MapReduce-自定义 InputFormat 生成 SequenceFile
Hadoop 框架自带的 InputFormat 类型不能满足所有应用场景,需要自定义 InputFormat 来解决实际问题。
无论 HDFS 还是 MapReduce,在处理小文件时效率都非常低,但又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。可以自定义 InputFormat 实现小文件的合并。
将多个小文件合并成一个 SequenceFile 文件(SequenceFile 文件是 Hadoop 用来存储二进制形式的 key-value 对的文件格式),SequenceFile 里面存储着多个文件,存储的形式为文件路径+名称为key,文件内容为 value。
- 自定义 ImputFormat 步骤:
(1)自定义一个类继承 FilelnputFormat。- (1.1)重写 isSplitable() 方法,返回 false 不可切割
- (1.2)重写createRecordReader(),创建自定义的 RecordReader 对象,并初始化
(2)改写 RecordReader,实现一次读取一个完整文件封装为K-V。- (2.1)采用IO流一次读取一个文件输出到 value 中,因为设置了不可切片,最终把所有文件都封装到了 value 中
- (2.2)获取文件路径信息 + 名称,并设置 key
(3)输入时使用自定义的 InputFormat,在输出时使用 SequenceFileOutPutFormat 输出合并文件。
自定义一个 InputFormat,将小文件合并为一个文件(SequenceFile)
1.测试数据

2.切片数,与 TextInputFormat 一样,按照文件大小进行切片

3.读取数据方式,查看 k-v 值,按照自定义的方式在读取
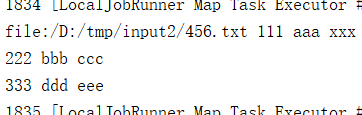
4.结果,大概可以看出是文件路径加上文件类容组成

5.测试代码
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.BytesWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
- import org.apache.log4j.BasicConfigurator;
- import java.io.IOException;
- public class SequenceFileDriver {
- static {
- try {
- // 设置 HADOOP_HOME 环境变量
- System.setProperty("hadoop.home.dir", "D://DevelopTools/hadoop-2.9.2/");
- // 日志初始化
- BasicConfigurator.configure();
- // 加载库文件
- System.load("D://DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
- } catch (UnsatisfiedLinkError e) {
- System.err.println("Native code library failed to load.\n" + e);
- System.exit(1);
- }
- }
- public static void main(String[] args) throws Exception, IOException {
- args = new String[]{"D:\\tmp\\input2", "D:\\tmp\\456"};
- // 1 获取job对象
- Configuration conf = new Configuration();
- Job job = Job.getInstance(conf);
- // 2 设置jar包存储位置、关联自定义的mapper和reducer
- job.setJarByClass(SequenceFileDriver.class);
- job.setMapperClass(SequenceFileMapper.class);
- job.setReducerClass(SequenceFileReducer.class);
- // 3 设置map输出端的kv类型
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(BytesWritable.class);
- // 4 设置最终输出端的kv类型
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(BytesWritable.class);
- // 5 设置输入输出路径
- FileInputFormat.setInputPaths(job, new Path(args[0]));
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
- // 6 设置输入的inputFormat
- job.setInputFormatClass(WholeFileInputFormat.class);
- // 7 设置输出的outputFormat
- job.setOutputFormatClass(SequenceFileOutputFormat.class);
- // 8 提交job
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
- class SequenceFileMapper extends Mapper<Text, BytesWritable, Text, BytesWritable> {
- @Override
- protected void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException {
- // 查看 k-v
- System.out.println(key + "\t" + new String(value.getBytes()));
- context.write(key, value);
- }
- }
- class SequenceFileReducer extends Reducer<Text, BytesWritable, Text, BytesWritable> {
- @Override
- protected void reduce(Text key, Iterable<BytesWritable> values, Context context) throws IOException, InterruptedException {
- for (BytesWritable value : values) {
- context.write(key, value);
- }
- }
- }
自定义的 InputFormat
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.BytesWritable;
- import org.apache.hadoop.io.IOUtils;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.InputSplit;
- import org.apache.hadoop.mapreduce.RecordReader;
- import org.apache.hadoop.mapreduce.TaskAttemptContext;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- public class WholeFileInputFormat extends FileInputFormat<Text, BytesWritable>{
- @Override
- public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
- WholeRecordReader recordReader = new WholeRecordReader();
- recordReader.initialize(split, context);
- return recordReader;
- }
- }
- class WholeRecordReader extends RecordReader<Text, BytesWritable>{
- FileSplit split;
- Configuration configuration;
- Text k = new Text();
- BytesWritable v = new BytesWritable();
- boolean isProgress = true;
- @Override
- public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
- // 初始化
- this.split = (FileSplit) split;
- configuration = context.getConfiguration();
- }
- @Override
- public boolean nextKeyValue() throws IOException, InterruptedException {
- if (isProgress) {
- byte[] buf = new byte[(int) split.getLength()];
- // 1 获取fs对象
- Path path = split.getPath();
- FileSystem fs = path.getFileSystem(configuration);
- // 2 获取输入流
- FSDataInputStream fis = fs.open(path);
- // 3 拷贝
- IOUtils.readFully(fis, buf, 0, buf.length);
- // 4 封装v
- v.set(buf, 0, buf.length);
- // 5 封装k
- k.set(path.toString());
- // 6 关闭资源
- IOUtils.closeStream(fis);
- isProgress = false;
- return true;
- }
- return false;
- }
- @Override
- public Text getCurrentKey() throws IOException, InterruptedException {
- return k;
- }
- @Override
- public BytesWritable getCurrentValue() throws IOException, InterruptedException {
- return v;
- }
- @Override
- public float getProgress() throws IOException, InterruptedException {
- // 进度
- return 0;
- }
- @Override
- public void close() throws IOException {
- // 关闭资源
- }
- }
生成的 part-r-00000 文件就是合并后的 SequenceFile 文件
https://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/SequenceFile.html
https://wiki.apache.org/hadoop/SequenceFile
MapReduce-自定义 InputFormat 生成 SequenceFile的更多相关文章
- 【Hadoop离线基础总结】MapReduce自定义InputFormat和OutputFormat案例
MapReduce自定义InputFormat和OutputFormat案例 自定义InputFormat 合并小文件 需求 无论hdfs还是mapreduce,存放小文件会占用元数据信息,白白浪费内 ...
- MapReduce自定义InputFormat和OutputFormat
一.自定义InputFormat 需求:将多个小文件合并为SequenceFile(存储了多个小文件) 存储格式:文件路径+文件的内容 c:/a.txt I love Beijing c:/b.txt ...
- MapReduce自定义InputFormat,RecordReader
MapReduce默认的InputFormat是TextInputFormat,且key是偏移量,value是文本,自定义InputFormat需要实现FileInputFormat,并重写creat ...
- MapReduce之自定义InputFormat
在企业开发中,Hadoop框架自带的InputFormat类型不能满足所有应用场景,需要自定义InputFormat来解决实际问题. 自定义InputFormat步骤如下: (1)自定义一个类继承Fi ...
- MapReduce框架原理-InputFormat数据输入
InputFormat简介 InputFormat:管控MR程序文件输入到Mapper阶段,主要做两项操作:怎么去切片?怎么将切片数据转换成键值对数据. InputFormat是一个抽象类,没有实现怎 ...
- 自定义InputFormat和OutputFormat案例
一.自定义InputFormat InputFormat是输入流,在前面的例子中使用的是文件输入输出流FileInputFormat和FileOutputFormat,而FileInputFormat ...
- Hadoop案例(六)小文件处理(自定义InputFormat)
小文件处理(自定义InputFormat) 1.需求分析 无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案.将多个小文件合并 ...
- 自定义inputformat和outputformat
1. 自定义inputFormat 1.1 需求 无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案 1.2 分析 小文件的优 ...
- Hadoop_28_MapReduce_自定义 inputFormat
1. 自定义inputFormat 1.1.需求: 无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件,此时就需要有相应解决方案; 1.2.分析: 小文件的优化 ...
随机推荐
- 减小SSN影响
单板级SSN 从单板级来看,芯片中多个逻辑门同时翻转时,将从单板电源和地平面瞬间汲取较大的电流.任何电源分配系统都存在着阻抗,特别是感抗,导致在短时间内电压调整模块来不及供应这些电流,从而在单板和电源 ...
- HDOJ1010 (DFS+奇偶剪枝)
Tempter of the Bone Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Othe ...
- 阿里巴巴开源项目: canal 基于mysql数据库binlog的增量订阅&消费
背景 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求.不过早期的数据库同步业务,主要是基于trigger的方式获取增 量变更,不过从2010年开始,阿里系公司开始逐步的 ...
- Spring Boot整合Rabbitmq
Spring Boot应用中整合RabbitMQ,并实现一个简单的发送.接收消息的例子来对RabbitMQ有一个直观的感受和理解. 在Spring Boot中整合RabbitMQ是一件非常容易的事,因 ...
- Java-API:javax.servlet.http.HttpServletRequest
ylbtech-Java-API:javax.servlet.http.HttpServletRequest 1.返回顶部 1. javax.servlet.http Interface HttpSe ...
- [转]RabbitMQ三种Exchange模式(fanout,direct,topic)的性能比较
RabbitMQ中,所有生产者提交的消息都由Exchange来接受,然后Exchange按照特定的策略转发到Queue进行存储 RabbitMQ提供了四种Exchange:fanout,direct, ...
- linux环境下Apache+Tomcat集群配置
写在前面 apache配置多个tomcat,实现请求分流,多个tomcat服务均衡负载,增加服务的可靠性.最近研究了一下,遇到许多问题,记录一下,方便以后查阅,不喜欢apache,nginx也是可以做 ...
- H.264学习笔记
1.帧和场的概念 视频的一场或一帧可用来产生一个编码图像.通常,视频帧可以分成两种类型:连续或隔行视频帧.我们平常看的电视是每秒25帧,即每秒更换25个图像,由于视觉暂留效应,所以人眼不会感到闪烁.每 ...
- DAY9-python并发之多进程
一 multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程.P ...
- Class类动态加载类的用法
编译时刻加载类出现的问题:一个功能有错,所有功能都用不了 动态加载类: