网络编程-day3
---恢复内容开始---
一.缓冲区: 将程序和网络解耦

输入缓冲区
输出缓冲区
- 每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。
- write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
- TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。
- read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。
- 这些I/O缓冲区特性可整理如下:
- 1.I/O缓冲区在每个TCP套接字中单独存在;
- 2.I/O缓冲区在创建套接字时自动生成;
- 3.即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
- 4.关闭套接字将丢失输入缓冲区中的数据。
- 输入输出缓冲区的默认大小一般都是 8K,可以通过 getsockopt() 函数获取:
- 1.unsigned optVal;
- 2.int optLen = sizeof(int);
- 3.getsockopt(servSock, SOL_SOCKET, SO_SNDBUF,(char*)&optVal, &optLen);
- 4.printf("Buffer length: %d\n", optVal);
- socket缓冲区解释
缓冲区
Import Subprocess
sub_obj = subprocess.Popen(
‘dir’,
shell=True,
stdout=subprocess.PIPE, #正确结果的存放位置
stderr=subprocess.PIPE #错误结果的存放位置
)
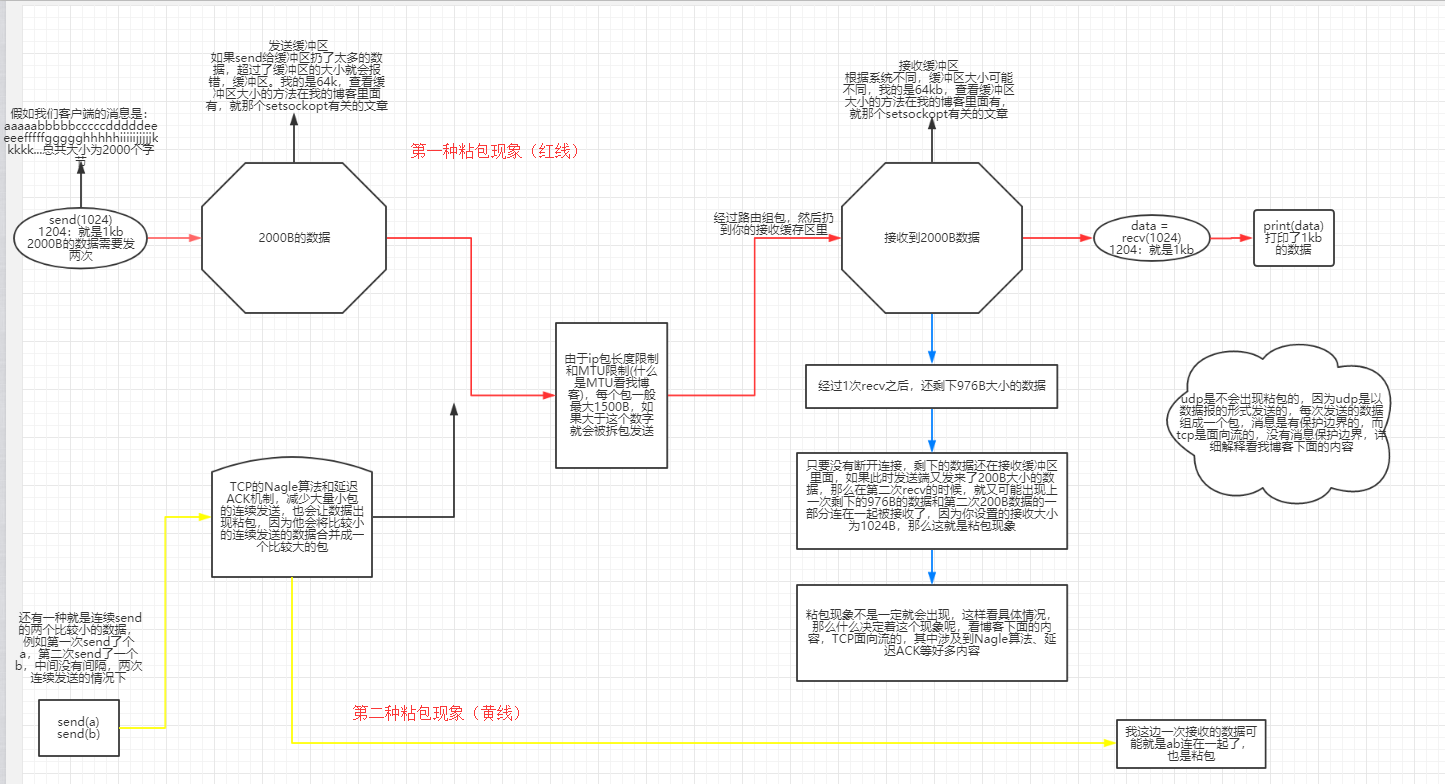
二.两种黏包现象:
1 连续的小包可能会被优化算法给组合到一起进行发送
2 第一次如果发送的数据大小2000B接收端一次性接受大小为1024,这就导致剩下的内容会被下一次recv接收到,导致结果错乱
方案一:由于双方不知道对方发送数据的长度,导致接收的时候,可能接收不全,或者多接收另外一次发送的信息内容,所以在发送真实数据之前,要先发送数据的长度,接收端根据长度来接收后面的真实数据,但是双方有一个交互确认的过程
- import socket
- import subprocess
- server = socket.socket()
- ip_port = ('127.0.0.1',8001)
- server.bind(ip_port)
- server.listen()
- conn,addr = server.accept()
- while 1:
- from_client_cmd = conn.recv(1024)
- print(from_client_cmd.decode('utf-8'))
- #接收到客户端发送来的系统指令,我服务端通过subprocess模块到服务端自己的系统里面执行这条指令
- sub_obj = subprocess.Popen(
- from_client_cmd.decode('utf-8'),
- shell=True,
- stdout=subprocess.PIPE, #正确结果的存放位置
- stderr=subprocess.PIPE #错误结果的存放位置
- )
- #从管道里面拿出结果,通过subprocess.Popen的实例化对象.stdout.read()方法来获取管道中的结果
- std_msg = sub_obj.stdout.read()
- #为了解决黏包现象,我们统计了一下消息的长度,先将消息的长度发送给客户端,客户端通过这个长度来接收后面我们要发送的真实数据
- std_msg_len = len(std_msg)
- # std_bytes_len = bytes(str(len(std_msg)),encoding='utf-8')
- #首先将数据长度的数据类型转换为bytes类型
- std_bytes_len = str(len(std_msg)).encode('utf-8')
- print('指令的执行结果长度>>>>',len(std_msg))
- conn.send(std_bytes_len)
- status = conn.recv(1024)
- if status.decode('utf-8') == 'ok':
- conn.send(std_msg)
- else:
- pass
方案一:服务端
- import socket
- client = socket.socket()
- client.connect(('127.0.0.1',8001))
- while 1:
- cmd = input('请输入指令:')
- client.send(cmd.encode('utf-8'))
- server_res_len = client.recv(1024).decode('utf-8')
- print('来自服务端的消息长度',server_res_len)
- client.send(b'ok')
- server_cmd_result = client.recv(int(server_res_len))
- print(server_cmd_result.decode('gbk'))
方案一:客户端
方案二:
Struct模块,
打包:struct.pack(‘i’,长度)
解包:struct.unpack(‘i’,字节)
- import socket
- import subprocess
- import struct
- server = socket.socket()
- ip_port = ('127.0.0.1',8001)
- server.bind(ip_port)
- server.listen()
- conn,addr = server.accept()
- while 1:
- from_client_cmd = conn.recv(1024)
- print(from_client_cmd.decode('utf-8'))
- #接收到客户端发送来的系统指令,我服务端通过subprocess模块到服务端自己的系统里面执行这条指令
- sub_obj = subprocess.Popen(
- from_client_cmd.decode('utf-8'),
- shell=True,
- stdout=subprocess.PIPE, #正确结果的存放位置
- stderr=subprocess.PIPE #错误结果的存放位置
- )
- #从管道里面拿出结果,通过subprocess.Popen的实例化对象.stdout.read()方法来获取管道中的结果
- std_msg = sub_obj.stdout.read()
- #为了解决黏包现象,我们统计了一下消息的长度,先将消息的长度发送给客户端,客户端通过这个长度来接收后面我们要发送的真实数据
- std_msg_len = len(std_msg)
- print('指令的执行结果长度>>>>',len(std_msg))
- msg_lenint_struct = struct.pack('i',std_msg_len)
- conn.send(msg_lenint_struct+std_msg)
方案二:服务端
- import socket
- import struct
- client = socket.socket()
- client.connect(('127.0.0.1',8001))
- while 1:
- cmd = input('请输入指令:')
- #发送指令
- client.send(cmd.encode('utf-8'))
- #接收数据长度,首先接收4个字节长度的数据,因为这个4个字节是长度
- server_res_len = client.recv(4)
- msg_len = struct.unpack('i',server_res_len)[0]
- print('来自服务端的消息长度',msg_len)
- #通过解包出来的长度,来接收后面的真实数据
- server_cmd_result = client.recv(msg_len)
- print(server_cmd_result.decode('gbk'))
方案二:客户端
三.打印进度条
- #总共接收到的大小和总文件大小的比值:
- #all_size_len表示当前总共接受的多长的数据,是累计的
- #file_size表示文件的总大小
- per_cent = round(all_size_len/file_size,2) #将比值做成两位数的小数
- #通过\r来实现同一行打印,每次打印都回到行首打印
- print('\r'+ '%s%%'%(str(int(per_cent*100))) + '*'*(int(per_cent*100)),end='') #由于float类型的数据没法通过%s来进行字符串格式化,所以我在这里通过int来转换了一下,并用str转换了一下,后面再拼接上*,这个*的数量根据现在计算出来的比值来确定,就能够出来%3***这样的效果。自行使用上面的sys.stdout来实现一下这个直接print的效果。
打印进度条
网络编程-day3的更多相关文章
- 猫哥网络编程系列:HTTP PEM 万能调试法
注:本文内容较长且细节较多,建议先收藏再阅读,原文将在 Github 上维护与更新. 在 HTTP 接口开发与调试过程中,我们经常遇到以下类似的问题: 为什么本地环境接口可以调用成功,但放到手机上就跑 ...
- python select网络编程详细介绍
刚看了反应堆模式的原理,特意复习了socket编程,本文主要介绍python的基本socket使用和select使用,主要用于了解socket通信过程 一.socket模块 socket - Low- ...
- Linux Socket 网络编程
Linux下的网络编程指的是socket套接字编程,入门比较简单.在学校里学过一些皮毛,平时就是自学玩,没有见识过真正的socket编程大程序,比较遗憾.总感觉每次看的时候都有收获,但是每次看完了之后 ...
- 猫哥网络编程系列:详解 BAT 面试题
从产品上线前的接口开发和调试,到上线后的 bug 定位.性能优化,网络编程知识贯穿着一个互联网产品的整个生命周期.不论你是前后端的开发岗位,还是 SQA.运维等其他技术岗位,掌握网络编程知识均是岗位的 ...
- 浅谈C#网络编程(一)
阅读目录: 基础 Socket编程 多线程并发 阻塞式同步IO 基础 在现今软件开发中,网络编程是非常重要的一部分,本文简要介绍下网络编程的概念和实践. Socket是一种网络编程接口,它是对传输层T ...
- C++11网络编程
Handy是一个简洁优雅的C++11网络库,适用于linux与Mac平台.十行代码即可完成一个完整的网络服务器. 下面是echo服务器的代码: #include <handy/handy.h&g ...
- Java - 网络编程
Java的网络编程学习,关于计算机基础的学习参考:计算机网络基础学习 - sqh. 参考:
- Linux网络编程-IO复用技术
IO复用是Linux中的IO模型之一,IO复用就是进程预先告诉内核需要监视的IO条件,使得内核一旦发现进程指定的一个或多个IO条件就绪,就通过进程进程处理,从而不会在单个IO上阻塞了.Linux中,提 ...
- Python Socket 网络编程
Socket 是进程间通信的一种方式,它与其他进程间通信的一个主要不同是:它能实现不同主机间的进程间通信,我们网络上各种各样的服务大多都是基于 Socket 来完成通信的,例如我们每天浏览网页.QQ ...
随机推荐
- jmeter的新增函数说明
本文算是对<零成本实现Web性能测试:基于Apache JMeter>中的<详解JMeter函数和变量>进行狗尾续貂哈,因为最近版本的jmeter增加了几个新函数,在原书中没有 ...
- java反射之获取所有方法及其注解(包括实现的接口上的注解),获取各种标识符备忘
java反射之获取类或接口上的所有方法及其注解(包括实现的接口上的注解) /** * 获取类或接口上的所有方法及方法上的注解(包括方法实现上的注解以及接口上的注解),最完整的工具类,没有现成的工具类 ...
- 泛型集合List的详细用法
命名空间: System.Collections.Generic List<T>类是 ArrayList 类的泛型等效类. 该类使用大小可 按需动态增加 的数组实现 IList& ...
- mysql批量导出单结构与结构数据表脚本
由于一个库里面不需要导出全部, 只需要导出一部分指定的数据表结构与数据 那么就写了一个比较简单而且为了能偷懒的小shell #!/bin/bash #************************* ...
- Scrum Meeting 合集
一.Alpha [Alpha]Scrum meeting 1 [Alpha]Scrum meeting 2 [Alpha]Scrum meeting 3 [Alpha]Scrum meeting 4 ...
- IDEA 初建Spring项目(Hello Spring)
新建项目 在文件夹中建立一个项目文件 打开项目 打开IDEA,点击Open,根据所建项目路径找到该项目 依赖注入 点击项目名右键,点击new,点击file,创建pom.xml 内容为: <pro ...
- 20175312 2018-2019-2 《Java程序设计》第6周课下选做——类定义
20175312 2018-2019-2 <Java程序设计>第6周课下选做--类定义 设计思路 1.我觉得Book其实就是一个中转的作用,由测试类Bookself通过Book输入数据,然 ...
- 论文笔记:Auto-ReID: Searching for a Part-aware ConvNet for Person Re-Identification
Auto-ReID: Searching for a Part-aware ConvNet for Person Re-Identification 2019-03-26 15:27:10 Paper ...
- php LBS(附近地理位置)功能实现的一些思路
在开发中经常会遇到把数据库已有经纬度的地方进行距离排序然后返回给用户 例如一些外卖app打开会返回附近的商店,这个是怎么做到的呢? 思路一: 根据用户当前的位置,用计算经纬度距离的算法逐一计算比对距离 ...
- JVM-GC学习
http://blog.csdn.net/column/details/14851.html 地址记录