我的一次Postgre数据库Insert 、Query性能优化实践
一、前言
以前的系统由于表设计比较复杂(多张表,表与表直接有主从关系),这个是业务逻辑决定的。 插入效率简直实在无法忍受,必须优化。在了解了Postgre的Copy,unlogged table 特性
之后,决定一探究竟。
二、测试用例
1.数据表结构:表示一个员工工作绩效的表(work_test):共15个字段
id,no,name,sex,tel,address,provice,city,post,mobile,department,work,start_time,end_time,score
索引(b-tree的集群索引或者叫聚集索引):id,no,name,sex,tel,address,provice,city,post,mobile,department,work
2.测试环境:win7,四核,2GB内存;postgre版本9.3;Npgsql连接Postgre数据库。
三、insert/ transaction/ copy/unlogged table
1.insert 一个10W数据大概需要120s,虽然已经提升“不少”,但是还是不尽如人意。以前用SQLite时发现Transaction可以大幅提升性能,于是在Postgre中试试,发现并没有明显变
化。不知何故。
2. copy可以将文件(csv)中的数据复制进数据库中,当然数据表的结构和要数据类型要与文件一一对应。据说可以大幅提升插入性能。
COPY 'work_test' from 'c:\temp.csv' WITH DELIMITER AS ','
使用Copy后发现插入的性能立马提升至30s,相当于1s插入3300条记录。这中间还包含生成csv文件的时间。
3.unlogged table
unlogged table,网上的文章说可以10倍于insert。使用方法也很简单:Create unlogged table ...
但是unlogged table 在遇到Postgre服务器异常重启后会丢失全部数据,所以如果你的数据不允许丢失,请不要使用。
使用后发现,大概20s,1s插入5000条记录。
下面是三种插入方式的走势图:
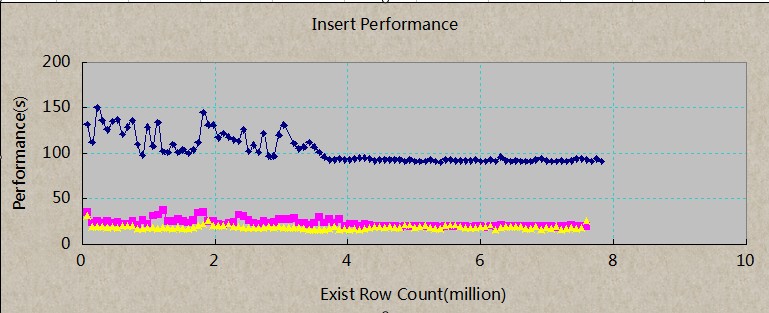
说明:x轴表示数据库中已有的记录数,单位百万,每个点是10W.Y轴表示每次插入所耗时间,单位秒。
蓝色线:insert;之所以后面比较稳定是因为电脑没有运行其他程序。所以说,电脑工作状态对Postgre效率有一定的影响。
粉红色:copy;
黄色线:copy+unlogged
虽然建了索引,并且表中的数据一直累加进来,对于后续插入数据性能并没有任何影响,这个结果就是我想看到的。
四、查询测试
按name字段搜索:
select * from work_test where name='1'
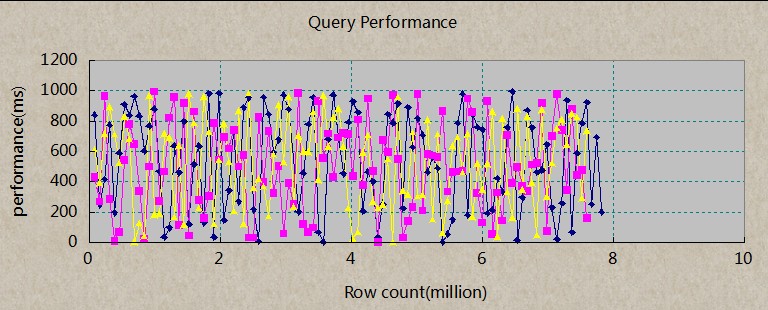
说明:x轴表示数据库中已有的记录数,单位百万,每个点是10W.Y轴表示每次查询所耗时间,单位毫秒。
蓝色线:insert;
粉红色:copy;
黄色线:copy+unlogged
由于三种插入方式结果都是一样的,所以对比并没有意义,这里主要看查询耗时。平均下来:500ms,并且随着Row count的增加,查询效率并没有降低。这主要得益于良好的索引。
另外发现:条件越多,查询效率越高,因为扫描的行数在减少,后面的图就不贴出来了。
不知道其他数据库性能如何,请大家赐教。我自己试了Mysql的MariaDB,结果不怎么样。
我的一次Postgre数据库Insert 、Query性能优化实践的更多相关文章
- 数据库订正脚本性能优化两则:去除不必要的查询和批量插入SQL
最近在做多数据库合并的脚本, 要将多个分数据库的表数据合并到一个主数据库中. 以下是我在编写数据订正脚本时犯过的错误, 记录以为鉴. 不必要的查询 请看以下语句: regiondb = db.Houy ...
- Android中数据库Sqlite的性能优化
1.索引简单的说,索引就像书本的目录,目录可以快速找到所在页数,数据库中索引可以帮助快速找到数据,而不用全表扫描,合适的索引可以大大提高数据库查询的效率.(1). 优点大大加快了数据库检索的速度,包括 ...
- 高并发数据库之MySql性能优化
1.慢查询 SHOW VARIABLES LIKE '%quer%'
- MySQL数据库在IO性能优化方面的设置选择(硬件)
提起MySQL数据库在硬件方面的优化无非是CPU.内存和IO.下面我们着重梳理一下关于磁盘I/O方面的优化. 1.磁盘冗余阵列RAID RAID(Redundant Array of Inexpens ...
- 高并发数据库之MySql性能优化实战总结
向MySQL发送一个请求时MySQL具体的操作过程 慢查询 1.慢查询 SHOW VARIABLES LIKE '%quer%' 索引优化技巧 1.对于创建的多列索引(复合)索引,只要查询条件使用了最 ...
- 数据库SQL语句性能优化
选择最有效率的表名顺序 ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下 ...
- MySQL数据库INSERT、UPDATE、DELETE以及REPLACE语句的用法详解
本篇文章是对MySQL数据库INSERT.UPDATE.DELETE以及REPLACE语句的用法进行了详细的分析介绍,需要的朋友参考下 MySQL数据库insert和update语句引:用于操作数 ...
- Postgre cannot insert multiple commands into a prepared statement
悲剧... FireDAC连接Postgre数据库, 使用默认的属性, 一次执行多条SQL的时候, 会报"cannot insert multiple commands into a pre ...
- 转载:MySQL数据库INSERT、UPDATE、DELETE以及REPLACE语句的用法详解
转自:http://www.jb51.net/article/39199.htm 本篇文章是对MySQL数据库INSERT.UPDATE.DELETE以及REPLACE语句的用法进行了详细的分析介绍, ...
随机推荐
- jQuery遍历 filter()方法
实例 改变所有 div 的颜色,然后向类名为 "middle" 的类添加边框: $("div").css("background", &qu ...
- 团队Alpha版本(九)
目录 组员情况 组员1(组长):胡绪佩 组员2:胡青元 组员3:庄卉 组员4:家灿 组员5:凯琳 组员6:翟丹丹 组员7:何家伟 组员8:政演 组员9:黄鸿杰 组员10:刘一好 组员11:何宇恒 展示 ...
- PAT 1070 结绳
https://pintia.cn/problem-sets/994805260223102976/problems/994805264706813952 给定一段一段的绳子,你需要把它们串成一条绳. ...
- CSS——(2)盒子模型与标准流
上篇博客<CSS--(1)基础>中简单介绍了CSS的概念和几种使用方法,现在主要是介绍其的核心内容. 盒子模型 为了理解盒子模型,我们可以先从生活中的盒子入手.盒子是用来放置物品的,内部除 ...
- Android开发中Parcelable接口的使用方法
在网上看到很多Android初入门的童鞋都在问Parcelable接口的使用方法,小编参考了相关Android教程,看到里面介绍的序列化方法主要有两种分别是实现Serializable接口和实现Par ...
- NAT64与DNS64基本原理概述
NAT64与DNS64基本原理概述 1.NAT64与DNS64背景 在IPv6网络的发展过程中,面临最大的问题应该是IPv6与IPv4的不兼容性,因此无法实现二种不兼容网络之间的互访.为了实现 ...
- [hdu6428]Problem C. Calculate
题目大意:有$T(1\leqslant T\leqslant 10)$组数据,每组数据给你$A,B,C(0<A,B,C\leqslant 10^7)$,求$\sum\limits_{i=1}^A ...
- Codeforces 938.A Word Correction
A. Word Correction time limit per test 1 second memory limit per test 256 megabytes input standard i ...
- MFC 屏幕截图(libjpeg bmp转jpg)
项目中需要用到的功能. void Screenshot() { CDC *pDC; pDC = CDC::FromHandle(GetDC(GetDesktopWindow())); if(pDC = ...
- ie8 不支持media
可以用respond.js库解决,bootstrap文件夹里有.同时需要注意以下几点. 1.需要启动本地服务器(localhost),不能使用普通本地的url地址(file://开头): 2.需要外部 ...