spark中的RDD以及DAG
今天,我们就先聊一下spark中的DAG以及RDD的相关的内容
1.DAG:有向无环图:有方向,无闭环,代表着数据的流向,这个DAG的边界则是Action方法的执行
2.如何将DAG切分stage,stage切分的依据:有宽依赖的时候要进行切分(shuffle的时候,
也就是数据有网络的传递的时候),则一个wordCount有两个stage,
一个是reduceByKey之前的,一个事reduceByKey之后的(图1),
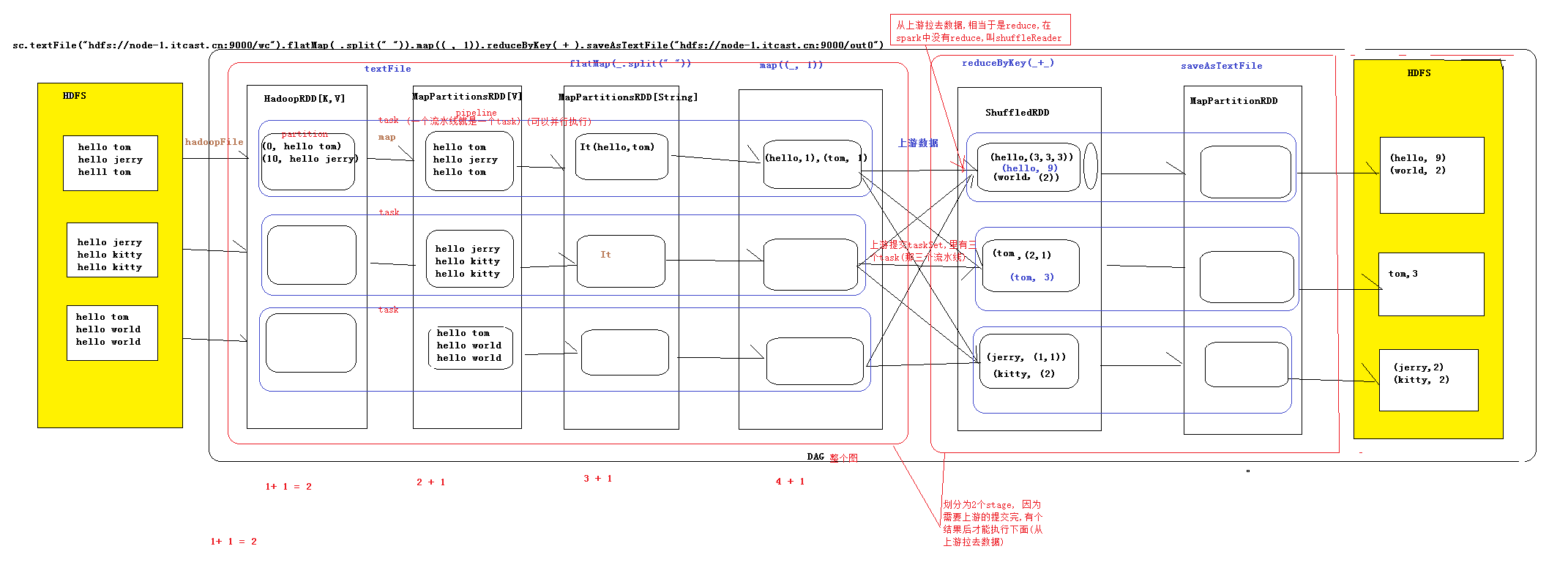
则我们可以这样的理解,当我们要进行提交上游的数据的时候,
此时我们可以认为提交的stage,但是严格意义上来讲,我们提交的是Task
sets(Task的集合),这些Task可能业务逻辑相同,就是处理的数据不同
3.流程
构建RDD形成DAG遇到Action的时候,前面的stage先提交,提交完成之后再交给
下游的数据,在遇到TaskScheduler,这个时候当我们遇到Action的方法的时候,我们
就会让Master决定让哪些Worker来执行这个调度,但是到了最后我们真正的传递的
时候,我们用的是Driver给Worker传递数据(其实是传递到Excutor里面,这个里面执行
真正的业务逻辑),Worker中的Excutor只要启动,则此后就和Master没有多大关系了
4.宽窄依赖
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)以及
宽依赖(wide dependency).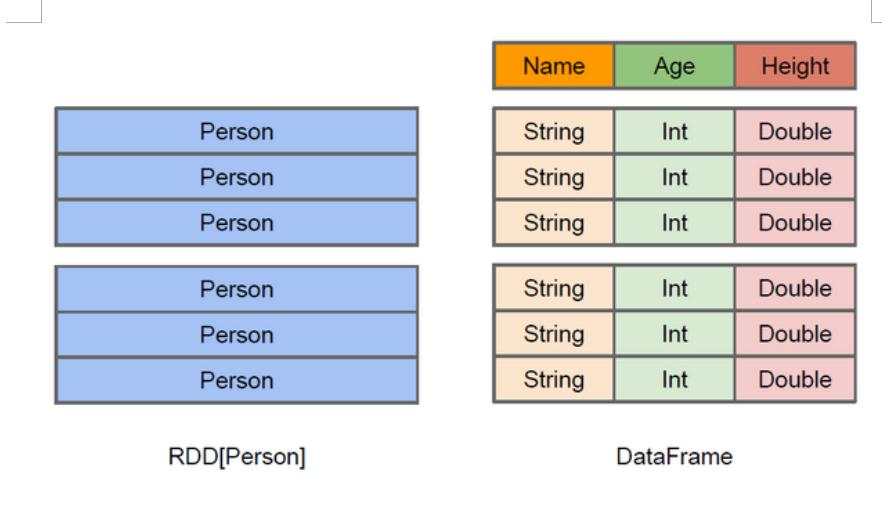

窄分区的划分依据,如果后面的一个RDD,前面的一个RDD有一个唯一对应的RDD,
则此时就是窄依赖,就相当于一次函数,y对应于一个x,而宽依赖则是类似于,前面的
一个RDD,则此时一个RDD对应多个RDD,就相当于二次函数,一个y对应多个x的值
5.DAG的生成
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成
DAG,根据RDD的之间的依赖关系的不同将DAG划分为不同的stage,对于窄依赖,
partition的转换处理在stage中完成计算,对于宽依赖,由于有shuffle的存在,只能在
partentRDD处理完成后,才能开始接下来的计算,因此宽依赖是划分stage的依据
一般我们认为join是宽依赖,但是对于已经分好区的join来说,我们此时可以认为这个
时候的join是窄依赖
spark中的RDD以及DAG的更多相关文章
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- Spark中的RDD和DataFrame
什么是DataFrame 在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格. RDD和DataFrame的区别 DataFrame与RDD的主要区别在 ...
- 浅谈大数据神器Spark中的RDD
1.究竟什么是RDD呢? 有人可能会回答是:Resilient Distributed Dataset.没错,的确是如此.但是我们问这个实际上是想知道RDD到底是个什么东西?以及它到底能干嘛?好的,有 ...
- Spark中的RDD操作简介
map(func) 对数据集中的元素逐一处理,变为新的元素,但一个输入元素只能有一个输出元素 scala> pairData.collect() res6: Array[Int] = Array ...
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark 核心概念RDD
文章正文 RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此, ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
- Spark学习笔记——RDD编程
1.RDD——弹性分布式数据集(Resilient Distributed Dataset) RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD.转换已有的RDD和调用RDD操作 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
随机推荐
- 移动端纯CSS3制作圆形进度条所遇到的问题
近日在开发的页面中,需要制作一个动态的圆形进度条,首先想到的是利用两个矩形,宽等于直径的一半,高等于直径,两个矩形利用浮动贴在一起,设置overflow:hidden属性,作为盒子,内部有一个与其宽高 ...
- 即将要被淘汰的兼容之--CSS Hack
css hack 条件注释法只在IE下生效<!--[if IE]>这段文字只在IE浏览器显示<![endif]-->只在IE6下生效<!--[if IE 6]>这段 ...
- 测试驱动开发(TDD)及测试框架Mocha.js入门学习
组里马上要转变开发模式,由传统的开发模式(Developer开发,QA测试),转变为尝试TDD(Test-driven development,测试驱动开发)的开发模型.由此将不存在QA的角色,或者仅 ...
- react-native —— 在Mac上搭建React Native Android开发环境
需要:JDK,Android SDK,Node.js 1.安装JDK 去Java官网下载列表选择Mac OS X x64版 2.安装Android SDK 虽然现在谷歌推荐使用Android ...
- python模块详解 shelve
shelve模块是一个简单的k,v 将内存数据通过文件持久化的模块,可以持久化任何pickle可以支持的python数据.简单的说对 pickle的更上一层的封装. 写文件 import shelve ...
- linux服务器tomcat启动时,不能加载项目
---恢复内容开始--- 问题描述:tomcat启动时候,能够成功启动但是项目不能加载,查看catalina.out后出现以下的错误 due to a StackOverflowError. Poss ...
- SaberSama【css总结】
为什么要转过来呢? 因为我觉到,同样是一个初学者,应该互相学习,交流. css:Cascading Style Sheets 层叠样式表 CSS引入方式: 1.内嵌: <p style=&quo ...
- windows服务器间文件同步搭建步骤搜集
Rsync https://www.cnblogs.com/janas/p/3321087.html https://yq.aliyun.com/ziliao/110867 subersion协议 h ...
- Last_Errno: 1396
Last_Errno: 1396 Last_Error: Error 'Operation CREATE USER failed for 'usera63'@'%'' on query. Defa ...
- dotNetFx40_Client_x86_x64和dotNetFx40_Full_x86_x64这两个有什么区别?两个都要安装还是安装其中一个?
这个是NET Framework 4.0的安装文件它是支持生成和运行下一代应用程序和 XML Web Services 的内部 Windows 组件,很多基于此架构的程序需要它的支持才能够运行.简单的 ...