mysql数据库之表与表之间的关系
表1 foreign key 表2
则表1的多条记录对应表2的一条记录,即多对一 利用foreign key的原理我们可以制作两张表的多对多,一对一关系
多对多:
表1的多条记录可以对应表2的一条记录
表2的多条记录也可以对应表1的一条记录 一对一:
表1的一条记录唯一对应表2的一条记录,反之亦然 分析时,我们先从按照上面的基本原理去套,然后再翻译成真实的意义,就很好理解了
1、先确立关系
2、找到多的一方,吧关联字段写在多的一方
一、多对一或者一对多(左边表的多条记录对应右边表的唯一一条记录)
需要注意的:1.先建被关联的表,保证被关联表的字段必须唯一。
2.在创建关联表,关联字段一定保证是要有重复的。
其实上一篇博客已经举了一个多对一关系的小例子了,那我们在用另一个小例子来回顾一下。
这是一个书和出版社的一个例子,书要关联出版社(多个书可以是一个出版社,一个出版社也可以有好多书)。
谁关联谁就是谁要按照谁的标准。
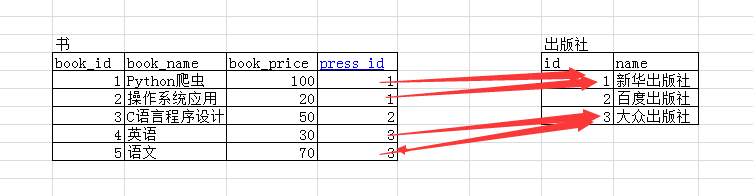
书要关联出版社
被关联的表
create table press(
id int primary key auto_increment,
name char(20)
);
关联的表
create table book(
book_id int primary key auto_increment,
book_name varchar(20),
book_price int,
press_id int,
constraint Fk_pressid_id foreign key(press_id) references press(id)
on delete cascade
on update cascade
); 插记录
insert into press(name) values('新华出版社'),
('海燕出版社'),
('摆渡出版社'),
('大众出版社');
insert into book(book_name,book_price,press_id) values('Python爬虫',100,1),
('Linux',80,1),
('操作系统',70,2),
('数学',50,2),
('英语',103,3),
('网页设计',22,3);
运行结果截图:

二、一对一
例子一:用户和管理员(只有管理员才可以登录,一个管理员对应一个用户)
管理员关联用户
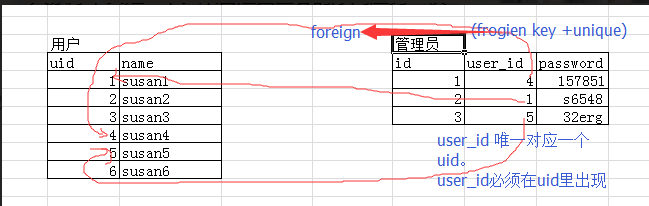
===========例子一:用户表和管理员表=========
先建被关联的表
create table user(
id int primary key auto_increment, #主键自增
name char(10)
);
在建关联表
create table admin(
id int primary key auto_increment,
user_id int unique,
password varchar(16),
foreign key(user_id) references user(id)
on delete cascade
on update cascade
);
insert into user(name) values('susan1'),
('susan2'),
('susan3'),
('susan4'),
('susan5'),
('susan6');
insert into admin(user_id,password) values(4,'sds156'),
(2,'531561'),
(6,'f3swe');
运行结果截图:

例子二:学生表和客户表

========例子二:学生表和客户表=========
create table customer(
id int primary key auto_increment,
name varchar(10),
qq int unique,
phone int unique
);
create table student1(
sid int primary key auto_increment,
course char(20),
class_time time,
cid int unique,
foreign key(cid) references customer(id)
on delete cascade
on update cascade
);
insert into customer(name,qq,phone) values('小小',13564521,11111111),
('嘻哈',14758254,22222222),
('王维',44545522,33333333),
('胡军',545875212,4444444),
('李希',145578543,5555555),
('李迪',754254653,8888888),
('艾哈',74545145,8712547),
('啧啧',11147752,7777777);
insert into student1(course,class_time,cid) values('python','08:30:00',3),
('python','08:30:00',4),
('linux','08:30:00',1),
('linux','08:30:00',7);
运行结果截图:

三、多对多(多条记录对应多条记录)
书和作者(我们可以再创建一张表,用来存book和author两张表的关系)
要把book_id和author_id设置成联合唯一
联合唯一:unique(book_id,author_id)
联合主键:alter table t1 add primary key(id,avg)
多对多:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
关联方式:foreign key+一张新的表
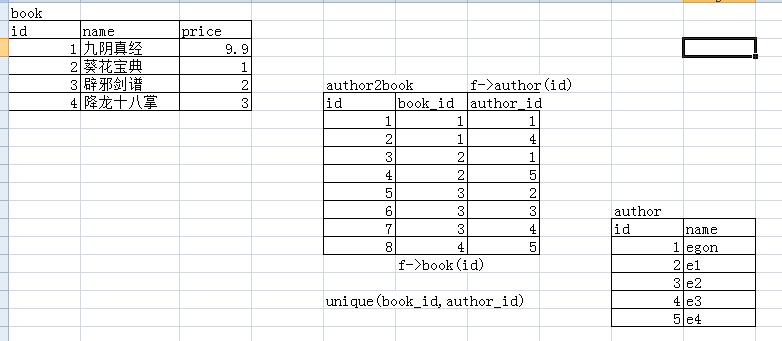


========书和作者,另外在建一张表来存书和作者的关系
#被关联的
create table book1(
id int primary key auto_increment,
name varchar(10),
price float(3,2)
);
#========被关联的
create table author(
id int primary key auto_increment,
name char(5)
);
#========关联的
create table author2book(
id int primary key auto_increment,
book_id int not null,
author_id int not null,
unique(book_id,author_id),
foreign key(book_id) references book1(id)
on delete cascade
on update cascade,
foreign key(author_id) references author(id)
on delete cascade
on update cascade
);
#========插入记录
insert into book1(name,price) values('九阳神功',9.9),
('葵花宝典',9.5),
('辟邪剑谱',5),
('降龙十巴掌',7.3);
insert into author(name) values('egon'),('e1'),('e2'),('e3'),('e4');
insert into author2book(book_id,author_id) values(1,1),
(1,4),
(2,1),
(2,5),
(3,2),
(3,3),
(3,4),
(4,5);
多对多关系举例
用户表,用户组,主机表
-- 用户组
create table user (
id int primary key auto_increment,
username varchar(20) not null,
password varchar(50) not null
);
insert into user(username,password) values('egon','123'),
('root',147),
('alex',123),
('haiyan',123),
('yan',123); -- 用户组表
create table usergroup(
id int primary key auto_increment,
groupname varchar(20) not null unique
);
insert into usergroup(groupname) values('IT'),
('Sale'),
('Finance'),
('boss'); -- 建立user和usergroup的关系表
create table user2usergroup(
id int not NULL UNIQUE auto_increment,
user_id int not null,
group_id int not NULL,
PRIMARY KEY(user_id,group_id),
foreign key(user_id) references user(id)
ON DELETE CASCADE
on UPDATE CASCADE ,
foreign key(group_id) references usergroup(id)
ON DELETE CASCADE
on UPDATE CASCADE
);
insert into user2usergroup(user_id,group_id) values(1,1),
(1,2),
(1,3),
(1,4),
(2,3),
(2,4),
(3,4);
-- 主机表
CREATE TABLE host(
id int primary key auto_increment,
ip CHAR(15) not NULL UNIQUE DEFAULT '127.0.0.1'
);
insert into host(ip) values('172.16.45.2'),
('172.16.31.10'),
('172.16.45.3'),
('172.16.31.11'),
('172.10.45.3'),
('172.10.45.4'),
('172.10.45.5'),
('192.168.1.20'),
('192.168.1.21'),
('192.168.1.22'),
('192.168.2.23'),
('192.168.2.223'),
('192.168.2.24'),
('192.168.3.22'),
('192.168.3.23'),
('192.168.3.24'); -- 业务线表
create table business(
id int primary key auto_increment,
business varchar(20) not null unique
);
insert into business(business) values
('轻松贷'),
('随便花'),
('大富翁'),
('穷一生'); -- 建立host和business关系表
CREATE TABLE host2business(
id int not null unique auto_increment,
host_id int not null ,
business_id int not NULL ,
PRIMARY KEY(host_id,business_id),
foreign key(host_id) references host(id),
FOREIGN KEY(business_id) REFERENCES business(id)
); insert into host2business(host_id,business_id) values
(1,1),
(1,2),
(1,3),
(2,2),
(2,3),
(3,4);
-- 建立user和host的关系
create table user2host(
id int not null unique auto_increment,
user_id int not null,
host_id int not null,
primary key(user_id,host_id),
foreign key(user_id) references user(id),
foreign key(host_id) references host(id)
); insert into user2host(user_id,host_id) values(1,1),
(1,2),
(1,3),
(1,4),
(1,5),
(1,6),
(1,7),
(1,8),
(1,9),
(1,10),
(1,11),
(1,12),
(1,13),
(1,14),
(1,15),
(1,16),
(2,2),
(2,3),
(2,4),
(2,5),
(3,10),
(3,11),
(3,12);
练习

mysql数据库之表与表之间的关系的更多相关文章
- Hibernate连接mysql数据库并自动创建表
天才第一步,雀氏纸尿裤,Hibernate第一步,连接数据库. Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个 ...
- mysql数据库为什么要分表和分区?
一般下载的源码都带了MySQL数据库的,做个真正意义上的网站没数据库肯定不行. 数据库主要存放用户信息(注册用户名密码,分组,等级等),配置信息(管理权限配置,模板配置等),内容链接(html ,图片 ...
- MYSQL数据库、用户、表等基础构建
MYSQL数据库.用户.表等基础构建: 1.->:创建数据库: 1.1. create schema [数据库名称] default character set utf8 collate utf ...
- MySQL数据库性能优化:表、索引、SQL等
一.MySQL 数据库性能优化之SQL优化 注:这篇文章是以 MySQL 为背景,很多内容同时适用于其他关系型数据库,需要有一些索引知识为基础 优化目标 减少 IO 次数IO永远是数据库最容易瓶颈的地 ...
- Mysql数据库进阶之(分表分库,主从分离)
前言:数据库的优化是一个程序员的分水岭,作为小白我也得去提前学习这方面的数据的 (一) 三范式和逆范式 听起范式这个迟非常专业我来举个简单的栗子: 第一范式就是: 把能够关联的每条数据都拆分成一个 ...
- mysql数据库(一):建表与新增数据
一. 学习目标 理解什么是数据库,什么是表 怎样创建数据库和表(create) 怎样往表里插入数据(insert) 怎样修改表里的数据(update) 怎样删除数据库,表以及数据(delete) 二. ...
- 检查mysql数据库是否存在坏表脚本
#!/bin/bash #此脚本的主要用途是检测mysql服务器上所有的db或者单独db中的坏表 #变量说明 pass mysql账户口令 name mysql账号名称 data_path mysql ...
- MySql数据库中,判断表、表字段是否存在,不存在就新增
本文是针对MySql数据库创建的SQL脚本,别搞错咯. 判断表是否存在,不存在就可新增 CREATE TABLE IF NOT EXISTS `mem_cardtype_resource` ( ... ...
- mysql数据库分区和分表
转载自 https://www.cnblogs.com/miketwais/articles/mysql_partition.html https://blog.csdn.net/vbirdbest/ ...
- 什么是分表和分区 MySql数据库分区和分表方法
1.为什么要分表和分区 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性 ...
随机推荐
- 丢失vcruntime140.dll
我在php7安装yaf时报了标题所提示的错误信息. 解决方案是:下载vc++2015 并安装 链接如下:https://www.microsoft.com/zh-cn/download/confirm ...
- wechat JS-SKD (getLoaction) 定位显示百度map
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- Android LockScreen (锁屏弹窗)
在要弹窗的Activity需要进行以下设置,才可以在锁屏状态下弹窗 @Override protected void onCreate(Bundle savedInstanceState) { fin ...
- SM30维护视图创建【转】
在SAP中,经常需要自定义数据库表.而且可能需要人工维护数据库表中的数据,可以通过SM30进行维护数据:但是SM30事务的权限太大,不适宜将SM30直接分配:因此,可以通过给维护表分配事 ...
- web audio living
总结网页音频直播的方案和遇到的问题. 代码:(github,待整理) 结果: 使用opus音频编码,web audio api 播放,可以达到100ms以内延时,高质量,低流量的音频直播. 背景: V ...
- R语言做正态性检验
摘自:吴喜之:<非参数统计>(第二版),中国统计出版社,2006年10月:P164-165 1.ks.test() 例如零假设为N(15,0.2),则ks.test(x," ...
- persisted? vs new_record?
https://joe11051105.gitbooks.io/you-need-to-know-about-ruby-on-rails/content/activerecord/persisted_ ...
- Linux通过Shell对文件自动进行远程拷贝备份
在执行计划任务拷贝文件的时候,用scp命令需要输入密码,这里用公共密钥的方式实现密码的自动输入. 具体操作: 要求:把192.168.0.2机上的test.tar拷贝到192.168.0.3机器的上 ...
- Linux查看硬盘使用情况
df df - report file system disk space usage df是查看文件系统磁盘使用情况的命令.如: # df -h Filesystem Size Used Avail ...
- nginx配置大全
nginx配置大全