Python机器学习(python简介篇)
1.Python 数据类型
Python 内置的常用数据类型共有6中:
数字(Number)、布尔值(Boolean)、字符串(String)、元组(Tuple)、列表(List)、字典(Dictionary)。
数字:常用的数字类型包括整型数(Integer)、长整型(Long)、浮点数(Float)、复杂型数(Complex)。
10、100、-100都是整型数;-0.1、10.01是浮点数。
布尔值:True代表真,False代表假。
字符串:在Python里,字符串的表示使用成对的英文单引号,双引号进行表示,‘abc’或“123”。
元组:使用一组小括号()表示,(1,‘abc’,0.4)是一个包含三个元素的元组。假设上例的这个元组叫做t,那么t[0]=1,t[1]='abc'。默认索引的起始值为0,不是1。
列表:使用一对中括号[ ]来组织数据,[1,‘abc’,0.4]。需要注意的是Python允许在访问列表时同时修改列表里的数据,而元组则不然。
字典:包括多组键(key):值(value),Python使用大括号{ }来容纳这些键值对,{1:‘1’,‘abc’:0.1,0.4:80},假设上例字典为变量d,那么d[1]='1',d['abc']=0.1
2.Python 流程控制
比较常见的包括分支语句(if)和循环控制(for)
分支语句语法结构:
if布尔值/表达式:
else:
或者
if布尔值/表达式:
elif布尔值/表达式:
else:
代码1:分支语句代码样例:
=====》
b=True
if b:
print("It's True!")
else:
print('It's False!")
=====》
It's True!
=====》
b=False
c=True
if b:
print("b is True!")
elif c:
print('c is True!")
else:
print("both are False")
=====》
c is True!
循环控制语法结构:
for 临时变量 in 可遍历数据结构(列表、元组、字典)
执行语句
代码2:循环语句代码样例:
=====》
d={1:'1','abc':0.1,0.4:80}
for k in d:
print(k,":",d[k])
=====》
1:1
abc:0.1
0.4:80
1.3 Python函数模块设计
Python采用def关键字来定义一个函数:
代码3:函数定义和调用代码样例:
=====》
def foo(x):
return x**2
print(foo(8.0))
=====》
64.0
1.4 Python编程库(包)的导入
代码4:程序库/工具包导入代码示例
=====》
import math
#调用math包下的函数exp求自然指数
print(math.exp(2))
#2.从(from)math工具包里指定导入exp函数
from math import exp
print(exp(2))
#3.从(from)math工具包里指定导入exp函数,并且对exp重新命名为ep
from math import exp as ep
print(ep(2))
=====》
7.38905609893065
7.38905609893065
7.38905609893065
1.5 Python基础综合实践
代码5:良/恶性乳腺癌肿瘤预测代码样例
=====》
import pandas as pd
#调用pandas工具包的read_csv函数/模块,传入训练文件地址参数,获得返回的数据并且存至变量df_train
df_train=pd.read_csv('breast-cancer-train.csv')
#调用pandas工具包的read_csv函数/模块,传入测试文件地址参数,获得返回的数据并且存至变量df_test
df_test=pd.read_csv('breast-cancer-test.csv')
#选取‘肿块厚度’(Clump Thickness)与‘细胞大小’(Cell Size)作为特征,构建测试集中的正负分类样本
df_test_negative=df_test.loc[df_test['Type']==0][['Clump Thickness','Cell Size']]
df_test_positive=df_test.loc[df_test['Type']==1][['Clump Thickness','Cell Size']]
#导入matplotlib工具包中pyplot并命名为plt
import matplotlib.pyplot as plt
#matplotlib.pyplot.scatter(x,y,s=None,c=None,marker=None)
#x,y接收array。表示x轴和y轴对应的数据。无默认
#s接收数值或者一维的array。指定点的大小,若传入一维array,则表示每个点的大小。默认为None
#c接收颜色或者一维的array。指定点的颜色,若传入一维array,则表示每个点的颜色。默认为None
#marker接收特定string。表示绘制的点的类型。默认为None
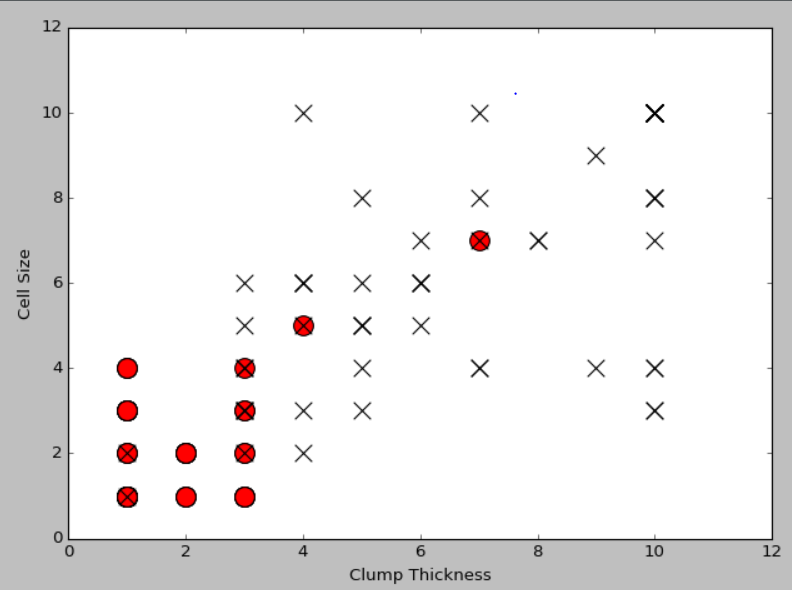
#绘制良性肿瘤样本点,标记为红色的o
plt.scatter(df_test_negative['Clump Thickness'],df_test_negative['Cell Size'],marker='o',s=200,c='red')
#绘制恶性肿瘤样本点,标记为黑色的x
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
#绘制x,y轴的说明
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
#显示图
plt.show()
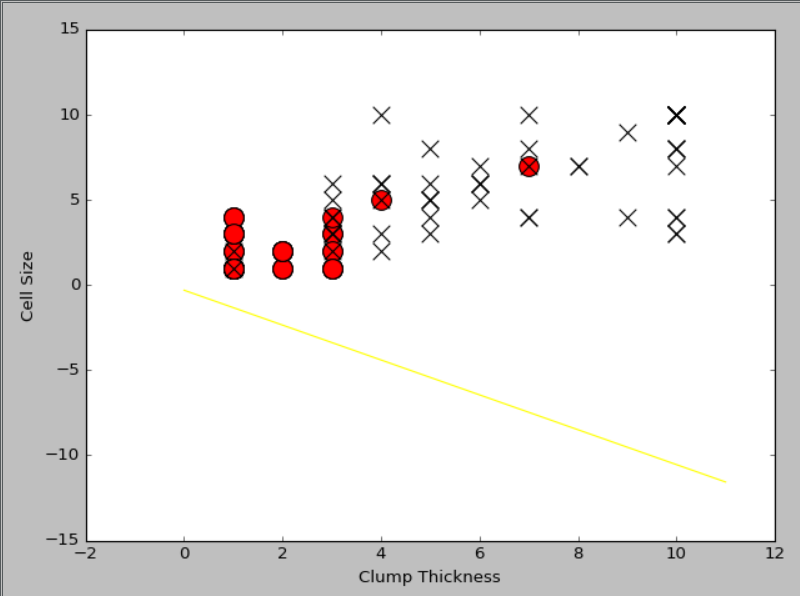
import numpy as np
#利用numpy中的random函数随机采样直线的截距和系数
intercept=np.random.random([1])
# print(intercept)#[0.79195932]
coef=np.random.random([2])
# print(coef)#[0.37965899 0.47387532]
lx=np.arange(0,12)
# print(lx)#[ 0 1 2 3 4 5 6 7 8 9 10 11]
ly=(-intercept-lx*coef[0])/coef[1]
# print(ly)
# [-1.09996728 -1.60387435 -2.10778142 -2.61168849 -3.11559556 -3.61950262
# # -4.12340969 -4.62731676 -5.13122383 -5.6351309 -6.13903797 -6.64294503]
#绘制一条随机直线
plt.plot(lx,ly,c='yellow')
plt.scatter(df_test_negative['Clump Thickness'],df_test_negative['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()
#导入sklearn中的逻辑斯蒂回归分类器
from sklearn.linear_model import LogisticRegression
lr=LogisticRegression()
#使用前10条训练样本学习直线的系数和截距
lr.fit(df_train[['Clump Thickness','Cell Size']][:10],df_train['Type'][:10])
print('Testing accuracy (10 training samples):',lr.score(df_test[['Clump Thickness','Cell Size']],df_test['Type']))
intercept=lr.intercept_
coef=lr.coef_[0,:]
#原本这个分类面应该是lx*coef[0]+ly*coef[1]+intercept=0,映射到2维平面上之后,应该是:
ly=(-intercept-lx*coef[0])/coef[1]
plt.plot(lx,ly,c='green')
plt.scatter(df_test_negative['Clump Thickness'],df_test_negative['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()

lr=LogisticRegression()
#使用所有的训练样本学习直线的系数和截距
lr.fit(df_train[['Clump Thickness','Cell Size']],df_train['Type'])
print('Testing accuracy (all training samples):',lr.score(df_test[['Clump Thickness','Cell Size']],df_test['Type']))
intercept=lr.intercept_
coef=lr.coef_[0,:]
#原本这个分类面应该是lx*coef[0]+ly*coef[1]+intercept=0,映射到2维平面上之后,应该是:
ly=(-intercept-lx*coef[0])/coef[1]
plt.plot(lx,ly,c='blue')
plt.scatter(df_test_negative['Clump Thickness'],df_test_negative['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()
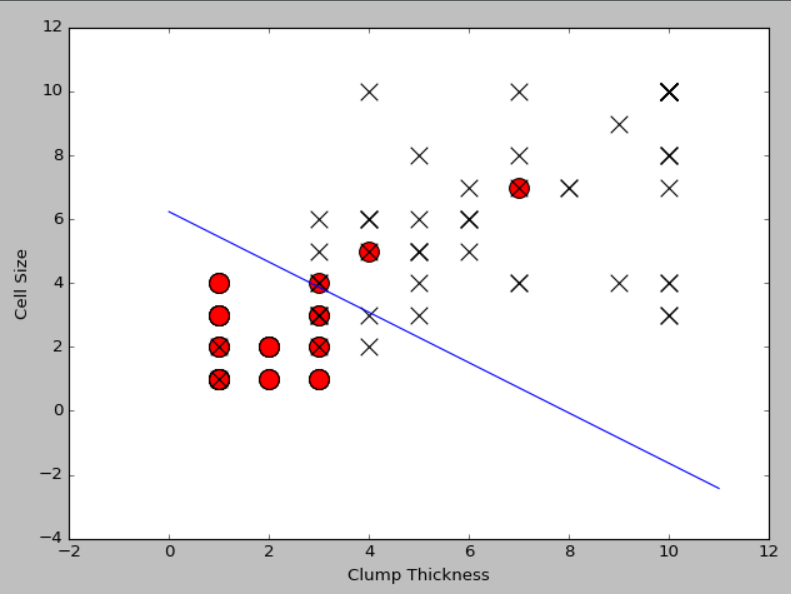
Testing accuracy (all training samples): 0.9371428571428572
Python机器学习(python简介篇)的更多相关文章
- Python机器学习(基础篇---监督学习(线性分类器))
监督学习经典模型 机器学习中的监督学习模型的任务重点在于,根据已有的经验知识对未知样本的目标/标记进行预测.根据目标预测变量的类型不同,我们把监督学习任务大体分为分类学习与回归预测两类.监督学习任务的 ...
- Python机器学习(基础篇---监督学习(k近邻))
K近邻 假设我们有一些携带分类标记的训练样本,分布于特征空间中,对于一个待分类的测试样本点,未知其类别,按照‘近朱者赤近墨者黑’,我们需要寻找与这个待分类的样本在特征空间中距离最近的k个已标记样本作为 ...
- Python机器学习(基础篇---监督学习(集成模型))
集成模型 集成分类模型是综合考量多个分类器的预测结果,从而做出决策. 综合考量的方式大体分为两种: 1.利用相同的训练数据同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则作出最终的 ...
- Python机器学习(基础篇---监督学习(朴素贝叶斯))
朴素贝叶斯 朴素贝叶斯分类器的构造基础是贝叶斯理论.采用概率模型来表述,定义x=<x1,x2,...,xn>为某一n维特征向量,y∈{c1,c2,...ck}为该特征向量x所有k种可能的类 ...
- Python机器学习(基础篇---监督学习(支持向量机))
支持向量机(分类) 支持向量机分类器根据训练样本的分布,搜索所有可能的线性分类器中最佳的那个.我们会发现决定其直线位置的样本并不是所有训练数据,而是其中的两个空间间隔最小的两个不同类别的数据点,而我们 ...
- 机器学习1—简介及Python机器学习环境搭建
简介 前置声明:本专栏的所有文章皆为本人学习时所做笔记而整理成篇,转载需授权且需注明文章来源,禁止商业用途,仅供学习交流.(欢迎大家提供宝贵的意见,共同进步) 正文: 机器学习,顾名思义,就是研究计算 ...
- python机器学习简介
目录 一:学习机器学习原因和能够解决的问题 二:为什么选择python作为机器学习的语言 三:机器学习常用库简介 四:机器学习流程 机器学习是一门多领域交叉学科,涉及概率论.统计学.逼近论.凸分析 ...
- Python学习【第一篇】Python简介
Python简介 Python前世今生 Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言. 现在,全世界差不多有600多种编 ...
- Python之路(第一篇):Python简介和基础
一.开发简介 1.开发: 开发语言: 高级语言:python.JAVA.PHP.C#..ruby.Go-->字节码 低级语言: ...
随机推荐
- Subversion ----> svnserve.conf / authz / passwd / hooks-env.tmpl <<翻译笔记>>
svnserve.conf 假如你使用这个文件去允许访问这个仓库,那么这个文件控制着svnserve后台进程的配置.(但是如果你只是允许通过http和/或者 file:URLs,则这个文件就不起作用了 ...
- (最完美)红米手机5的Usb调试模式在哪里打开的教程
就在我们使用安卓手机接通PC的时候,或者使用的有些app比如我们企业营销部门就在使用的app引号精灵,之前老版本就需要开启usb开发者调试模式下使用,现就在新版本不需要了,如果手机没有开启usb开发者 ...
- JAVA程序设计的第一次作业
这是我第一次接触博客,刚开始用博客很生疏,感觉很麻烦,但是后来慢慢从老师那里了解到了许多博客可以带给我们的便利.通过博客,我们不仅可以记录自己从刚开始进入程序学习的懵懵懂懂到后来想要学,想深究,想探讨 ...
- cookie,session,fileter,liscen
会话技术: 会话:一次会话中发生多次请求和响应 一次会话:从浏览器的打开到关闭 功能:在会话的过程中 ,可以共享数据 cookie:客户端的会话技术session:服务端的会话技术 Cookie:小饼 ...
- ArcSDE10.1配置Oracle 监听器来使用SQL操作ST_Geometry(个人改动版)
发了两天的时间来解决配置Oracle 监听器来使用SQL操作ST_Geometry的配置,网上搜索一大片,结果真正找到的只有方法可用,下面把这个方法我个人在总结下. ArcSDE10.1配置Oracl ...
- JMETER-01
jmter安装 1.Linxu安装: 步骤:下载JMeter包-->解压包-->赋权限-->配置环境变量-->测试服务 1.下载:wget http://mirrors.hus ...
- python3读写csv文件
python读取CSV文件 python中有一个读写csv文件的包,直接import csv即可.利用这个python包可以很方便对csv文件进行操作,一些简单的用法如下. 1. 读文件 csv_ ...
- mac电脑上不能用移动硬盘的原因和方法
原因: 一般性是因为这个移动硬盘的格式是 NTFS 格式的,对于这种格式的磁盘格式,在苹果系统中却是不支持往硬盘里写入数据的 解决方法: 方法一: ntfs的格式分区,这种格式分区与我们的苹果电脑自身 ...
- 使用EasyPOI导出excel示例
package com.mtoliv.sps.controller; import java.io.IOException; import java.io.OutputStream; import j ...
- java 动态增/减集合元素
1. 简介 有时候需要在集合遍历过程中进行增/删,下面介绍几种正确的操作方式. 2. 示例 例如有如下集合[1, 2, 2, 3, 5],需要删除被2整除的元素. import java.util.* ...