Django_URL
视图函数介绍
视图一般都写在app的views中,并且视图的第一个参数永远都是request(HttpRequest)对象。这个对象存储了请求过来的所有信息,包括携带的参数以及一些头部信息等。再视图中,一般完成逻辑相关的操作,比如这个请求是添加一篇博客,那么可以通过request来接收到这些数据,然后存储到数据库中,最后再把执行的结果返回给浏览器。
视图函数的返回结果必须是HttpResponseBase对象或者HttpResponseBase子类的对象。
django与flask传递参数区别:flask不需要传递这个request,是一个全局变量,django的request必须传递过来才能使用;
from django.http import HttpResponse def index(request):
return HttpResponse(u"花花")
URL映射
1.为什么回去urls.py文件中寻找映射呢?
因为在settings.py中配置了ROOT_URLCONF为urls.py:
ROOT_URLCONF = 'first.urls'
2.在urls.py中我们所有的映射都应该放在urlpatterns这个变量中
urlpatterns = [
path('admin/', admin.site.urls),
]
3.所有的映射不是随便写的,而是通过path函数或者re_path函数进行包装的。
path = partial(_path, Pattern=RoutePattern)
re_path = partial(_path, Pattern=RegexPattern)
4、默认首页映射查找
在没有写任何url映射时,django会给到一个默认的页面,如果一旦有映射其他url页面,就要写个视图函数,url映射到空字符串,给到一个首页;
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'',views.index),
]
URL中传递参数给视图函数
1、采用在url中使用变量的方式
在path的第一个参数中,使用<参数名>的方式可以传递参数。然后在视图函数中也要写一个参数,视图函数中的参数必须和url中的参数名称保持一致,不然就找不到这个参数。另外,url中可以传递多个参数
views.py
from django.http import HttpResponse def index(request):
return HttpResponse(u"花花首页") def book(request):
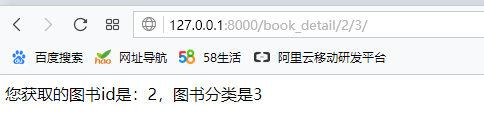
return HttpResponse("图书") def book_detail(request,book_id,category_id):
text = "您获取的图书id是:%s,图书分类是%s" % (book_id,category_id)
return HttpResponse(text)
urls.py
from django.contrib import admin
from django.urls import path,re_path
from cmdb import views urlpatterns = [
path('admin/', admin.site.urls),
path(r'',views.index),
path(r'book/',views.book),
path(r'book_detail/<book_id>/<category_id>/',views.book_detail),
]
结果:
2、采用查询字符串的方式
在url中,不需要单独的匹配查询字符串的部分。只需要在视图函数中使用request.GET.get('参数名称')的方式来获取。示例代码如下:
path('book_author/',views.author_detail),
def author_detail(request):
author_id = request.GET['id'] #request包括客户端和浏览器请求过来的所有数据
text = '作者的id是:%s' % author_id
return HttpResponse(text)
访问:http://127.0.0.1:8000/book_author/?id=2 即可将参数传递过去。
因为查询字符串使用的是`GET`请求,所以我们通过`request.GET`来获取参数。并且因为`GET`是一个类似于字典的数据类型,所有获取值跟字典的方式都是一样的。
django内置的URL转换器
1、如何限制参数类型:
可以使用django内置的url转换器(converters)。我们可以从converters包中了解所有的转换器,首先在urls.py中导入urls包引入转换器,(快速打开converters.py方法:写一行 "from django.urls import converters" 鼠标放在converters下ctrl+b)
from django.urls import converters
打开converters.py后可以了解到所有的转换器:
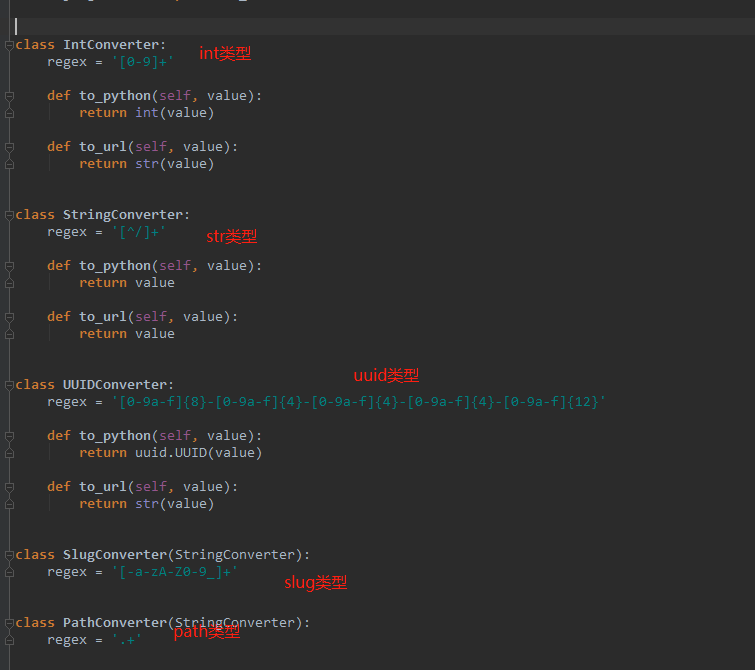
2、类型总结:
int类型:1个或者多个0-9的数字;
str类型:除了/其余都可以作为str类型,默认时str转换器;
uuid类型:uuid转换器具有唯一性,只满足uuid.uuid4()类型的 ,如:923c3f5f-edeb-4d2b-ac70-a99eb4425b0b(print(uuid.uuid4()));
slug类型:数字、大小写字母、-满足,其余不行;
path类型:str转换器不能有/ 而path转换器是可以包含任意字符的,包括/;
3、格式规范
只要在url,path中<参数名>前加格式类型即可
path(r'publisher_detail/<int:publisher_id>/',views.publisher_detail), #参数名前面加上格式类型 def publisher_detail(request,publisher_id):
text = '出版社的id是:%s' % (publisher_id)
return HttpResponse(text)
4、如何生成uuid?
进入python函数,uuid是python内置库
>>> import uuid
>>> print(uuid.uuid4())
74858df0-7b95-4366-ae6c-dc54aa9402c6 #自动生成uuid
>>>
url分层模块化
当项目越来越大,url也会变得越来越多。如果放在主"urls.py"文件中,将会不好管理。因此我们可以将每个app自己的urls放在自己的app中进行管理,一般我们会在app中新建一个urls.py文件用来存储所有和此app相关的url。
1、在app文件夹下新建一个urls.py文件,并写入相关app的urls,注意要import 视图函数
from django.urls import path
from . import views urlpatterns = [ path(r'',views.book),
path(r'detail/<book_id>/<category_id>/',views.book_detail),
path('author/',views.book_author),
path(r'publisher/<int:publisher_id>/',views.book_publisher), ##参数名前面加上格式类型
]
2、在主urls.py中调入app的url
from django.urls import path,include #导入include模块
path(r'',include('cmdb.urls')), #这边我写个空代表会找到urls表里的第一个path映射的view
path('book/',include('cmdb.urls')),
#url是会根据主 urls.py 和 app中的 urls.py 进行拼接,因此这边book加了'/',app中的拼接前面就不需要加'/'了
3、需要注意的地方:
1) url模块化是为了方便管理,即将每个APP中各建立自己的urls.py文件 。
2) 在项目下有一个总的urls.py文件,这个文件的主要作用是将每个APP去找各自的urls.py文件,在该文件中,应该使用include函数包含urls.py,且是相对于项目路径 。
3) 在APP中的urls.py文件,所有的匹配也应该放在urlpatterns中 。
4) 最终的url是根据主url.py和APP的url.py进行拼接的,因此,不可多加或少加/。
URL命名与反转URL
1.新建一个项目 在项目中创建cms和fomt两个app。
2. 在cms应用的views.py文件里输入如下代码:
from django.http import HttpResponse def index(request):
return HttpResponse('CMS首页') def login(request):
return HttpResponse('CMSlogin登录页面')
3. 在fomt应用的views.py文件里输入如下代码:
from django.http import HttpResponse def index(request):
return HttpResponse('前台首页') def login(request):
return HttpResponse('前台登录页面')
4. 在cms和fomt两个app里各创建一个urls.py文件,分别写下文件中代码如下:
from django.urls import path
from . import views urlpatterns = [
path('',views.index),
path('login/',views.login),
]
5. 在项目的urls.py文件中更新代码如下:
from django.urls import path,include urlpatterns = [
#path('admin/', admin.site.urls),
path('',include('fomt.urls')),
path('cms/',include('cms.urls')),
]
6. 实现url反转
调整fomt应用views.py里的代码,实现未登陆用户调转到登陆页面的功能。
调整后的代码如下:
from django.shortcuts import render
from django.http import HttpResponse
from django.shortcuts import redirect #redirect重定向 def index(request):
username = request.GET.get('username') #获取查询字符串
if username:
return HttpResponse('前台首页')
else:
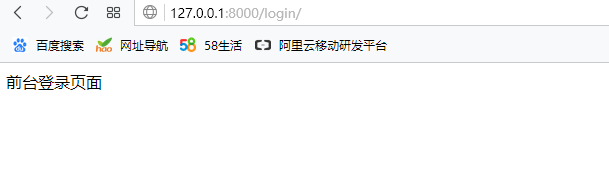
return redirect('/login/') #重定向到登录页面 def login(request):
return HttpResponse('前台登录页面')
访问127.0.0.1:8000 直接跳转到前台登录页面
访问http://127.0.0.1:8000/?username=huahua 跳转到前台首页

7. url命名
为什么需要给url命名?
因为url是经常变化的。如果在代码中写死可能会经常改代码。给url取个名字,以后使用url的时候就使用他的名字进行反转就可以了,就不需要写死url了。
在fomt应用中views.py代码修改如下:
from django.http import HttpResponse
from django.shortcuts import redirect,reverse #redirect重定向 ,增加了reverse函数 def index(request):
username = request.GET.get('username') #获取查询字符串
if username:
return HttpResponse('前台首页')
else:
login_url=reverse('login') #urls.py中的url的name print(login_url)#在控制台可查看打印的东西
return redirect(login_url) # 将login反转的url赋值给login_url def login(request):
return HttpResponse('前台登录页面')
如何给url指定名称?
在'path'函数中,传递一个'name'参数可以指定。
在front应用中urls.py代码修改如下:
from django.urls import path
from . import views urlpatterns = [
path('',views.index,name='index'),
path('signin/',views.login,name='login'),
] # 后期如果想将login改为signin,只需要将前面的“login/”修改为“signin/”即可,别的不用动。
访问http://127.0.0.1:8000/自动跳到http://127.0.0.1:8000/signin/前台登录页面;
应用(app)命名空间
在多个app之间,有可能产生同名的url。这时候为了避免反转url的时候产生混淆,可以使用应用命名空间,来做区分。定义应用命名空间非常简单,只要在app的urls.py中定义一个叫做app_name的变量,来指定这个应用的命名空间即可。
’cms’的app应用views.py文件中给url命名:
from django.urls import path
from . import views urlpatterns = [
path('',views.index,name = 'index'),
path('login',views.login,name = 'login'),
]
访问:http://127.0.0.1:8000/cms/login
发现跳转至了cms登录页面去了,而我们是想让他跳转至前台登录页面啊!
这是因为我们现在的项目中有两个app,在这两个app中我们都将各自的主页url取名为‘index’,登录页面也都是命名为’login’,在
return redirect( reverse('login') )
进行反转的时候,Django不能准确的找到需要跳转的页面,所以他就会跳转至找到的第一个’login’的页面。这个时候我们就需要让Django明确的知道需要跳转的页面,所以我们在每个app中的urls.py中添加一个变量app_name
1、fomt中的urls.py中添加:
#应用命名空间
#应用命名空间的变量叫做app_name
app_name = 'fomt'
2、在cms中的urls.py中添加:
app_name = 'cms'
3、然后我们需要明确的指出需要跳转的页面,在front中的views.py中的index函数修
这样以后左反转的时候就可以使用'应用命名空间:url名称'的方式进行反转;
def index(request):
username = request.GET.get('username')
if username:
return HttpResponse('前台首页')
else:
login_url=reverse('fomt:login') #urls.py中的url的name
return redirect(login_url)
访问:http://127.0.0.1:8000 这样Django就明确的知道需要跳转至哪一个页面了。
实例命名空间
一个app,可以创建多个实例。即可以使用多个url映射同一个app。所以这就会产生一个问题。以后在做反转的时候,如果使用应用命名空间,那么就会发生混淆。为了避免这个问题。我们可以使用实例命名空间。实例命名空间也是非常简单,只要在include函数中传递一个namespace变量即可。
1.在主urls.py中对cms添加两个映射,然后实例化命名
from django.urls import path,include urlpatterns = [
#path('admin/', admin.site.urls),
path('',include('fomt.urls')),
path('cms1/',include('cms.urls',namespace='cms1')),
path('cms2/',include('cms.urls',namespace='cms2')),
]
2.然后修改下cms的views.py中index函数的代码,没有传入用户名进来时直接跳转至登录页面
from django.shortcuts import reverse,redirect
def index(request):
username = request.GET.get("username")
if username:
return HttpResponse('CMS首页')
else:
# 获取当前的命名空间
current_namespace = request.resolver_match.namespace
return redirect(reverse("%s:login" % current_namespace))
们就使用cms1进入时,就会进入cms1的登录页面,使用cms2进入,就会进入cms2的登录页面,http://127.0.0.1:8000/cms2/login
include函数用法
1、include(module,namespace = None):
module:子url的模块字符串;
namespace:实例命名空间,如果指定实例命名空间,前提必须要先指定应用命名空间,也就是在子'urls.py'中添加'app_name'变量‘
2、include(pattern_list):'pattern_list'是一个列表,这个列表中装的是'path'或者're_path'函数;
3、include((pattern_list,app_namespace),namespace = None): include函数的第一个参数既可以为一个字符,也可以为一个元祖,如果是元组,那么元组的第一个参数是’urls.py‘
模块的字符串,元组的第二个参数是应用命名空间,也就是说,应用命名空间既可以在子'urls.py'中通过'app_name'指定,也可以在'include'函数中指定;
re_path和path的区别
1、re_path和path的作用都是一样的。只不过re_path是在写url的时候可以用正则表达式,功能更加强大。
2、写正则表达式都推荐使用原生字符串。也就是以r开头的字符串。
3、在正则表达式中定义变量,需要使用圆括号括起来。这个参数是有名字的,那么需要使用(?P<参数的名字>)。然后在后面添加正则表达式的规则。
4、编写路由需要用的正则表达式,
r 字符串前面加“ r ”是为了防止字符串中出现类似“\t”字符时被转义。
^ 匹配字符串开头;在多行模式中匹配每一行的开头。 ^abc abc
$ 匹配字符串末尾;在多行模式中匹配每一行末尾
例如:
re_path(r"^list/(?P<year>\d{4})/$",views.article_list),
re_path(r"^list/(?P<month>\d{2})/$",views.article_list_month)
第一个表示以list开始,中间需要有4个数字,一个都不能多也不能少,再以 ‘/’ 结尾。
形如list/2222/这样的字符窜才能被识别,
同理,第二句是需要形如list/22/这样的字符窜才能被识别。
例2:
from django.urls import path,re_path urlpatterns = [
re_path(r'^search_phone/$',views.search_phone),
re_path(r'^sign_index/(?P<event_id>[0-9]+)/$', views.sign_index),
re_path(r'^sign_index_action/(?P<event_id>[0-9]+)/$', views.sign_index_action),
如果不是特别要求。直接使用path就够了,除非是url中确实是需要使用正则表达式来解决才使用re_path。
reverse 函数补充
1、如若在反转url时,需要添加参数,那么可以传递 kwargs 参数到 reverse 函数中,实例代码如下:
views.py
from django.shortcuts import render,reverse,redirect
from django.http import HttpResponse def index(request):
username = request.GET.get('username')
if username:
return HttpResponse('首页')
else:
detail_url = reverse('detail', kwargs={"article_id":''}) #使用 kwargs 参数到 reverse 函数中,也可添加多个参数;
#detail_url = reverse('login') +"?next=/"
return redirect(detail_url) def login (request):
return HttpResponse('登录页面') def detail(request,article_id):
text = '您的文章id是:%s' % article_id
return HttpResponse(text)
urls.py
from django.urls import path
from front import views urlpatterns = [
path('', views.index),
path('login/', views.login),
path('detail/<article_id>', views.detail,name='detail'),
]
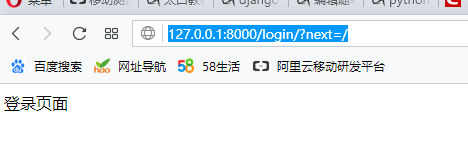
2、如若想添加查询字符串参数,则必须手动进行url拼接,
#detail_url = reverse('login') +"?next=/"
指定默认参数
使用path或者re_path时,在route中都可以包含参数,而有时想指定默认参数,通过以下方式完成
url.py
path('', views.books),
path('book/<int:page>/', views.books),
views.py
from django.http import HttpResponse
book_list=[
'自动化',
'python',
'selenium'
] def books (request,page=0):
return HttpResponse(book_list[page])
当访问book的时候,因为没有传递page参数,所以会匹配到第一个url,这时候view.books这个视图函数,而在books函数中,又有page=0这个默认参数,因此这是就可以不用传递参数,而如果访问book/1的时候,因为在传递参数的时候传递了page,因此会匹配到第二个url,这时候也会执行views.books,然后把传递进来的参数传给books函数中的page。
Django_URL的更多相关文章
- django_url配置
前言 我们在浏览器访问一个网页是通过url地址去访问的,django管理url配置是在urls.py文件.当一个页面数据很多时候,通过会有翻页的情况,那么页数是不固定的,如:page=1.也就是url ...
- Django Rest framework 之 版本
RESTful 规范 django rest framework 之 认证(一) django rest framework 之 权限(二) django rest framework 之 节流(三) ...
随机推荐
- tcp ip 协议安全
ARP(地址解析协议) 地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议.主机发送信息时将包含目标IP地址的ARP请求 ...
- Nginx处理请求的11个阶段(agentzh的Nginx 教程学习记录)
Nginx 处理请求的过程一共划分为 11 个阶段,按照执行顺序依次是 post-read.server-rewrite.find-config.rewrite.post-rewrite.preacc ...
- LoadXml 加载XML时,报错:“根级别上的数据无效。 行1,位置1“
==XML=================================== <?xml version="1.0" encoding="utf-8" ...
- Flutter中使用sqlite
sqflite使用引入插件在pubspec.yaml文件中添加path_provider插件,2019年2月18号最新版本为1.1.0: dependencies: flutter: sdk: flu ...
- php高精度计算问题
从事金融行业,资金运算频繁,这里说下我遇到的坑....稍不留神,用户资金可能损失几十万,甚至更可怕......直接上实例吧: javascript 0.1 + 0.2 为啥不等于 0.3 ? (正确结 ...
- 3、SpringBoot 集成Storm wordcount
WordCountBolt public class WordCountBolt extends BaseBasicBolt { private Map<String,Integer> c ...
- 02_计算机网络的OSI七层(应表会传网数物)
七层: 应用层 表示层 会话层 传输层 网络层 数据链路层 物理层 五层: 应用层 传输层 网络层 数据链路层 物理层 四层: 应用层 传输层 网络层 数据接口层 一.物理层(Physical Lay ...
- cv2.getRotationMatrix2D函数
- Bootstrap3基础 栅格系统 标尺(col-lg/md/sm/xs-1)
内容 参数 OS Windows 10 x64 browser Firefox 65.0.2 framework Bootstrap 3.3.7 editor ...
- P1659 [国家集训队]拉拉队排练
思路 求出cnt和len之后,直接乘起来即可 代码 #include <cstdio> #include <algorithm> #include <cstring> ...