python+NLTK 自然语言学习处理八:分类文本一
从这一章开始将进入到关键部分:模式识别。这一章主要解决下面几个问题
1 怎样才能识别出语言数据中明显用于分类的特性
2 怎样才能构建用于自动执行语言处理任务的语言模型
3 从这些模型中我们可以学到那些关于语言的知识。
监督式分类:
分类是为给定的输入选择正确的类标签。就好比身份证上的身份证号。每个身份证号都能标识出对应的一个人。在比如我们从一个固定的主题领域列表中,如“体育”,“技术”和“政治”来判断新闻报道的主题是什么
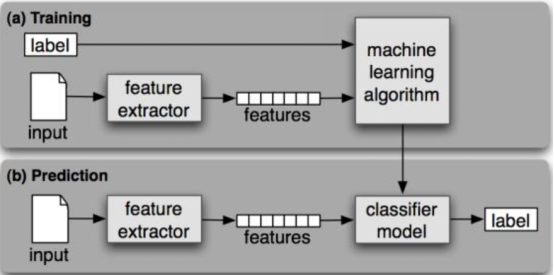
下图是监督式分类的框架图。在训练过程中,特征提取器将每一个输入值转换为特征集。这些特征集捕捉到每个输入中应被用于分类的基本信息。然后特征集与标签的配对放入到机器学习算法中,生成模型。
在之前的章节中,我们从nltk.corpus.names能够获得2个文件,分别是male.txt和female.txt。从里面的结果可以看到男性和女性的名字有各自鲜明的特点。以a,e,i结尾的姓名很可能是女性姓名。而以k,o,r,s结尾的姓名很可能是男性姓名。因此我们要区分人名是男性还是女性,就需要建立一个分类器从而更精确的模拟这些差异。
创建分类器的第一步是决定什么样的输入特征相关的。以及如何为这些特征编码,下面的例子从寻找给定名称的最后一个字母开始。建立一个特征提取器函数,这个函数返回一个字典,其中包含给定名称的相关信息
def gender_features(word):
return {'last_letter':word[-1]}
这个函数返回的字典被称为特征集。在后面的应用中,我们将不同的姓名输入其中得到最后一个字母。
接下来定义一个特征提取器,同时准备一些例子和其对应的类标签
from nltk.corpus import names
names=([(name,'male') for name in names.words('male.txt')]+[(name,'female') for name in names.words('female.txt')])
上面的这个特征提取器得到一个列表。分别是从male.txt和female.txt中提取出一个元组。元组分别是姓名以及对应的性别。接下来使用特征提取器处理names数据。并把特征集的结果链表划分为训练集和测试集。训练集用于训练新的朴素贝叶斯分类器。
names=([(name,'male') for name in names.words('male.txt')]+[(name,'female') for name in names.words('female.txt')])
featuresets=[(gender_features(n),g) for (n,g) in names]
train_set,test_set=featuresets[500:],featuresets[:500]
classfier=nltk.NaiveBayesClassifier.train(train_set)
在上面的代码中,对于names中的名字提取最后一个字母,并保持这个字母的性别属性得到一个特征集。然后取这个特征集500以后的集合作为训练集合,前500个作为测试集合。最后调用NaiveBayesClassifier.train贝叶斯进行训练。然后我们输入一个在之前names不存在的名字看下判断结果如何
classfier.classify(gender_features('neo'))
在这里输入neo,得到的结果是male.结果正确。我们来看下对于这个采用训练集的分类器评估的准确性有多少。
nltk.classify.accuracy(classfier,test_set)
结果是0.776。77%的识别率还算可以
最后我们检查分类器,确定那些特征对于区分名字的性别是最有效的。我们只列出其中5个
classfier.show_most_informative_features(5)
Most Informative Features
last_letter = 'a' female : male = 33.0 : 1.0
last_letter = 'k' male : female = 32.8 : 1.0
last_letter = 'f' male : female = 16.7 : 1.0
last_letter = 'p' male : female = 11.2 : 1.0
last_letter = 'd' male : female = 10.1 : 1.
从上面的结果可以看到,以a结尾的名字女性的比例是男性的33倍.而以k结尾的名字男性的比例是女性的32倍。这些比率称为似然比,可以用于比较不同特征-结果关系。
从上面可以看到,其实对于名字的分类最重要的在于选择相关的特征。因此建立分类器的工作之一就是找出那些特征可能是相关的。前面的特征选取是针对姓名的最后一个字母。那么这个特征是否可以进一步进行优化呢。比如考虑第一个字母或者是每个字母出现的次数等等。首先来看下下面的代码:
def gender_features_update(word):
features={}
features["firstletter"]=word[0].lower()
features["lastletter"]=word[-1].lower()
for letter in 'abcdefghijklmnopqrstuvwxyz':
features["count(%s)" % letter]=word.lower().count(letter)
features["has(%s)" % letter]=(letter in word.lower())
print(features)
在这个更新版的特征提取器中,首先统计每个名字在字母中出现的次数,然后统计字母是否在名字中出现,得到如下的结果。这个特征集收集的特征够详细了。那么实际效果如何呢
{'firstletter': 'd', 'lastletter': 'd', 'count(a)': 1, 'has(a)': True, 'count(b)': 0, 'has(b)': False, 'count(c)': 0, 'has(c)': False, 'count(d)': 2, 'has(d)': True, 'count(e)': 0, 'has(e)': False, 'count(f)': 0, 'has(f)': False, 'count(g)': 0, 'has(g)': False, 'count(h)': 0, 'has(h)': False, 'count(i)': 1, 'has(i)': True, 'count(j)': 0, 'has(j)': False, 'count(k)': 0, 'has(k)': False, 'count(l)': 0, 'has(l)': False, 'count(m)': 0, 'has(m)': False, 'count(n)': 0, 'has(n)': False, 'count(o)': 0, 'has(o)': False, 'count(p)': 0, 'has(p)': False, 'count(q)': 0, 'has(q)': False, 'count(r)': 0, 'has(r)': False, 'count(s)': 0, 'has(s)': False, 'count(t)': 0, 'has(t)': False, 'count(u)': 0, 'has(u)': False, 'count(v)': 1, 'has(v)': True, 'count(w)': 0, 'has(w)': False, 'count(x)': 0, 'has(x)': False, 'count(y)': 0, 'has(y)': False, 'count(z)': 0, 'has(z)': False}
names=([(name,'male') for name in names.words('male.txt')]+[(name,'female') for name in names.words('female.txt')])
featuresets=[(gender_features_update(n),g) for (n,g) in names]
train_set,test_set=featuresets[500:],featuresets[:500]
classfier=nltk.NaiveBayesClassifier.train(train_set)
print(nltk.classify.accuracy(classfier,test_set))
得到的结果是0.742。比之前的77%低了2个百分点。原因在于提供太多的特征,那么该算法将高度依赖训练数据的特性而对一般化的新例子不起作用。这个问题被称为过拟合,在小型训练集上运行经常会出现这个问题。
那么我们该如何选择特征集呢,一种方法就是进行错误分析。首先选择开发集,然后将开发集分为训练集和开发测试集
train_names=names[1500:]
devtest_names=names[500:1500]
test_names=names[:500]
train_set=[(gender_features(n),g) for (n,g) in train_names]
devtest_set = [(gender_features(n), g) for (n, g) in devtest_names]
test_set = [(gender_features(n), g) for (n, g) in test_names]
但是测试下来识别度只有0.34. 那如何优化呢
使用开发测试集可以生成分类器在预测名字性别时出现的错误列表
error=[]
for (name,tag) in devtest_names:
guess=classfier.classify(gender_features(name))
if guess != tag:
error.append((tag,guess,name))
for (tag,guess,name) in sorted(error):
print('correct=%s guess=%s name=%s' % (tag,guess,name))
结果:
correct=male guess=female name=Clinton
correct=male guess=female name=Clive
correct=male guess=female name=Clyde
correct=male guess=female name=Cob
correct=male guess=female name=Cobb
correct=male guess=female name=Cobbie
correct=male guess=female name=Cobby
correct=male guess=female name=Cody
correct=male guess=female name=Colbert
correct=male guess=female name=Cole
correct=male guess=female name=Coleman
correct=male guess=female name=Colin
correct=male guess=female name=Collin
correct=male guess=female name=Conan
correct=male guess=female name=Connie
correct=male guess=female name=Connolly
correct=male guess=female name=Conroy
correct=male guess=female name=Constantin
correct=male guess=female name=Constantine
correct=male guess=female name=Conway
correct=male guess=female name=Corbin
correct=male guess=female name=Corby
correct=male guess=female name=Corey
correct=male guess=female name=Corky
correct=male guess=female name=Corrie
correct=male guess=female name=Cortese
correct=male guess=female name=Corwin
correct=male guess=female name=Cory
correct=male guess=female name=Costa
correct=male guess=female name=Courtney
correct=male guess=female name=Creighton
correct=male guess=female name=Curt
correct=male guess=female name=Curtice
correct=male guess=female name=Cy
correct=male guess=female name=Cyril
correct=male guess=female name=Cyrill
correct=male guess=female name=Cyrille
correct=male guess=female name=Dabney
correct=male guess=female name=Daffy
correct=male guess=female name=Dale
correct=male guess=female name=Dalton
correct=male guess=female name=Damian
correct=male guess=female name=Damien
correct=male guess=female name=Damon
correct=male guess=female name=Dan
correct=male guess=female name=Dana
correct=male guess=female name=Dane
correct=male guess=female name=Dani
correct=male guess=female name=Danie
correct=male guess=female name=Daniel
correct=male guess=female name=Dannie
correct=male guess=female name=Danny
correct=male guess=female name=Dante
correct=male guess=female name=Darby
correct=male guess=female name=Darcy
correct=male guess=female name=Daren
correct=male guess=female name=Darian
correct=male guess=female name=Darien
correct=male guess=female name=Darin
correct=male guess=female name=Darrel
correct=male guess=female name=Darrell
correct=male guess=female name=Darren
correct=male guess=female name=Darrin
correct=male guess=female name=Darryl
correct=male guess=female name=Darth
correct=male guess=female name=Darwin
correct=male guess=female name=Daryl
correct=male guess=female name=Daryle
correct=male guess=female name=Dave
correct=male guess=female name=Davey
correct=male guess=female name=Davidde
correct=male guess=female name=Davide
correct=male guess=female name=Davidson
correct=male guess=female name=Davie
correct=male guess=female name=Davin
correct=male guess=female name=Davon
correct=male guess=female name=Davy
correct=male guess=female name=Dawson
correct=male guess=female name=Dean
correct=male guess=female name=Deane
correct=male guess=female name=Del
correct=male guess=female name=Delbert
correct=male guess=female name=Dell
correct=male guess=female name=Demetre
correct=male guess=female name=Demetri
correct=male guess=female name=Dennie
correct=male guess=female name=Denny
correct=male guess=female name=Derby
correct=male guess=female name=Derrin
correct=male guess=female name=Derrol
correct=male guess=female name=Derron
correct=male guess=female name=Deryl
correct=male guess=female name=Devin
correct=male guess=female name=Devon
correct=male guess=female name=Dewey
correct=male guess=female name=Dewitt
correct=male guess=female name=Dickey
correct=male guess=female name=Dickie
correct=male guess=female name=Dietrich
correct=male guess=female name=Dillon
correct=male guess=female name=Dimitri
correct=male guess=female name=Dimitrou
correct=male guess=female name=Dimitry
correct=male guess=female name=Dion
correct=male guess=female name=Dmitri
correct=male guess=female name=Dominique
correct=male guess=female name=Don
correct=male guess=female name=Donal
correct=male guess=female name=Donn
correct=male guess=female name=Donnie
correct=male guess=female name=Donny
correct=male guess=female name=Donovan
correct=male guess=female name=Dorian
correct=male guess=female name=Dory
correct=male guess=female name=Douggie
correct=male guess=female name=Dougie
correct=male guess=female name=Doyle
correct=male guess=female name=Drake
correct=male guess=female name=Dru
correct=male guess=female name=Dryke
correct=male guess=female name=Duane
correct=male guess=female name=Dudley
correct=male guess=female name=Duffie
correct=male guess=female name=Duffy
correct=male guess=female name=Dugan
correct=male guess=female name=Duke
correct=male guess=female name=Duncan
correct=male guess=female name=Dunstan
correct=male guess=female name=Durant
correct=male guess=female name=Durante
从上面的错误结果来看,以yn为结尾的名字大多以女性为主,但是以n结尾的名字往往是男性,以ch结尾的名字通常是男性。但是h结尾的名字多半是女性。因此我们需要调整特征提取器使其包含两个字母后缀的特性
def gender_features(word):
return {'suffix1':word[-1],'suffix2':word[-2:]}
优化后来准确度为0.604
}
python+NLTK 自然语言学习处理八:分类文本一的更多相关文章
- python+NLTK 自然语言学习处理二:文本
在前面讲nltk安装的时候,我们下载了很多的文本.总共有9个文本.那么如何找到这些文本呢: text1: Moby Dick by Herman Melville 1851 text2: Sense ...
- python+NLTK 自然语言学习处理六:分类和标注词汇一
在一段句子中是由各种词汇组成的.有名词,动词,形容词和副词.要理解这些句子,首先就需要将这些词类识别出来.将词汇按它们的词性(parts-of-speech,POS)分类并相应地对它们进行标注.这个过 ...
- python+NLTK 自然语言学习处理四:获取文本语料和词汇资源
在前面我们通过from nltk.book import *的方式获取了一些预定义的文本.本章将讨论各种文本语料库 1 古腾堡语料库 古腾堡是一个大型的电子图书在线网站,网址是http://www.g ...
- python+NLTK 自然语言学习处理:环境搭建
首先在http://nltk.org/install.html去下载相关的程序.需要用到的有python,numpy,pandas, matplotlib. 当安装好所有的程序之后运行nltk.dow ...
- python+NLTK 自然语言学习处理五:词典资源
前面介绍了很多NLTK中携带的词典资源,这些词典资源对于我们处理文本是有大的作用的,比如实现这样一个功能,寻找由egivronl几个字母组成的单词.且组成的单词每个字母的次数不得超过egivronl中 ...
- python+NLTK 自然语言学习处理三:如何在nltk/matplotlib中的图片中显示中文
我们首先来加载我们自己的文本文件,并统计出排名前20的字符频率 if __name__=="__main__": corpus_root='/home/zhf/word' word ...
- python+NLTK 自然语言学习处理七:N-gram标注
在上一章中介绍了用pos_tag进行词性标注.这一章将要介绍专门的标注器. 首先来看一元标注器,一元标注器利用一种简单的统计算法,对每个标识符分配最有可能的标记,建立一元标注器的技术称为训练. fro ...
- Python+NLTK自然语言处理学习(一):环境搭建
Python+NLTK自然语言处理学习(一):环境搭建 参考黄聪的博客地址:http://www.cnblogs.com/huangcong/archive/2011/08/29/2157437.ht ...
- Python NLTK 自然语言处理入门与例程(转)
转 https://blog.csdn.net/hzp666/article/details/79373720 Python NLTK 自然语言处理入门与例程 在这篇文章中,我们将基于 Pyt ...
随机推荐
- HTML5 Canvas 动态勾画等速螺线
等速螺线亦称阿基米德螺线,得名于公元前三世纪希腊数学家阿基米德.阿基米德螺线是一个点匀速离开一个固定点的同时又以固定的角速度绕该固定点转动而产生的轨迹.在此向这位古代最伟大的数学家致敬.用Canvus ...
- 安装openstack 时 遇见的一些问题及解决方法!
感谢朋友支持本博客,欢迎共同探讨交流.因为能力和时间有限,错误之处在所难免.欢迎指正! 假设转载.请保留作者信息. 博客地址:http://blog.csdn.net/qq_21398167 原博文地 ...
- jQuery中$().each与$.each的区别
在jQuery中 $().each与$.each是不同的,$().each用于对jQuery对象做遍历操作处理,而$.each用于循环遍历一个Array或Object对象,相当于for或while循环 ...
- xtrabackup详解
xtrabackup是Percona公司CTO Vadim参与开发的一款基于InnoDB的在线热备工具,具有开源,免费,支持在线热备,备份恢复速度快,占用磁盘空间小等特点,并且支持不同情况下的多种备份 ...
- 状态机工作流,顺序工作流和Flowchart
什么是工作流,工作流可以说是对业务处理过程的建模,当我们设计工作流的时候,我们首先要分析业务处理过程中要经历的步骤.然后,我们就可以利用WF创建工作流模型来模拟业务的处理过程. WF工作流包含两种类型 ...
- Android蓝牙
代码地址如下:http://www.demodashi.com/demo/12772.html 前言:最近,新换了一家公司,公司的软件需要通过蓝牙与硬件进行通讯,于是趁此机会将Android蓝牙详细的 ...
- Centos7 搭建最新 Nexus3 Maven 私服
Maven 介绍 Apache Maven 是一个创新的软件项目管理和综合工具.Maven 提供了一个基于项目对象模型(POM)文件的新概念来管理项目的构建,可以从一个中心资料片管理项目构建,报告和文 ...
- automaticallyAdjustsScrollViewInsets(UITextView文字顶部留有空白)
iOS7新添加的UIViewController的属性automaticallyAdjustsScrollViewInsets 此属性默认为YES,这样UIViewController下如果只有一个U ...
- HTTP协议断点续传
using System;using System.Collections.Generic;using System.IO;using System.Linq;using System.Net;usi ...
- PJISP 修改 消息头Fromto字段
项目需求,需要修改sip信令消息头中Fromto字段,完成此功能需要修改sip库(PJSIP)源码,具体如下: PJSIP 消息头 Formto 字段默认的格式是sip:平台@平台IP地址,例如si ...