MYSQL实战-------丁奇(极客时间)学习笔记
1.基础架构:一条sql查询语句是如何执行的?
mysql> select * from T where ID=10;

2.基础架构:一条sql更新语句是如何执行的?
mysql> update T set c=c+1 where ID=2;
redo log
(1)存储引擎的日志,InnoDB特有的;
(2)物理日志
(3)循环写,空间固定会用完;
binlog
(1)server端日志,所有引擎都有;
(2)逻辑日志
(3)追加写,文件写到一定大小,切换下一个,并不会覆盖之前的日志;
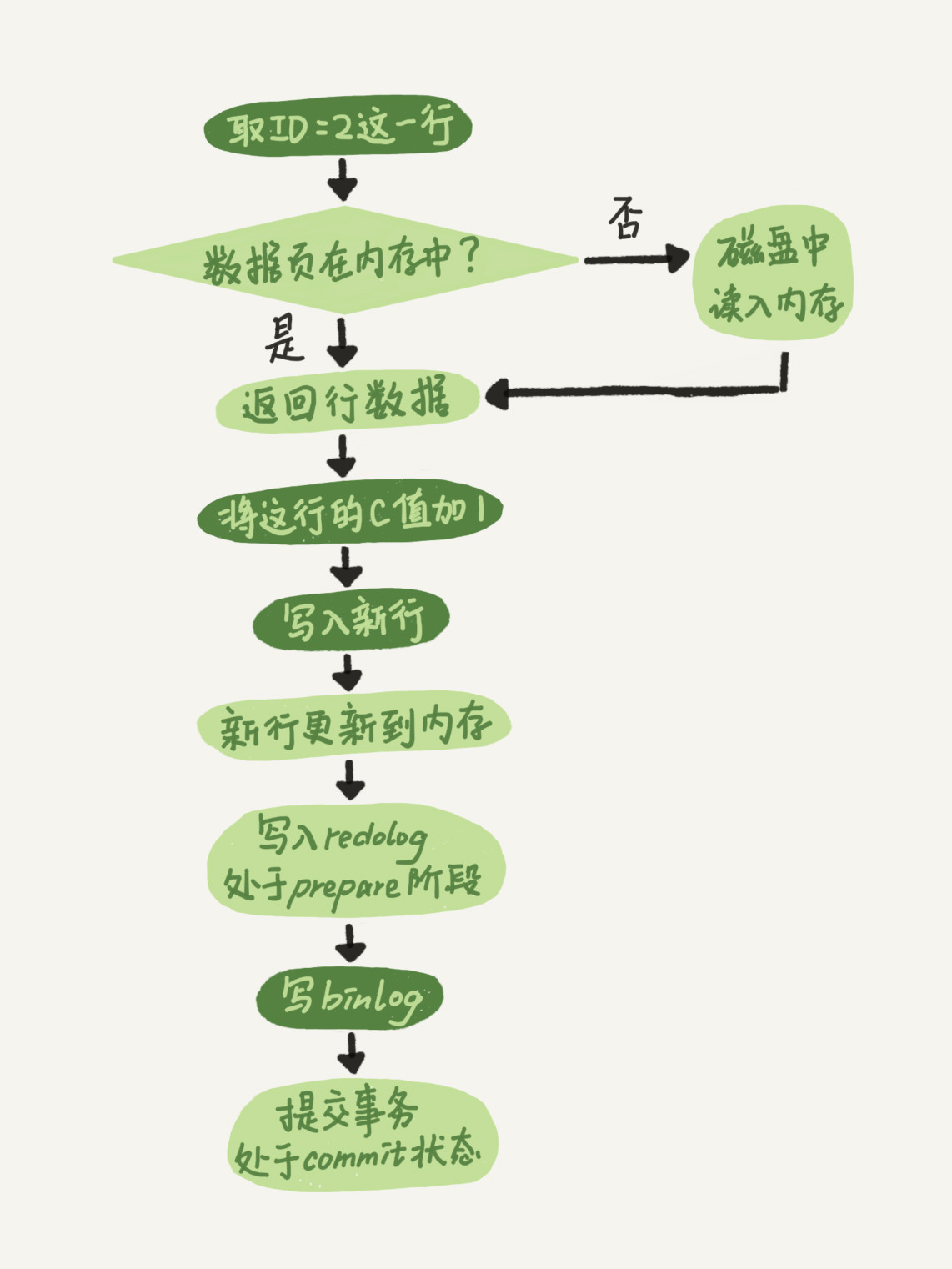
redolog的写入拆分成两个步骤:prepare和commit
redo log 和binlog都可以用于表示事务的提交状态,两阶段提交是为了维持这两个状态一致。
恢复:

注:正常执行redolog commit;崩溃恢复的时候可以接受redolog prepare并且binglog完整
3.事务隔离
MyISAM不支持事务,InnoDB 支持事务
读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到。
读已提交:别人改数据的事务已经提交,我在我的事务中才能读到。
可重复读:别人改数据的事务已经提交,我在我的事务中也不去读。(对账的例子)
串行:我的事务尚未提交,别人就别想改数据。
https://blog.csdn.net/changhenshui1990/article/details/77161401
4.索引(上)
索引---目录:提供数据查询的效率
(1)哈希表:适合等值查询的场景
缺点:范围查找比较麻烦
哈希冲突:链表(两个key生成的N一样)
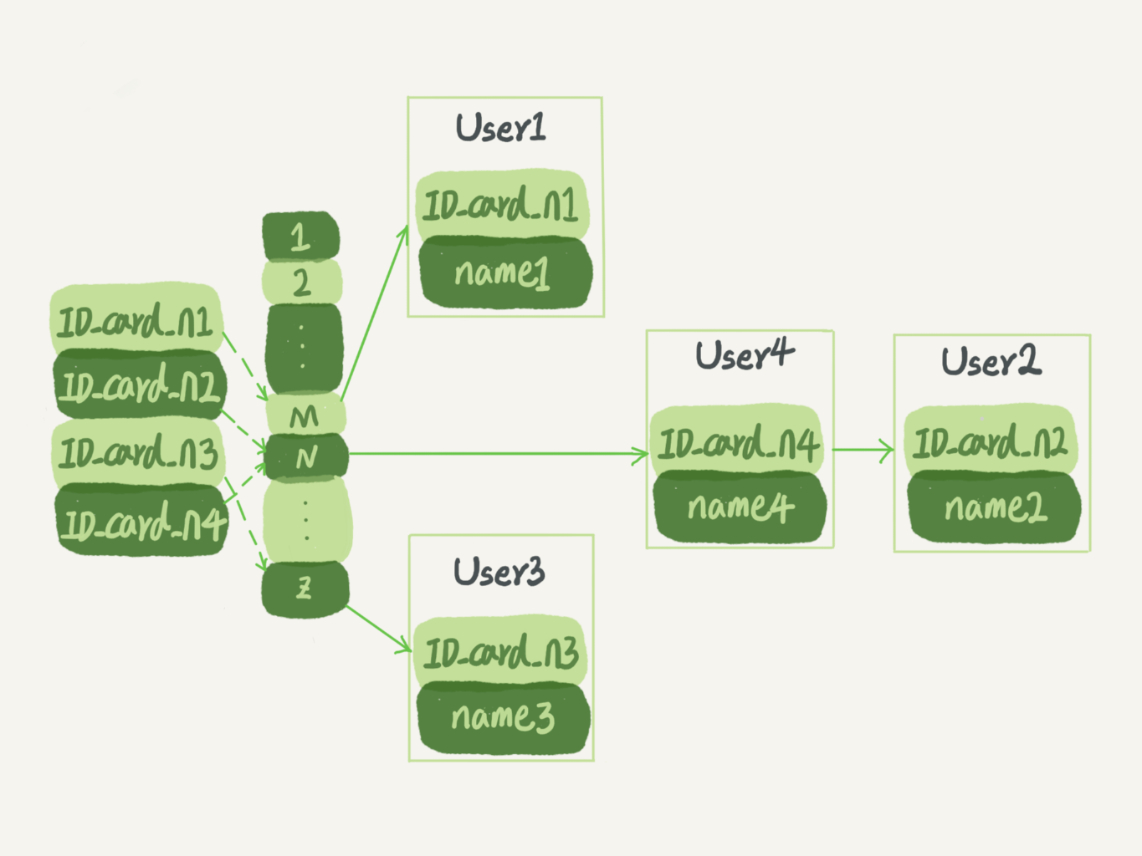
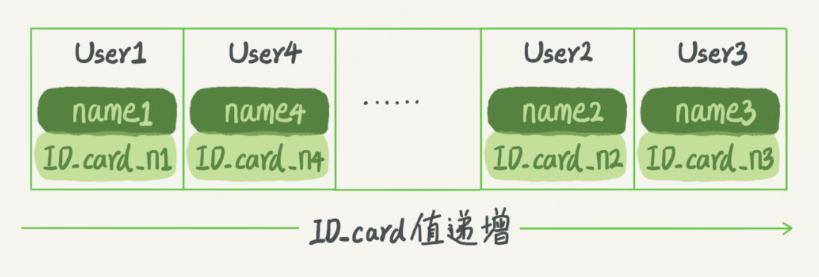
(2)有序数组:等值查找,范围查询性能都很好、只适合静态存储引擎
缺点:更新比较麻烦
(3)二叉搜索树:每个节点的左儿子小于父节点,父节点又小于右儿子
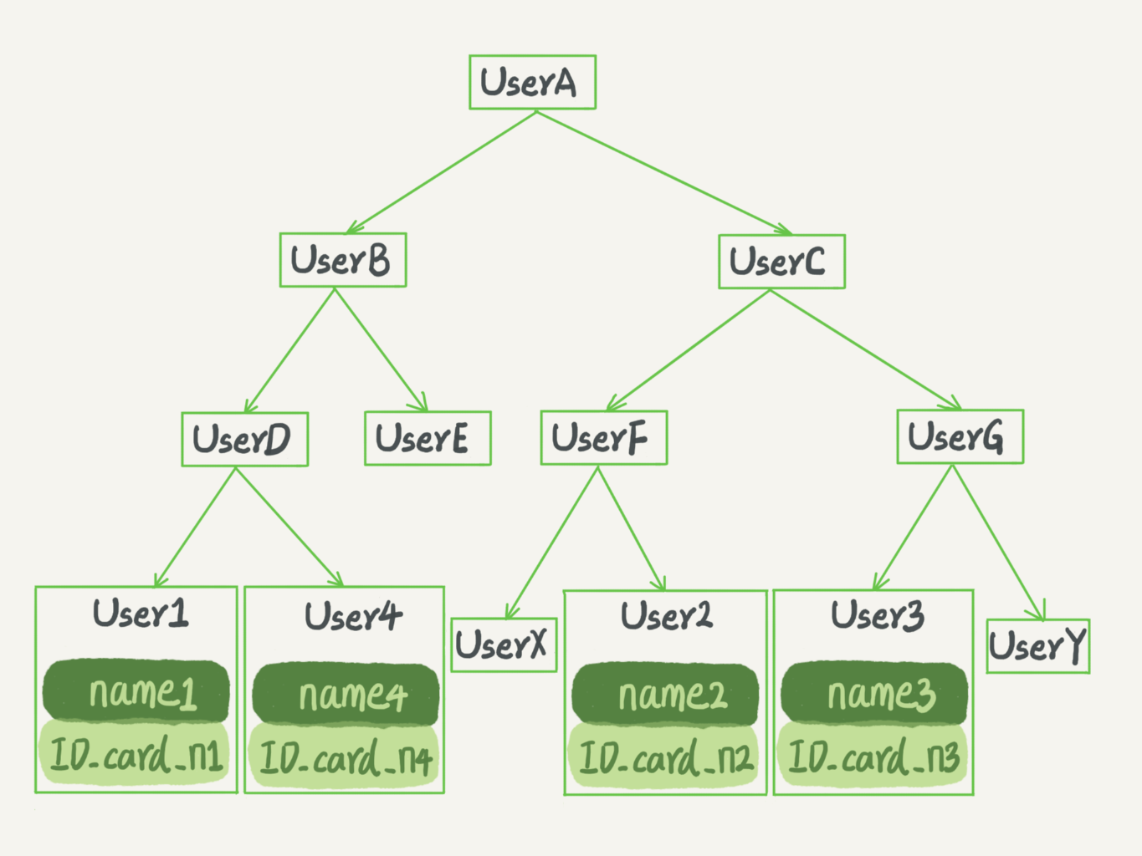
InnoDB的索引模型
B+树索引模型
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
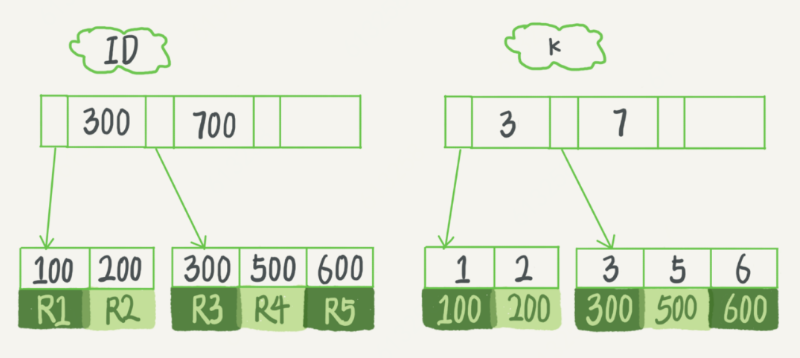
索引类型:主建索引、非主建索引
主建索引的叶子节点存储:整行数据(聚簇索引),主建索引只要搜索id这个B+ Tree就可以拿到数据
非主建索引叶子节点:主建的值(二级索引),普通索引先搜索索引拿到主建值,再到主建索引搜索一次(回表)
索引维护:
一个数据页满了,按照B+Tree算法,新增加一个数据页,叫做页分裂,会导致性能下降。空间利用率降低大概50%。当相邻的两个数据页利用率很低的时候会做数据页合并,合并的过程是分裂过程的逆过程。
性能和存储上来考虑,自增主建往往是更合理的选择;递增插入,追加,不会触发叶子节点分裂。
业务字段用作主建:(1)只有一个索引(2)该索引必须唯一索引。-------------------------直接将这个索引设置成主建,避免每次查询搜索两棵树。
5.索引(下)
(1)覆盖索引:select ID from T where k betwe 3 and 5 不需要回表(回到主键索引树搜索的过程,成为回表)

(2)前缀索引
(3)索引下推
总结:
1、覆盖索引:如果查询条件使用的是普通索引(或是联合索引的最左原则字段),查询结果是联合索引的字段或是主键,不用回表操作,直接返回结果,减少IO磁盘读写读取正行数据
2、最左前缀:联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符
3、联合索引:根据创建联合索引的顺序,以最左原则进行where检索,比如(age,name)以age=1 或 age= 1 and name=‘张三’可以使用索引,单以name=‘张三’ 不会使用索引,考虑到存储空间的问题,还请根据业务需求,将查找频繁的数据进行靠左创建索引。
4、索引下推:like 'hello%’and age >10 检索,MySQL5.6版本之前,会对匹配的数据进行回表查询。5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度
6.数据库锁——行锁,表锁
锁:并发
(1)全局锁:对整个数据库实例加锁,全库数据备份的时候用;(InnoDB采用事务,可重复读可以支持;不支持事务的引擎不能够实现,采用FTWRL) FTWRL——保证只读
(2)表级锁:表锁、元数据锁;
(3)行级锁:InnoDB(行锁)、MyIsAM(不支持行锁)
7.索引选择——唯一索引,普通索引
8.给字符串字段加索引
前缀索引
mysql> alter table SUser add index index1(email);
或
mysql> alter table SUser add index index2(email(6));




使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本
前缀索引对覆盖索引的影响:

其他方式: 倒序存储、hash字段
9.mysql "抖"了一下
WAL:先写日志,再写磁盘
刷脏页(flush)
(1)InnoDB的redo log满了的时候
(2)内存不够用了,先将脏页写到磁盘
(3)mysql系统空闲的时候
(4)mysql正常关闭的时候
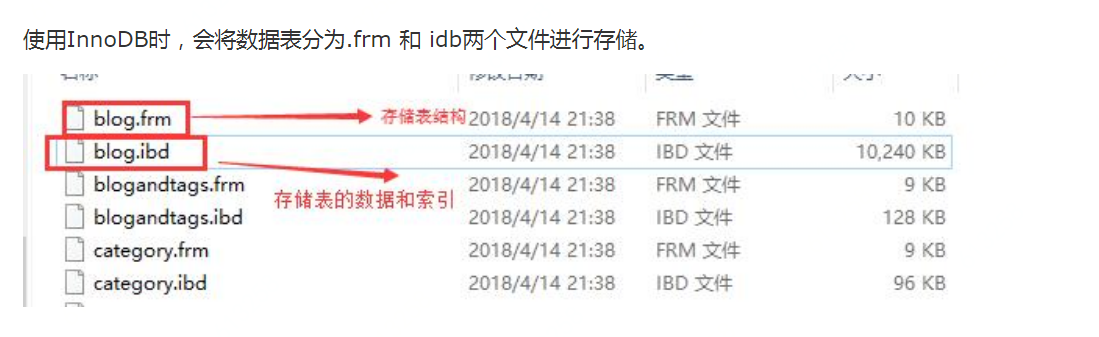
10.数据删除,表文件大小不变
InnoDB:表结构(.frm)定义和数据(.ibd)。
delete 命令其实只是把记录的位置,或者数据页标记为“可复用”,但磁盘文件的大小是不会变的。----空洞
重建表可以收缩空间
11.count(*)的实现
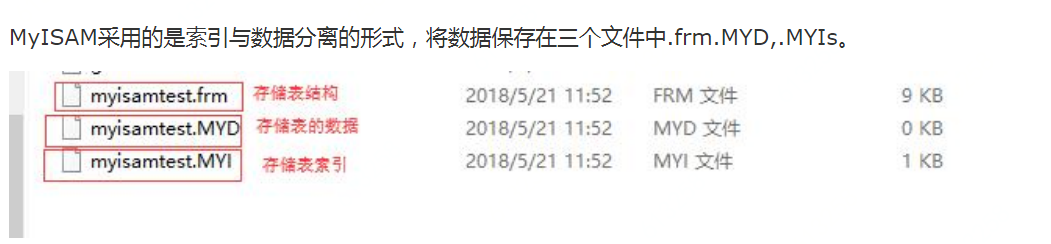
MyISAM:一个表的总行数存在了磁盘上
InnoDB:把数据一行一行地从引擎里面读出来,然后累加


count(字段)<count(主建id)<count(1)约等于count(*)
12.order by的原理
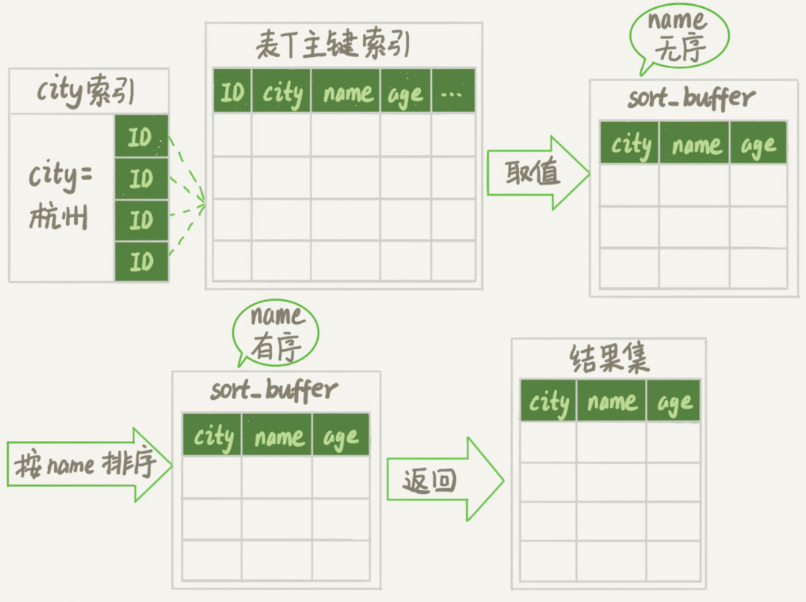
(1)全字段排序:
缺点:
1.造成sort_buffer中存放不下很多数据,因为除了排序字段还存放其他字段,对sort_buffer的利用效率不高
2.当所需排序数据量很大时,会有很多的临时文件,排序性能也会很差
优点:MySQL认为内存足够大时会优先选择全字段排序,因为这种方式比rowid 排序避免了一次回表操作
(2)rowId排序
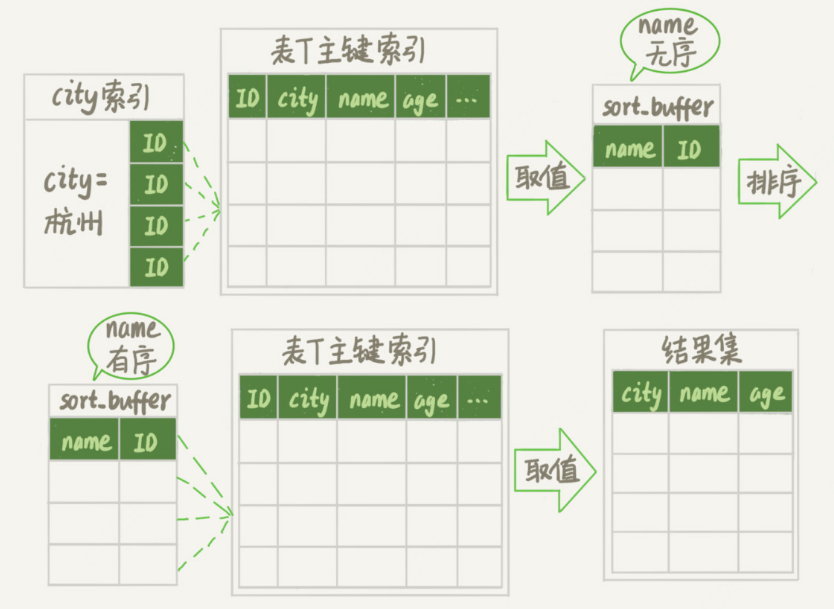
优点:更好的利用内存的sort_buffer进行排序操作,尽量减少对磁盘的访问
缺点:回表的操作是随机IO,会造成大量的随机读,不一定就比全字段排序减少对磁盘的访问
13.mysql随机消息
mysql> select word from words order by rand() limit 3;
14.逻辑相同的sql语句性能相差很大
(1)条件字段函数
mysql> select count(*) from tradelog where month(t_modified)=7;
如果对字段做了函数计算,就用不上索引了,这是 MySQL 的规定。
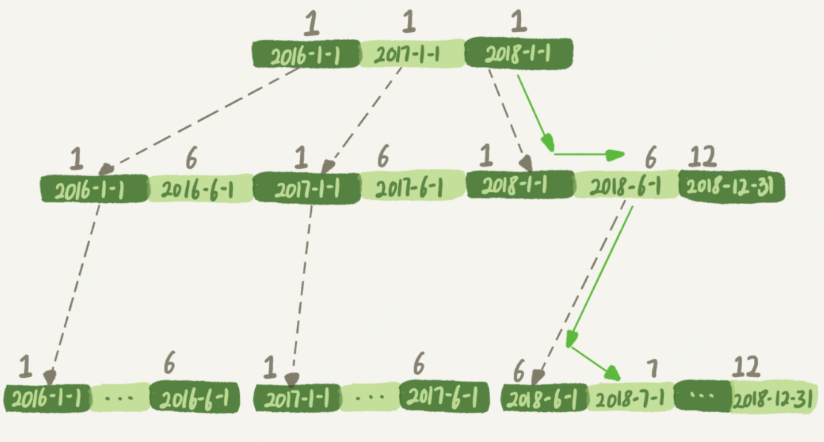
对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
mysql> select count(*) from tradelog where
-> (t_modified >= '2016-7-1' and t_modified<'2016-8-1') or
-> (t_modified >= '2017-7-1' and t_modified<'2017-8-1') or
-> (t_modified >= '2018-7-1' and t_modified<'2018-8-1');
(2)隐式类型转换
mysql> select * from tradelog where tradeid=110717;
相当于 mysql> select * from tradelog where CAST(tradid AS signed int) = 110717;
对索引字段做函数操作,优化器会放弃走树搜索功能。
(3)隐式字符串编码转换
15.查一行数据也很慢
(1)查询长时间不返回:等MDL锁、等flush、等行锁
(2)查询慢:没有加索引,需要全表扫描;
16.幻读
间隙锁
17.mysql如何保证数据不丢失
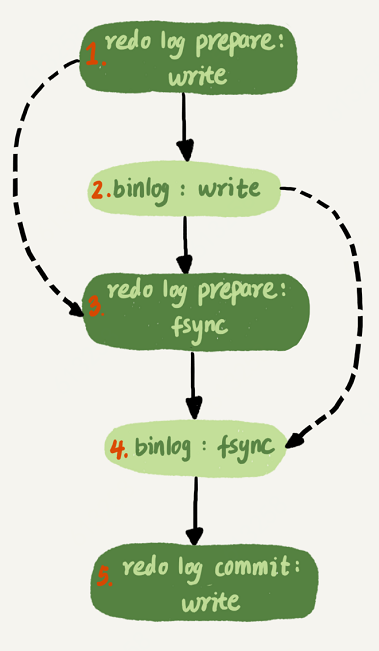
18.mysql主备一致:binlog归档
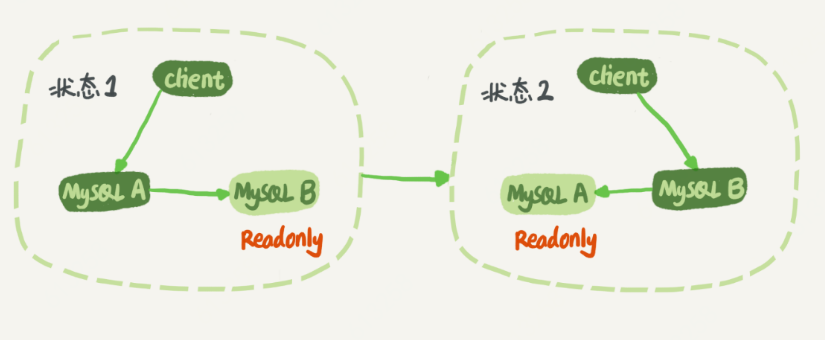
binlog的格式:
(1)statement

(2)row
(3)mixed
19.mysql如何保证高可用
主备(写数据)、主从(读数据)------一主多从
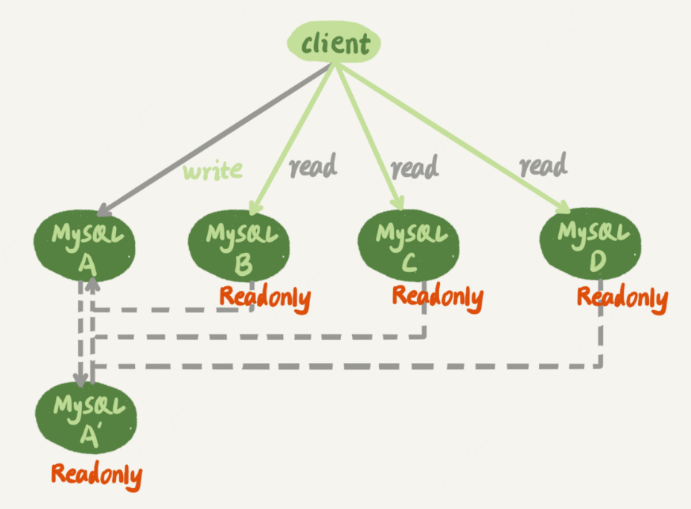
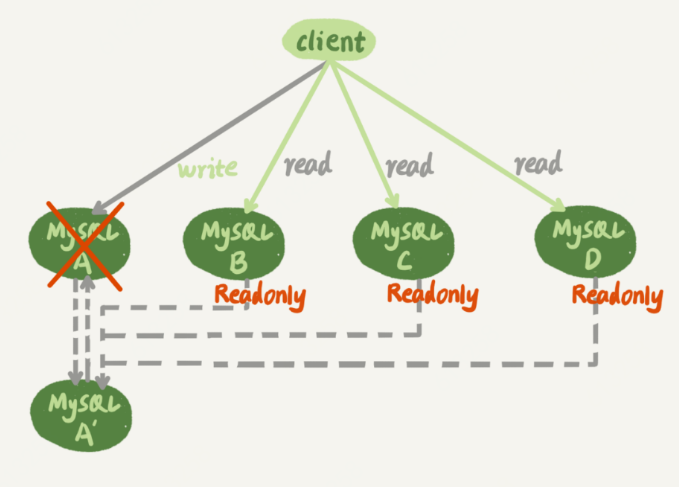
20.mysql读写分离
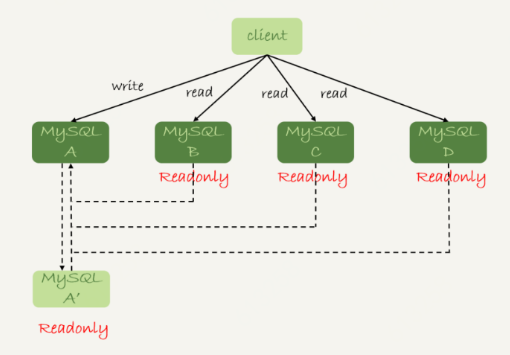
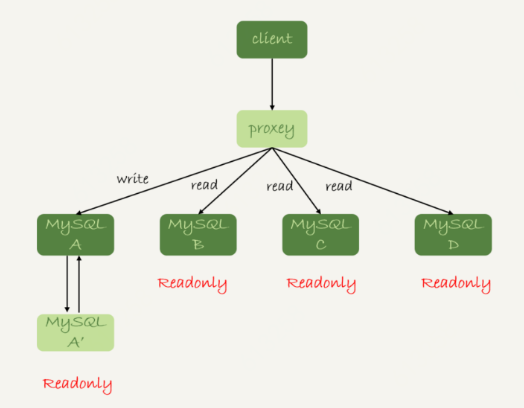
21.join
select * from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=50;
select * from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=50;
第二条语句更好,小表作为驱动表;
22.分区表
CREATE TABLE `t` (
`ftime` datetime NOT NULL,
`c` int(11) DEFAULT NULL,
KEY (`ftime`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE (YEAR(ftime))
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,
PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);
insert into t values('2017-4-1',1),('2018-4-1',1);

索引参考:https://blog.csdn.net/tongdanping/article/details/79878302
https://www.cnblogs.com/yuyue2014/p/3662005.html
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
https://www.cnblogs.com/liqiangchn/p/9066686.html
MYSQL实战-------丁奇(极客时间)学习笔记的更多相关文章
- MySQL的过滤(极客时间学习笔记)
数据过滤 SQL的数据过滤, 可以减少不必要的数据行, 从而可以达到提升查询效率的效果. 比较运算符 在SQL中, 使用WHERE子句对条件进行筛选, 筛选的时候比较运算符是很重要. 上面的比较运算符 ...
- MySQL的select(极客时间学习笔记)
查询语句 首先, 准备数据, 地址是: https://github.com/cystanford/sql_heros_data, 除了id以外, 24个字段的含义如下: 查询 查询分为单列查询, 多 ...
- Mysql中的sql是如何执行的 --- 极客时间学习笔记
MySQL中的SQL是如何执行的 MySQL是典型的C/S架构,也就是Client/Server架构,服务器端程序使用的mysqld.整体的MySQL流程如下图所示: MySQL是有三层组成: 连接层 ...
- SQL的概念与发展 - 极客时间学习笔记
了解SQL SQL的两个重要标准是SQL92和SQL99. SQL语言的划分 DDL,也叫Data Definition Language,也就是数据定义语言,用来定义数据库对象,包括数据库.数据表和 ...
- DDL创建数据库,表以及约束(极客时间学习笔记)
DDL DDL是DBMS的核心组件,是SQL的重要组成部分. DDL的正确性和稳定性是整个SQL发型的重要基础. DDL的基础语法及设计工具 DDL的英文是Data Definition Langua ...
- java并发编程实践——王宝令(极客时间)学习笔记
1.并发 分工:如何高效地拆解任务并分配给线程 同步:线程之间如何协作 互斥:保证同一时刻只允许一个线程访问共享资源 Fork/Join 框架就是一种分工模式,CountDownLatch 就是一种典 ...
- Mysql实战45讲 06讲全局锁和表锁:给表加个字段怎么有这么多阻碍 极客时间 读书笔记
Mysql实战45讲 极客时间 读书笔记 Mysql实战45讲 极客时间 读书笔记 笔记体会: 根据加锁范围:MySQL里面的锁可以分为:全局锁.表级锁.行级锁 一.全局锁:对整个数据库实例加锁.My ...
- Mysql实战45讲 05讲深入浅出索引(下)极客时间 读书笔记
极客时间 Mysql实战45讲 04讲深入浅出索引(下)极客时间 笔记体会: 回表:回到主键索引树搜索的过程,称为回表覆盖索引:某索引已经覆盖了查询需求,称为覆盖索引,例如:select ID fro ...
- mysql实战45讲 (三) 事务隔离:为什么你改了我还看不见 极客时间读书笔记
提到事务,你肯定不陌生,和数据库打交道的时候,我们总是会用到事务.最经典的例子就是转账,你要给朋友小王转100块钱,而此时你的银行卡只有100块钱. 转账过程具体到程序里会有一系列的操作,比如查询余额 ...
随机推荐
- ADOConnection断线重连
问题: ADOConnection断线重连问题描述: 使用ADOConnection连接oracle数据库,开始正常,当网络断开时数据库连接失败(此时查询ADOConnection.connected ...
- 从0开始的Python学习010return语句&DocStrings
return语句 return语句用来从一个函数中 返回 即跳出函数.当然也可以从函数中返回一个值. #return 语句从一个函数返回 即跳出函数.我们也可选从函数返回一个值 def maximum ...
- 程序员利器Tmux使用手册
转:https://blog.csdn.net/chenqiuge1984/article/details/80132042
- c/c++ 继承与多态 友元与继承
问题1:类B是类A的友元类,类C是类B的友元类,那么类C是类A的友元类吗?函数fun是类B的友元函数,那么fun是类A的友元函数吗? 都不是,友元关系不能传递. 问题2:类B是类A的友元类,类C是类B ...
- iOS开发之Swift 4 JSON 解析指南
Apple 终于在 Swift 4 的 Foundation 的模块中添加了对 JSON 解析的原生支持. 虽然已经有很多第三方类库实现了 JSON 解析,但是能够看到这样一个功能强大.易于使用的官方 ...
- 含有package关键字的java文件在命令行运行报错
程序中含有package关键字,使用命令行运行程序时出现"找不到或无法加载主类",而使用Eclipse软件可以正常运行程序的可能解决办法. 在包下的类,在Java源文件的地方编译后 ...
- ZooKeeper学习总结 第一篇:ZooKeeper快速入门
1. 概述 Zookeeper是Hadoop的一个子项目,它是分布式系统中的协调系统,可提供的服务主要有:配置服务.名字服务.分布式同步.组服务等. 它有如下的一些特点: 简单 Zookeeper的核 ...
- 【转】Android OkHttp3简介和使用详解
一 OKHttp简介 OKHttp是一个处理网络请求的开源项目,Android 当前最火热网络框架,由移动支付Square公司贡献,用于替代HttpUrlConnection和Apache HttpC ...
- 好程序员分享ApacheSpark常见的三大误解
误解一:Spark是一种内存技术 大家对Spark最大的误解就是其是一种内存技术(in-memorytechnology).其实不是这样的!没有一个Spark开发者正式说明这个,这是对Spark计算过 ...
- ESP8266远程OTA升级
https://blog.csdn.net/xh870189248/article/details/80095139 https://www.wandianshenme.com/play/arduin ...