Mybatis从认识到了解
首发日期:2018-10-31
MyBatis的介绍
介绍:
- MyBatis是Apache旗下的开源项目,是一个持久层框架
- 与Hibernate的全自动ORM框架可以仅仅依靠映射关系进行SQL查询不同,MyBatis是一个基于SQL语句的半自动ORM框架,它需要我们手动去定义SQL语句。
为什么选择MyBatis:
与JDBC的对比中,MyBatis是基于ORM的,天然要比JDBC强,基于ORM使得MyBatis具有查询的数据可以自动封装到对象中的等好处,而JDBC需要手动编码的位置就较多了(就算是使用DButils,你也需要使用定义不同的方法来给不同的持久类赋值。)。
在互联网应用程序开发中,对于存储过程和复杂的SQL,Hibernate并没有很好地去处理,所以它比较难提升性能(并不是说不能,而是耗费心思较多),无法满足高并发和高响应的需求(如果要强行优化,又破坏了Hibernate的全自动ORM设计)。
与之对应的,Mybatis可以说是基于SQL的,它需要我们去自定义SQL,那么我们可以根据需要去设计和优化SQL,这种可针对SQL的优化的持久层框架,恰巧符合高并发和高响应的互联网应用程序开发开发需求。
与Hibernate的对比:
- ORM区别:
- Hibernate是完全面向POJO的,它基本不需要编写SQL,可以直接通过映射关系来操作数据。
- 而MyBatis需要我们自定义SQL语句。
- 面向的需求:
- 对于一些不需要太高性能的,可以使用Hibernate去开发。【ERP,CRM,OA之类的】
- 对于有性能要求的,通常需要使用MyBatis。
MyBatis的优点:
- 支持存储过程
- 由于是自定义SQL,方便进行SQL优化
- 可以简化开发,对比JDBC开发,省去了很多代码;
- 基于Mapper发送SQL的方式使得DAO层仅需要定义接口,而不需要DAO实现类了。
入门示例
1.首先要下载依赖包https://github.com/mybatis/mybatis-3/releases
- 文件\文件夹详情:
- lib:包含MyBatis依赖包,MyBatis的功能需要这些依赖包。
- mybatis-3.4.5.jar:mybatis的核心包。
- mybatis-3.4.5.pdf:mybatis的官方文档。
2.创建普通javase工程,导入依赖包(我这里使用mybatis-3.4.5 ):
- 导入MyBatis核心包:mybatis-3.4.5.jar
- 导入数据库驱动包:mysql-connector-java-5.1.7-bin.jar
- 导入MyBatis依赖包:

3.创建持久类和创建数据表:持久类是用于封装从数据库中返回的结果,可以说持久类的对象就是数据库记录在java中的实体(这里约定数据表的列名与持久类的属性名一致)。
- 持久类
package work.pojo;
public class User {
private Integer id;
private String name;
private Integer age;
//省略setter,getter,toString
}
- 数据表:
create table user(
id int primary key auto_increment,
name varchar(20),
age int
);
4.在持久类User.java同级目录下创建映射文件user.xml:这个映射文件的意义是用来定义sql语句,使得我们可以在代码中调用sql语句【不同类的标签定义不同类的SQL,id用于标识SQL语句,parameterType是传入SQL语句的参数,resultType定义了返回结果的类型(这里由于表字段和类属性名一致,查询的记录的各个值会自动赋给对象)】
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="user">
<!--id用于标识SQL,parameterType是传给SQL的参数的类型,resultType是返回结果的类型 -->
<select id="getUserById" parameterType="int" resultType="work.pojo.User" >
<!-- 使用#{}来传入参数 -->
SELECT * FROM USER WHERE id = #{id}
</select>
</mapper>
5.配置mybatis配置文件,这里命名为mybatis-config.xml。配置文件的意义是配置MyBatis的运行设置,MyBatis是针对持久层的框架,所以它必须要有数据库连接的配置。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<!-- environment用来定义数据库连接环境,environments用来定义多个environment -->
<environment id="development">
<!-- transactionManager配置事务管理,使用jdbc事务管理 -->
<transactionManager type="JDBC" />
<!-- dataSource配置数据库连接池 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/mybatis" />
<property name="username" value="root" />
<property name="password" value="123456" />
</dataSource>
</environment>
</environments>
<mappers>
<!-- 导入映射文件,这样MyBatis才能管理到SQL语句 -->
<mapper resource="work/pojo/user.xml"/>
</mappers>
</configuration>
6.编写测试方法:
配置文件配完后,要想通过mybatis操作数据库,那么就需要使用SqlSessionFactoryBuilder、SqlSessionFactory和SqlSession几个对象。
- SqlSessionFactoryBuilder:用来读取配置文件,得到一个SqlSessionFactory
- SqlSessionFactory:SqlSessionFactory相当于连接池工厂,可以获得一个SqlSession对象
- SqlSession:相当于JDBC的Connection对象,可以调用方法来操作数据表
@Test
public void test1() throws IOException {
// 创建SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder sfb = new SqlSessionFactoryBuilder();
// 通过Mybatis包的Resources类来将配置文件转成输入流
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 加载配置文件输入流,创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = sfb.build(inputStream);
// sqlSessionFactory创建SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
// 执行查询,第一个参数是映射文件中定义的SQL的id名,第二个参数是传给SQL的参数。
User user = sqlSession.selectOne("getUserById", 1);
// 输出查询结果
System.out.println(user);
// 释放资源
sqlSession.close();
}
这里给一下文件结构、数据表数据和测试结果。
文件结构:
数据表数据:

测试结果:User [id=1, name=沙僧, age=18]
上面演示了MyBatis的使用,相信你对MyBatis已经有了一个初步的了解,下面将对各个部分的知识进行讲解。
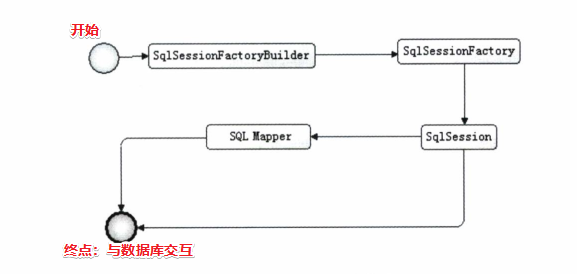
1.核心组件【关于SqlSessionFactoryBuilder这些对象,以及了解Mybatis的运行流程】
2.mybatis配置文件的配置【关于数据库连接之类的配置】
3.映射文件的配置【关于SQL语句的定义方式】
Mybatis核心组件
四大核心组件
- SqlSessionFactoryBuilder:负责根据配置文件来生成SqlSessionFactory
- SqlSessionFactory:一个用来生成SqlSession的工厂(这个工厂由SqlSessionFactoryBuilder生成)
- SqlSession:SqlSession是会话的意思,即与数据库的会话,相当于JDBC中的Connection。它是一个既可以既可以发送SQL去执行并返回结果,也可以获取Mapper的接口。
- SQL Mapper:它是Mybatis新设计的组件,它由一个Java接口和一个配置文件(XML式或注解式的)组成,它可以获取配置文件中的SQL语句和映射关系,它也可以发生SQL去执行并返回结果。
SqlSessionFactoryBuilder
- SqlSessionFactoryBuilder是一个基于建造者设计模式的接口,它可以根据配置去生成SqlSessionFactory
- SqlSessionFactoryBuilder生成SqlSessionFactory依靠build方法,build可以传入多种参数(下面是其中三种方式),常见情况是传入一个配置文件的字节输入流对象。
- build(InputStream inputStream)【传入一个配置文件的字节输入流对象】
- build(Reader reader)【传入一个配置文件的字符输入流对象】
- build(Reader reader, String environment)【传入一个配置文件的字符输入流对象,并根据指定的environment生成工厂,默认是使用environments中的默认值】
- build(Configuration config)【传入一个Configuration 对象,这里不讲它怎么配置】
以传入一个配置文件的字节输入流对象为例,MyBatis提供了一个Resource类,它可以很方便地将配置文件转成输入流:
// 创建SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder sfb = new SqlSessionFactoryBuilder();
// 通过Resources类来将配置文件转成输入流,Resources是mybatis提供的
InputStream inputStream=Resources.getResourceAsStream("mybatis-config.xml");
// 加载配置文件输入流,创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = sfb.build(inputStream);
SqlSessionFactory
- SqlSessionFactory是SqlSessionFactoryBuilder读取了配置文件之后生成的对象,它解析了配置文件的信息(mybatis的数据库连接信息、缓存信息、事务管理等等)。
- SqlSessionFactory可以调用openSession方法来获取一个SqlSession,openSession方法是可以传入参数的,如果你传入一个布尔值那么将影响事务管理,为true时将自动提交,为false将默认不提交,默认为false,这时候需要你手动提交:
sqlSession.commit();。 - openSession除了可以传入布尔值,还可以传入其他类型的对象,这里不讲。
// sqlSessionFactory创建SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//开启自动提交,默认增、删、改是不自动提交的
//SqlSession sqlSession = sqlSessionFactory.openSession(true);
SqlSession
SqlSession的作用类似于JDBC中的Connection对象。
作用:
- 管理事务:SqlSession可以调用commit和rollback方法【要注意,MyBatis使用JDBC作为事务管理器时,事务是默认不自动提交的】
- 提交SQL:SqlSession内置了selectOne、insert、update、delete等超过20种操作数据库的方法。
- 调用的方法里面通常的第一个参数都是字符串,这个字符串是映射文件中的SQL语句的id,本质上是调用映射文件中的SQL语句。
- 释放资源:SqlSession可以调用close方法来关闭连接资源。
使用示例:
SqlSession sqlSession = sqlSessionFactory.openSession();
User user = new User();
user.setName("铁头娃");
user.setAge(4);
//发送sql
sqlSession.insert("insertUser", user);
//提交事务
sqlSession.commit();
// 释放资源
sqlSession.close();
SQL Mapper
SQL Mapper是mybatis新设计的一个组件,也是一种新的执行SQL的模式,在ibatis时代,主要使用sqlSession来进行查询,而有了SQL Mapper之后,只要遵循一种开发规范,那么就可以利用一个接口和一份映射文件
如果这个接口遵循了Mapper的开发规范,并且有对应的映射文件,那么sqlSession调用getMapper方法可以获取一个mapper对象,mapper对象可以直接调用接口方法来执行映射文件中对应的SQL语句。
sqlSession.getMapper(某个接口.class);
Mapper的规范
- 映射文件的namespace是接口的全限定名
- 接口的方法名通常与映射文件的SQL id同名【使得Mapper的方法与SQL对应起来,这样调用方法就是调用对应的SQL】【还有各种各样的要求,由于这涉及两种开发方式,所以这将在后面讲】
- 映射文件就是配置SQL语句的文件
功能:
Mapper也可以发送SQL,调用Mapper接口中的方法就相当于sqlSession调用映射文件中的SQL。【这样的调用是完全面向对象的,现在普遍用这种。】
SqlSession sqlSession = sqlSessionFactory.openSession();
//发送sql
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUserById(1);
//User user = sqlSession.selectOne("getUserById", 1); //原方式
System.out.println(user);
// 释放资源
sqlSession.close();
核心组件的生命周期
- SqlSessionFactoryBuilder的主要作用是创建SqlSessionFactory,一旦创建了 SqlSessionFactory 后,这个类就不需要存在了。通常只让它处在局部环境(本地方法变量)中。
- SqlSessionFactory用于创建Session接口对象,所以SqlSessionFactory应该是长期有效的,但不应该重复创建,所以通常使用单例模式或静态单例模式来获取SqlSessionFactory对象。
- SqlSession相当于一个连接对象,每次获取它,都是用来处理业务的,所以每个业务(线程)都应该有一个SqlSession对象,而它通常应该在业务结束后归还给SqlSessionFactory,SqlSession的范围为一个业务的请求范围。
- Mapper是绑定了SQL的接口,在使用Mapper来操作的时候,很明显的--Mapper的生命周期与SqlSession有关。Mapper的生命周期最大可以与SqlSession等同,但如果把Mapper放到try-catch这样的语句或方法中,那么它的生命周期就会变小了。
总结
稍微了解了一下核心组件之后,再回头看一下之前的代码:
@Test
public void test1() throws IOException {
// 创建SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder sfb = new SqlSessionFactoryBuilder();
// 通过Mybatis包的Resources类来将配置文件转成输入流
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 加载配置文件输入流,创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = sfb.build(inputStream);
// sqlSessionFactory创建SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
// 执行查询,第一个参数是映射文件中定义的SQL的id名,第二个参数是传给SQL的参数。
User user = sqlSession.selectOne("getUserById", 1);
// 输出查询结果
System.out.println(user);
// 释放资源
sqlSession.close();
}
映射文件的配置
我们现在先来了解一些映射文件的配置,也就是映射文件里面所谓的SQL语句之类的怎么写。这里了解了映射文件怎么配置之后,你可以先使用sqlSession来执行SQL体验一下其中的意义的。
SqlSession sqlSession = sqlSessionFactory.openSession();
User user = new User();
user.setName("铁头娃");
user.setAge(4);
//发送sql
sqlSession.insert("insertUser", user);
//提交事务
sqlSession.commit();
// 释放资源
sqlSession.close();
dtd约束:
映射文件需要dtd约束,在依赖包没有包含dtd的配置方法,只能从官方文档中获取,这里给一下。
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
可配置标签:
基础结构,下面是一个大致的映射文件结构,在mapper标签下面配置其他标签:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="user">
<select id="getUserById" parameterType="int" resultType="work.pojo.User" >
SELECT * FROM USER WHERE id = #{id}
</select>
</mapper>
mapper标签:
- mapper标签中的属性namespace是命名空间的意思,它可以将定义的SQL语句区分到不同的命名空间上,就好像把类区分到不同的包中。命名空间可以解决SQL ID相同的问题,SQL ID唯一时,可以调用SQL ID来调用对应的SQL语句;不唯一时,应该使用
命名空间.SQL ID。 - mapper标签是映射文件的顶级标签,子标签有:
- select:用于定义查询语句,可以自定义入参类型和返回的结果集类型。
- insert:用于定义插入语句,可以自定义入参类型,返回结果是插入的记录数。
- update:用于定义更新语句,可以自定义入参类型,返回结果是更新的记录数。
- delete:用于定义删除语句,可以自定义入参类型,返回结果是删除的记录数。
- sql:用来封装一部分经常出现的SQL,这样可以在别的地方进行引用,避免了老是重复。
- resultMap:用来手动将数据库返回的结果与Java中的数据建立上关系,使用了resultMap的地方,会根据resultMap的规则来封装数据。
- cache:给命名空间配置缓存。【配置缓存可以影响CRUD语句是否保留缓存值】
- cache-ref:引用其他命名空间中的缓存配置。
select标签:
select标签用来定义查询类的SQL语句。
属性:
- id:与命名空间组合,用来唯一标识SQL语句。MyBatis可以根据id来调用对应的SQL语句。【要注意唯一性,唯一的时候,可以直接使用SQL ID;如果不是唯一,那么要使用
命名空间.SQL ID来调用对应的SQL语句。】 - parameterType:用来定义传给SQL语句的参数的数据类型。可以是各种数据类型,也可以是POJO类对象(要求是类的全限定名),也可以给出别名(别名是指数据类型的别名或类的全限定名的别名,由于Mybatis提前定义了一堆别名,所以我们直接使用int的时候,相当于使用了java.lang.Integer)。
- resultType:用来定义SQL语句返回结果的参数类型。可以是各种数据类型,也可以是POJO类(要求是类的全限定名),也可以给出别名(数据类型的别名或类的全限定名的别名)。【给出POJO类的时候,如果允许自动匹配,将自动根据映射关系自动将返回结果封装到对象中】。【resultType不能与resultMap一起用,他们的功能重复了】
- resultMap:resultMap标签用来定义返回结果与类的映射关系,在select中使用resultMap属性时,可以将返回结果根据映射关系来赋值。【后面将具体介绍】
- id:与命名空间组合,用来唯一标识SQL语句。MyBatis可以根据id来调用对应的SQL语句。【要注意唯一性,唯一的时候,可以直接使用SQL ID;如果不是唯一,那么要使用
示例:
<select id="getUserById" parameterType="int" resultType="user" >
SELECT * FROM USER WHERE id = #{id1}
</select>
使用问题:
- 传参问题:
- 可以使用
#{参数名}来向SQL语句传递参数。对于基本数据类型,由于仅有一个参数(不像集合或类包含多个变量),参数名是可以随意取的。
<select id="getUserById" parameterType="int" resultType="work.pojo.User" >
SELECT * FROM USER WHERE id = #{id1}
</select>
对于对象类型,由于对象中有属性,所以要使用
#{属性名}来把对象中的数据传递给SQL。如果对象的属性还是一个对象那么可以使用#{内含对象名.属性名}。<!-- 由于传参是一样的用法,这里用insert作为例子,User中有属性name和age -->
<insert id="insertUser" parameterType="work.pojo.User" >
INSERT INTO USER(name,age)
VALUES
(#{name},#{age});
</insert>
- 对于集合类的入参,这需要使用到动态SQL中的foreach标签,这个留到后面再讲。
- 可以使用
- 传参问题:
- 对于模糊查询,在传参的时候可能会有问题,你可能会思索
%这个东西在哪里存:- 方式一:在函数调用方法并传参给SQL的时候,手动拼接;然后在SQL正常的使用
#{参数名}来获取参数。- 代码中进行拼接:
sqlSession.selectList("user.getUserByName","%唐%");,SQL中使用#{参数名}:SELECT * FROM USER WHERE name LIKE #{name};
- 代码中进行拼接:
- 方式二:
${参数名}可以用来字符串拼接,它可以在将字符串包裹的${参数名}转成对应的数据,但对于非POJO类型的参数名只能为value,对于POJO类型的就只能使用POJO类型的属性了。SELECT * FROM USER WHERE name LIKE '%${value}%';
- 方式三:调用SQL内置函数concat来拼接。【这个要注意数据库有没有这个函数】
SELECT * FROM USER WHERE name LIKE CONCAT('%',#{name},'%')
- 方式一:在函数调用方法并传参给SQL的时候,手动拼接;然后在SQL正常的使用
- 返回结果问题:
- 可以使用resultType和resultMap来定义返回结果,由于resultMap属性借助resultMap标签,resultMap留到resultMap标签再讲
- resultType的值可以是各种数据类型,不过要符合数据的封装要求,比如返回多列数据时resultType不应该设置成int,resultType的值是什么要你自己去判断,只要你符合封装规则,那么就能封装成功。比如
SELECT * FROM USER WHERE id = #{id}的返回值应该是一个User类。 - 返回结果是多条记录的时候,返回结果类型也可以是POJO类,MyBatis会自动将返回结果转成POJO类的数组。
- 映射规则问题:
如果传入一个POJO类,默认是自动映射的,【如果属性名不一致,可以使用字段别名或者resultMap来进行强制映射】
假设数据表中的字符名为username,但对象中的属性名为name,那么怎么对应上呢?
<!-- SELECT id,username ,age FROM USER WHERE id = #{id} --><!--由于字符名与属性名不完全相同,自动映射失败-->
<!-- 使用下面的语句,利用别名 -->
SELECT id,username as name ,age FROM USER WHERE id = #{id}
使用resultMap,显式对应:property是类对象的属性名,column是字段名
<resultMap type="work.pojo.User" id="userMap">
<id property="id" column="id" />
<!-- 手动把字段名与属性对应上 -->
<result property="name" column="username" />
<result property="age" column="age"/>
</resultMap>
多表时必须使用resultMap。因为没有自动跨表映射(除非你定义了返回结果是一个包含了多个表所有字段的类)。
resultMap
resultMap用来显式定义数据封装规则,resultMap把数据表的数据与对象的属性一一对应起来,如果SQL语句的返回结果类型使用了resultMap,这样MyBatis就会根据resultMap中的规则来封装返回的数据。
属性
- id:resultMap的id,有了id,就可以在其他标签的resultMap属性中引用了。
- type:要建立映射关系的POJO类的全限定名。
id标签:用来定义主键的映射关系
- property:对象的属性名,代表映射到对象的哪个属性中。
- column:代表数据表中的列名。
result标签:用来定义普通字段的映射关系。
<!-- 定义resultMap -->
<resultMap type="work.pojo.User" id="userMap">
<!--id标签把数据表中的id字段与User类中的id属性对应起来 -->
<id property="id" column="id" />
<result property="name" column="name" />
<result property="age" column="age"/>
</resultMap>
<!-- 引用resultMap -->
<select id="getUserById" parameterType="int" resultMap="userMap">
SELECT * FROM USER WHERE id = #{id1}
</select>
resultMap还与关联查询有关系,关联查询依靠resultMap来定义映射关系。这留到后面讲。
insert标签:
insert用来定义插入语句
属性:
- parameterType:定义传入的参数类型,使用可以参考select中的parameterType。
- useGeneratedKeys:获取插入记录的主键(数据库自动生成的)
- keyProperty:用来标识主键返回结果赋给哪个变量,复合主键时,使用逗号分隔变量名。【keyColumn】
使用说明:增删改三种语句默认是不提交,要commit
<insert id="insertUser" parameterType="work.pojo.User" >
INSERT INTO USER(name,age)
VALUES
(#{name},#{age});
</insert>
主键返回问题,有时候我们希望插入了一条记录后,获取到它的ID来处理其他业务,那么这时候我们怎么获取它的主键呢?下面列举两种方法:
JDBC式:在insert标签上配置useGeneratedKeys和keyProperty属性,useGeneratedKeys用来表明这个数据库是不是自增长id的,所以这个获取主键的方式不适用与Oracle。keyProperty用来指明返回的主键值存储到哪个属性中。
<insert id="save" parameterType="work.domain.User" useGeneratedKeys="true" keyProperty="userId" >
insert into user(userName,password,comment)
values(#{userName},#{password},#{comment})
</insert>
数据库式:利用数据库的函数来获取主键,keyProperty用来指明返回的主键值存储到哪个属性中。order用来指定执行的顺序,究竟是插入前获取--BEFORE,还是插入后获取--AFTER。resultType用来指明返回主键的数据类型。
<insert id="save" parameterType="work.domain.User" >
<selectKey resultType="java.lang.Long" order="AFTER" keyProperty="userId">
SELECT LAST_INSERT_ID()
</selectKey>
insert into user(userName,password) values(#{userName},#{password})
</insert>
update标签:
属性与insert差不多
MyBatis由于是根据SQL去修改,所以它不会发生覆盖修改问题(Hibernate基于对象来查询,对于没有设置值的属性也会修改到数据表中,所以Hibernate中通常都是先查询后修改)
<update id="updateUser" parameterType="com.pojo.User">
UPDATE USER SET username = #{username} WHERE id = #{id}
</update>
delete标签:
属性与insert差不多
<delete id="deleteUser" parameterType="int">
DELETE FROM user WHERE `id` = #{id1}
</delete>
sql标签:
- sql标签可以用来定义一部分SQL语句,定义的部分SQL语句可以在别的地方引用。比如我们经常会用到列名,我们需要反复填写列名,如果我们将这一部分列名定义到sql标签中,我们就可以通过引用来使用了。
<sql id="userCols">
id,name,age
</sql>
<!-- 开始引用 -->
<select id="getUserById" parameterType="int" resultType="work.pojo.User">
<!-- SELECT id,name,age FROM USER WHERE id = #{id1} -->
SELECT <include refid="userCols"></include> FROM USER WHERE id = #{id1}
</select>
补充:
- 由于cache和cache-ref涉及缓存问题,这将留到后面缓存部分再讲。
SQL发送
上面学过了映射文件里面定义SQL,那么下面来了解一下怎么使用这些SQL语句。发送SQL的方式有两种,一种是使用SqlSession来发送,一种是使用Mapper来发送。
使用SqlSession发送:
1.创建映射文件,这里假设为user.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="user">
<select id="getUserById" parameterType="int" resultType="user" >
SELECT id,name,age FROM USER WHERE id = #{id}
</select>
</mapper>
2.在配置文件中引入映射文件:【由于没有怎么讲mybatis配置文件,你可以先按照基础示例里面来修改】
<mappers>
<!-- 导入映射文件 -->
<mapper resource="work/pojo/user.xml"/>
</mappers>
3.获取SqlSession,并使用SqlSession调用对应的SQL:
@Test
public void test3() throws IOException {
SqlSessionFactoryBuilder sfb=new SqlSessionFactoryBuilder();
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sessionFactory = sfb.build(inputStream);
SqlSession sqlSession = sessionFactory.openSession();
//根据SQL ID来发送SQL,第二个是传给SQL的参数。
User user = sqlSession.selectOne("user.getUserById",3);
System.out.println(user);
sqlSession.close();
}
常用方法
- selectOne("sql id")方法表示调用的是查询语句,并且返回的是一个对象【如果返回结果是多个,会报错。】
- selectList("sql id")方法表示调用的是查询语句,并且返回的是一个列表。
- insert("sql id")方法表示调用的是插入语句,对应映射文件中使用insert标签定义的SQL语句。
- delete("sql id")方法表示调用的是删除语句,对应映射文件中使用delete标签定义的SQL语句。
- update("sql id")方法表示调用的是修改语句,对应映射文件中使用update标签定义的SQL语句。
使用Mapper接口发送:动态代理开发
1.首先创建一个接口,
- 接口名通常都是XXXMapper,如果是针对User类,可以是UserMapper
- 接口名要求与映射文件名一致
- 接口的方法名要求与映射文件的SQL id一致,
- 接口的方法的形参必须要与对应SQL的parameterType类型一致,
- 接口的返回类型必须与对应的SQL的resultType类型一致。
package work.pojo;
public interface UserMapper {
public User getUserById(int id);
}
2.创建映射文件(这里假设为UserMapper.xml),映射文件要求namespace必需是接口的全路径名:
<!-- namespace要写接口的全限定名 -->
<mapper namespace="work.pojo.UserMapper">
<!--注意返回类型和入参类型要与接口的一致 -->
<select id="getUserById" parameterType="int" resultType="work.pojo.User" >
SELECT id,name,age FROM USER WHERE id = #{id}
</select>
</mapper>
3.在配置文件中引入Mapper:
<mappers>
<!-- 导入映射文件 -->
<!--既可以导入接口,也可以导入映射文件 -->
<!--<mapper resource="work/pojo/UserMapper.xml"/> -->
<mapper class="work.pojo.UserMapper"/>
</mappers>
4.在代码中利用sqlSession获取接口的Mapper,并使用Mapper发送SQL(调用对应的接口方法就是发送对应SQL):【这里提一下,虽然获取的是接口,但由于遵循了开发规范,Mybatis会帮忙创建一个这个接口的实现类,所以实质返回的是一个实现类对象】
@Test
public void test4() throws IOException {
SqlSessionFactoryBuilder sfb=new SqlSessionFactoryBuilder();
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sessionFactory = sfb.build(inputStream);
SqlSession sqlSession = sessionFactory.openSession();
//根据接口.class来获取mapper
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//调用接口的方法就是调用方法对应的SQL。
User user = mapper.getUserById(3);
System.out.println(user);
sqlSession.close();
}
Mapper说明:
- 在
UserMapper mapper = sqlSession.getMapper(UserMapper.class);传入一个UserMapper.class就可以获取一个能够调用方法的mapper,我们仅仅定义了UserMapper接口,为什么能获取一个能够获取一个能够调用方法的mapper呢?因为mybatis底层自动帮我们去创建这个接口的实现类了,由于我们遵循了设计规范,mybatis能够很容易地了解该如何去创建实现类。创建完实现类后,返回一个实现类的对象。
两种方式对比与DAO层开发问题
MyBatis通常用于数据访问层DAO的开发,对于使用SqlSession发送SQL的方式来说,它跟以往的开发一样,也需要定义DAO接口和实现方法;但对于使用Mapper发送SQL的方式来说,它跟以往的开发不同,它只需要定义接口了,而不再需要接口实现类了。
SqlSession方式:

Mapper方式:由于UserMapper接口已经包含原来的UserDao的功能了,并且不需要自定义实现类,所以这里可以省去DAO层。
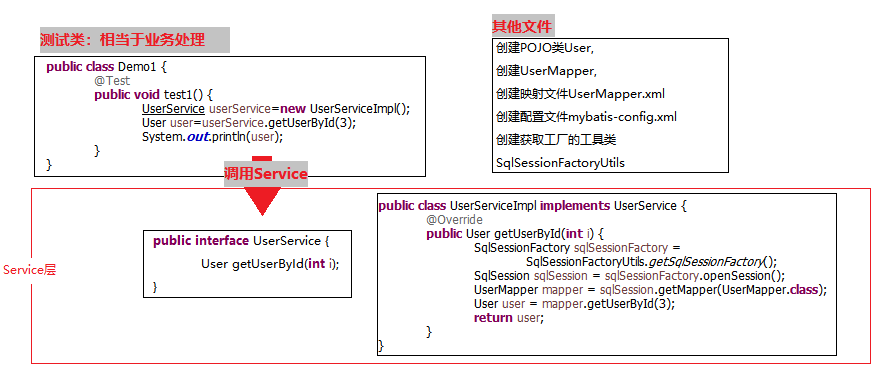
两种方式比较:
- 建议使用Mapper方式发送
- SqlSession发送是直接发送;Mapper方式是先通过SqlSession获取Mapper接口再发送。
- SqlSession方式是面向SQL的,Mapper方式是面向对象的。SqlSession发送SQL,需要一个SQL id 去匹配SQL。Mapper发送SQL只需要调用调用对应的方法,例如`mapper.getRole(1L)`。
- 使用Mapper方式发生SQL要调用对应的接口方法,接口方法能帮我们检查入参类型,参数类型不对时编译器会检错,而sqlsession.selectOne()只有在运行时才报错。
MyBatis配置文件
- 上面谈完了一些“定义SQL和发送SQL”方面的内容,这节主要是讲解MyBatis配置文件的内容,配置文件是用来配置Mybatis的运行环境的,例如数据库驱动、url、用户名、密码、采用的事务管理方式等。
- 配置文件的命名是可以随意的,通常可以命名为mybatis-config.xml
配置文件的约束
配置文件的dtd约束配置信息并没有写在jar包中,所以我们不能从依赖包中查到,只能依靠官方文档来获取,下载的包中的mybatis-3.4.5.pdf中就有,在 Getting started中可以复制dtd约束。
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
可配置标签:
标签的出现的顺序必须按照顺序。
<configuration><!-- configuration是配置文件的顶级标签 -->
<!-- properties用于配置一些参数,这些参数可以被引用到下面的其他配置中,相当于properties文件 -->
<properties></properties>
<!-- setting用于配置一些mybatis底层相关的属性,比如缓存 -->
<settings></settings>
<!--typeAliases 用于配置类型命名 -->
<typeAliases></typeAliases>
<!-- typeHandlers用于配置类型处理器 -->
<typeHandlers></typeHandlers>
<!-- objectFactory用于配置对象工厂 -->
<objectFactory type=""></objectFactory>
<!--plugins用于配置插件 -->
<plugins></plugins>
<!-- environments配置不同的数据库连接环境 -->
<environments default="">
<environment id=""> <!--environment用于配置数据库连接环境 -->
<!-- transactionManager用于配置事务管理器 -->
<transactionManager type=""></transactionManager>
<!--dataSource用于配置数据源 -->
<dataSource type=""></dataSource>
</environment>
</environments>
<!-- databaseIdProvider是数据库产商标识 -->
<databaseIdProvider type=""></databaseIdProvider>
<!-- mappers用于配置映射器 -->
<mappers></mappers>
</configuration>
上面的标签中,plugins涉及插件,是偏向底层的内容,如果不了解mybatis运行原理,那么可能会比较晦涩,这会留到另外一篇博文再讲述(如果有空的话)。【databaseIdProvider和objectFactory不讲述】
下面主要讲properties、settings、typeAliases、typerHandler、environments、mappers。
常用标签:
environments标签
environments用来配置多个数据库连接环境,每一个环境都使用environment标签来定义。(不同的环境可以定义不同的数据库连接信息)
- 唯一属性--default:代表默认使用哪个环境,值为environment的id,这里的值影响SqlSessionFactoryBuilder调用build(配置文件输入流)时使用哪个环境初始化SqlSessionFactory。例如:
<environments default="development">省略environment配置</environments>代表默认使用id="development"的环境。
- 唯一属性--default:代表默认使用哪个环境,值为environment的id,这里的值影响SqlSessionFactoryBuilder调用build(配置文件输入流)时使用哪个环境初始化SqlSessionFactory。例如:
environment标签:是environments的子标签,用来定义数据库连接环境,子标签有transactionManager(用来定义事务管理器,事务管理器负责定义这个数据库环境中的事务怎么处理)、dataSource(用来定义数据源,主要是配置数据库连接信息)。
- 唯一属性——id:用来唯一标识每个环境。
- 子标签transactionManager:用来定义事务管理器
- 唯一属性:type:
- JDBC:以JDBC的方式对数据库的提交和回滚进行操作。MyBatis中JDBC事务管理器的事务默认是不自动提交的,所以增删改操作需要
sqlSession.comit()来进行事务提交。 - MANAGED:把事务交给容器来管理,如JBOSS,Weblogic这样的容器。
- JDBC:以JDBC的方式对数据库的提交和回滚进行操作。MyBatis中JDBC事务管理器的事务默认是不自动提交的,所以增删改操作需要
- transactionManager有子标签property,可以配置事务管理器的一些规则【这里不讲,有兴趣自查。】
- 示例:
<transactionManager type="JDBC" ></transactionManager>
- 唯一属性:type:
- 子标签dataSource:用来定义数据源
- 唯一属性:type:
- POOLED:数据库连接池的方式,配置这个值代表使用MyBatis自带的数据库连接池。
- UNPOOLED:非数据库连接池的方式
- JNDI:使用外部数据库连接源,tomcat数据源之类的外部数据库连接源
- 第三方连接池【mybatis可以整合第三方连接池,但这需要创建新的类,所以留到后面再讲。】
- 子标签property可以配置一些数据库连接的参数,除了基本的数据库driver、url、username、password,还可以根据type的不同值来配置一些不同参数,不同type里面的数据库驱动的定义方式可能也是不同的。
- 唯一属性:type:
<environments default="development">
<!-- environment用来定义数据库环境,environments用来定义多个environment -->
<environment id="development">
<!-- 配置事务管理,使用jdbc事务管理 -->
<transactionManager type="JDBC" />
<!-- 配置数据库连接池 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/mybatis2" />
<property name="username" value="root" />
<property name="password" value="123456" />
</dataSource>
</environment>
</environments>
properties标签
properties标签的作用类似properties文件,properties标签可以导入properties配置文件,也可以直接使用子标签property来配置参数。properties标签中配置的参数可以在后面的其它属性配置中引用。
使用方式:
用properties标签导入配置文件:
<!-- 示例 -->
<properties resource="jdbc.properties"></properties>
导入后,根据
${键名}来引用配置文件中配置的参数,例如在配置数据源的时候:<property name="driver" value="${jdbc.driverClass}" />
用properties标签定义property变量,定义后也可以使用
${键名}来引用。设置参数:
<properties>
<property name="db.driver" value="com.mysql.jdbc.Driver"/>
<property name="db.url" value="jdbc:mysql://localhost:3306/mybatis2"/>
<property name="db.user" value="root"/>
<property name="db.password" value="123456"/>
</properties>
引用参数:
<environment id="test">
<!-- 配置事务管理,使用jdbc事务管理 -->
<transactionManager type="JDBC" />
<!-- 配置数据库连接池 -->
<dataSource type="POOLED">
<property name="driver" value="${db.driver}" />
<property name="url" value="${db.url}" />
<property name="username" value="${db.user}" />
<property name="password" value="${db.password}" />
</dataSource>
</environment>
为了分清楚配置的属性的作用,通常都会使用点分法来定义变量,如可以使用db.xxx代表这个配置与数据库相关。【当然,不使用点分法也可以】
Settings标签
- Settings用于配置一些涉及MyBatis底层运行的参数(比如日志打印、自动映射、缓存管理),大部分情况下使用默认值。
- 配置项以及配置项的值,可以参考这篇博文
https://blog.csdn.net/u014231523/article/details/53056032,好像写的算靠谱了。
typeAliases标签
typeAliases通常用来别名,定义别名后,可以把很长的名字定义成一个较短的名字,例如类的全限定名(qualified name)很长时,可以用一个别名来代表这个类路径。
别名可以使用在映射文件中,通常可以把类的全限定名定义成别名,这样就可以简写了。
别名分为系统定义别名和自定义别名
系统定义别名主要是一些数据类型别名,所以要注意定义sql的入参类型和结果类型,SQL语句的结果类型resultType定义成int的时候,返回的结果应该用Integer类型的变量存储
别名 映射的类型 _bytebyte _longlong _shortshort _intint _integerint _doubledouble _floatfloat _boolean boolean string String byte Byte long Long short Short int Integer integer Integer double Double float Float boolean Boolean date Date decimal BigDecimal bigdecimal BigDecimal 自定义别名:
可以使用typeAlias标签来定义别名:
<typeAliases>
<!-- alias的值是别名,type的值是要定义别名的名字 -->
<typeAlias type="work.pojo.User" alias="user"/>
</typeAliases>
别名包扫描:
- 由于别名很多时候都用在映射文件中(解决类全限定名过长问题),所以MyBatis支持对包进行别名扫描,扫描的包下的类都被定义成别名,别名就是类名
<typeAliases>
<!-- 整个包下的类都被定义别名,别名为类名,不区分大小写-->
<package name="work.pojo"/>
<!--这样pojo下的类都被定义成了别名,例如work.pojo.User可以简写成user -->
</typeAliases>
别名是忽略大小写的,所以别名user,你既可以使用user来引用,也可以使用User来引用。
typeHandler标签:
typeHandler是用来处理类型转换问题的,从数据库中获取的数据要想装入到对象中,势必要经过类型转换,好比MyBatis必须知道如何将varchar转成String。对于常见的类型转换,MyBatis已经帮我们定义了不少类型转换器,下面给出常见的。
数据库数据类型 Java类型 类型转换器 CHAR, VARCHARString StringTypeHandlerBOOLEAN Boolean BooleanTypeHandlerSMALLINTShortShortTypeHandlerINTEGERIntegerIntegerTypeHandlerFLOATFloatFloatTypeHandlerDOUBLEDoubleDoubleTypeHandler
由于MyBatis的转换器已经能够解决大部分问题了,所以这里不讲怎么自定义转换器,有兴趣的可以自查。
mappers标签
mappers是用来引入映射器(映射文件)的,有了映射器,Mybatis才能够管理到在映射文件中定义的SQL。
引入方式:
导入配置文件,通过配置文件的路径名导入:
<mappers>
<!-- 第一种方式,根据映射文件路径-->
<mapper resource="work/pojo/user.xml"/>
</mappers>
使用mapper方式开发时,由于映射文件与mapper对应,也可以通过mapper的全限定名导入:
【要求映射文件与mapper处于同一目录,而且映射文件的文件名与要mapper名一致】
<mappers>
<!-- 对下面的配置,要求映射配置文件的文件名为UserMapper.xml;要求UserMapper.xml与UserMapper处于同一目录下-->
<mapper class="work.mapper.UserMapper"/>
</mappers>
使用mapper方式开发时,由于映射文件与mapper对应,也可以通过扫描mapper所在的包来导入:
【要求映射文件与mapper处于同一目录,而且映射文件的文件名与要mapper名一致】
<mappers>
<!-- 第三种方式,包扫描器:
1、映射文件与接口同一目录下
2、映射文件名必需与接口文件名称一致
-->
<package name="work.mapper"/>
</mappers>
补充:
- plugin插件是一个比较大的内容,而且偏向底层,这会留到另外一篇博文再讲述。。
- 除了上面的,还有databaseIdProvide数据库厂商标识,objectFactory对象工厂,但不常用。有兴趣的自查。
动态SQL
- 当允许使用不定数量的条件来查询的时候(这种情况就是多条件查询的情况),入参无法确定是否已经正确填写,那么你可能遇到查询条件为空的情况。所以我们需要对查询条件进行判断,动态SQL就可以解决这种问题。
标签:
if标签
单条件分支判断
属性:
- test:对条件进行判断,test里面可以是一个表达式。判断字符串时,允许字符串调用函数。
下面的SQL语句,如果调用的时候不传参,将得到
SELECT * FROM USER WHERE age = null;<select id="getUserByAge" parameterType="int" resultType="work.pojo.User">
SELECT * FROM USER WHERE age = #{age};
</select>
利用if标签解决问题:
<select id="getUserByAge" parameterType="int" resultType="work.pojo.User">
SELECT * FROM USER
<if test="age!=null ">
WHERE age = #{age}
</if>
</select>
where标签
where主要用于处理多个判断条件的拼接。在where A条件 and B条件可能需要判断一下A和B的合法性,如果仅仅使用if标签那么可能会导致where、and字符串重复,而where会自动处理多余的and和where,还会自动加上where。
<select id="getUserByAgeOrName" parameterType="work.pojo.User" resultType="work.pojo.User">
SELECT * FROM USER
<where>
<if test="age!=null ">
and age = #{age}
</if>
<if test="name!=null">
and name like '%${name}%'
</if>
</where>
</select>
set标签:
where标签可以解决查询条件中的where问题,但如果对一个对象进行update时,如何判断传入的set值是否为空呢?可以使用if来进行判断,然后再使用set标签解决条件字符串重复问题,set标签可以去除多余的逗号。
<update id="updateUser" parameterType="work.pojo.User">
UPDATE USER SET
name=#{name},
age=#{age}
where id=#{id}
</update>
<update id="updateUser" parameterType="work.pojo.User">
UPDATE USER
<set>
<if test="name!=null">name=#{name},</if>
<if test="age!=null">age=#{age}</if>
</set>
where id=#{id}
</update>
foreach标签
- 当传入的参数是一个集合的时候,遇到的问题是怎么把集合中的数据遍历出来,foreach标签可以遍历集合。
- 标签的属性:
- collection:要遍历的集合【传入类型为List,那么集合名为list;传入的是数组,数组名为array】
- item:用来迭代的变量
- open:循环开始之前输出的内容
- close:循环完成后输出的内容
- seperator:分隔符
<select id="getUserByAgeCollection" parameterType="List" resultType="work.pojo.User">
SELECT * FROM USER WHERE
<foreach item="age" collection="list" open="age IN(" separator="," close=")">
#{age}
</foreach>
</select>
补充:
- 除了上面的标签,还有例如trim,choose,when标签,由于上面的足够日常使用了,所以就不讲那么多了。其他的有兴趣可以自查了解一下。
关联查询
- 在开发中,关联查询是非常常见的,关联查询就是在查询某个表时,通过字段关联关系,查出我们所需要的另外一个表中的数值。例如:通常来说,班级信息表和学生表是独立的,但班级信息表和学生表是有关系的,我们不能从班级信息表中获取到学生信息,如果我们查询班级信息表时希望同时获取到班级下的学生信息,那么我们就需要使用到关联查询。
- 关联查询通常有一对一查询(关系类似于一个部门只有一个经理),一对多查询(关系类似于一个部分可以有多个员工),多对多查询(关系类似于一个学生可以选修多门课,一门课也可以被多名学生选修)。
一对一关联查询:
以一个部门对应一个经理为例。
方式一:
创建一个POJO类,用连接查询语句查询出两个表的数据,通过resultType封装到一个POJO类中。
步骤:
1.首先创建一个POJO类,要求包含了部门信息和经理信息(如果你不想重复定义属性,也可以选择继承单个类的信息继承两个类,这里考虑到有选择地查询字段所以不继承):
package work.pojo;
public class Department_Manager {
//部门的信息
private Integer did;
private String department_name;
//经理的信息
private Integer mid;
private String name;
private Double salary;
public Integer getDid() {
return did;
}
public void setDid(Integer did) {
this.did = did;
}
public String getDepartment_name() {
return department_name;
}
public void setDepartment_name(String department_name) {
this.department_name = department_name;
}
public Integer getMid() {
return mid;
}
public void setMid(Integer mid) {
this.mid = mid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
@Override
public String toString() {
return "Department_Manager [did=" + did + ", 部门名=" + department_name + ", mid=" + mid + ", 经理名="+ name + ", 工资=" + salary + "]";
}
}
数据表的创建(要注意,由于存在关系,那么两个表之间肯定有一个字段用于建立关联,在POJO类中可以没有这个字段,但表中一定要有,因为SQL语句依靠这个来查询):
use mybatis2;
create table department(
did int primary key auto_increment,
department_name varchar(20)
);
create table manager(
mid int primary key auto_increment,
name varchar(20),
salary double(7,2),
did int,
foreign key(did) references department(did) --这里用外键关联
);
insert into department values(null,'开发部'),(null,'市场部');
insert into manager values(null,'张三',20000.00,1),(null,'李四',20000.00,2);
2.编写SQL语句:【这里使用Mapper方式】
定义接口:
package work.pojo;
public interface UserMapper {
public Department_Manager[] getDepartmentManager();
}
创建映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="work.pojo.UserMapper">
<select id="getDepartmentManager" resultType="work.pojo.Department_Manager" >
SELECT
d.did,d.department_name,
m.mid,m.name,m.salary
FROM department d
LEFT JOIN manager m
ON d.did = m.did
</select>
</mapper>
3.编写测试方法:
@Test
public void test5() throws IOException {
SqlSessionFactoryBuilder sfb=new SqlSessionFactoryBuilder();
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sessionFactory = sfb.build(inputStream);
SqlSession sqlSession = sessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Department_Manager[] departmentManager = mapper.getDepartmentManager();
for (Department_Manager department_Manager : departmentManager) {
System.out.println(department_Manager);
}
sqlSession.close();
}
所以第一种方式是把数据封装到一个包含了多个表的所有字段的POJO对象的方式。如果有多个表,有多种关系的话,第一种方式会显得麻烦复杂。
方式二:
创建一个在部门类里面添加一个经理类对象,用连接查询语句查询出两个表的数据,通过resultMap把查出来的数据封装到部门类中。
步骤:
1.创建经理类,创建部门类,在部门类中添加一个经理类对象。
经理类:
```java
package work.pojo;
public class Manager {
private Integer mid;
private String name;
private Double salary;
private Integer did;
//did是部门表的主键,你可以不定义,因为关注点在部门,你也可以定义成一个部门对象。
public Integer getMid() {
return mid;
}
public void setMid(Integer mid) {
this.mid = mid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
public Integer getDid() {
return did;
}
public void setDid(Integer did) {
this.did = did;
}
@Override
public String toString() {
//由于没有给did封装数据,所以这里不打印did
return "Manager [mid=" + mid + ", name=" + name + ", salary=" + salary + "]";
}
}
部门类:
```java
package work.pojo;
public class Department {
private Integer did;
private String department_name;
//经理的映像
private Manager manager;
public Integer getDid() {
return did;
}
public void setDid(Integer did) {
this.did = did;
}
public String getDepartment_name() {
return department_name;
}
public void setDepartment_name(String department_name) {
this.department_name = department_name;
}
public Manager getManager() {
return manager;
}
public void setManager(Manager manager) {
this.manager = manager;
}
@Override
public String toString() {
return "Department [did=" + did + ", department_name=" + department_name + ", manager=" + manager + "]";
}
}
2.定义映射文件和接口:
定义接口:
package work.pojo;
public interface UserMapper {
public Department_Manager[] getDepartmentManager2();
}
创建映射文件,使用resultMap定义多表关联映射规则:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="work.pojo.UserMapper">
<resultMap type="work.pojo.Department" id="department_manager">
<id property="did" column="did" />
<result property="department_name" column="department_name" />
<!--association用来处理对象中存在另一个类的对象的情况,
property是对象中另一个类的对象变量名,javaType是另一个类的全限定名
标签里面使用id和result来映射数据与另一个类的对象的关系。
-->
<association property="manager" javaType="work.pojo.Manager">
<id property="mid" column="mid"/>
<result property="name" column="name" />
<result property="salary" column="salary"/>
<!-- 这里要注意不要封装外键字段,因为我们这里的经理表的外键是did,部门表主键是did,会命名冲突;由于这里没封装数据给经理类的did,所以经理类的did是没有数据的;如果你想给经理类的did赋值,那么你应该利用别名,在SQL中令m.did m_did,然后上面使用<result property="did" column="m_did"/> -->
</association>
</resultMap>
<select id="getDepartmentManager2" resultMap="department_manager" >
SELECT
d.did,d.department_name,
m.mid,m.name,m.salary
FROM department d
LEFT JOIN manager m
ON d.did = m.did
</select>
</mapper>
3.编写测试方法:
@Test
public void test6() throws IOException {
SqlSessionFactoryBuilder sfb=new SqlSessionFactoryBuilder();
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sessionFactory = sfb.build(inputStream);
SqlSession sqlSession = sessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Department[] departments = mapper.getDepartmentManager2();
for (Department department : departments) {
System.out.println(department);
}
sqlSession.close();
}
一对多关联查询:
如果采用类似上面一对一的方式一来处理一对多话,一一方的会出现很多次(方式一是封装查询的每行记录,一对多查询的时候一一方的数据会出现多次,所以采用方式二来实现一对多)。下面以一个班级可以有多个学生为例。
步骤:
1.创建Student类,创建Grade类,在Grade中添加一个由Student对象组成的List:
Student类:
package work.pojo;
public class Student {
private Integer sid;
private String stu_name;
public Integer getSid() {
return sid;
}
public void setSid(Integer sid) {
this.sid = sid;
}
public String getStu_name() {
return stu_name;
}
public void setStu_name(String stu_name) {
this.stu_name = stu_name;
}
@Override
public String toString() {
return "Student [sid=" + sid + ", stu_name=" + stu_name + "]";
}
}
Grade类:
package work.pojo;
import java.util.List;
public class Grade {
private Integer gid;
private String grade_name;
private List<Student> students;
public Integer getGid() {
return gid;
}
public void setGid(Integer gid) {
this.gid = gid;
}
public String getGrade_name() {
return grade_name;
}
public void setGrade_name(String grade_name) {
this.grade_name = grade_name;
}
public List<Student> getStudents() {
return students;
}
public void setStudents(List<Student> students) {
this.students = students;
}
@Override
public String toString() {
return "Grade [gid=" + gid + ", grade_name=" + grade_name + ", students=" + students + "]";
}
}
2.创建数据表,插入测试数据:
create table grade(
gid int primary key auto_increment,
grade_name varchar(20)
);
create table student(
sid int primary key auto_increment,
stu_name varchar(20),
gid int,
foreign key(gid) references grade(gid)
);
insert into grade values(null,"python班"),(null,'Java班');
insert into student values(null,'张三',1),(null,'李四',1),(null,'王五',2),(null,'赵六',2);
3.创建mapper接口和映射文件:
接口:
package work.pojo;
public interface UserMapper {
public Grade[] getGradeStudent();
}
映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="work.pojo.UserMapper">
<resultMap type="work.pojo.Grade" id="grade_student_map">
<id property="gid" column="gid"/>
<result property="grade_name" column="grade_name"/>
<!-- collection用来处理一个类中含有其他类的集合时的数据映射(一对多)
property是集合的变量名,ofType是集合元素的全限定名,
collection内使用id和result建立映射关系
-->
<collection property="students" ofType="work.pojo.Student" >
<id property="sid" column="sid"/>
<result property="stu_name" column="stu_name" />
</collection>
</resultMap>
<select id="getGradeStudent" resultMap="grade_student_map">
SELECT
g.gid,g.grade_name,
s.sid,s.stu_name
FROM grade g
LEFT JOIN student s
ON g.gid = s.gid
</select>
</mapper>
4.编写测试方法:
@Test
public void test7() throws IOException {
SqlSessionFactoryBuilder sfb=new SqlSessionFactoryBuilder();
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sessionFactory = sfb.build(inputStream);
SqlSession sqlSession = sessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Grade[] gradeStudent = mapper.getGradeStudent();
for (Grade grade : gradeStudent) {
System.out.println(grade);
}
sqlSession.close();
}
多对多:
由于多对多太过复杂,Mybatis不支持多对多,Mybatis选择使用两个一对多来实现多对多。下面以一名学生可以选多门课,一门课可以被多个学生选为例。【多对多关系模型是两方都有对方的数据,两方都能查询到对方的数据,所以我们使用一对多的时候,能向两方的对象中都装入数据,就可以达到多对多的效果;但有一点效果不能达到,(以例子讲解)课程对象中的学生集合没有与课程对象建立上关系,但从业务需求来说通常不关注另外一方的关系(如果关注,从学生一方查询即可,为什么要使用课程中的学生对象?),所以这个缺点也不算缺点。另外,下面也会讲一下解决这个问题的方法。】
步骤:
1.创建Cource类,创建SchoolChild类,分别在两个类中创建对方类的集合:【这里要注意toString问题,如果A的toString包含B,B包含A,那么会死循环。】
Cource类:
package work.pojo;
import java.util.List;
public class Cource {
private Integer cid;
private String cource_name;
private List<SchoolChild> schoolchilds;
public Integer getCid() {
return cid;
}
public void setCid(Integer cid) {
this.cid = cid;
}
public String getCource_name() {
return cource_name;
}
public void setCource_name(String cource_name) {
this.cource_name = cource_name;
}
public List<SchoolChild> getSchoolchilds() {
return schoolchilds;
}
public void setSchoolchilds(List<SchoolChild> schoolchilds) {
this.schoolchilds = schoolchilds;
}
}
SchoolChild类:
package work.pojo;
import java.util.List;
public class SchoolChild {
private Integer sid;
private String stu_name;
private List<Cource> cources;
public Integer getSid() {
return sid;
}
public void setSid(Integer sid) {
this.sid = sid;
}
public String getStu_name() {
return stu_name;
}
public void setStu_name(String stu_name) {
this.stu_name = stu_name;
}
public List<Cource> getCources() {
return cources;
}
public void setCources(List<Cource> cources) {
this.cources = cources;
}
}
2.创建表(注意有中间表):
create table cource(
cid int primary key auto_increment,
cource_name varchar(20)
);
create table schoolChild(
sid int primary key auto_increment,
stu_name varchar(20)
);
create table cource_schoolChild(
cid int,
sid int,
foreign key(cid) references cource(cid),
foreign key(sid) references schoolChild(sid)
);
insert into cource values(null,"python"),(null,'Java');
insert into schoolChild values(null,'张三'),(null,'李四'),(null,'王五');
insert into cource_schoolChild values(1,1),(1,2),(1,3),(2,1),(2,3);
3.创建接口和映射文件:
接口:
package work.pojo;
public interface UserMapper {
public Cource[] getCource();
public SchoolChild[] getSchoolChild();
}
映射文件:【难点是sql语句,其他的resultMap与一对多的一样】
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="work.pojo.UserMapper">
<resultMap type="work.pojo.Cource" id="cource_schoolchild_map">
<id property="cid" column="cid" />
<result property="cource_name" column="cource_name" />
<collection property="schoolchilds" ofType="work.pojo.SchoolChild">
<id property="sid" column="sid" />
<result property="stu_name" column="stu_name" />
</collection>
</resultMap>
<select id="getCource" resultMap="cource_schoolchild_map">
select
t1.cid,t1.cource_name,
t3.sid,t3.stu_name
from cource t1 left join cource_schoolChild t2 on t1.cid=t2.cid left join schoolChild t3 on t2.sid=t3.sid;
</select>
<resultMap type="work.pojo.SchoolChild" id="schoolchild_cource_map">
<id property="sid" column="sid" />
<result property="stu_name" column="stu_name" />
<collection property="cources" ofType="work.pojo.Cource">
<id property="cid" column="cid" />
<result property="cource_name" column="cource_name" />
</collection>
</resultMap>
<select id="getSchoolChild" resultMap="schoolchild_cource_map">
select
t1.cid,t1.cource_name,
t3.sid,t3.stu_name
from cource t1 left join cource_schoolChild t2 on t1.cid=t2.cid left join schoolChild t3 on t2.sid=t3.sid;
</select>
</mapper>
4.编写测试方法:
@Test
public void test8() throws IOException {
SqlSessionFactoryBuilder sfb=new SqlSessionFactoryBuilder();
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sessionFactory = sfb.build(inputStream);
SqlSession sqlSession = sessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Cource[] cources = mapper.getCource();
for (Cource cource : cources) {
System.out.println(cource);
}
System.out.println("---分隔线---");
SchoolChild[] schoolChilds = mapper.getSchoolChild();
for (SchoolChild schoolChild : schoolChilds) {
System.out.println(schoolChild);
}
5.测试结果:
Cource [cid=1, cource_name=python, schoolchilds=[SchoolChild [sid=1, stu_name=张三, cources=null], SchoolChild [sid=2, stu_name=李四, cources=null], SchoolChild [sid=3, stu_name=王五, cources=null]]]
Cource [cid=2, cource_name=Java, schoolchilds=[SchoolChild [sid=1, stu_name=张三, cources=null], SchoolChild [sid=3, stu_name=王五, cources=null]]]
---分隔线---
SchoolChild [sid=1, stu_name=张三, cources=[Cource [cid=1, cource_name=python, schoolchilds=null], Cource [cid=2, cource_name=Java, schoolchilds=null]]]
SchoolChild [sid=2, stu_name=李四, cources=[Cource [cid=1, cource_name=python, schoolchilds=null]]]
SchoolChild [sid=3, stu_name=王五, cources=[Cource [cid=1, cource_name=python, schoolchilds=null], Cource [cid=2, cource_name=Java, schoolchilds=null]]]
使用说明:
在上面的测试结果中,课程对象中查出的学生对象的课程对象是null,这是因为没有封装上,下面可以提供一种方法来解决上面这个问题,但要注意--这个问题是解决不了的:这是因为MyBatis是面向SQL的,你定义了映射规则它才能帮你封装,MyBatis对于对象与对象中嵌套对象的关系并不了解,它不知道怎么做,只有你进行了封装定义才能够给嵌套对象封装数据。如果你在resultMap的collection中嵌套一个collection就可以对嵌套对象中的嵌套对象封装数据,但嵌套对象中的嵌套对象的嵌套对象里的对象还是会空的。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="work.pojo.UserMapper">
<resultMap type="work.pojo.Cource" id="cource_schoolchild_map">
<id property="cid" column="cid" />
<result property="cource_name" column="cource_name" />
<collection property="schoolchilds" ofType="work.pojo.SchoolChild">
<id property="sid" column="sid" />
<result property="stu_name" column="stu_name" />
<!-- 给嵌套对象里面的嵌套对象封装数据 -->
<collection property="cources" ofType="work.pojo.Cource">
<id property="cid" column="cid" />
<result property="cource_name" column="cource_name" />
</collection>
</collection>
</resultMap>
<select id="getCource" resultMap="cource_schoolchild_map">
select
t1.cid,t1.cource_name,
t3.sid,t3.stu_name
from cource t1 left join cource_schoolChild t2 on t1.cid=t2.cid left join schoolChild t3 on t2.sid=t3.sid;
</select>
<!-- 省略SchoolChild的。 -->
</mapper>
关联对象的插入问题
- 如果你学过一些其他的ORM框架,你可能会有点迷糊有关联关系的对象怎么插入到数据表。这里提一下,MyBatis是面向SQL的,上面的一对多查询本质上都是面向对象的,association和collection主要作用于Java对象,而不作用于数据库,association和collection只是定义了返回的数据的封装规则,从本质来看,SQL操作还是join操作。
- 所以,明白了MyBatis是面向SQL的之后,那么怎么插入有关联关系的对象数据呢?像直接操作SQL那样,插入记录即可。一对多的,通常都是多一方维护外键,那么直接在多一方的表插入带外键的记录即可,插入的时候获取一下关联对象的主键作为外键值;多对多的,直接在中间表插入记录,插入的时候获取一下关联对象的主键作为中间表的外键值。
<mapper namespace="work.mapper.ProductMapper">
<resultMap type="work.domain.Product" id="product_category">
<id property="pid" column="pid"/>
<result property="pname" column="pname"/>
<result property="price" column="price"/>
<result property="pimage" column="pimage"/>
<result property="pdesc" column="pdesc"/>
<!-- 这里是多表查询操作,这里商品里面有一个商品分类外键 -->
<association property="category" javaType="work.domain.Category">
<result property="category_name" column="category_name"/>
</association>
</resultMap>
<select id="findAll" resultMap="product_category">
select
p.pid,p.pname,p.price,p.pimage,p.pdesc,
c.cid,c.category_name
from product p left join category c on p.cid = c.cid;
</select>
<insert id="save" parameterType="work.domain.Product">
insert into product(pname,price,pimage,pdesc,cid) values(
#{pname},#{price},#{pimage},#{pdesc},#{category.cid}
);
</insert>
</mapper>
补充:
- 不论一对一、一对多、多对多,都是两种方式,但其实还有一种方式。建立独立的查询语句(关系模型中的每个对象都有),通过在resultMap中配置,进行某个对象查询的时候,调用查询另一个对象的SQL来传入指定参数并封装结果。【有兴趣的自查。】
缓存
- 一级缓存存放在sqlSession上,默认开启。
- 二级缓存存放在SqlSessionFactory上
- 缓存的意义:
- 一级缓存在sqlSession上,重复查询时,不会重复发送SQL,会从缓存中获取之前查询到的数据。
- 二级缓存是SqlSessionFactory层次上的缓存,它是面向命名空间,同一个命名空间(不同的SqlSession可以使用同一个命名空间下的SQL)中使用重复的查询时,不会重复发送SQL,会从缓存中获取之前查询到的数据。【二级缓存默认是不开启的,而且涉及序列化内容,这里不讲。】
测试一级缓存的存在性:
- 一级缓存是默认开启的。
- 尝试重复查询,如果仅仅发送一次SQL语句。那么就可以得出一级缓存是存在的【mybatis的运行信息输出依赖log4j,所以要给一个log4j的配置文件】。
@Test
public void test9() throws IOException {
SqlSessionFactoryBuilder sfb=new SqlSessionFactoryBuilder();
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sessionFactory = sfb.build(inputStream);
SqlSession sqlSession = sessionFactory.openSession();
//根据接口.class来获取mapper
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUserById(3);
User user2 = mapper.getUserById(3);
System.out.println(user);
System.out.println(user==user2);
sqlSession.close();
}
缓存的配置
在select\delete\insert标签 中,有一个flushCache属性:设置查询之后是否删除本地缓存和二级缓存。
补充:
- 还可以自定义缓存,然后在映射文件中使用cache引入,其他映射文件再想引入时,可以直接使用cache-ref。通常采用Redis这类数据库来进行缓存。
mybatis整合第三方连接池
整合第三方连接池,当然要引入依赖包啦。这里就不多讲了,就是第三方连接池的依赖包。
首先需要定义一个数据源工厂,这个工厂要继承UnpooledDataSourceFactory,在构造函数中返回需要使用的连接池对象
package work.dataSource;
import org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class C3P0DataSourceFactory extends UnpooledDataSourceFactory {
public C3P0DataSourceFactory(){
this.dataSource=new ComboPooledDataSource();
}
}
然后在mybatis-config.xml中配置使用第三方连接池:
<!-- type里填刚才定义的连接池工厂的全限定名 -->
<dataSource type="work.dataSource.C3P0DataSourceFactory">
<!-- 下面的属性名要按照连接池自身的规则来配置,比如c3p0的驱动参数是driverClass -->
<property name="driverClass" value="com.mysql.jdbc.Driver" />
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/mybatis2" />
<property name="user" value="root" />
<property name="password" value="123456" />
<property name="idleConnectionTestPeriod" value="60" />
<property name="maxPoolSize" value="20" />
<property name="maxIdleTime" value="600" />
</dataSource>
补充:
- 上面的演示采用的是c3p0的,dbcp的也一样。
- 除此之外,还有一种实现DataSourceFactory接口来整合连接池的方式,里面有个setProperties可以把mybatis-config.xml的连接池配置封装到形参properties中,然后在getDataSource利用properties来新建目标连接池对象,返回的时候返回连接池对象;然后也需要在mybatis-config.xml中像上面一样配置。【原本也想写一下这个方式的,但不知道为什么dataSource.setProperties(properties)的时候无法获取到properties中的数据,打印过发现properties中是有数据的。】
写在最后
现在没有写的内容:
- mybatis的运行原理
- 插件
- 分页插件
- 存储过程
- 延迟加载
不写,有兴趣自查的内容:
- 注解式mybatis:由于mybatis使用注解来配置有几点非常不方便的地方,一般都会使用XML来配置。
- 二级缓存,自定义缓存。
Mybatis从认识到了解的更多相关文章
- 【分享】标准springMVC+mybatis项目maven搭建最精简教程
文章由来:公司有个实习同学需要做毕业设计,不会搭建环境,我就代劳了,顺便分享给刚入门的小伙伴,我是自学的JAVA,所以我懂的.... (大图直接观看显示很模糊,请在图片上点击右键然后在新窗口打开看) ...
- Java MyBatis 插入数据库返回主键
最近在搞一个电商系统中由于业务需求,需要在插入一条产品信息后返回产品Id,刚开始遇到一些坑,这里做下笔记,以防今后忘记. 类似下面这段代码一样获取插入后的主键 User user = new User ...
- [原创]mybatis中整合ehcache缓存框架的使用
mybatis整合ehcache缓存框架的使用 mybaits的二级缓存是mapper范围级别,除了在SqlMapConfig.xml设置二级缓存的总开关,还要在具体的mapper.xml中开启二级缓 ...
- 【SSM框架】Spring + Springmvc + Mybatis 基本框架搭建集成教程
本文将讲解SSM框架的基本搭建集成,并有一个简单demo案例 说明:1.本文暂未使用maven集成,jar包需要手动导入. 2.本文为基础教程,大神切勿见笑. 3.如果对您学习有帮助,欢迎各种转载,注 ...
- mybatis plugins实现项目【全局】读写分离
在之前的文章中讲述过数据库主从同步和通过注解来为部分方法切换数据源实现读写分离 注解实现读写分离: http://www.cnblogs.com/xiaochangwei/p/4961807.html ...
- MyBatis基础入门--知识点总结
对原生态jdbc程序的问题总结 下面是一个传统的jdbc连接oracle数据库的标准代码: public static void main(String[] args) throws Exceptio ...
- Mybatis XML配置
Mybatis常用带有禁用缓存的XML配置 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE ...
- MyBatis源码分析(一)开篇
源码学习的好处不用多说,Mybatis源码量少.逻辑简单,将写个系列文章来学习. SqlSession Mybatis的使用入口位于org.apache.ibatis.session包中的SqlSes ...
- (整理)MyBatis入门教程(一)
本文转载: http://www.cnblogs.com/hellokitty1/p/5216025.html#3591383 本人文笔不行,根据上面博客内容引导,自己整理了一些东西 首先给大家推荐几 ...
- MyBatis6:MyBatis集成Spring事物管理(下篇)
前言 前一篇文章<MyBatis5:MyBatis集成Spring事物管理(上篇)>复习了MyBatis的基本使用以及使用Spring管理MyBatis的事物的做法,本文的目的是在这个的基 ...
随机推荐
- [Swift]LeetCode10. 正则表达式匹配 | Regular Expression Matching
Given an input string (s) and a pattern (p), implement regular expression matching with support for ...
- [Swift]LeetCode296. 最佳开会地点 $ Best Meeting Point
A group of two or more people wants to meet and minimize the total travel distance. You are given a ...
- [Swift]LeetCode996. 正方形数组的数目 | Number of Squareful Arrays
Given an array A of non-negative integers, the array is squareful if for every pair of adjacent elem ...
- ubuntu16.04安装lnmp环境
1.安装mysql sudo apt install mysql-server 2.安装nginx和php #添加nginx和php的ppa源 sudo apt-add-repository ppa ...
- Java并发编程-volatile可见性的介绍
要学习好Java的多线程,就一定得对volatile关键字的作用机制了熟于胸.最近博主看了大量关于volatile的相关博客,对其有了一点初步的理解和认识,下面通过自己的话叙述整理一遍. 有什么用? ...
- logback.xml sql语句输出
在使用springBoot框架之后,日志配置文件变成了logback.xml,输出sql语句的方法为: <!-- 打印sql语句 --> <logger name="com ...
- 『高次同余方程 Baby Step Giant Step算法』
高次同余方程 一般来说,高次同余方程分\(a^x \equiv b(mod\ p)\)和\(x^a \equiv b(mod\ p)\)两种,其中后者的难度较大,本片博客仅将介绍第一类方程的解决方法. ...
- Spring AOP实现统一日志输出
目的: 统一日志输出格式 思路: 1.针对不同的调用场景定义不同的注解,目前想的是接口层和服务层. 2.我设想的接口层和服务层的区别在于: (1)接口层可以打印客户端IP,而服务层不需要 (2)接口层 ...
- 给vs2015添加EF
今天做EF的小例子时,发现需要添加实体数据模型,但是不管怎么找在新建项中都找不到这个选项,这是怎么回事,于是就开始百度吧,有的说可能是VS安装时没有全选,也有的人说可能是重装VS时,没有将注册表清除, ...
- 知其所以然~mongodb副本集
MongoDB 复制(副本集) MongoDB复制是将数据同步在多个服务器的过程. 复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性. 复制还允许您 ...