SQL Server 创建索引方法
转自 《SQL Server 创建索引的 5 种方法》 地址:https://www.cnblogs.com/JiangLe/p/4007091.html
前期准备:
create table Employee (
ID int not null primary key,
Name nvarchar(4),
Credit_Card_ID varbinary(max)); --- 小心这种数据类型。
go
说明:本表上的索引,都会在创建下一个索引前删除。
-------------------------------------------------------------------------------------------------------------------------------------------------------------
操作 1、
创建聚集索引
方法 1、
alter table table_name add constraint cons_name
priamry key(columnName ASC|DESC,[.....]) with (drop_existing = on);
alter table Employee
add constraint PK_for_Employee primary key clustered (ID);
go
这个是一种特别的方法,因为在定义主键的时候,会自动添加索引,好在加的是聚集索引还是非聚集索引是我们人为可以控制的。
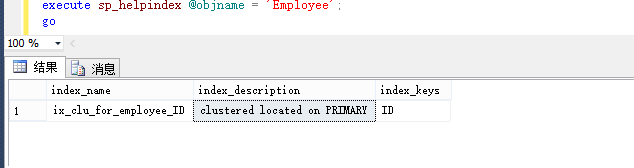
通过sp_helpindex 可以查看表中的索引
execute sp_helpindex @objname = 'Employee';
go

注意、
这个索引是无法删除的,不信! 你去删一下
drop index Employee.PK__Employee__3214EC277D95E615;
go

方法 2、
create clustered index ix_name on table_name(columnName ASC|DESC[,......]) with (drop_existing = on);方法
create clustered index ix_clu_for_employee_ID on Employee(ID);
go
查看创建的索引
操作 2、
创建复合索引
create index ix_com_Employee_IDName on Employee (ID,Name)with (drop_existing = on);
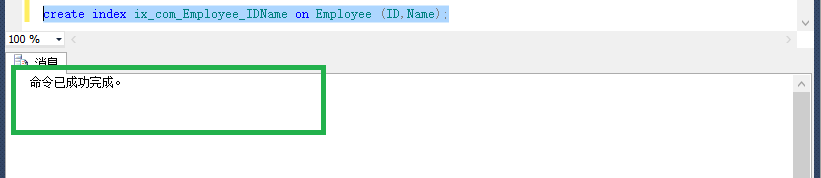
这样就算是创建一个复合索引了,不过脚下的路很长,我们看下一个复合索引的例句:
create index ix_com_Employee_IDCreditCardID on Employee(ID,Credit_Card_ID);
看到这句话,你先问一下自己它有没有错!
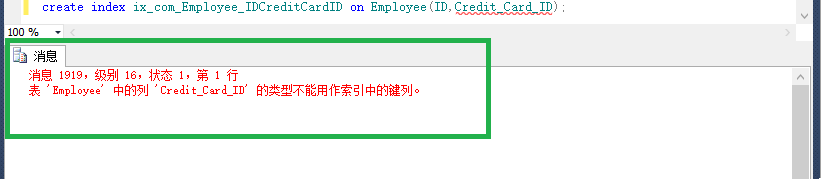
可以发现它错了,varbinary是不可以建索引的。
操作 3、
创建覆盖索引
create index index_name on table_Name (columnName
ASC|DESC[,......]) include(column_Name_List)with (drop_existing = on);
create index ix_cov_Employee_ID_Name on Employee (ID) include(Name);
go
首先,覆盖索引它只是非聚集索引的一种特别形式,下文说的非聚集索引不包涵覆盖索引,当然这个约定只适用于这一段话,这样做的
目的是为了说明各中的区别。
首先:
1、非聚集索引不包涵数据,通过它找到的只是文件中数据行的引用(表是堆的情况下)或是聚集索引的引用,SQL Server
要通这个引用去找到相应的数据行。
2、正因为非聚集索引它没有数据,才引发第二次查找。
3、覆盖索引就是把数据加到非聚集索引上,这样就不需要第二次查找了。这是一种以空间换性能的方法。非聚集索引也是。
只是做的没有它这么出格。
操作 4、
创建唯一索引
create unique index index_name on table_name (column ASC|DESC[,.....])with (drop_existing = on);
正如我前面所说,在创建表上的索引前,我会删除表上的所有索引,这里为什么我要再说一下呢!因为我怕你忘了。二来这个例子用的到它。
目前表是一个空表,我给它加两行数据。
insert into Employee(ID,Name) values(1,'AAA'),(1,'BBB');

这下我们为表加唯一索引,它定义在ID这个列上
create unique index ix_uni_Employee_ID on Employee(ID);
go -- 可以想到因为ID有重复,所以它创建不了。

结论 1、 如果在列上有重复值,就不可以在这个列上定义,唯一索引。
下面我们把表清空: truncate table Employee;

接下来要做的就是先,创建唯一索引,再插入重复值。
create unique index ix_uni_Employee_ID on Employee(ID);
go
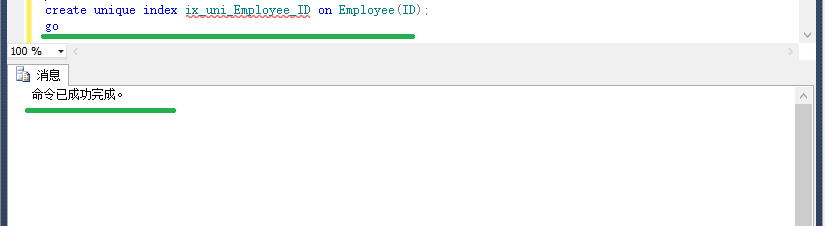
insert into Employee(ID,Name) values(1,'AAA'),(1,'BBB');
go

结论 2、
定义唯一索引后相应的列上不可以插入重复值。
操作 5、
筛选索引
create index index_name on table_name(columName) where boolExpression;
create index ix_Employee_ID on Employee(ID) where ID>100 and ID< 200;
go
只对热点数据加索引,如果大量的查询只对ID 由 100 ~ 200 的数据感兴趣,就可以这样做。
1、可以减小索引的大小
2、为据点数据提高查询的性能。
总结:
BTree 索引有聚集与非聚集之分。
就查看上到聚集索引性能比非聚集索引性能要好。
非聚集索引分 覆盖索引,唯一索引,复合索引(当然聚集索引也有复合的,复合二字,只是说明索引,引用了多列),一般非聚集索引
就查看上到非聚集索引中覆盖索引的性能比别的非聚集索引性能要好,它的性能和聚集索引差不多,可是
它也不是’银弹‘ 它会用更多的磁盘空间。
最后说一下这个
with (drop_existing = on|off),加上这个的意思是如果这个索引还在表上就drop 掉然后在create 一个新的。特别是在聚集索引上
用使用这个就可以不会引起非聚集索引的重建。
with (online = on|off) 创建索引时用户也可以访问表中的数据,
with(pad_index = on|off fillfactor = 80); fillfactor 用来设置填充百分比,pad_index 只是用来连接fillfactor 但是它又不难少,
这点无语了。
with(allow_row_locks = on|off | allow_page_locks = on |off); 是否允许页锁 or 行锁
with (data_compression = row | page ); 这样可以压缩索引大小
SQL Server 创建索引方法的更多相关文章
- SQL Server创建索引
原文:SQL Server创建索引 什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的 ...
- SQL Server创建索引(转)
什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的速度,汉语字(词)典一般都有按拼音. ...
- (转)SQL Server创建索引
什么是索引拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的速度,汉语字(词)典一般都有按拼音.笔 ...
- SQL Server 创建索引的 5 种方法
前期准备: create table Employee ( ID int not null primary key, Name nvarchar(4), ...
- SQL Server 创建索引
索引的简介: 索引分为聚集索引和非聚集索引,数据库中的索引类似于一本书的目录,在一本书中通过目录可以快速找到你想要的信息,而不需要读完全书. 索引主要目的是提高了SQL Server系统的性能,加快数 ...
- SQL Server 创建索引(index)
索引的简介: 索引分为聚集索引和非聚集索引,数据库中的索引类似于一本书的目录,在一本书中通过目录可以快速找到你想要的信息,而不需要读完全书. 索引主要目的是提高了SQL Server系统的性能,加快数 ...
- sql server 创建索引 超时时间已到
如下图所示:在现场PR_Product表中添加绯聚焦索引PSCode,点击保存按钮后等了一段时间弹出超时警告!现场这张表的数据量也是特别大的(250+万),但是我本地也是把现场数据库还原了的,一样的数 ...
- SQL语句-创建索引
语法:CREATE [索引类型] INDEX 索引名称ON 表名(列名)WITH FILLFACTOR = 填充因子值0~100 GO USE 库名GO IF EXISTS (SELECT * FRO ...
- SQL Server创建表超出行最大限制解决方法
问题的现象在创建表A的时候,出现“信息 511,级别 16,状态 1,第 5 行 无法创建大小为 的行,该值大于允许的最大值 8060.”的信息提示.很奇怪,网上查了一下,是因为要插入表的数据类型的 ...
随机推荐
- MyBatis探究-----动态SQL详解
1.if标签 接口中方法:public List<Employee> getEmpsByEmpProperties(Employee employee); XML中:where 1=1必不 ...
- pickel加速caffe读图
64*64*3小图(12KB),batchSize=128,训练样本100万, 全部load进来内存受不了,load一次需要大半天 训练时读入一个batch,ali云服务器上每个batch读入时间1. ...
- 示例, linq分组
public class HIS_CLIREGISTER : BaseModel{ private String _FBCODE;[StringLength(8)]/// <summary> ...
- css中height 100vh的应用场景,动态高度百分比布局,浏览器视区大小单位
css中height 100vh的应用场景,动态高度百分比布局,浏览器视区大小单位 height:100vh 一些只能vw, vh才能完成的应用场景: 1. 场景之:元素的尺寸限制 vw vh 主要是 ...
- CCF CSP 201712-1 最小差值
题目链接:http://118.190.20.162/view.page?gpid=T68 问题描述 试题编号: 201712-1 试题名称: 最小差值 时间限制: 1.0s 内存限制: 256.0M ...
- [最新]ABP ASP.NET Zero v5.5.2 破解
参考https://www.cnblogs.com/xajh/p/8428818.html后, 搞定了Abp.AspNetZeroCore.dll.Abp.AspNetZeroCore.Web.dll ...
- ceph添加osd(ceph-deploy)
修改主机名和 /etc/hosts 关闭防火墙和 SELINUX 安装和配置 NTP ceph-deploy 节点安装 安装 ceph-deploy sudo yum install ceph-dep ...
- spring整合dubbo[单机版]
Spring整合Dubbo,这个是用xml配置的 (方式一) 来梳理下步骤: 1. 安装zookeeper,在进行简单配置[这里使用单机模式,不用集群] 2. 创建maven项目,构建项目结构 3. ...
- 面试小记---java基础知识
**static 和 final 的理解** static:是静态变量修饰符,修饰的是全局变量,所以对象是共享的,在开始类设计的初期就分配空间. final:声明式属性,方法,类.分别表示属 ...
- 【转】java线上程序排错经验2 - 线程堆栈分析
前言 在线上的程序中,我们可能经常会碰到程序卡死或者执行很慢的情况,这时候我们希望知道是代码哪里的问题,我们或许迫切希望得到代码运行到哪里了,是哪一步很慢,是否是进入了死循环,或者是否哪一段代码有问题 ...