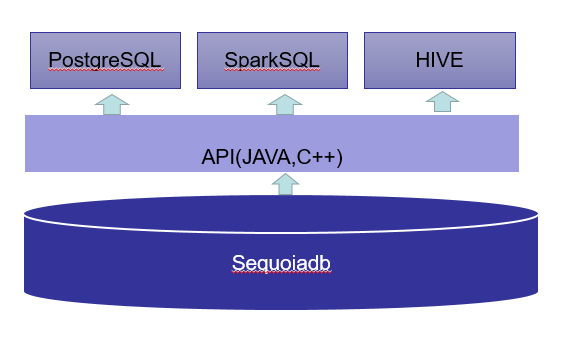
Sequoiadb该如何选择合适的SQL引擎
Sequoiadb作为一个文档型NoSQL数据既可以存储结构化数据也可以存储非结构化数据,对于非结构化数据只能使用原生的API进行查询,对结构化数据我们可以选择使用原生的API和开源SQL引擎,目前PostgresSQL,Hive,SparkSQL都可以作为Sequoiadb的SQL引擎,应用中该如何选择?

Sequoiadb该如何选择合适的SQL引擎的更多相关文章
- Mysql选择合适的存储引擎
Myisam:默认的mysql插件式存储引擎.如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性.并发性要求不是很高,那么选择这个存储引擎是非常合适的.Myisam是在we ...
- MySQL如何选择合适的引擎以及引擎的转换。
我们怎么选择合适的引擎?这里简单归纳一句话:"除非需要用到某些InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该优先选择InnoDB引擎." 除非万不得已,否则不建议混 ...
- Android研究之为基于 x86 的 Android* 游戏选择合适的引擎具体解释
摘要 游戏开发者知道 Android 中蕴藏着巨大的机遇. 在 Google Play 商店的前 100 款应用中,约一半是游戏应用(在利润最高的前 100 款应用中.它们所占的比例超过 90% ...
- 为基于 x86 的 Android* 游戏选择合适的引擎
摘要 游戏开发者知道 Android 中蕴藏着巨大的机遇. 在 Google Play 商店的前 100 款应用中,约一半是游戏应用(在利润最高的前 100 款应用中.它们所占的比例超过 90%). ...
- 谈谈数据库中MyISAM与InnoDB区别 针对业务类型选择合适的表
MyISAM:这个是默认类型,它是基于传统的ISAM类型, ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法. ...
- 六大主流开源SQL引擎
导读 本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以 ...
- 六大主流开源SQL引擎总结
本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以及2个 ...
- 重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29
Kafka 的作者 Neha Narkhede 在 Confluent 上发表了一篇博文,介绍了Kafka 新引入的KSQL 引擎——一个基于流的SQL.推出KSQL 是为了降低流式处理的门槛,为处理 ...
- 6大主流开源SQL引擎总结,遥遥领先的是谁?
根据 O’Reilly 2016年数据科学薪资调查显示,SQL 是数据科学领域使用最广泛的语言.大部分项目都需要一些SQL 操作,甚至有一些只需要SQL.本文就带你来了解这些主流的开源SQL引擎!背景 ...
随机推荐
- 如何显示PHP运行错误
在运行文件的最前面加两行代码: error_reporting(E_ALL); ini_set('display_errors', '1'); 这样调试起来就方便多了
- New Year and Buggy Bot
Bob programmed a robot to navigate through a 2d maze. The maze has some obstacles. Empty cells are d ...
- RequireJS 也可以引入 VUE
RequireJS 也可以引入 VUE 由于 FastAdmin 是使用 RequireJS 导入 JS 模块的. 有人想把 VUE 也引入进去,虽然说也是可以,VUE 还是推荐使用 Webpack ...
- 把ASM下的HDD VM转换成ARM下Managed Disk的SSD VM
在ASM下,要把HDD的VM转换成SSD的VM步骤非常复杂.需要手工把Disk从普通存储账户复制到高级存储账户.再通过这个Disk创建VM. 目前在有了ASM到ARM的迁移工具,以及Managed D ...
- HDU2579(bfs迷宫)
Dating with girls(2) Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...
- Day2-VIM(二):插入
基础 字符位置插入 i 在光标之前插入 a 在光标之后追加 你看,其实刚开始用这两个就足够了,这就是最基础的 为什么这么说呢?因为你可以依靠上一节中的移动命令来达到任意位置,然后再大力插入 不要忘了, ...
- DCloud-MUI:HBuilder 安装
ylbtech-DCloud-MUI:HBuilder 安装 1.返回顶部 1. 2. 3. 4. 2.返回顶部 3.返回顶部 4.返回顶部 5.返回顶部 6.返回顶部 7.返 ...
- 关于无法解析的外部符号 _main
今天在写一段代码的时候,遇到了这个问题,一般遇到这种问题,都是找不到主函数,就是main函数,可是我写的代码是有入口地址main函数的呀.最后发现是自己源文件里,main函数是.c文件,.h文件对应的 ...
- 前端js上传文件后端C#接收文件
本文粗略的讲下前端文件上传和后端文件接收的原理 前端代码 html <form onsubmit="uploadFile(event)"> <input type ...
- windows cmd for paramiko
wmic cpu get LoadPercentage wmic memphysical list brief wmic memphysical get MaxCapacity 主板芯片组支持最 ...