CentOS7.5搭建Hadoop分布式集群
材料:3台虚拟主机,ip分别为:
192.168.1.201
192.168.1.202
192.168.1.203
1、配置主机名称
三个ip与主机名称分别对应关系如下:
192.168.1.201 node201
192.168.1.202 node202
192.168.1.203 node203
1)修改配置文件
- vi /etc/sysconfig/network
- <!-- 添加 -->
- NETEORKING=yes
- HOSTNAME=node203

2)重启使生效
- service network restart
3)检查
- hostname

其他两个虚拟主机做同样的配置。
2、建立主机名和ip的映射
1)使三个虚拟主机通过节点名称直接相互访问
- vi /etc/hosts
在3台虚拟机的/etc/hosts文件里面添加:
- 192.168.1.201 node201
- 192.168.1.202 node202
- 192.168.1.203 node203

2)使windows可以通过节点名称访问虚拟机
和虚拟机一样添加内容:
文件路径:C:\Windows\System32\drivers\etc
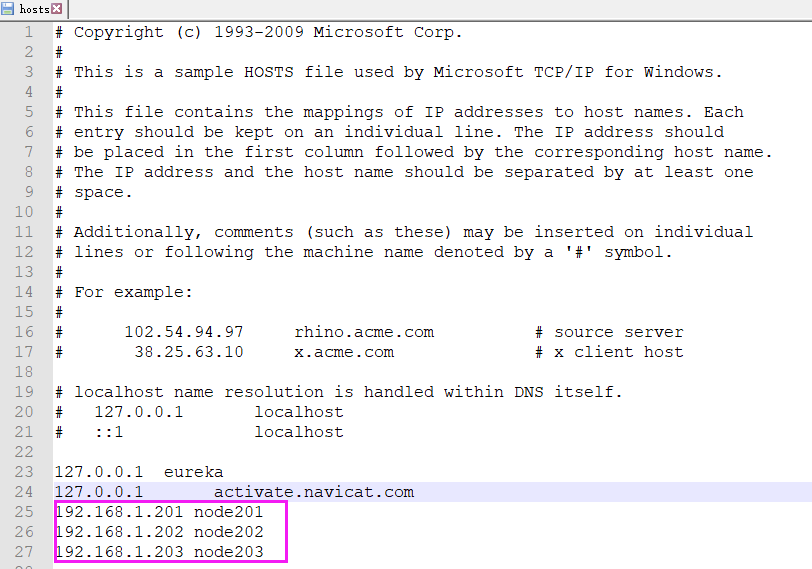
3)测试
虚拟机直接访问节点名称:
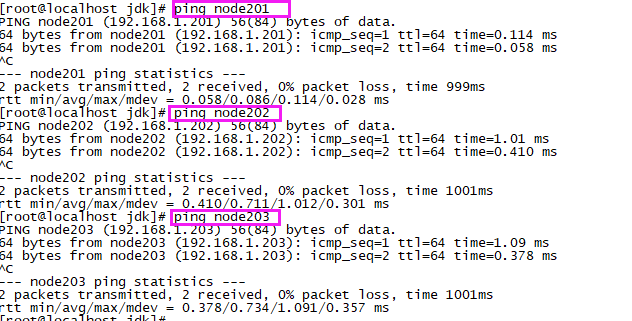
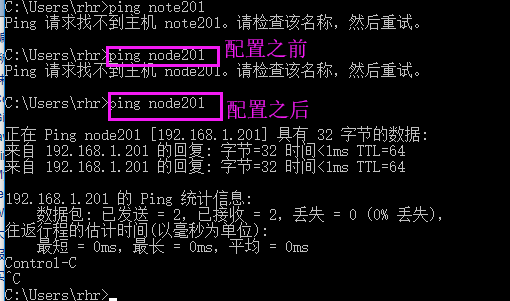
windows访问节点名称:
3、配置ssh免密码登录
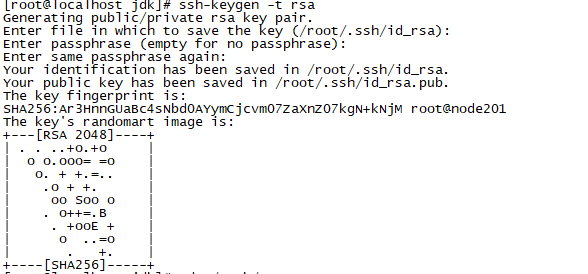
1)生成密钥
- ssh-keygen -t rsa
之后一直按回车
2)检查密钥
- cd ~/.ssh/
- ls

秘钥生成后在~/.ssh/目录下,有两个文件id_rsa(私钥)和id_rsa.pub(公钥)
3)在主节点(node201)上将公钥复制到authorized_keys并赋予authorized_keys600权限
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- chmod 600 ~/.ssh/authorized_keys
复制:

赋权:

3)同理在node202和node203节点上生成秘钥
- ssh-keygen -t rsa
- cat ~/.ssh/id_rsa.pub
4)将node202和node203节点的秘钥复制到node201节点上的authoized_keys
- vi ~/.ssh/authorized_keys

5)将node201节点上的authoized_keys远程传输到node202和node203的~/.ssh/目录下
- scp ~/.ssh/authorized_keys root@node202:~/.ssh/
- scp ~/.ssh/authorized_keys root@node203:~/.ssh/


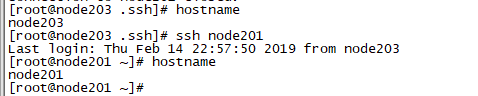
6)检查是否免密登录
- ssh node201

4、新建hadoop用户及其用户组
1)新建hadoop用户
- adduser hadoop
- passwd hadoop

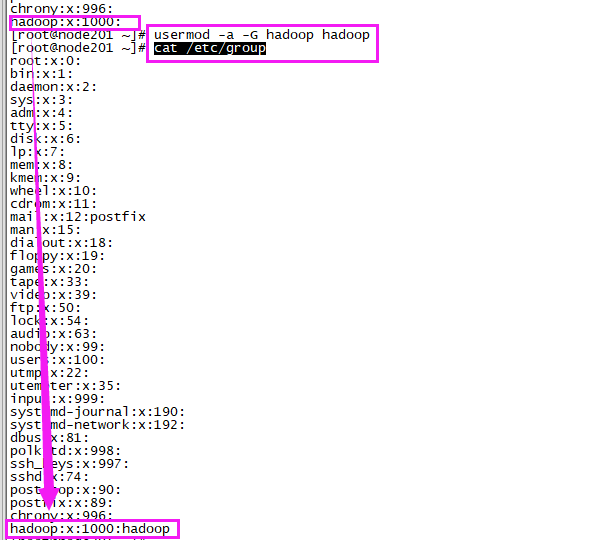
2)将hadoop用户归为hadoop组
- usermod -a -G hadoop hadoop
- cat /etc/group
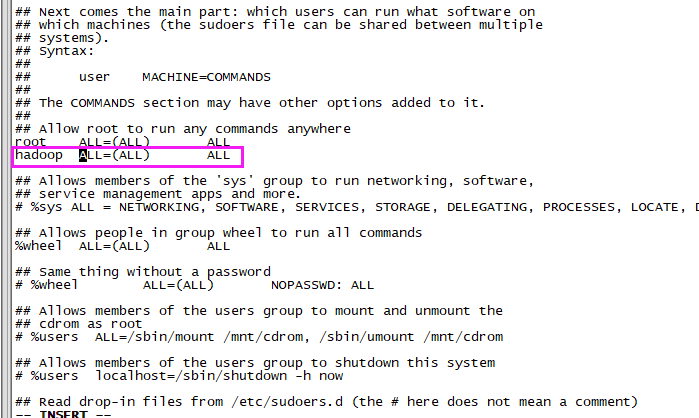
3)赋予hadoop用户root权限
- vi /etc/sudoers
- <!-- 添加 -->
- hadoop ALL=(ALL) ALL
5、安装hadoop
1)准备文件夹
- mkdir /home/soft/hadoop
- cd /home/soft/hadoop
2)下载hadoop安装包
- wget /home/soft/hadoopwget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
3)解压hadoop安装包
- tar -zxvf hadoop-3.1..tar.gz
4)配置环境变量
- vi /etc/profile
- <!-- 添加 -->
- export HADOOP_HOME=/home/soft/hadoop/hadoop-3.1.2
- :$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- source /etc/profile
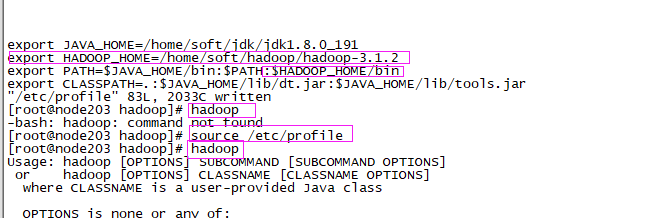
5)查看hadoop版本

6、搭建集群
1)在node201节点上创建以下文件夹
/home/soft/hadoop/hadoop-3.1.2/dfs/name
/home/soft/hadoop/hadoop-3.1.2/dfs/data
/home/soft/hadoop/hadoop-3.1.2/temp
- cd /home/soft/hadoop/hadoop-3.1.
- mkdir -p dfs/name
- mkdir -p dfs/data
- mkdir temp

2)配置hadoop文件
需要配置/home/soft/hadoop/hadoop-3.1.2/etc/hadoop目录下的7个配置文件:
【1】hadoop-env.sh
- vi hadoop-env.sh
- <!-- 添加 -->
- export JAVA_HOME=/home/soft/jdk/jdk1.8.0_191

【2】mapred-env.sh
- vi mapred-env.sh
- <!-- 添加 -->
- export JAVA_HOME=/home/soft/jdk/jdk1.8.0_191
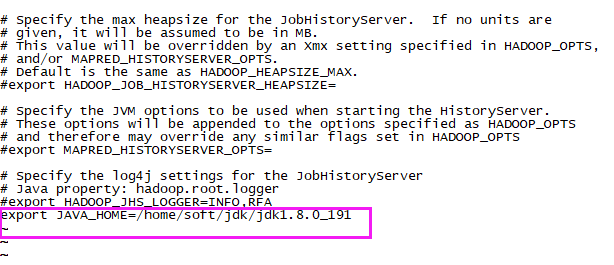
【3】yarn-env.sh
- vi yarn-env.sh
- <!-- 添加 -->
- export JAVA_HOME=/home/soft/jdk/jdk1.8.0_191

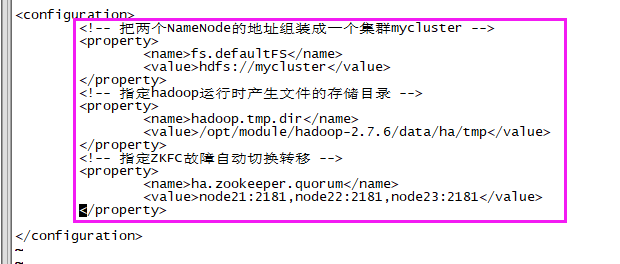
【4】core-site.xml
- vi core-site.xml
- <!-- 把两个NameNode的地址组装成一个集群mycluster -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://mycluster</value>
- </property>
- <!-- 指定hadoop运行时产生文件的存储目录 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/module/hadoop-2.7.6/data/ha/tmp</value>
- </property>
- <!-- 指定ZKFC故障自动切换转移 -->
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>node201:2181,node202:2181,node203:2181</value>
- </property>
【5】hdfs-site.xml
- vi hdfs-site.xml
- <!-- 设置dfs副本数,默认3个 -->
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- <!-- 完全分布式集群名称 -->
- <property>
- <name>dfs.nameservices</name>
- <value>mycluster</value>
- </property>
- <!-- 集群中NameNode节点都有哪些 -->
- <property>
- <name>dfs.ha.namenodes.mycluster</name>
- <value>nn1,nn2</value>
- </property>
- <!-- nn1的RPC通信地址 -->
- <property>
- <name>dfs.namenode.rpc-address.mycluster.nn1</name>
- <value>node201:8020</value>
- </property>
- <!-- nn2的RPC通信地址 -->
- <property>
- <name>dfs.namenode.rpc-address.mycluster.nn2</name>
- <value>node202:8020</value>
- </property>
- <!-- nn1的http通信地址 -->
- <property>
- <name>dfs.namenode.http-address.mycluster.nn1</name>
- <value>node201:50070</value>
- </property>
- <!-- nn2的http通信地址 -->
- <property>
- <name>dfs.namenode.http-address.mycluster.nn2</name>
- <value>node202:50070</value>
- </property>
- <!-- 指定NameNode元数据在JournalNode上的存放位置 -->
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://node201:8485;node202:8485;node203:8485/mycluster</value>
- </property>
- <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>sshfence</value>
- </property>
- <!-- 使用隔离机制时需要ssh无秘钥登录-->
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>/home/admin/.ssh/id_rsa</value>
- </property>
- <!-- 声明journalnode服务器存储目录-->
- <property>
- <name>dfs.journalnode.edits.dir</name>
- <value>/opt/module/hadoop-2.7.6/data/ha/jn</value>
- </property>
- <!-- 关闭权限检查-->
- <property>
- <name>dfs.permissions.enable</name>
- <value>false</value>
- </property>
- <!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
- <property>
- <name>dfs.client.failover.proxy.provider.mycluster</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
- <!-- 配置自动故障转移-->
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
【6】mapred-site.xml
- vi mapred-site.xml
- <!-- 指定mr框架为yarn方式 -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <!-- 指定mr历史服务器主机,端口 -->
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>node201:10020</value>
- </property>
- <!-- 指定mr历史服务器WebUI主机,端口 -->
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>node201:19888</value>
- </property>
- <!-- 历史服务器的WEB UI上最多显示20000个历史的作业记录信息 -->
- <property>
- <name>mapreduce.jobhistory.joblist.cache.size</name>
- <value>20000</value>
- </property>
- <!--配置作业运行日志 -->
- <property>
- <name>mapreduce.jobhistory.done-dir</name>
- <value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.intermediate-done-dir</name>
- <value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
- </property>
- <property>
- <name>yarn.app.mapreduce.am.staging-dir</name>
- <value>/tmp/hadoop-yarn/staging</value>
- </property>
【7】yarn-site.xml
- vi yarn-site.xml
- <!-- reducer获取数据的方式 -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <!--启用resourcemanager ha-->
- <property>
- <name>yarn.resourcemanager.ha.enabled</name>
- <value>true</value>
- </property>
- <!--声明两台resourcemanager的地址-->
- <property>
- <name>yarn.resourcemanager.cluster-id</name>
- <value>rmCluster</value>
- </property>
- <property>
- <name>yarn.resourcemanager.ha.rm-ids</name>
- <value>rm1,rm2</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname.rm1</name>
- <value>node202</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname.rm2</name>
- <value>node203</value>
- </property>
- <!--指定zookeeper集群的地址-->
- <property>
- <name>yarn.resourcemanager.zk-address</name>
- <value>node201:2181,node202:2181,node203:2181</value>
- </property>
- <!--启用自动恢复-->
- <property>
- <name>yarn.resourcemanager.recovery.enabled</name>
- <value>true</value>
- </property>
- <!--指定resourcemanager的状态信息存储在zookeeper集群-->
- <property>
- <name>yarn.resourcemanager.store.class</name>
- <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
- </property>
【8】新建slaves
- vi slaves
- node201
- node202
- node203
2)将配置好的hadoop文件复制到其他节点上
由于hadoop集群需要在每一个节点上进行相同的配置,因此先在node201节点上配置,然后再复制到其他节点上即可。
- scp -r /home/soft/hadoop/hadoop-3.1.2/etc/hadoop/ root@node202:/home/soft/hadoop/hadoop-3.1.2/etc/
- scp -r /home/soft/hadoop/hadoop-3.1.2/etc/hadoop/ root@node203:/home/soft/hadoop/hadoop-3.1.2/etc/
7、启动验证集群
1)格式化Namenode
如果集群是第一次启动,需要格式化namenode
- hdfs namenode -format
2)启动Hdfs
- start-dfs.sh
启动报错:

CentOS7.5搭建Hadoop分布式集群的更多相关文章
- 使用docker搭建hadoop分布式集群
使用docker搭建部署hadoop分布式集群 在网上找了非常长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,仅仅能自己写一个了. 一:环境准备: 1:首先要有一个Cento ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
- 在 Ubuntu 上搭建 Hadoop 分布式集群 Eclipse 开发环境
一直在忙Android FrameWork,终于闲了一点,利用空余时间研究了一下Hadoop,并且在自己和同事的电脑上搭建了分布式集群,现在更新一下blog,分享自己的成果. 一 .环境 1.操作系统 ...
- VM搭建hadoop分布式集群
1. 安装VMware Workstation Pro 2.安装Ubuntu-16.04 3.以下全程使用sudo –s 切换root权限 4.更新deb软件包列表:apt-get update 5 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- hadoop分布式集群的搭建
电脑如果是8G内存或者以下建议搭建3节点集群,如果是搭建5节点集群就要增加内存条了.当然实际开发中不会用虚拟机做,一些小公司刚刚起步的时候会采用云服务,因为开始数据量不大. 但随着数据量的增大才会考虑 ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
随机推荐
- Ruby 局部变量做block参数
Ruby中使用yield语句调用block时可以带有参数,参数值见传送个相关联的block.如果传给block的参数是已经存在的局部变量,那么这些变量即为block的参数,他们的值可能会因block的 ...
- springMVC绑定json参数之一
一.SpringMVC @RequestBody接收Json对象字符串 以前,一直以为在SpringMVC环境中,@RequestBody接收的是一个Json对象,一直在调试代码都没有成功,后来发现, ...
- window下git,TortoiseGit安装,以及和github托管项目
下载地址:http://msysgit.github.io/,安装时最好是先装git,再安装TortoiseGit. 一.git安装 1.第一步 2.第二步 3.第三步 4.第四步 5.第五步 6.第 ...
- [Gym 101334E]Exploring Pyramids(区间dp)
题意:给定一个先序遍历序列,问符合条件的树的种类数 解题关键:枚举分割点进行dp,若符合条件一定为回文序列,可分治做,采用记忆化搜索的方法. 转移方程:$dp[i][j] = \sum {dp[i + ...
- 项目一:第四天 1、快递员的条件分页查询-noSession,条件查询 2、快递员删除(逻辑删除) 3、基于Apache POI实现批量导入区域数据 a)Jquery OCUpload上传文件插件使用 b)Apache POI读取excel文件数据
1. 快递员的条件分页查询-noSession,条件查询 2. 快递员删除(逻辑删除) 3. 基于Apache POI实现批量导入区域数据 a) Jquery OCUpload上传文件插件使用 b) ...
- 5.6 安装Virtual box
本以为安装虚拟机很复杂的样子,经过kevin一指点,发现soeasy.废话少说,直接上图片: 将安装包放到自己的目录下: 安装完后,可以在搜索框中搜索:virtual 会出现安装好的虚拟机盒子.
- Sharepoint2013商务智能学习笔记之Secure Store Service服务配置(二)
Secure Store Service 是运行在应用程序服务器上的授权服务,它提供一个存储用户凭据的数据库,Secure Store Service 在商务智能中的地位很重要,Sharepoint商 ...
- DESede/CBC/PKCS5Padding
Java.security.NoSuchAlgorithmException: Cannot find any provider supporting DESede/CBC/PKCS5Padding ...
- [翻译]pytest测试框架(二):使用
此文已由作者吴琪惠授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 调用pytest 调用命令: python -m pytest [...] 上面的命令相当于在命令行直接调用 ...
- Linux ubi子系统原理分析
本文思维导图总纲: 综述 关于ubi子系统,早已有比较正式的介绍,也提供非常形象的介绍ubi子系统ppt 国内的前辈 alloysystem 不辞辛劳为我们提供了部分正式介绍的中文译文,以及找不到原文 ...