GBDT的数学原理
一、GBDT的原理
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。
GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。业界中,Facebook使用其来自动发现有效的特征、特征组合,来作为LR模型中的特征,以提高CTR预估(Click-Through Rate Prediction)的准确性(详见参考文献5、6);GBDT在淘宝的搜索及预测业务上也发挥了重要作用(详见参考文献7)。
提升树利用加法模型和前向分步算法实现学习的优化过程。当损失函数时平方损失和指数损失函数时,每一步的优化很简单,如平方损失函数学习残差回归树。

但对于一般的损失函数,往往每一步优化没那么容易,如上图中的绝对值损失函数和Huber损失函数。针对这一问题,Freidman提出了梯度提升算法:利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值,拟合一个回归树。(注:鄙人私以为,与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例)算法如下(截图来自《The Elements of Statistical Learning》):

算法步骤解释:
- 1、初始化,估计使损失函数极小化的常数值,它是只有一个根节点的树,即ganma是一个常数值。
- 2、
(a)计算损失函数的负梯度在当前模型的值,将它作为残差的估计
(b)估计回归树叶节点区域,以拟合残差的近似值
(c)利用线性搜索估计叶节点区域的值,使损失函数极小化
(d)更新回归树 - 3、得到输出的最终模型 f(x)
二、GBDT的参数设置
1、推荐GBDT树的深度:6;(横向比较:DecisionTree/RandomForest需要把树的深度调到15或更高)
2、【问】xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
用xgboost/gbdt在在调参的时候把树的最大深度调成6就有很高的精度了。但是用DecisionTree/RandomForest的时候需要把树的深度调到15或更高。用RandomForest所需要的树的深度和DecisionTree一样我能理解,因为它是用bagging的方法把DecisionTree组合在一起,相当于做了多次DecisionTree一样。但是xgboost/gbdt仅仅用梯度上升法就能用6个节点的深度达到很高的预测精度,使我惊讶到怀疑它是黑科技了。请问下xgboost/gbdt是怎么做到的?它的节点和一般的DecisionTree不同吗?
【答】
(1)Boosting主要关注降低偏差(bais),因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差(variance),因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
(2)随机森林(random forest)和GBDT都是属于集成学习(ensemble learning)的范畴。集成学习下有两个重要的策略Bagging和Boosting。
Bagging算法是这样做的:每个分类器都随机从原样本中做有放回的采样,然后分别在这些采样后的样本上训练分类器,然后再把这些分类器组合起来。简单的多数投票一般就可以。其代表算法是随机森林。Boosting的意思是这样,他通过迭代地训练一系列的分类器,每个分类器采用的样本分布都和上一轮的学习结果有关。其代表算法是AdaBoost, GBDT。
(3)其实就机器学习算法来说,其泛化误差可以分解为两部分,偏差(bias)和方差(variance)。这个可由下图的式子导出(这里用到了概率论公式D(X)=E(X^2)-[E(X)]^2)。偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。这个有点儿绕,不过你一定知道过拟合。
如下图所示,当模型越复杂时,拟合的程度就越高,模型的训练偏差就越小。但此时如果换一组数据可能模型的变化就会很大,即模型的方差很大。所以模型过于复杂的时候会导致过拟合。
当模型越简单时,即使我们再换一组数据,最后得出的学习器和之前的学习器的差别就不那么大,模型的方差很小。还是因为模型简单,所以偏差会很大。
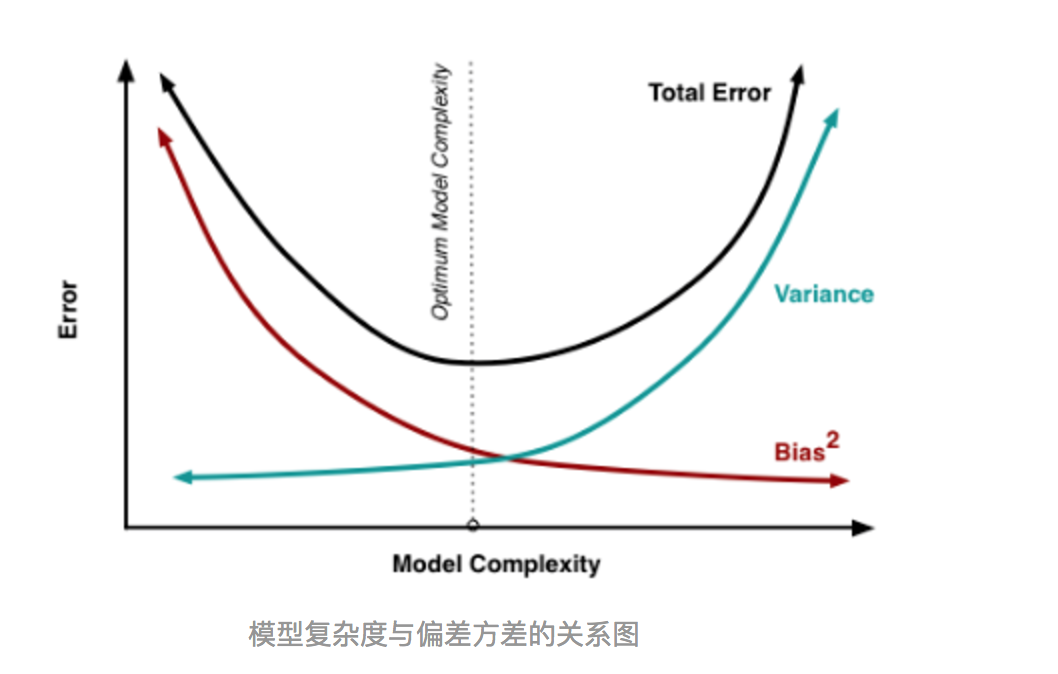
也就是说,当我们训练一个模型时,偏差和方差都得照顾到,漏掉一个都不行。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance) ,因为采用了相互独立的基分类器多了以后,h的值自然就会靠近.所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树。
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
三、参考文献
1、http://www.jianshu.com/p/005a4e6ac775
GBDT的数学原理的更多相关文章
- 机器学习系列------1. GBDT算法的原理
GBDT算法是一种监督学习算法.监督学习算法需要解决如下两个问题: 1.损失函数尽可能的小,这样使得目标函数能够尽可能的符合样本 2.正则化函数对训练结果进行惩罚,避免过拟合,这样在预测的时候才能够准 ...
- OpenGL坐标变换及其数学原理,两种摄像机交互模型(附源程序)
实验平台:win7,VS2010 先上结果截图(文章最后下载程序,解压后直接运行BIN文件夹下的EXE程序): a.鼠标拖拽旋转物体,类似于OGRE中的“OgreBites::CameraStyle: ...
- RSA加密数学原理
RSA加密数学原理 */--> *///--> *///--> UP | HOME RSA加密数学原理 Table of Contents 1 引言 2 RSA加密解密过程 2.1 ...
- PCA的数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维 数据的 ...
- PCA数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- 【机器学习笔记之七】PCA 的数学原理和可视化效果
PCA 的数学原理和可视化效果 本文结构: 什么是 PCA 数学原理 可视化效果 1. 什么是 PCA PCA (principal component analysis, 主成分分析) 是机器学习中 ...
- word2vec 数学原理
word2vec 是 Google 于 2013 年推出的一个用于获取词向量的开源工具包.我们在项目中多次使用到它,但囿于时间关系,一直没仔细探究其背后的原理. 网络上 <word2vec 中的 ...
- 非对称加密技术- RSA算法数学原理分析
非对称加密技术,在现在网络中,有非常广泛应用.加密技术更是数字货币的基础. 所谓非对称,就是指该算法需要一对密钥,使用其中一个(公钥)加密,则需要用另一个(私钥)才能解密. 但是对于其原理大部分同学应 ...
- PCA的数学原理(转)
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
随机推荐
- particular.js
参数 键值 参数选项/ 说明 实例 particles.number.value number 数量 40 particles.number.density.enable boolean t ...
- java mvn:安装jar包
mvn install:install-file -Dfile=fastdfs-client-java-1.27-SNAPSHOT.jar(路径) -DgroupId=org.csource -Dar ...
- 浅谈Pool对象
Pool对象的技术指标: 避免频繁创建经常使用的稀有资源,提高工作效率. 控制阀值,很多情况下一些关键资源都有一个最佳并发数,超过这个拐点性能有可能急剧下降,也有可能继续增大并发数性能不能提升. 安全 ...
- document.body.scrollTop和document.documentElement.scrollTop 以及值为0的问题
转自http://wo13145219.iteye.com/blog/2001598 一.先遇到document.body.scrollTop值为0的问题 做页面的时候可能会用到位置固定的层,读取do ...
- python爬虫-入门-了解爬虫
作为一个爬虫新手,我觉得首先要了解爬虫是的作用以及应用. 作用:通过爬虫获取网页内的信息.包括:标题(title)图片(image)链接(url)等等 应用:抽取所需信息,进行数据汇总及分析(从事网页 ...
- DataSet结果转模型类
引入命名空间: using System.Data; using System.Reflection; 类封装代码: public class ModelHelper { public T To< ...
- EF开发中EntityFramework在web.config中的配置问题
异常: 未找到具有固定名称“System.Data.SqlClient”的 ADO.NET 提供程序的实体框架提供程序.请确保在应用程序配置文件的“entityFramework”节中注册了该提供程序 ...
- iOS 底层解析weak的实现原理(包含weak对象的初始化,引用,释放的分析)
原文 很少有人知道weak表其实是一个hash(哈希)表,Key是所指对象的地址,Value是weak指针的地址数组.更多人的人只是知道weak是弱引用,所引用对象的计数器不会加一,并在引用对象被释放 ...
- 这里我们介绍的是 40+ 个非常有用的 Oracle 查询语句,主要涵盖了日期操作,获取服务器信息,获取执行状态,计算数据库大小等等方面的查询。这些是所有 Oracle 开发者都必备的技能,所以快快收藏吧!
日期/时间 相关查询 获取当前月份的第一天 运行这个命令能快速返回当前月份的第一天.你可以用任何的日期值替换 “SYSDATE”来指定查询的日期. SELECT TRUNC (SYSDATE, 'MO ...
- vue做的第二个app
用vue做应用最好的还是组件的复用上次做饿了吗的app封装了一个评分star的组件只要引入组件传入size大小和score分数就行了,这次做豆瓣直接就就用上了不用重复写代码.不过vue做单页应用全部挂 ...