NLP&深度学习:近期趋势概述
NLP&深度学习:近期趋势概述
摘要:当NLP遇上深度学习,到底发生了什么样的变化呢?
在最近发表的论文中,Young及其同事汇总了基于深度学习的自然语言处理(NLP)系统和应用程序的一些最新趋势。本文的重点介绍是对各种NLP任务(如视觉问答(QA)和机器翻译)最新技术(SOTA)结果的回顾和比较。在这篇全面的综述中,你可以详细了解NLP深度学习的过去,现在和未来。此外,你还将学习一些 在NLP中应用深度学习的最佳实践。其中主题包括:
1、分布式表示的兴起(例如,word2vec);
2、卷积,循环和递归神经网络;
3、在强化学习中的NLP的应用;
4、无监督模型在表示学习中的最新进展;
5、将深度学习模型与增强记忆策略相结合;
什么是NLP?
自然语言处理(NLP)涉及构建计算机算法以自动分析和表示人类语言。基于NLP的系统现在已经实现了广泛的应用,例如Google强大的搜索引擎,以及最近阿里巴巴的语音助手天猫精灵。NLP还可用于教授机器执行复杂的自然语言相关任务的能力,例如机器翻译和对话生成。
长期以来,用于研究NLP问题的大多数方法都采用浅机器学习模型和耗时的手工制作特征。由于大多数的语言信息用稀疏表示(高维特征)表示,这导致诸如维数灾难之类的问题。然而,随着最近词嵌入(低维,分布式表征)的普及和成功,与传统的机器学习模型(如SVM或逻辑回归)相比,基于神经的模型在各种语言相关任务上取得了优异的成果。
分布式表征
如前所述,手工制作的特征主要用于模拟自然语言任务,直到神经网络的方法出现并解决了传统机器学习模型所面临的一些问题,如维数的灾难。
词嵌入: 分布向量,也称为词嵌入,基于所谓的分布假设-出现在类似语境中的单词具有相似的含义。Word嵌入是在任务上预先训练的,其目标是基于其上下文预测单词,通常使用浅层神经网络。下图说明了Bengio及其同事提出的神经语言模型 。
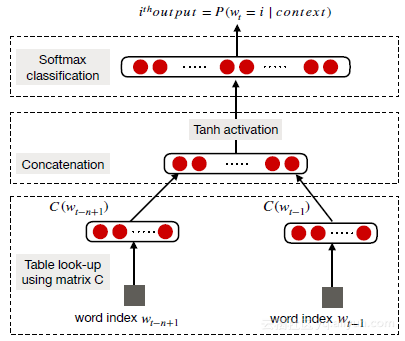
词向量倾向于嵌入语法和语义信息,并在各种NLP任务中负责SOTA,例如情感分析和句子组成。
分布式表征在过去被大量用于研究各种NLP任务,但是当连续的词袋(CBOW)和skip-gram模型被引入该领域时,它才开始流行起来。它们很受欢迎,因为它们可以有效地构建高质量的词嵌入,并且它们可以用于语义组合(例如,'man'+'royal'='king')。
Word2vec:2013年左右,Mikolav等人提出了CBOW和skip-gram模型。CBOW是构造词嵌入的神经网络方法,其目的是在给定上下文单词的情况下计算目标单词的条件概率。另一方面,Skip-gram是构建词嵌入的神经网络方法,其目标是在给定中心目标单词的情况下预测周围的上下文单词(即条件概率)。对于两种模型,通过计算(以无监督的方式)预测的准确性来确定单词嵌入维度。
使用词嵌入方法的挑战之一是当我们想要获得诸如“hot potato”或“Boston Globe”之类的短语的矢量表示时。我们不能简单地组合单个单词矢量表示,因为这些短语不代表单个单词的含义的组合。当考虑更长的短语和句子时,它会变得更加复杂。
word2vec模型的另一个限制是使用较小的窗口大小(window sizes)产生类似的嵌入,用于对比诸如“好”和“坏”之类的单词,这对于这种区分很重要的任务(例如情感分析)是不可取的。词嵌入的另一个限制是它们依赖于使用它们的应用程序,即为每个新任务重新训练任务特定的嵌入是一个探索的选项,但这通常是计算上昂贵的,并且可以使用负抽样更有效地解决。Word2vec模型还存在其他问题,例如没有考虑多义因素和其他可能从训练数据中浮现的偏见。
字符嵌入:对于诸如词性(POS)标记和命名实体识别(NER)之类的任务,查看单词中的形态信息(例如字符或其组合)是有用的。这对于形式丰富的语言也很有用,例如葡萄牙语,西班牙语和中文。由于我们在字符级别分析文本,因此这些类型的嵌入有助于处理未知单词问题,因为我们不再表示需要为了高效计算目的而需要减少的大词汇表。
最后,重要的是要理解即使字符级和字级嵌入都已成功应用于各种NLP任务,但长期影响仍受到质疑。例如,Lucy和Gauthier最近发现,词向量受限于它们如何很好地捕捉单词背后的概念意义的不同方面。换句话说,他们声称只有分布式语义不能用于理解单词背后的概念。最近,在自然语言处理系统的背景下,对意义表征进行了重要的辩论。
卷积神经网络(CNN)
CNN基本上是基于神经网络的方法,其应用于构成单词或n-gram以提取更高级特征的特征函数。由此产生的抽象特征已被有效地用于情感分析,机器翻译和问答(QA)系统,以及其他任务。Collobert和Weston是首批将基于CNN的框架应用于NLP任务的研究人员之一。他们的方法的目标是通过查找表将词转换为矢量表示,这使得一种原始的词嵌入方法,可以在神经网络训练期间学习权重(见下图)。
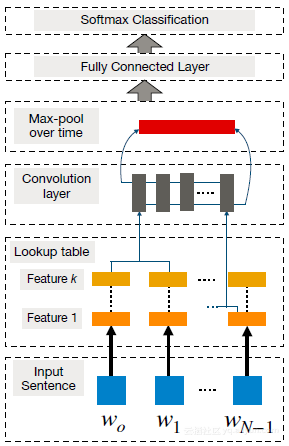
为了利用基本的CNN进行句子建模,首先要先将句子标记为单词,进一步将其转换为d 维的词嵌入矩阵(即输入嵌入层)。然后,在该输入嵌入层上应用卷积滤波器,其包括应用所有可能窗口大小(window size)的滤波器以产生所谓的特征映射。然后进行最大池操作,对每个过滤器应用最大操作以获得固定长度输出并减小输出的维数,并且该过程产生最终句子表征。
通过增加上述基本的CNN的复杂性并使其适应于执行基于词的预测,可以研究诸如NER,物体检测和POS(词性标记)的其他NLP任务。这需要基于窗口(window)的方法,其中对于每个单词,考虑相邻单词(句子)的固定大小窗口。然后将独立的CNN应用于句子中,并且训练目标是预测窗口中心的单词,也称为单词级分类。
CNNs的一个缺点是无法建模-长距离依赖关系,这对于各种NLP任务很重要。为了解决这个问题,CNN已经与时间延迟神经网络(TDNN)耦合,后者在训练期间可以立即实现更大的上下文范围。在不同的NLP任务中表现成功的其他有用类型的CNN,例如情绪预测和问题类型分类,被称为动态卷积神经网络(DCNN)。DCNN使用动态k-max池策略,其中过滤器可以在执行句子建模时动态地跨越可变范围。
CNN还用于更复杂的任务,对于不同长度的文本,例如物体检测,情感分析,短文本分类和讽刺检测。然而,其中一些研究报告说,在将基于CNN的方法应用于Twitter文本等微观文本时,外部知识是必要的。证明CNN有用的其他任务是查询-文档匹配,语音识别,机器翻译和问答等。另一方面,DCNN被用于分层学习捕获并将低级词汇特征组合成用于文本的自动概括的高级语义概念。
总体而言,CNN是有效的,因为它们可以在上下文窗口中挖掘语义线索,但是它们难以保持连续顺序和模拟远距离的上下文信息。RNN更适合这种类型的学习,接下来将对它们进行讨论。
递归神经网络(RNN)
RNN是专门用于处理顺序信息的神经网络的方法。RNN将计算应用于以先前计算结果为条件的输入序列。这些序列通常由固定大小的标记向量表示,他们被顺序送至循环单元。下图说明了一个简单的RNN框架。
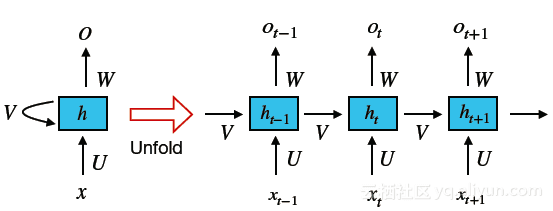
RNN的主要优势在于能够记忆先前的计算结果并在当前计算中使用该信息。这使得RNN模型适合于在任意长度的输入中都具有上下文依赖性,这样可以为输入创建适当的组合。RNN已被用于研究各种NLP任务,例如机器翻译、图像字幕和语言建模等。
与CNN模型相比,RNN模型在特定的自然语言任务中可以同样有效甚至更好。因为它们模拟了数据不同的方面,这才会使它们有效,具体的效果取决于任务所需的语义。
RNN期望的输入通常是单热(one-hot)编码或词嵌入,但在某些情况下,它们与由CNN模型构造的抽象表征耦合。简单的RNN容易遭受消失的梯度问题,这使得网络难以学习和调整较早层中的参数。其他变体正在出现已解决这个问题,例如长短期记忆(LSTM)网络,残留网络(ResNets)和门控循环网络(GRU)后来被引入以克服这一限制。
RNN变体
LSTM由三个门(输入,遗忘和输出门)组成,并通过三者的组合计算隐藏状态。GRU类似于LSTM,但只包含两个门,效率更高,因为它们不那么复杂。一项研究表明,很难说RNN哪些门控更有效,通常只是根据可用的计算能力来挑选它们。研究及实验表明各种基于LSTM的模型用于序列到序列映射(通过编码器-解码器框架),其适用于机器翻译,文本摘要,人工对话建模,问题回答,基于图像的语言生成以及其他任务。
总的来说,RNN可以用于许多NLP系统,例如:
• 字级分类(NER);
• 语言建模;
• 句子级别分类(例如,情感极性);
• 语义匹配(例如,将消息与对话系统中的候选响应相匹配);
• 自然语言生成(例如,机器翻译,视觉QA和图像字幕);
注意力机制
本质上,注意力机制是一种技术,其受益于允许上述基于RNN框架的解码器使用最后隐藏状态以及基于输入隐藏状态序列计算的信息(即上下文矢量)的需要。这对于需要在输入和输出文本之间进行某些对齐的任务特别有用。
注意力机制已成功用于机器翻译,文本摘要,图像字幕,对话生成和基于内容(aspect-based)的情感分析。并且已经有人提出了各种不同形式和类型的注意力机制,它们仍然是NLP研究人员研究各种应用的重要领域。
递归神经网络(Recursive Neural Network)
与RNN类似,递归神经网络是对连续数据建模非常适用。这是因为语言可以被视为递归结构,其中单词和短语构成层次结构中其他更高级别的短语。在这种结构中,非终端节点由其所有子节点的表示来表示。下图说明了下面的一个简单的递归神经网络。
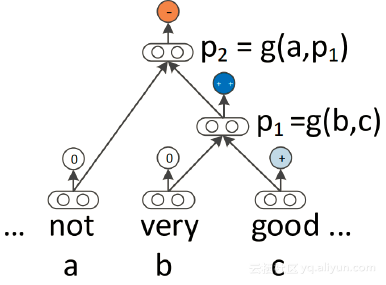
在基本递归神经网络形式中,组合函数(即网络)以自下而上的方法组合成分来计算更高级别短语的表示(参见上图)。在变体MV-RNN中,单词由矩阵和向量表示,这意味着由网络学习的参数表示每个成分的矩阵。另一种变型,即递归神经张量网络(RNTN),使得输入矢量之间的更多交互能够避免大的参数产生,如MV-RNN的情况。递归神经网络更能显示出灵活性,并且它们可以与LSTM单元耦合以处理诸如梯度消失之类的问题。
递归神经网络用于各种应用,例如:
• 解析;
• 利用短语级表示来进行情绪分析;
• 语义关系分类(例如,主题消息);
• 句子相关性;
强化学习
强化学习是通过机器学习的方法,训练代理执行离散动作,然后奖励。正在通过强化学习来研究几种自然语言生成(NLG)任务,例如文本摘要。
强化学习在NLP上的应用受到一些问题的阻力。当使用基于RNN的发生器时,标准答案会被模型生成的答案所取代,这会迅速提升错误率。此外,对于这样的模型,词级训练的目标不同于测试度量的目标,例如用于机器翻译和对话系统的n-gram重叠测量,BLEU。由于这种差异,当前的NLG类型系统往往会产生不连贯,重复和枯燥的信息。
为了解决上述问题,业内采用称为REINFORCE的强化算法来解决NLP任务,例如图像字幕和机器翻译。这个强化学习框架由一个代理(基于RNN的生成模型)组成,它与外部环境相互作用(在每个时间步骤看到的输入词和上下文向量)。代理根据策略(参数)选择一个动作,该策略会在每个时间步骤预测序列的下一个单词。然后代理会更新其内部状态(RNN的隐藏单元)。这一直持续到达最终计算奖励序列的结尾。奖励功能因任务而异,例如,在句子生成任务中,奖励可以是信息流。
尽管强化学习方法显示出了希望,但它们需要适当地处理动作和状态空间,这可能限制模型的表达能力和学习能力。记住,独立的基于RNN的模型力求表现力和表达语言的自然能力。
对抗训练也被用来训练语言生成器,其目的是欺骗训练有素的鉴别器,以区分生成的序列和真实的序列。如果一个对话系统,通过policy gradient(策略网络),可以在强化学习范例下构建任务,其中鉴别器就像人类图灵测试员一样,鉴别器基本上是受过训练以区分人类和机器生成的对话。
无监督学习
无监督的句子表征学习涉及以无监督的方式将句子映射到固定大小的向量。分布式表征从语言中捕获语义和句法属性,并使用辅助任务进行训练。
研究员与用于学习词嵌入的算法类似,提出了跳过思维模型,其中任务是基于中心句子预测下一个相邻句子。使用seq2seq框架训练该模型,其中解码器生成目标序列,并且编码器被视为通用特征提取器-甚至在该过程中学习了字嵌入。该模型基本上学习输入句子的分布式表征,类似于在先前语言建模技术中如何为每个单词学习词嵌入。
深度生成模型
诸如变分自动控制器(VAE)和生成对抗网络(GAN)之类的深度生成模型也可以应用于NLP中,通过从潜在代码空间生成逼真句子的过程来发现自然语言中的丰富结构。
众所周知,由于无约束的潜在空间,标准的自动编码器无法生成逼真的句子。VAE在隐藏的潜在空间上施加先验分布,使模型能够生成适当的样本。VAE由编码器和发生器网络组成,编码器和发生器网络将输入编码到潜在空间中,然后从潜在空间生成样本。训练目标是在生成模型下最大化观测数据的对数似然的变分下界。下图说明了用于句子生成的基于RNN的VAE。
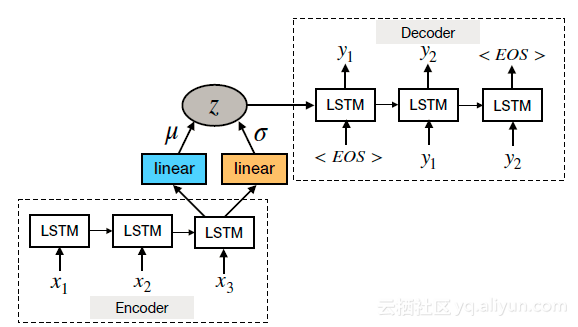
生成模型对于许多NLP任务是有用的,并且它们本质上是灵活的。例如,与标准自动编码器相比,基于RNN的VAE生成模型被提出用于产生更多样化且格式良好的句子。其他模型允许将结构化变量(例如,时态和情感)结合到潜在代码中以生成合理的句子。
由两个竞争网络组成的GAN(生成器和鉴别器)也被用于生成逼真的文本。例如,将LSTM用作生成器,CNN用作区分真实数据和生成样本的鉴别器。在这种情况下,CNN表示二进制句子分类器。该模型能够在对抗训练后生成逼真的文本。
除了鉴别器的梯度不能通过离散变量适当地反向传播的问题之外,深层生成模型同时也是难以评估的。近年来已经提出了许多解决方案,但这些解决方案尚未标准化。
内存增强网络(Memory-Augmented Network)
在输出结果生成阶段由注意力机制访问的隐藏向量表示模型的“内部存储器”。神经网络还可以与某种形式的内存耦合,以解决视觉QA,语言建模,POS标记和情感分析等任务。例如,为了解决QA任务,将支持事实或常识知识作为存储器的形式提供给模型。动态存储器网络是对先前基于存储器的模型的改进,其采用神经网络模型用于输入表征、注意力机制和应答机制。
结论
到目前为止,我们现在已经知道了基于神经网络的模型(如CNN和RNN)的容量和有效性。我们也意识到将强化学习、无监督方法和深度生成模型正在被应用于复杂的NLP任务(如可视化QA和机器翻译)。注意力机制和记忆增强网络在扩展基于神经的NLP模型的能力方面是强大的。结合这些强大的技术,我们相信会找到令人信服的方法来处理语言的复杂性。
本文作者:【方向】
作者:阿里云云栖社区
链接:https://www.jianshu.com/p/f1e6c888479d
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
NLP&深度学习:近期趋势概述的更多相关文章
- 自然语言处理(NLP)入门学习资源清单
Melanie Tosik目前就职于旅游搜索公司WayBlazer,她的工作内容是通过自然语言请求来生产个性化旅游推荐路线.回顾她的学习历程,她为期望入门自然语言处理的初学者列出了一份学习资源清单. ...
- 模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理.分类及应用 lqfarmer 深度学习研究员.欢迎扫描头像二维码,获取更多精彩内容. 946 人赞同了该文章 Atte ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 【转】贾扬清:希望Caffe成为深度学习领域的Hadoop
[转:http://www.csdn.net/article/2015-07-07/2825150] 在深度学习(Deep Learning)的热潮下,Caffe作为一个高效.实用的深度学习框架受到了 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 学习笔记DL002:AI、机器学习、表示学习、深度学习,第一次大衰退
AI早期成就,相对朴素形式化环境,不要求世界知识.如IBM深蓝(Deep Blue)国际象棋系统,1997,击败世界冠军Garry Kasparov(Hsu,2002).国际象棋,简单领域,64个位置 ...
- NLP+词法系列(二)︱中文分词技术简述、深度学习分词实践(CIPS2016、超多案例)
摘录自:CIPS2016 中文信息处理报告<第一章 词法和句法分析研究进展.现状及趋势>P4 CIPS2016 中文信息处理报告下载链接:http://cips-upload.bj.bce ...
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
- 回望2017,基于深度学习的NLP研究大盘点
回望2017,基于深度学习的NLP研究大盘点 雷锋网 百家号01-0110:31 雷锋网 AI 科技评论按:本文是一篇发布于 tryolabs 的文章,作者 Javier Couto 针对 2017 ...
随机推荐
- Bugly 多渠道热更新解决方案
作者:巫文杰 Gradle使用productFlavors打渠道包的痛 有很多同学可能会采用配置productFlavors来打渠道包,主要是它是原生支持,方便开发者输出不同定制版本的apk,举个例子 ...
- [Swift]LeetCode654. 最大二叉树 | Maximum Binary Tree
Given an integer array with no duplicates. A maximum tree building on this array is defined as follo ...
- [Swift]LeetCode1027. 最长等差数列 | Longest Arithmetic Sequence
Given an array A of integers, return the length of the longest arithmetic subsequence in A. Recall t ...
- Mac下安装配置Python2和Python3并相互切换使用
mac os 以前没有使用过,这次使用了一把,的确还是比较不顺手的,估计从今以后,就要把平台逐渐切换到mac了.今后好的文章,专门会开一个macos专栏,专门记录macos的使用过程中的心得,体会,以 ...
- 像素数据YUV简介与觉存储格式介绍
主要学习链接:博客园.51CTO 前言 照例是先废话几句,下面的内容都是在学习时从网上找来的,并非我原创,我之所以要写这篇笔记是因为网的内容都很分散,找的时候要从各个地方看,很不方便,所以就自己总结了 ...
- Python档案袋( Socket 与 ScoketServer 通信 )
Socket有一个缓冲区,缓冲区是一个流,先进先出,发送和取出的可自定义大小的,如果取出的数据未取完缓冲区,则可能存在数据怠慢.其中[recv(1024)]表示从缓冲区里取最大为1024个字节,但实际 ...
- J2EE-tomcat的配置
修改web.xml文件里面的内容: 路径:D:\software\apache-tomcat-8.0.44\webapps\ROOT\WEB-INF\web.xml: 内容:<?xml ver ...
- Java IO 导入导出TXT文件
字节流和字符流 区别: 读写单位:顾名思义,字节流以字节(byte)为读写单位,而字符流以字符为读写单位,根据码表映射字符,一次可能读入多个字符. 处理对象:字节流可以处理所有类型的数据(包括图片等) ...
- Python 创建递归文件夹
# 创建递归文件夹 def createfiles(filepathname): try: os.makedirs(filepathname) except Exception as err: pri ...
- 前两天做项目遇到了sqlserver最大连接数 Max Pool Size 的问题
前言:出现这种问题使因为程序对connection的回收出现了问题,是因为你的代码出出现了过多new connection(),这种情况还是你的代码问题,如果不想把问题归根于程序,那你就可以改变con ...