【Spark篇】---Spark中transformations算子二
一、前述
今天继续整理几个Transformation算子如下:
- mapPartitionWithIndex
- repartition
- coalesce
- groupByKey
- zip
- zipWithIndex
二、具体细节
- mapPartitionWithIndex
类似于mapPartitions,除此之外还会携带分区的索引值。
java代码:
package com.spark.spark.transformations; import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2; public class Operator_mapPartitionWithIndex {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("mapPartitionWithIndex");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> names = Arrays.asList("zhangsan1", "zhangsan2", "zhangsan3","zhangsan4"); /**
* 这里的第二个参数是设置并行度,也是RDD的分区数,并行度理论上来说设置大小为core的2~3倍
*/
JavaRDD<String> parallelize = sc.parallelize(names, 3);
JavaRDD<String> mapPartitionsWithIndex = parallelize.mapPartitionsWithIndex(
new Function2<Integer, Iterator<String>, Iterator<String>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
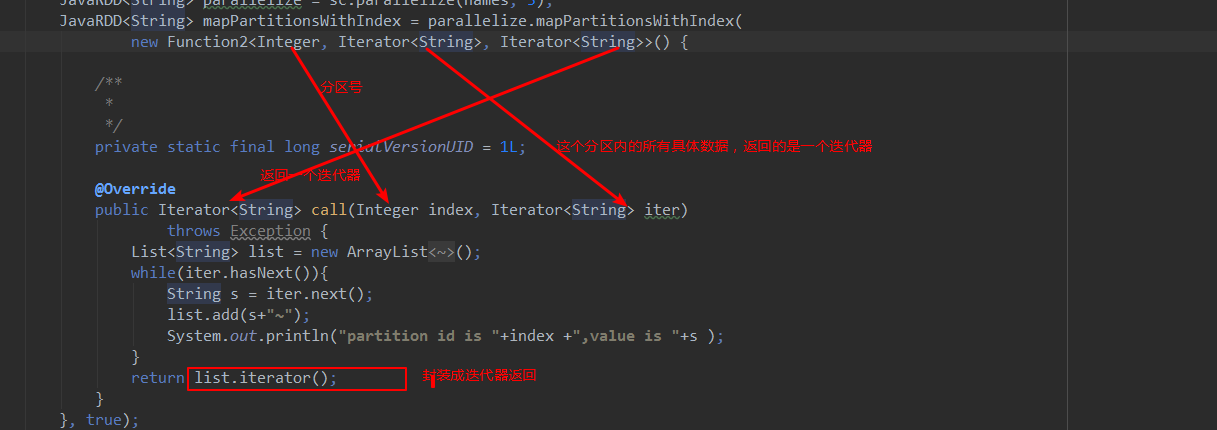
public Iterator<String> call(Integer index, Iterator<String> iter)
throws Exception {
List<String> list = new ArrayList<String>();
while(iter.hasNext()){
String s = iter.next();
list.add(s+"~");
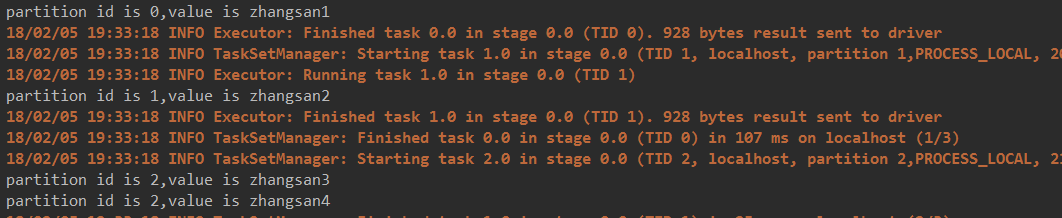
System.out.println("partition id is "+index +",value is "+s );
}
return list.iterator();
}
}, true);
mapPartitionsWithIndex.collect();
sc.stop();
}
}
scala代码:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import scala.collection.mutable.ListBuffer object Operator_mapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("mapPartitionsWithIndex")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List("a","b","c"),3)
rdd.mapPartitionsWithIndex((index,iter)=>{
val list = ListBuffer[String]()
while(iter.hasNext){
val v = iter.next()
list.+(v)
println("index = "+index+" , value = "+v)
}
list.iterator
}, true).foreach(println)
sc.stop(); }
}
代码解释:
结果:
- coalesce
coalesce常用来减少分区,第二个参数是减少分区的过程中是否产生shuffle。
true为产生shuffle,false不产生shuffle。默认是false。
如果coalesce设置的分区数比原来的RDD的分区数还多的话,第二个参数设置为false不会起作用,如果设置成true,效果和repartition一样。即repartition(numPartitions) = coalesce(numPartitions,true)
java代码:
package com.spark.spark.transformations; import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
/**
* coalesce减少分区
* 第二个参数是减少分区的过程中是否产生shuffle,true是产生shuffle,false是不产生shuffle,默认是false.
* 如果coalesce的分区数比原来的分区数还多,第二个参数设置false,即不产生shuffle,不会起作用。
* 如果第二个参数设置成true则效果和repartition一样,即coalesce(numPartitions,true) = repartition(numPartitions)
*
* @author root
*
*/
public class Operator_coalesce {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("coalesce");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> list = Arrays.asList(
"love1","love2","love3",
"love4","love5","love6",
"love7","love8","love9",
"love10","love11","love12"
); JavaRDD<String> rdd1 = sc.parallelize(list,3);
JavaRDD<String> rdd2 = rdd1.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>(){ /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterator<String> call(Integer partitionId, Iterator<String> iter)
throws Exception {
List<String> list = new ArrayList<String>();
while(iter.hasNext()){
list.add("RDD1的分区索引:ll【"+partitionId+"】,值为:"+iter.next());
}
return list.iterator();
} }, true);
JavaRDD<String> coalesceRDD = rdd2.coalesce(2, false);//不产生shuffle
//JavaRDD<String> coalesceRDD = rdd2.coalesce(2, true);//产生shuffle //JavaRDD<String> coalesceRDD = rdd2.coalesce(4,false);//设置分区数大于原RDD的分区数且不产生shuffle,不起作用
// System.out.println("coalesceRDD partitions length = "+coalesceRDD.partitions().size()); //JavaRDD<String> coalesceRDD = rdd2.coalesce(5,true);//设置分区数大于原RDD的分区数且产生shuffle,相当于repartition
// JavaRDD<String> coalesceRDD = rdd2.repartition(4);
JavaRDD<String> result = coalesceRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>(){ /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterator<String> call(Integer partitionId, Iterator<String> iter)
throws Exception {
List<String> list = new ArrayList<String>();
while(iter.hasNext()){
list.add("coalesceRDD的分区索引:【"+partitionId+"】,值为: "+iter.next()); }
return list.iterator();
} }, true);
for(String s: result.collect()){
System.out.println(s);
}
sc.stop();
}
}
scala代码:
package com.bjsxt.spark.transformations import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ListBuffer object Operator_repartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("repartition")
val sc = new SparkContext(conf) val rdd1 = sc.makeRDD(List(1,2,3,4,5,6,7),3)
val rdd2 = rdd1.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = new ListBuffer[String]()
while(iter.hasNext){
list += "rdd1partitionIndex : "+partitionIndex+",value :"+iter.next()
}
list.iterator
}) rdd2.foreach{ println } val rdd3 = rdd2.repartition(4)
val result = rdd3.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = ListBuffer[String]()
while(iter.hasNext){
list +=("repartitionIndex : "+partitionIndex+",value :"+iter.next())
}
list.iterator
})
result.foreach{ println} sc.stop()
}
}
代码解释:
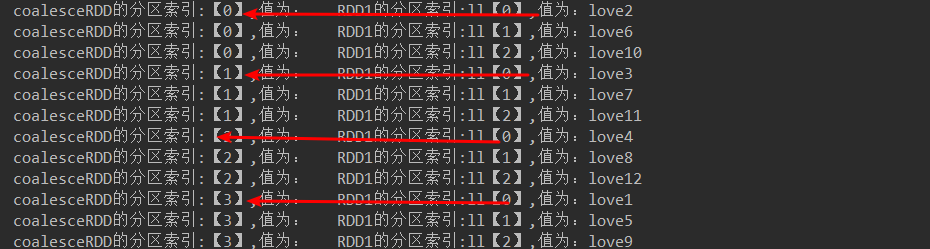
JavaRDD<String> coalesceRDD = rdd2.coalesce(2, true);//产生shuffle
代码结果:
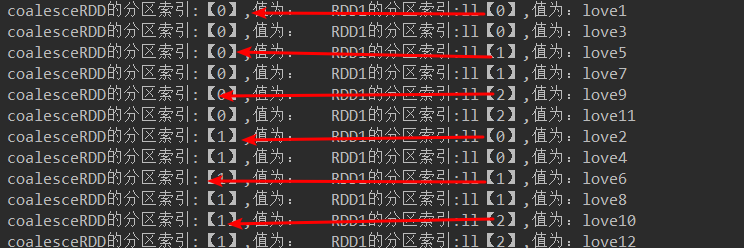
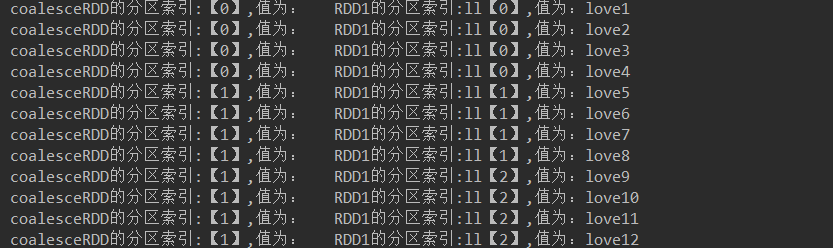
JavaRDD<String> coalesceRDD = rdd2.coalesce(2, false);//不产生shuffle
代码解释:
代码结果:
JavaRDD<String> coalesceRDD = rdd2.coalesce(4,false);//设置分区数大于原RDD的分区数且不产生shuffle,不起作用
代码结果:
JavaRDD<String> coalesceRDD = rdd2.coalesce(4,true);//设置分区数大于原RDD的分区数且产生shuffle,相当于repartition
代码结果:
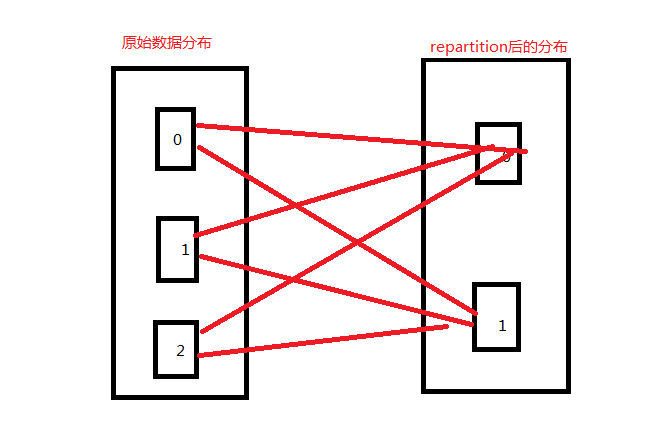
- repartition
增加或减少分区。会产生shuffle。(多个分区分到一个分区不会产生shuffle)
java代码
package com.spark.spark.transformations; import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
/**
* repartition
* 减少或者增多分区,会产生shuffle.(多个分区分到一个分区中不会产生shuffle)
* @author root
*
*/
public class Operator_repartition { public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("coalesce");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> list = Arrays.asList(
"love1","love2","love3",
"love4","love5","love6",
"love7","love8","love9",
"love10","love11","love12"
); JavaRDD<String> rdd1 = sc.parallelize(list,3);
JavaRDD<String> rdd2 = rdd1.mapPartitionsWithIndex(
new Function2<Integer, Iterator<String>, Iterator<String>>(){ /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterator<String> call(Integer partitionId, Iterator<String> iter)
throws Exception {
List<String> list = new ArrayList<String>();
while(iter.hasNext()){
list.add("RDD1的分区索引:【"+partitionId+"】,值为:"+iter.next());
}
return list.iterator();
} }, true);
// JavaRDD<String> repartitionRDD = rdd2.repartition(1);
JavaRDD<String> repartitionRDD = rdd2.repartition(2);
// JavaRDD<String> repartitionRDD = rdd2.repartition(6);
JavaRDD<String> result = repartitionRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>(){ /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterator<String> call(Integer partitionId, Iterator<String> iter)
throws Exception {
List<String> list = new ArrayList<String>();
while(iter.hasNext()){
list.add("repartitionRDD的分区索引:【"+partitionId+"】,值为: "+iter.next()); }
return list.iterator();
} }, true);
for(String s: result.collect()){
System.out.println(s);
}
sc.stop();
} }
scala代码:
package com.bjsxt.spark.transformations import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ListBuffer object Operator_repartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("repartition")
val sc = new SparkContext(conf) val rdd1 = sc.makeRDD(List(1,2,3,4,5,6,7),3)
val rdd2 = rdd1.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = new ListBuffer[String]()
while(iter.hasNext){
list += "rdd1partitionIndex : "+partitionIndex+",value :"+iter.next()
}
list.iterator
}) rdd2.foreach{ println } val rdd3 = rdd2.repartition(4)
val result = rdd3.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = ListBuffer[String]()
while(iter.hasNext){
list +=("repartitionIndex : "+partitionIndex+",value :"+iter.next())
}
list.iterator
})
result.foreach{ println} sc.stop()
}
}
代码解释:
JavaRDD<String> repartitionRDD = rdd2.repartition(2);
代码结果: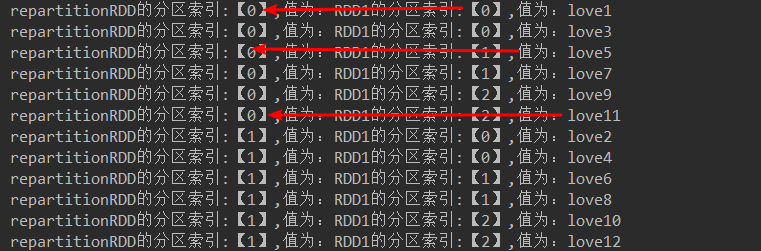
JavaRDD<String> repartitionRDD = rdd2.repartition(1);//不产生shuffle 代码结果:
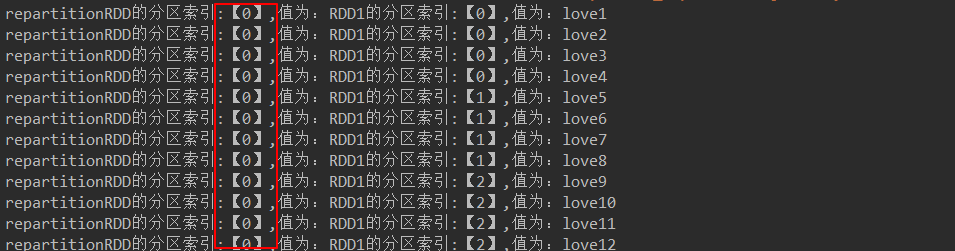
- groupByKey(是一个transformation算子注意和reducebykey区分)
作用在K,V格式的RDD上。根据Key进行分组。作用在(K,V),返回(K,Iterable <V>)。
java代码:
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_groupByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("groupByKey");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD<String, Integer> parallelizePairs = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,Integer>("a", 1),
new Tuple2<String,Integer>("a", 2),
new Tuple2<String,Integer>("b", 3),
new Tuple2<String,Integer>("c", 4),
new Tuple2<String,Integer>("d", 5),
new Tuple2<String,Integer>("d", 6)
)); JavaPairRDD<String, Iterable<Integer>> groupByKey = parallelizePairs.groupByKey();
groupByKey.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Iterable<Integer>> t) throws Exception {
System.out.println(t);
}
}); }
}
scala代码:
package com.bjsxt.spark.transformations import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object Operator_groupByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("groupByKey")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Array(
(1,"a"),
(1,"b"),
(2,"c"),
(3,"d")
)) val result = rdd1.groupByKey()
result.foreach(println)
sc.stop()
}
}
代码结果:

- zip
将两个RDD中的元素(KV格式/非KV格式)变成一个KV格式的RDD,两个RDD的个数必须相同。
java代码:
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_zip {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("zip");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> nameRDD = sc.parallelize(Arrays.asList("zhangsan","lisi","wangwu"));
JavaRDD<Integer> scoreRDD = sc.parallelize(Arrays.asList(100,200,300));
// JavaRDD<Integer> scoreRDD = sc.parallelize(Arrays.asList(100,200,300,400));
JavaPairRDD<String, Integer> zip = nameRDD.zip(scoreRDD);
zip.foreach(new VoidFunction<Tuple2<String,Integer>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println("tuple --- " + tuple);
}
}); // JavaPairRDD<String, String> parallelizePairs = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String, String >("a","aaa"),
// new Tuple2<String, String >("b","bbb"),
// new Tuple2<String, String >("c","ccc")
// ));
// JavaPairRDD<String, String> parallelizePairs1 = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String, String >("1","111"),
// new Tuple2<String, String >("2","222"),
// new Tuple2<String, String >("3","333")
// ));
// JavaPairRDD<Tuple2<String, String>, Tuple2<String, String>> result = parallelizePairs.zip(parallelizePairs1); sc.stop();
}
}
scala代码:
package com.bjsxt.spark.transformations import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* 将两个RDD中的元素(KV格式/非KV格式)变成一个KV格式的RDD,两个RDD的个数必须相同。
*/
object Operator_zip {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("zip").setMaster("local")
val sc = new SparkContext(conf)
val nameRDD = sc.makeRDD(Array("zhangsan","lisi","wangwu"))
val scoreRDD = sc.parallelize(Array(1,2,3))
val result = nameRDD.zip(scoreRDD)
result.foreach(println)
sc.stop() }
}
结果:

- zipWithIndex
该函数将RDD中的元素和这个元素在RDD中的索引号(从0开始)组合成(K,V)对。
java代码:
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2;
/**
* zipWithIndex 会将RDD中的元素和这个元素在RDD中的索引号(从0开始) 组合成(K,V)对
* @author root
*
*/
public class Operator_zipWithIndex {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("zipWithIndex");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> nameRDD = sc.parallelize(Arrays.asList("zhangsan","lisi","wangwu"));
JavaPairRDD<String, Long> zipWithIndex = nameRDD.zipWithIndex();
zipWithIndex.foreach(new VoidFunction<Tuple2<String,Long>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Long> t) throws Exception {
System.out.println("t ---- "+ t);
}
});
// JavaPairRDD<String, String> parallelizePairs = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String, String >("a","aaa"),
// new Tuple2<String, String >("b","bbb"),
// new Tuple2<String, String >("c","ccc")
// ));
// JavaPairRDD<Tuple2<String, String>, Long> zipWithIndex2 = parallelizePairs.zipWithIndex();
// zipWithIndex2.foreach(new VoidFunction<Tuple2<Tuple2<String,String>,Long>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Tuple2<Tuple2<String, String>, Long> t)
// throws Exception {
// System.out.println(" t ----" + t);
// }
// });
sc.stop();
} }
scala代码:
package com.bjsxt.spark.transformations import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* 该函数将RDD中的元素和这个元素在RDD中的索引号(从0开始)组合成(K,V)对
*/
object zipWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("zipWithIndex")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))
val result = rdd1.zipWithIndex()
result.foreach(println)
sc.stop() }
}
代码结果:
java结果:

scala结果:

【Spark篇】---Spark中transformations算子二的更多相关文章
- 【Spark篇】---Spark中控制算子
一.前述 Spark中控制算子也是懒执行的,需要Action算子触发才能执行,主要是为了对数据进行缓存. 控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化 ...
- 【Spark篇】---SparkStreaming中算子中OutPutOperator类算子
一.前述 SparkStreaming中的算子分为两类,一类是Transformation类算子,一类是OutPutOperator类算子. Transformation类算子updateStateB ...
- 【Spark篇】---SparkStreaming算子操作transform和updateStateByKey
一.前述 今天分享一篇SparkStreaming常用的算子transform和updateStateByKey. 可以通过transform算子,对Dstream做RDD到RDD的任意操作.其实就是 ...
- 【Spark篇】---Spark中广播变量和累加器
一.前述 Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量. 累机器相当于统筹大变量,常用于计数,统计. 二.具体原理 ...
- 【转帖】HBase读写的几种方式(二)spark篇
HBase读写的几种方式(二)spark篇 https://www.cnblogs.com/swordfall/p/10517177.html 分类: HBase undefined 1. HBase ...
- HBase读写的几种方式(二)spark篇
1. HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一 ...
- 【Spark篇】---Spark中Master-HA和historyServer的搭建和应用
一.前述 本节讲述Spark Master的HA的搭建,为的是防止单点故障. Spark-UI 的使用介绍,可以更好的监控Spark应用程序的执行. 二.具体细节 1.Master HA 1.Mast ...
- Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏)
RDD算子调优 不废话,直接进入正题! 1. RDD复用 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示: 对上图中的RDD计算架构进行修改,得到如下图所示的优 ...
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
随机推荐
- 如何优化UI布局?
Android系统中填充布局是一个开销巨大的过程,每一个额外的嵌套布局和包含的View,都直接影响到应用程序的性能和响应能力.为了使应用程序流畅地运行和快速地响应,重要的是尽可能地保持布局的简单和避免 ...
- sudo命令详解
语法 sudo(选项)(参数) 选项 选项 说明 -b 在后台执行指令: -h 显示帮助: -H 将HOME环境变量设为新身份的HOME环境变量: -k 结束密码的有效期限,也就是下次再执行sudo时 ...
- 20181115 python-第一章学习小结part4
python第一章 流程控制 单分枝任务 If 条件: 满足条件执行动作 注意if下面的缩进,建议直接使用tab键,4个空格太难输入. 双分枝任务 If 条件: 满足条件执行动作 else: 条件 ...
- 微信跳转技术,浏览器唤起微信,weixin://dl/business/?ticket=
weixin://dl/business/?ticket= 到底怎么生成的?调用以下接口 weixin://dl/scan 扫一扫weixin://dl/feedback 反馈weixin://dl ...
- CSS水平垂直居中!
总结一下,最经典的面试题 分两种情况,宽高确定和不定宽高 (一)宽高确定 初始条件如下: 1. 绝对定位 + 负margin 里面的盒子相对于父盒子绝对定位,距离上面和左边分别为50%,此处的50%是 ...
- 关于H5的一些杂思细想(一)
作为一名前端程序媛,虽然整天和代码打交道,但是还是有一颗小清新的内心,虽然有时候加起班来不是人,但是空闲的时候还是会整理一下思绪,顺便整理一下自己,两个多月的加班,一直没有更新,今天就把自己最近做的一 ...
- 【PHP版】火星坐标系 (GCJ-02) 与百度坐标系 (BD-09ll)转换算法
首先感谢java版作者@宋宋宋伟,java版我是看http://blog.csdn.net/coolypf/article/details/8569813 然后根据java代码修改成了php代码. & ...
- for循环:用turtle画一颗五角星
import turtle # 设置初始位置 turtle.penup() turtle.left(90) turtle.fd(200) turtle.pendown() turtle.right(9 ...
- SVN搭建外网远程访问
准备条件 SVN服务器安装及配置 SVN服务端,客户端安装配置可以参考:http://www.cnblogs.com/mq0036/p/5250198.html 花生壳客户端下载,安装,注册(内网穿透 ...
- UVALive 2474 Balloons in a Box(枚举)
https://vjudge.net/contest/277824#problem/A 尤其是模拟题,三思而后敲!!! 纠错了好久,主要还是没有处理好:单点若还未放气球,其他气球可以膨胀越过它(即可以 ...