机器学习实战 -- 决策树(ID3)
机器学习实战 -- 决策树(ID3)
ID3是什么我也不知道,不急,知道他是干什么的就行
ID3是最经典最基础的一种决策树算法,他会将每一个特征都设为决策节点,有时候,一个数据集中,某些特征属性是不必要的或者说信息熵增加的很少,这种决策信息是可以合并的修剪的,但是ID3算法并不会这么做
决策树的核心论点是香农信息论,借此理论得出某种分类情况下的信息熵
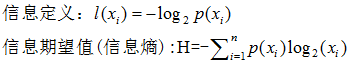
某种决策下,分类趋向于统一,则香农熵很小(熵描述杂乱无序的程度,如果'YES', 'NO' 可能性对半分,那么这个分类决策最终是趋向于杂乱的熵值会很大, 只出现 'YES' 那么表示这个决策的结果趋向于一个统一的结果,固定,那么熵就很小)
综上:某个决策节点下,信息熵越小,说明这个决策方式越好
整个决策树分为三个部分:1.学习出决策树 2.绘制决策树 3.存储决策树
比起sklearn这个决策树更简单,没有考虑基尼系数,只关注信息熵
- from math import log
- '''''
- 计算香农熵
- '''
- def calcShannonEnt(dataset):
- '''''
- dataset —— 数据集 eg:[[f1,f2,f3,L1],[f1,f2,f3,L2]]
- f表示特征,L表示标签
- shannonEnt —— 香农熵
- '''
- numEntries=len(dataset) #统计数据集中样本数量
- labelCounts={}
- for featVec in dataset:
- currentLabel=featVec[-1]
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel]=0
- labelCounts[currentLabel] +=1
- #for循环统计数据集中各个标签量的个数。如:有几种情况下是'no'
- shannonEnt=0.0
- for key in labelCounts:
- prob=float(labelCounts[key])/numEntries
- shannonEnt-=prob*log(prob,2)
- #香农熵计算见word
- return shannonEnt
- '''''
- 根据特征值划分数据集
- '''
- def splitDataSet(dataSet,axis,value):
- '''''
- dataset ——要数据集
- axis ——要从哪一个特征划分
- value ——精确到特征下的哪一个值
- 个特征值为0时划分
- 实际效果:将每个样本中特征值符合(axis,value)定位条件的样本找出来,并删除这个特征
- retDataSet——按照特征值划分出的数据子集
- '''
- retDataSet=[]
- for featVec in dataSet:
- if featVec[axis] == value: #找到定位点
- _=featVec.copy() #拷贝,防止删除特征时影响到原数据集
- del _[axis] #删除特征
- retDataSet.append(_) #将该样本添加到子集中
- return retDataSet
- '''''
- 判断当前数据集中最好的数据划分形式
- '''
- def Best(dataSet):
- numFeatures=len(dataSet[0])-1
- baseEntropy=calcShannonEnt(dataSet)
- bestInfoGain=0.0
- bestFeature=-1
- for i in range(numFeatures):
- #将每个特征都作为决策节点进行一一尝试,找出最佳
- featList=[example[i] for example in dataSet]
- #提取每个样本中第i个特征
- uniqueVals=set(featList)
- newEntropy=0.0
- for value in uniqueVals:
- #一个特征下有几个特征值,分特征值进行香农熵计算
- subDataSet=splitDataSet(dataSet,i,value)
- prob=len(subDataSet)/float(len(dataSet))
- newEntropy+=prob*calcShannonEnt(subDataSet)
- infoGain=baseEntropy-newEntropy
- if(infoGain>bestInfoGain):
- bestInfoGain=infoGain
- bestFeature=i
- return bestFeature
- '''''
- 多数表决
- 当所有特征都决策完时,标签还没有统一,此时就使用多数服从少数的原则
- 该分类下,哪种标签多,就以哪种标签作为分类依据
- '''
- def majorityCnt(classList):
- '''''
- classlist ——关于标签的列表
- 书上的
- classCount={}
- for vote in classList:
- if vote not in classCount.keys():
- classCount[vote]=0
- classCount[vote]+=1
- sortedClassCount=sorted(classCount.items(),
- key=operator.itemgetter(1),
- reverse=True)
- return sortedClassCount[0][0]
- '''
- value=0
- for i in classList:
- if classlist.count(i) >value:
- max_label=i
- value=classlist.count(i)
- return max_label
- def createTree(dataSet,labels):
- classList=[example[-1] for example in dataSet]
- #标签中只有一种了,说明到叶子节点了,直接返回标签
- if len(set(classList)) ==1:
- return classList[0]
- #样本中没有特征了,只能多数服从小数了
- if len(dataSet[0])==1:
- return majorityCnt(classList)
- #先找好决策节点
- bestFeat=Best(dataSet)
- bestFeatlabel=labels[bestFeat]
- myTree={bestFeatlabel:{}}
- del labels[bestFeat]#此处,标签列表要随着子集变化而变化
- #找出决策节点后,继续深入分析特征值
- featValues=[example[bestFeat] for example in dataSet]
- uniqueVals=set(featValues)
- #遍历特征值进行树创建
- for value in uniqueVals:
- subLabels=labels[:]
- #此处,记得保留最顶层的标签,不能递归的时候让孙子辈的子节点把爷爷辈的标签给改了
- myTree[bestFeatlabel][value]=createTree(
- splitDataSet(dataSet,bestFeat,value),
- subLabels)
- return myTree
- '''''
- -------------------------
- 绘制决策树
- 主要是接通matplotlib中的annotate函数来绘画
- 实际上现在可以借用graphviz来绘制,没去了解这个东西
- -------------------------
- '''
- import matplotlib.pyplot as plt
- #建立绘图参数
- decisionNode=dict(boxstyle='sawtooth',fc='0.8')
- leafNode=dict(boxstyle='round',fc='0.8')
- arrow_args=dict(arrowstyle='<-')
- #创建图纸,以及设立好初始xoff和yoff
- def createPlot(inTree):
- fig=plt.figure(1,facecolor='white')
- fig.clf()
- axprops=dict(xticks=[],yticks=[])
- createPlot.ax1=plt.subplot(111,frameon=False,**axprops)
- plotTree.totalW=float(getNumLeafs(inTree))
- plotTree.totalD=float(getTreeDepth(inTree))
- plotTree.xoff=-0.5/plotTree.totalW
- plotTree.yoff=1.0
- plotTree(inTree,(0.5,1.0),'')
- plt.show()
- #递归绘制决策树,遇到决策节点就递归,所以最后会有那条+1.0/plotTree.totalD语句返回分叉点
- def plotTree(myTree,parentPt,nodeTxt):
- numLeafs=getNumLeafs(myTree)
- depth=getTreeDepth(myTree)
- firstStr=list(myTree.keys())[0]
- cntrPt=(plotTree.xoff+(1+float(numLeafs))/2.0/plotTree.totalW,plotTree.yoff)
- #上面关于子节点的x值计算,有点绕,可以慢慢调整参数值,知道如何影响决策图的
- plotMidText(cntrPt,parentPt,nodeTxt)
- plotNode(firstStr,cntrPt,parentPt,decisionNode)
- secondDict=myTree[firstStr]
- plotTree.yoff=plotTree.yoff-1.0/plotTree.totalD
- for key in secondDict.keys():
- if type(secondDict[key])==dict:
- plotTree(secondDict[key],cntrPt,str(key))
- else:
- plotTree.xoff=plotTree.xoff+1.0/plotTree.totalW
- plotNode(secondDict[key],(plotTree.xoff,plotTree.yoff),cntrPt,leafNode)
- plotMidText((plotTree.xoff,plotTree.yoff),cntrPt,str(key))
- plotTree.yoff=plotTree.yoff+1.0/plotTree.totalD
- '''''
- 获取叶子节点数量
- 遍历所有节点,只要不是dict即不是决策节点,numLeafs就+1
- '''
- def getNumLeafs(myTree):
- numLeafs=0
- firstStr=list(myTree.keys())[0]
- secondDict=myTree[firstStr]
- for key in secondDict.keys():
- if type(secondDict[key]) ==dict:
- numLeafs+=getNumLeafs(secondDict[key])
- else:
- numLeafs+=1
- return numLeafs
- '''''
- 获取决策节点的数量
- 遍历所有节点,只要是dict,即决策节点,深度就+1
- 注意的是,没遍历一个特征就需要和储存的depth比较一番,选取最深的才是树的深度
- '''
- def getTreeDepth(myTree):
- maxDepth=0
- firstStr=list(myTree.keys())[0]
- secondDict=myTree[firstStr]
- for key in secondDict.keys():
- if type(secondDict[key])==dict:
- thisTreeDepth=1+getTreeDepth(secondDict[key])
- else:
- thisTreeDepth=1
- if thisTreeDepth>maxDepth:
- maxDepth=thisTreeDepth
- return maxDepth
- #在连接线的中间标注特征值
- def plotMidText(cntrPt,parentPt,txtString):
- xmid=(parentPt[0]-cntrPt[0])/2.0+cntrPt[0]
- ymid=(parentPt[1]-cntrPt[1])/2.0+cntrPt[1]
- createPlot.ax1.text(xmid,ymid,txtString)
- #绘制节点以及箭头
- def plotNode(nodeTxt,centerPt,parentPt,nodeType):
- createPlot.ax1.annotate(nodeTxt,xy=parentPt,xycoords='axes fraction',
- xytext=centerPt,textcoords='axes fraction',
- va='center',ha='center',bbox=nodeType,
- arrowprops=arrow_args)
- '''''
- -------------------------
- 储存决策树,使用pickle,序列化存储
- -------------------------
- '''
- import pickle
- def storeTree(inputTree,filename):
- with open(filename,'wb') as fw:
- pickle.dump(inputTree,fw)
- def loadTree(filename):
- with open(filename,'rb') as fr:
- return pickle.load(fr)
- if __name__=='__main__':
- fr=open('lenses.txt')
- lenses=[inst.strip().split('\t') for inst in fr.readlines()]
- lensesLabels=['age','prescript','astigmatic','tearRate']
- lensesTree=createTree(lenses,lensesLabels)
- createPlot(lensesTree)
- storeTree(lensesTree,'lensesTree-syt.txt')
机器学习实战 -- 决策树(ID3)的更多相关文章
- [机器学习实战] 决策树ID3算法
1. 决策树特点: 1)优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据. 2)缺点:可能会产生过度匹配问题. 3)适用数据类型:数值型和标称型. 2. 一般流程: ...
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
- 机器学习实战---决策树CART回归树实现
机器学习实战---决策树CART简介及分类树实现 一:对比分类树 CART回归树和CART分类树的建立算法大部分是类似的,所以这里我们只讨论CART回归树和CART分类树的建立算法不同的地方.首先,我 ...
- [机器学习&数据挖掘]机器学习实战决策树plotTree函数完全解析
在看机器学习实战时候,到第三章的对决策树画图的时候,有一段递归函数怎么都看不懂,因为以后想选这个方向为自己的职业导向,抱着精看的态度,对这本树进行地毯式扫描,所以就没跳过,一直卡了一天多,才差不多搞懂 ...
- 《机器学习实战》ID3算法实现
注释:之前从未接触过决策树,直接上手对着书看源码,有点难,确实有点难-- 本代码是基于ID3编写,之后的ID4.5和CART等还没学习到 一.决策树的原理 没有看网上原理,直接看源码懂得原理,下面是我 ...
- 机器学习实战---决策树CART简介及分类树实现
https://blog.csdn.net/weixin_43383558/article/details/84303339?utm_medium=distribute.pc_relevant_t0. ...
- 决策树ID3算法python实现 -- 《机器学习实战》
from math import log import numpy as np import matplotlib.pyplot as plt import operator #计算给定数据集的香农熵 ...
- 机器学习之决策树(ID3 、C4.5算法)
声明:本篇博文是学习<机器学习实战>一书的方式路程,系原创,若转载请标明来源. 1 决策树的基础概念 决策树分为分类树和回归树两种,分类树对离散变量做决策树 ,回归树对连续变量做决策树.决 ...
- 机器学习之决策树一-ID3原理与代码实现
决策树之系列一ID3原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9429257.html 应用实 ...
随机推荐
- better-scroll 遇到的问题 1
备注:better-scroll 实现下拉,是父子层的结构,父层的第一个子元素,如果超出父容器,那么就可以实现下拉 问题: 今天在使用better-scroll实现下拉功能,遇到了一个问题 &quo ...
- SharePoint 栏的三种名字Filed :StaticName、 InternalName、 DisplayName
SharePoint 的栏,有3个名字, StaticName InternalName DisplayName. 当在第一次创建栏的时候,这3个名字一起进行创建,并且都一样. <FIELD ...
- Android(java)学习笔记97:使用GridView以及重写BaseAdapter
1. BaseAdapter: 对于ListView.GridView.Gallery.Spinner等等,它是它们的适配器,直接继承自接口类Adapter的,使用BaseAdapter时需要重写很多 ...
- 2017.9.15 HTML学习总结---表格table
2.7 表格<table>的属性: 属性 用途 width 表格宽度 height 表格高度 align 表格水平对齐 border ...
- android获取传感器数据
传感器获取数据的频率: https://blog.csdn.net/huangbiao86/article/details/6745933 SensorManager.SENSOR_DELAY_GAM ...
- Linux下进程信息的深入分析[转]
这里我们主要介绍进程的状态,进程的状态可以通过/proc/PID/status来查看,也可以通过/proc/PID/stat来查看. 如果说到工具大家用的最多的ps也可以看到进程的信息.这里我们通过/ ...
- 安装ubuntu-tweak
第一步:添加tweak源 sudo add-apt-repository ppa:tualatrix/ppa 第二步:更新 sudo apt-get update 第三步:安装ubuntu-t ...
- Visual Studio Code快捷键_Linux
Keyboard shortcuts for Linux Basic editing Ctrl + X Cut line(empty selection) Ctrk + C Copy line(e ...
- lambda函数,内置map()函数及filter()函数
8.1 lambda函数 作用及意义: 1.没必要专门定义函数,给函数起名,起到精简的效果 2.简化代码的可读性 def ds(x): return 2 * x + 1 ds(5) ---11 g ...
- 武者Vue
1 - Introduction 2 - The Vue Instance 3 - Data & Methods 4 - Data Binding 5 - Events 6 - Event M ...