第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np
x = np.random.randint(1,100,[20,1])
y = np.zeros(20)
k = 3
def initcenter(x,k):
return x[:k] kc = initcenter(x,k)
kc
def nearest(kc,i):
d=(abs(kc-i))
w=np.where(d==np.min(d))
return w[0][0] kc = initcenter(x,k)
nearest(kc,56)
def xclassify(x,y,kc):
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
return y kc = initcenter(x,k)
y = xclassify(x,y,kc)
print(kc,y)
def kcmean(x,y,kc,k):
l = list(kc)
flag = False
for c in range(k):
m = np.where(y == c)
n = np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True
print(l,flag)
return (np.array(l),flag) kc = initcenter(x,k)
flag = True
k = 3 while flag:
y = xclassify(x,y,kc)
kc,flag = kcmean(x,y,kc,k)
运行结果

二.鸢尾花花瓣长度数据做聚类并用散点图显示
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:,1]
y = np.zeros(150) def initcenter(x,k): #初始聚类中心数组
return x[0:k].reshape(k) def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc-i))
w = np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]): #对数组的每个值进行分类,shape[0]读取矩阵第一维度的长度
y[i] = nearest(kc,x[i])
return y def kcmean(x,y,kc,k): #计算各聚类新均值
l = list(kc)
flag = False
for c in range(k):
print(c)
m = np.where(y == c)
n=np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True #聚类中心发生变化
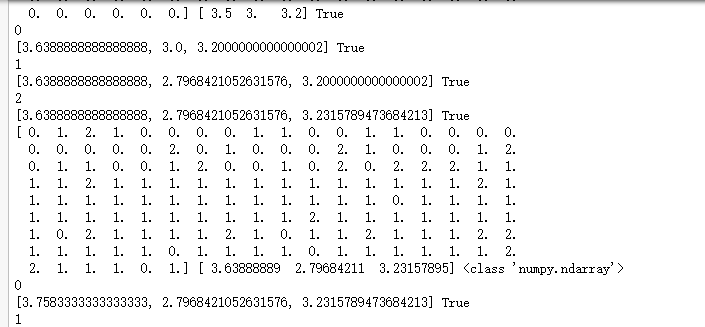
print(l,flag)
return (np.array(l),flag) k = 3
kc = initcenter(x,k) flag = True
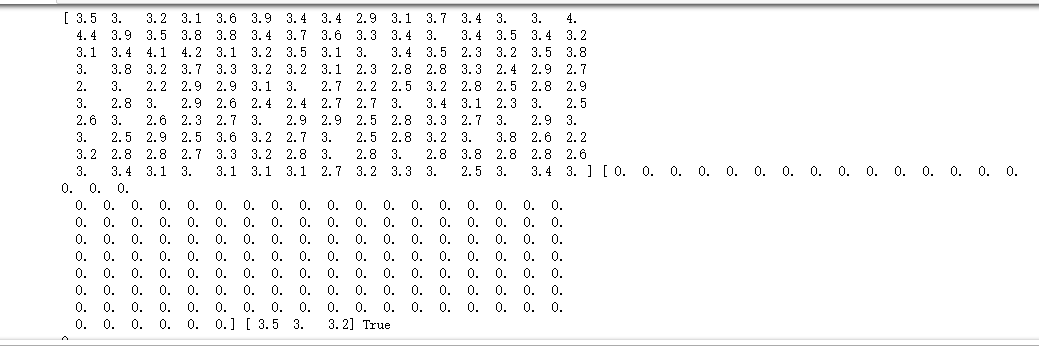
print(x,y,kc,flag) #判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2
while flag:
y = xclassify(x,y,kc)
kc, flag = kcmean(x,y,kc,k)
print(y,kc,type(kc)) print(x,y)
import matplotlib.pyplot as plt
plt.scatter(x,x,c=y,s=50,cmap="rainbow");
plt.show()
运行结果


第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用的更多相关文章
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
随机推荐
- c# linq lambda 去重,排序,取最高纪录。
----------------------------------------------------.对基础类型排序 方法一: 调用sort方法,如果需要降序,进行反转: List<int& ...
- 记录一下最近的解决的坑爹bug
最近解决的bug长得都很别致啊,记录一下 一 :天气插件引用报403 项目里有一个天气插件引用一直报403 后来确定原因是headers里缺少referer源,无法访问资源的服务器,再后来又发现项目引 ...
- 数据结构|-用C#实现一个简单的链表
我们知道C#中是没有链表的,我们可以自己实现一个 整个单链表能实现的功能有: 功能 方法 返回值 备注 获取链表长度 GetLength() int 返回值是链表长度 清空链表 Clear() voi ...
- spring cloud 初体验
spring cloud分为注册端.客户端以及消费端 初体验的理解就是: 注册端就是将之前所有的应用在这边进行注册,然后给每个应用都生成自己的标识,这些应用就是来自于客户端,消费端则通过调用注册端(有 ...
- google搜索引擎爬虫爬网站原理
google搜索引擎爬虫爬网站原理 一.总结 一句话总结:从几个大站开始,然后开始爬,根据页面中的link,不断爬 从几个大站开始,然后开始爬,根据页面中的link,不断加深爬 1.搜索引擎和数据库检 ...
- GT sport赛道详解 - Dragon Trail | 龙之径
参考:GT sport所有赛道简介 今天的心情变化挺大,从绝望放弃到豁然开朗. 前言:GT sport有个排位赛,是每位sim赛车手提升自己等级的唯一途径,其中一个排位赛就是龙之径II(逆时针跑),我 ...
- 【ERROR】ERROR: transport error 202: bind failed: Cannot assign requested address
异常信息: ERROR: transport error : bind failed: Cannot assign requested address ERROR: JDWP Transport dt ...
- hdu-1536 S-Nim SG函数
http://acm.hdu.edu.cn/showproblem.php?pid=1536 给出能够取的方法序列,然后求基本石子堆问题. 只要用S序列去做转移即可. 注意has初始化的一些技巧 #i ...
- 关于java类加载机制的一些理解
关于java的类加载机制加载顺序,这个东西可以说是基础的东西,不过很遗憾这方面很多人也都不是很在意,比如我自己,最近上班闲下来了,就开始看一些博客文章了,今天恰好被一篇博文给吸引了,并且他的示例题一开 ...
- jQuery的版本兼容问题
之前在做头像上传的时候,使用的jQuery是1.8.2的版本,然后头像上传做完后,发现项目用的jQuery版本是3.3.1的.由于两个版本的差距太大了.所以兼容很差. 3.3.1不支持剪切头像的某些函 ...