3、关于修改 sysctl.conf,如何使该文件在系统重启之后生效 作者:dagebudagegeda
http://blog.csdn.net/u010616985/article/details/44563931
4、文件系统缓存dirty_ratio与dirty_background_ratio两个参数区别 作者:vincent
http://blog.sina.com.cn/s/blog_448574810101k1va.html
5、一次内核hung task分析 作者:humjb_1983
http://blog.chinaunix.net/uid-14528823-id-4406510.html
linux 出错 “INFO: task xxxxxx: 634 blocked for more than 120 seconds.”的3种解决方案(转)的更多相关文章
- linux 出错 “INFO: task xxxxxx: 634 blocked for more than 120 seconds.”的3种解决方案
https://blog.csdn.net/electrocrazy/article/details/79377214
- linux 出错 “INFO: task java: xxx blocked for more than 120 seconds.” 的3种解决方案
1 问题描述 最近搭建的一个linux最小系统在运行到241秒时在控制台自动打印如下图信息,并且以后每隔120秒打印一次. 仔细阅读打印信息发现关键信息是“hung_task_timeout_secs ...
- INFO: task java:27465 blocked for more than 120 seconds不一定是cache太大的问题
这几天,老有几个环境在中午收盘后者下午收盘后那一会儿,系统打不开,然后过了一会儿,进程就消失不见了,查看了下/var/log/message,有如下信息: Dec 12 11:35:38 iZ23nn ...
- task mysqld:26208 blocked for more than 120 seconds
早上10点左右,某台线上ECS服务器突然没响应. 查看日志,发现如下信息: Aug 14 03:26:01 localhost rsyslogd: [origin software="rsy ...
- kernel: INFO: task sadc:14833 blocked for more than 120 seconds.
早上一到,发现oracle连不上. 到主机上,发现只有oracleora11g一个进程,其他进程全没了. Nov 14 23:33:30 hs-test-10-20-30-15 kernel: INF ...
- Linux 日志报错 xxx blocked for more than 120 seconds
监控作业发现一台服务器(Red Hat Enterprise Linux Server release 5.7)从凌晨1:32开始,有一小段时间无法响应,数据库也连接不上,后面又正常了.早上检查了监听 ...
- Linux系统出现hung_task_timeout_secs和blocked for more than 120 seconds的解决方法
Linux系统出现系统没有响应. 在/var/log/message日志中出现大量的 “echo 0 > /proc/sys/kernel/hung_task_timeout_secs" ...
- 服务器卡死,重启报错: INFO: task blocked for more than 120 seconds
问题:服务器负载很高,但是CPU利用率不高.服务器经常夯住,网站打不开,SSH连接非常不稳定,输入命令夯住. 重启服务器报错: INFO: task blocked for more than 120 ...
- hung_task_timeout_secs 和 blocked for more than 120 seconds
https://help.aliyun.com/knowledge_detail/41544.html 问题现象 云服务器 ECS Linux 系统出现系统没有响应. 在/var/log/messag ...
随机推荐
- 2017.9.17 HTML学习总结---table标签
接上: 2.1.3 HTML表单标签与表单设计 表单是用户与服务器交互的主要方法,用户在表单中输入数据,提交给服务器程序来处理. (1)表单的组成: 文本框(text),密码框(password), ...
- VisualSVN 4.0.10 破解版 附上破解过程
VisualSVN一般情况下使用不需要破解,可以直接使用社区授权.但是社区授权不支持域用户. 如果要再域下面使用就需要破解了. 原版的VisualSVN和破解后的DLL已打包上传(仅供学习使用) 破解 ...
- 使用C#的新特性:可空类型
随着C#语言最新标准的出炉,现在它也提供了对可空类型的支持.这个小变化将会在处理那些包括可选项的数据库记录时非常有用.当然在其他地方,它也是非常有用的. 简单说来,可空数据类型就是包含了所定义的数据类 ...
- 搭建基于Express框架运行环境
安装express generator生成器 通过生成器自动创建项目 配置分析 一.安装 cnpm i -g express-generator express --version // 查看版本 e ...
- 一篇SSM框架整合友好的文章(二)
上一篇讲述了DAO 层,mybatis实现数据库的连接,DAO层接口设计,以及mybtis和spring的整合.DAO层采用接口设计方式实现,接口和SQL实现的分离,方便维护.DAO层所负责的仅仅是接 ...
- html和node.js实现websocket
websocket websocket是HTML5开始提供的一种单个TCP连接上进行全双工通讯的协议.它让客户端和服务端之间的数据交换变得更加简单,允许服务端主动向客户端推送数据.浏览器和服务器只需要 ...
- VMware虚拟机安装CentOS 7 Minimal 详细全过程
VMware虚拟机安装CentOS 7 Minimal 详细全过程记录,并进行CentOS7 的网络配置,本次安装的CentOS镜像版本为官方网站下载的 CentOS-7-x86_64-Minimal ...
- NFS文件系统存储服务部署
1 NFS介绍 1.1 什么是NFS? NFS是Network File System的缩写,中文名称是网络文件系统.它的主要功能是通过网络让不用的主机系统之间可以共享文件或者目录.NFS客户端通过挂 ...
- 使用JDBC操作数据库
准备工作 1.创建一个java项目导入mysql驱动包 2.在src目录中创建一个新的Java类 JDBC查询: package com.ATedu.test; import java.sql.Con ...
- LNMP+HAProxy+Keepalived负载均衡 - 基础服务准备
日志服务 修改日志服务配置并重启日志服务: ``` vim /etc/rsyslog.conf ``` 编辑系统日志配置,指定包含的配置文件路径和规则: ``` $IncludeConfig /etc ...