Browser Page Parsing Details
Browser Work:
1、输入网址。
2、浏览器查找域名的IP地址。
3. 浏览器给web服务器发送一个HTTP请求
4. 网站服务的永久重定向响应
5. 浏览器跟踪重定向地址 现在,浏览器知道了要访问的正确地址,所以它会发送另一个获取请求。
6. 服务器“处理”请求,服务器接收到获取请求,然后处理并返回一个响应。
7. 服务器发回一个HTML响应
8. 浏览器开始显示HTML
9. 浏览器发送请求,以获取嵌入在HTML中的对象。在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。这些文件就包括CSS/JS/图片等资源,这些资源的地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等…
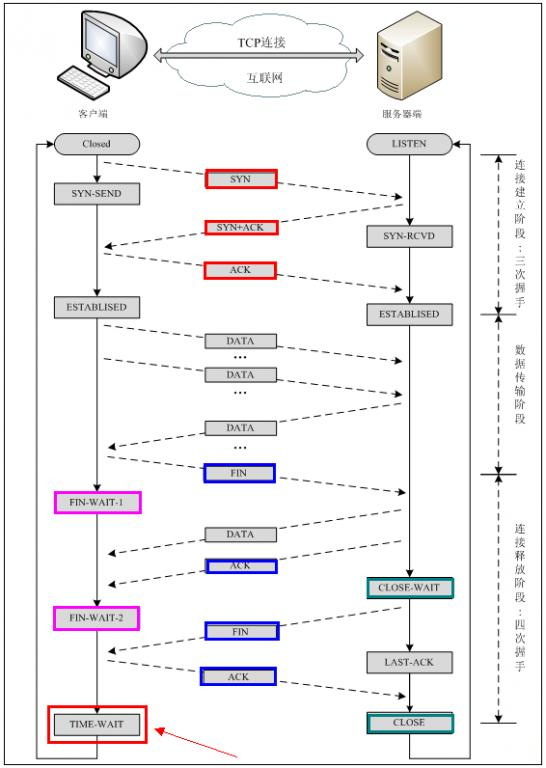
1. High level structure
Browser main components
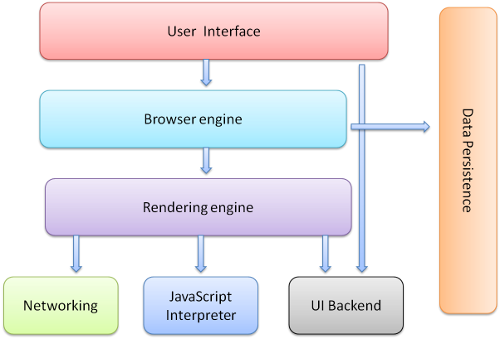
- The user interface - this includes the address bar, back/forward button, bookmarking menu etc. Every part of the browser display except the main window where you see the requested page.
- The browser engine - the interface for querying and manipulating the rendering engine.
- The rendering engine - responsible for displaying the requested content. For example if the requested content is HTML, it is responsible for parsing the HTML and CSS and displaying the parsed content on the screen.
- Networking - used for network calls, like HTTP requests. It has platform independent interface and underneath implementations for each platform.
- UI backend - used for drawing basic widgets like combo boxes and windows. It exposes a generic interface that is not platform specific. Underneath it uses the operating system user interface methods.
- JavaScript interpreter. Used to parse and execute the JavaScript code.
- Data storage. This is a persistence layer. The browser needs to save all sorts of data on the hard disk, for examples, cookies. The new HTML specification (HTML5) defines 'web database' which is a complete (although light) database in the browser.
2. Render Engine
2.1 main flow

2.2 webkit render flow
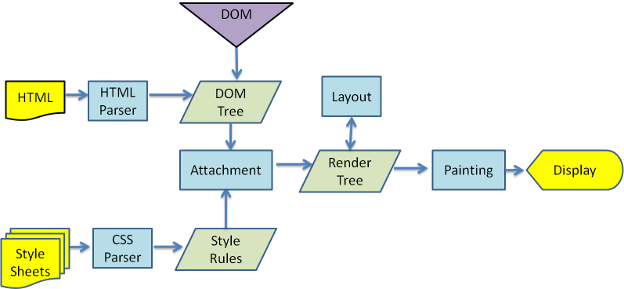
2.3 Gecko render flow
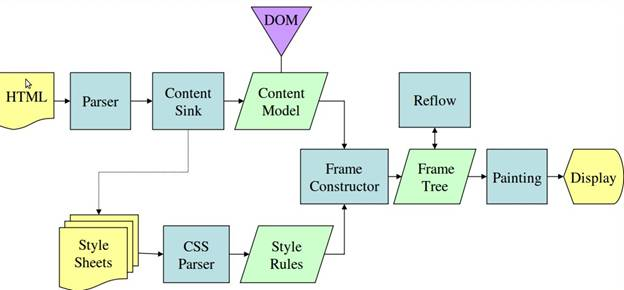
3. Parsing
Like complier, render engine parsing also have below steps:
3.1 Grammars
3.2 Lexer combination
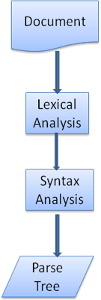
3.3 Translation
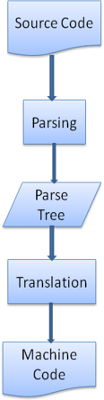
3.4 Generating parsers automatically
There are tools that can generate a parser for you. They are called parser generators. You feed them with the grammar of your language - its vocabulary and syntax rules and they generate a working parser. Creating a parser requires a deep understanding of parsing and its not easy to create an optimized parser by hand, so parser generators can be very useful.
Webkit uses two well known parser generators - Flex for creating a lexer and Bison for creating a parser (you might run into them with the names Lex and Yacc). Flex input is a file containing regular expression definitions of the tokens. Bison's input is the language syntax rules in BNF format.
4. HTML Parser
4.1 The HTML grammar definition
W3C - HTML4 & HTML5
4.2 HTML DTD(Document Type Definition)
The current strict DTD is here:http://www.w3.org/TR/html4/strict.dtd
4.3 DOM
The DOM has an almost one to one relation to the markup. Example, this markup:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Would be translated to the following DOM tree:
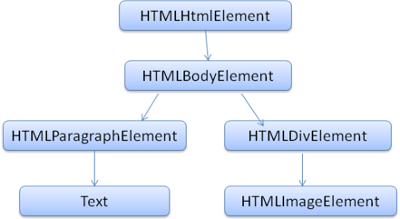
4.4 The parsing algorithm
HTML cannot be parsed using the regular top down or bottom up parsers.
The algorithm consists of two stages - tokenization and tree construction:
HTML parsing flow (taken from HTML5 spec):
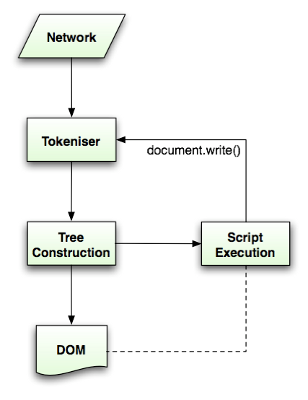
4.5 The tokenization algorithm
The algorithm's output is an HTML token. The algorithm is expressed as a state machine. Each state consumes one or more characters of the input stream and updates the next state according to those characters. The decision is influenced by the current tokenization state and by the tree construction state. This means the same consumed character will yield different results for the correct next state, depending on the current state. The algorithm is too complex to bring fully, so let's see a simple example that will help us understand the principal.
Basic example - tokenizing the following HTML:
<html>
<body>
Hello world
</body>
</html>
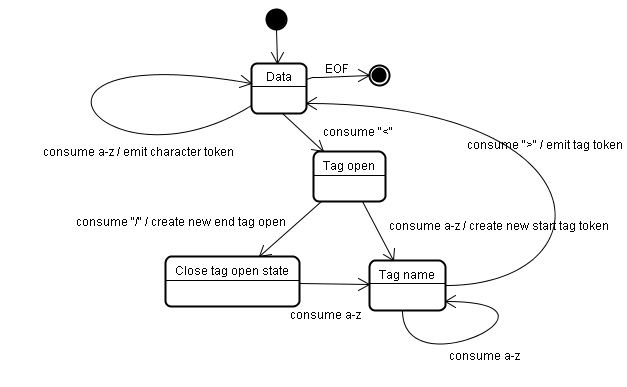
The initial state is the "Data state". When the "<" character is encountered, the state is changed to "Tag open state". Consuming an "a-z" character causes creation of a "Start tag token", the state is change to "Tag name state". We stay in this state until the ">" character is consumed. Each character is appended to the new token name. In our case the created token is an "html" token.
When the ">" tag is reached, the current token is emitted and the state changes back to the "Data state". The "<body>" tag will be treated by the same steps. So far the "html" and "body" tags were emitted. We are now back at the "Data state". Consuming the "H" character of "Hello world" will cause creation and emitting of a character token, this goes on until the "<" of "</body>" is reached. We will emit a character token for each character of "Hello world".
We are now back at the "Tag open state". Consuming the next input "/" will cause creation of an "end tag token" and a move to the "Tag name state". Again we stay in this state until we reach ">".Then the new tag token will be emitted and we go back to the "Data state". The "</html>" input will be treated like the previous case.
4.6 Tree construction algorithm
When the parser is created the Document object is created. During the tree construction stage the DOM tree with the Document in its root will be modified and elements will be added to it. Each node emitted by the tokenizer will be processed by the tree constructor. For each token the specification defines which DOM element is relevant to it and will be created for this token. Except of adding the element to the DOM tree it is also added to a stack of open elements. This stack is used to correct nesting mismatches and unclosed tags. The algorithm is also described as a state machine. The states are called "insertion modes".
Let's see the tree construction process for the example input:
<html>
<body>
Hello world
</body>
</html>
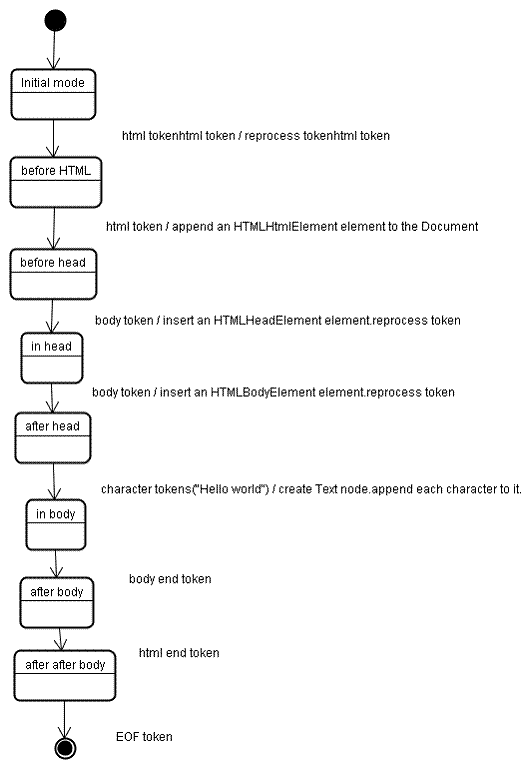
The input to the tree construction stage is a sequence of tokens from the tokenization stage The first mode is the "initial mode". Receiving the html token will cause a move to the "before html" mode and a reprocessing of the token in that mode. This will cause a creation of the HTMLHtmlElement element and it will be appended to the root Document object.
The state will be changed to "before head". We receive the "body" token. An HTMLHeadElement will be created implicitly although we don't have a "head" token and it will be added to the tree.
We now move to the "in head" mode and then to "after head". The body token is reprocessed, an HTMLBodyElement is created and inserted and the mode is transferred to "in body".
The character tokens of the "Hello world" string are now received. The first one will cause creation and insertion of a "Text" node and the other characters will be appended to that node.
The receiving of the body end token will cause a transfer to "after body" mode. We will now receive the html end tag which will move us to "after after body" mode. Receiving the end of file token will end the parsing.
4.7 Actions when the parsing is finished
At this stage the browser will mark the document as interactive and start parsing scripts that are in "deferred" mode - those who should be executed after the document is parsed.
The document state will be then set to "complete" and a "load" event will be fired.
4.8 Browsers error tolerance
The error handling is quite consistent in browsers but amazingly enough it's not part of HTML current specification. Like bookmarking and back/forward buttons it's just something that developed in browsers over the years. There are known invalid HTML constructs that repeat themselves in many sites and the browsers try to fix them in a conformant way with other browsers.
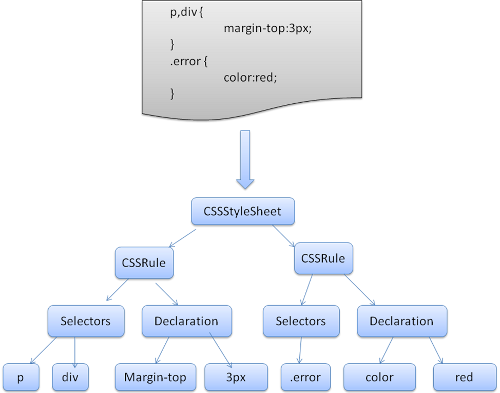
5. CSS parsing
CSS is a context free grammar and can be parsed using the types of parsers described in the introduction.
6. Parsing scripts
6.1 Scripts
The model of the web is synchronous. Authors expect scripts to be parsed and executed immediately when the parser reaches a <script> tag. The parsing of the document halts until the script was executed. If the script is external then the resource must be first fetched from the network - this is also done synchronously, the parsing halts until the resource is fetched. This was the model for many years and is also specified in HTML 4 and 5 specifications. Authors could mark the script as "defer" and thus it will not halt the document parsing and will execute after it is parsed. HTML5 adds an option to mark the script as asynchronous so it will be parsed and executed by a different thread.
6.2 Speculative parsing
Both Webkit and Firefox do this optimization. While executing scripts, another thread parses the rest of the document and finds out what other resources need to be loaded from the network and loads them. These way resources can be loaded on parallel connections and the overall speed is better. Note - the speculative parser doesn't modify the DOM tree and leaves that to the main parser, it only parses references to external resources like external scripts, style sheets and images.
6.3 Style sheets
Style sheets on the other hand have a different model. Conceptually it seems that since style sheets don't change the DOM tree, there is no reason to wait for them and stop the document parsing. There is an issue, though, of scripts asking for style information during the document parsing stage. If the style is not loaded and parsed yet, the script will get wrong answers and apparently this caused lots of problems. It seems to be an edge case but is quite common. Firefox blocks all scripts when there is a style sheet that is still being loaded and parsed. Webkit blocks scripts only when they try to access for certain style properties that may be effected by unloaded style sheets.
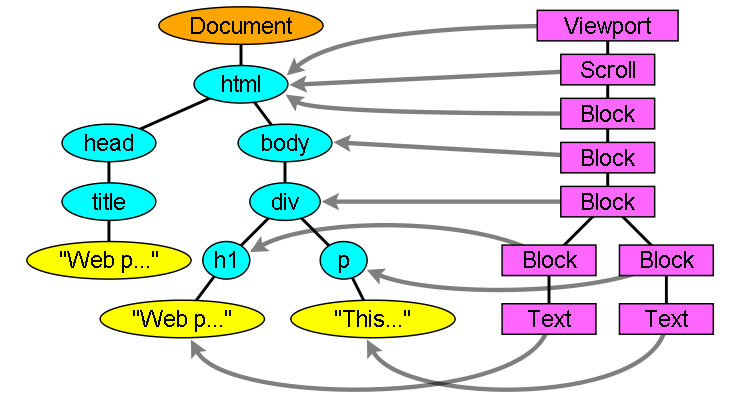
7. Render tree construction
While the DOM tree is being constructed, the browser constructs another tree, the render tree. This tree is of visual elements in the order in which they will be displayed. It is the visual representation of the document. The purpose of this tree is to enable painting the contents in their correct order.
7.1 The render tree relation to the DOM tree
Each renderer represents a rectangular area usually corresponding to the node's CSS box, as described by the CSS2 spec. It contains geometric information like width, height and position.
The render tree and the corresponding DOM tree:
7.2 Style Computation
- Sharing style data
- Manipulating the rules for an easy match
- Applying the rules in the correct cascade order
Style sheet cascade order
Specifity
Sorting the rules
8. Layout
Dirty bit system
In order not to do a full layout for every small change, browser use a "dirty bit" system. A renderer that is changed or added marks itself and its children as "dirty" - needing layout.
There are two flags - "dirty" and "children are dirty". Children are dirty means that although the renderer itself may be ok, it has at least one child that needs a layout.
Global and incremental layout
Asynchronous and Synchronous layout
Optimizations
The layout process
Width calculation
Line Breaking
9. Painting
- Global and Incremental
- The painting order
- background color
- background image
- border
- children
- outline
10. Dynamic changes
The browsers try to do the minimal possible actions in response to a change. So changes to an elements color will cause only repaint of the element. Changes to the element position will cause layout and repaint of the element, its children and possibly siblings. Adding a DOM node will cause layout and repaint of the node. Major changes, like increasing font size of the "html" element, will cause invalidation of caches, relyout and repaint of the entire tree.
11. The rendering engine's threads
The rendering engine is single threaded. Almost everything, except network operations, happens in a single thread. In Firefox and safari this is the main thread of the browser. In chrome it's the tab process main thread.
Network operations can be performed by several parallel threads. The number of parallel connections is limited (usually 2 - 6 connections. Firefox 3, for example, uses 6).
Refers:
http://taligarsiel.com/Projects/howbrowserswork1.htm
https://www.w3.org/TR/html5/syntax.html#html-parser
http://blog.csdn.net/dangnian/article/details/50876241
Browser Page Parsing Details的更多相关文章
- Personalize Oracle Applications Home Page Browser Window Title
修改登录页 http://expertoracle.com/2016/03/10/personalizing-the-e-business-suite-r12-login-page/ STEP 2 : ...
- 使用Puppeteer进行数据抓取(二)——Page对象
page对象是puppeteer最常用的对象,它可以认为是chrome的一个tab页,主要的页面操作都是通过它进行的.Google的官方文档详细介绍了page对象的使用,这里我只是简单的小结一下. 客 ...
- 12.1.2: How to Modify and Enable The Configurable Home Page Delivered Via 12.1.2 (Doc ID 1061482.1)
In this Document Goal Solution References APPLIES TO: Oracle Applications Framework - Ver ...
- 正向渲染路径细节 Forward Rendering Path Details
http://www.ceeger.com/Components/RenderTech-ForwardRendering.html This page describes details of For ...
- Java性能提示(全)
http://www.onjava.com/pub/a/onjava/2001/05/30/optimization.htmlComparing the performance of LinkedLi ...
- HTTP Server to Client Communication
1. Client browser short polling The most simple solution, client use Ajax to sends a request to the ...
- C++开源库集合
| Main | Site Index | Download | mimetic A free/GPL C++ MIME Library mimetic is a free/GPL Email lib ...
- webpack——Modules && Hot Module Replacement
blog:JavaScript Module Systems Showdown: CommonJS vs AMD vs ES2015 官网链接: Modules 官网链接:Hot Module Rep ...
- Solr Cloud - SolrCloud
关于 Solr Cloud Zookeeper 入门,介绍 原理 原封不动转自 http://wiki.apache.org/solr/SolrCloud/ ,文章的内存有些过时,但是了解原理. Th ...
随机推荐
- linux centos7下源码 tar安装mysql5.7.23(5.7以上均可试用)
1.工具:mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz.centos7 2.解压后,将mysql-5.7.22-linux-glibc2.12-x86_64里面 ...
- 实践作业4 Web测试(软件评测)
经过我们小组的讨论之后,我们选择的待检测产品为产品三:学校相关网站. 我们测的是华中科技大学软件学院官方网站和华中科技大学计算机学院官方网站. 我们比较的有: 一.功能缺陷一:网页显示信息不全 英文网 ...
- dos脚本1章
第一节 常用批处理内部命令简介 批处理定义:顾名思义,批处理文件是将一系列命令按一定的顺序集合为一个可执行的文本文件,其扩展名为BAT或者CMD.这些命令统称批处理命令.小知识:可以在键盘上按下Ctr ...
- 常用oracle可重复执行的脚本模板
为保证脚本的可重复执行以及丢失,涉及到数据库环境的移植等,就会使用可重复执行脚本,此处仅提供相关一些模板 说明下:该脚本需要在命令窗口执行,而不是在SQL窗口执行 创建序的脚本 /** * 作者:zk ...
- python 视频爬虫
打开网址:http://mv.688ing.com/ 输入视频播放地址 发现很多链接以.ts结尾. # import requests import os def download(): header ...
- 解决虚拟机centos7 无法无法上网问题
centos无法上网问题 虚拟机设置 网段设置 网关设置 查看本地电脑设置 登录服务器设置 /etc/sysconfig/network-scripts/ 下面的 ifcfg-ens33 文件操 ...
- mybatis 源码分析一
1.SqlSessionFactoryBuilder public SqlSessionFactory build(InputStream inputStream, String environme ...
- 2018上C语言程序设计(高级)- 第2次作业成绩
作业地址 评分准则 第一次作业各项成绩包括三项: 完成PTA所有题目:9分 总结和附加题目:15分 博客记录:70分 博客记录包含三次PTA,共8道题,有正确流程图题目12分,没有的8分: 设计思路2 ...
- ppt图片在word中不能正常显示,只显示为矩形框的解决方法
word中插入的其他图片是好的,但是从ppt复制粘贴过来的图片只显示个框. 解决方法:以下红框中内容去选中.
- Debug程序的使用
一.什么是Debug程序: Debug是DOS, Windows(但是Win7 64位没有,8 10不清楚.)都提供的实模式程序的调试工具, 使用它,可以查看CPU各种寄存器中的内容,内存的情况和在机 ...