利用PIL和Selenium实现页面元素截图
预备
照张相片
selenium.webdriver可以实现对显示页面的截图:
from selenium import webdriver dr = webdriver.Firefox()
dr.get('http://store.steampowered.com/')
dr.save_screenshot('D:\\page.png')
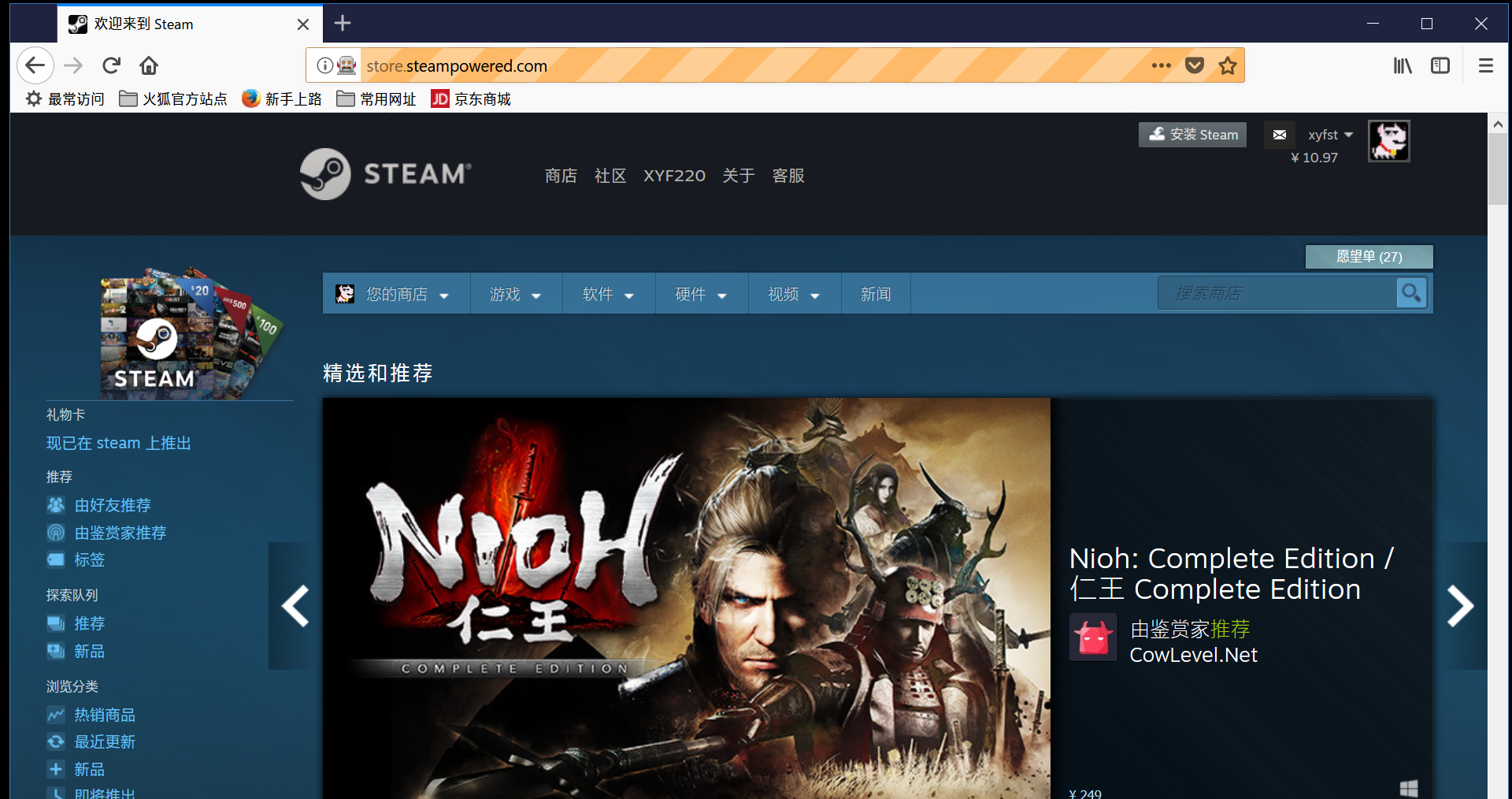

实际浏览器界面和截图结果
可以发现截图结果是浏览器内当前的显示内容。
让我想想...那只要让需要截图的元素出现在当前页面上,再从得到的截图里再把要的元素截取出来不就好啦?
那问题是怎么才能让当前元素先让我们看见呢?
让提线木偶动起来
在js中,页面可以滚动到特定元素:
item_obj = document.getElementsByClassName('store_capsule_frame');
item = item_obj[0];
item.style.border = '2px solid red';
item.scrollIntoView();
在浏览器的控制台执行上述代码
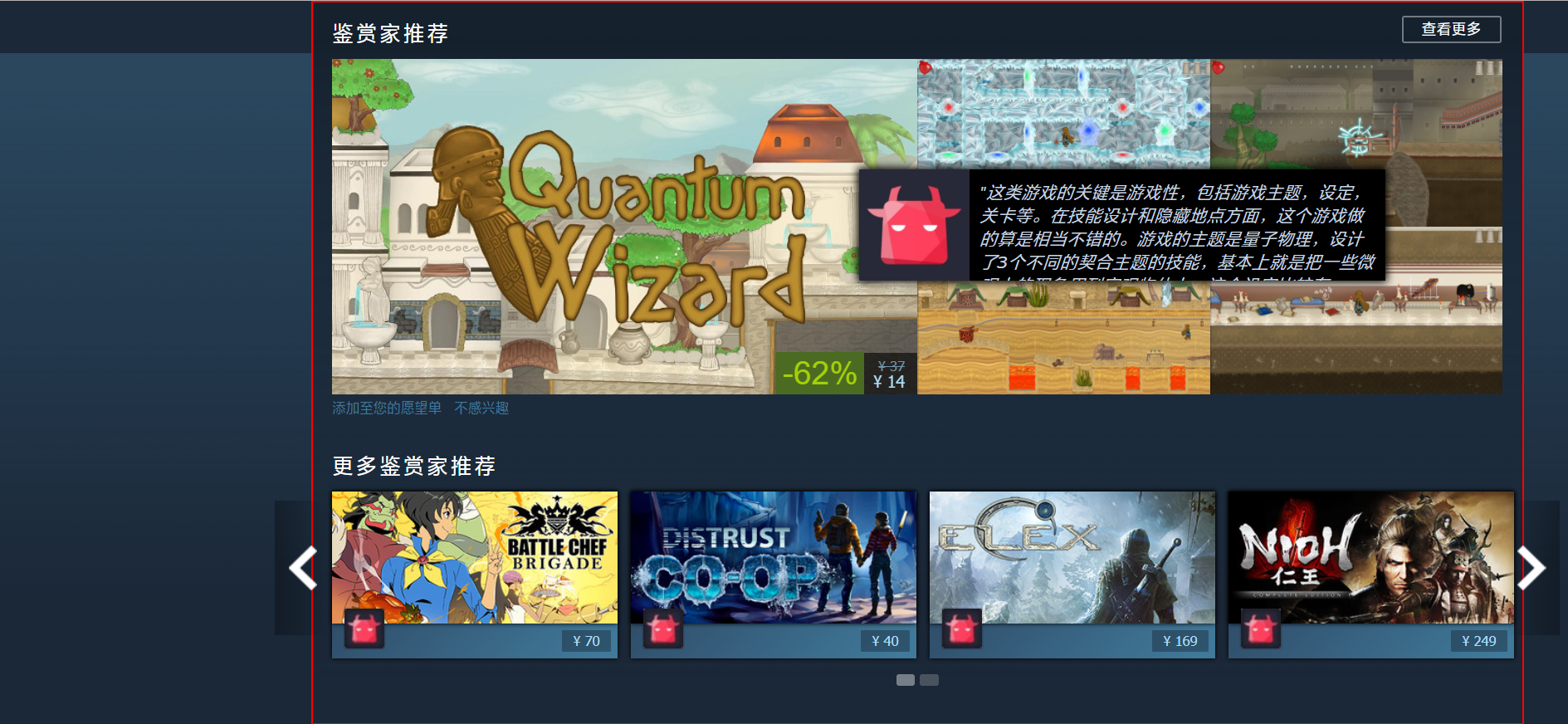
可以看到页面会滚动到鉴赏家推荐这一栏,并且我给该元素加了个红线条的边框。边框内的内容就是我们要截图保存的元素。
scrollIntoView方法的参数是一个布尔值,默认为True,指的是否与顶部对齐。true则页面从元素顶部开始,false则页面会与底部对齐。
在selenium中,webdriver有execute_script的方法
可以向webdriver中直接注入任何js代码,操作页面,并且可以传入参数。
我们可以把上面的js代码注入到webdriver中,实现同样的效果。(这里稍微改动一下,用webdriver来获取元素)
item = dr.find_element('class name', 'store_capsule_frame')
dr.execute_script('arguments[0].scrollIntoView();', item)
js代码中的arguments是execute_script方法后面的参数集合,这里我们将定位的元素传入,效果如上图。
现在可以让想要的元素显示出来啦,自然也可以截出一张对应的页面图片啦。
那么又该如何定位元素在图片中的位置并裁剪出来呢?
来切相片吧
先画好位置
webdriver获取的页面元素封装了对裁剪很有用的信息。这里会用到它的locaion属性。
item.location # {'x': 247, 'y': 1959}
item.size # {'width': , 'height': }
可以看到元素的location保存在一个字典中,分别是该元素相对整个html的x轴和y轴距离。size属性亦然。
因为截图时会以元素顶部为起始线,元素左上顶点在截图中的位置就是(item.location['x'],0),右下顶点位置就是(item.locaion['x'] + item.size['width'], item.size['height'])
学会剪裁
PIL是python中的图像处理库,pillow是其的一个分支,其核心仍然是PIL,但更易用。用pip即可安装。
来剪切刚刚保存的图片:
from PIL import Image
img = Image.open("D:\\page.png")
crop_size = (0,0,300,300)
cropped = img.crop(crop_size)
cropped.save('D:\\cropped.png')
先将图片读入到内存,存储到一个Image对象中。
crop方法返回一个长方形的Image对象,需要传入要剪切的尺寸,类型为一个元组。四个值分别是裁剪出的图片距离原图片左边、上边、右边、下边的距离,说简单点,其实就是裁剪结果左上顶点的x,y坐标以及右下定点的x,y坐标(以原图的左上顶点为原点)。
上面的操作会从原图片的左上角裁剪出一个300*300的正方形。

初步代码
def get_element_screenshot(driver, by, value, path):
from selenium import webdriver
from PIL import Image
ele = driver.find_element(by, value)
driver.execute_script('arguments[0].scrollIntoView();', ele)
if driver.save_screenshot(path):
img = Image.open(path+'_Page.png')
size = (ele.location['x'],0,ele.location['x']+ele.size['width'],ele.size['height'])
cropped = img.crop(size)
cropped.save(path+'Cropped.png')
del img, cropped
print('Image is cropped successfully.')
return True
else:
print('Image not saved.')
return False
跌落的坑
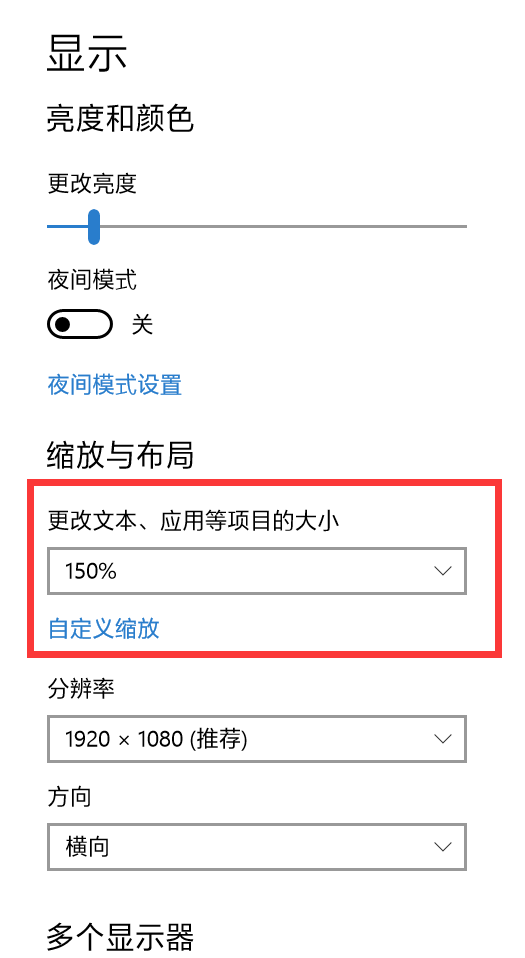
我在截图过程中,发现按照页面元素的实际大小去截取而得的图片总是要小很多。原先以为是截取时选择的高和宽不对,毕竟js中height值根据padding和boder是否包含分为了clientHeight、offsetHeight等值。但查找多时,仍是没有结果,无论怎样改变,都无法准确截取。去浏览器的控制台中选中元素查看,发现元素的高宽和实际的像素值差了一些,实际值是其1.5倍。突然想到是否和分辨率有关,就去看了一下,是1920 * 1080。在控制台中用window.screen.availHeight获得可用高度,刚好是1.5倍。我以为症结就是这个,就搜索了一下,准备用win32api模块中的GetSystemMetrics方法获得屏幕分辨率,在除以可用高/宽度,拿到一个比例。但是执行该方法查询后发现结果是1280和720。我觉得很奇怪,不是1920 * 1080吗?又去显示设置去瞧了一下,才忽然知道应该是这缩放设置惹的祸,我将缩放设置为了150%。调为100%后,再去截取图片,便没有任何问题了。
费时不少,虽然错误很小,但中间也复习了height的相关知识,也学习了些win32模块的一些小知识点,算是绕路式学习。
是以为记。
尚未解决的问题
scrollIntoView方法执行后,已经到页面底部,但是元素顶部并未与页面顶部对齐,这时的元素定位方法就要随之改变,但还未写,留待之后改进。
最终代码
def get_screenshot(driver, ele, path):
"""
:param driver: selenium webdriver object
:param by: method to find element
:param value: element value
:param path: path to save picture
:return:
"""
from PIL import Image # Decide whether a scroll bar exists
js_ret = driver.execute_script('''
var bounding_top = arguments[0].getBoundingClientRect();
if(document.documentElement.scrollHeight > document.documentElement.clientHeight){
arguments[0].scrollIntoView();
var rect_obj = arguments[0].getBoundingClientRect();
if(rect_obj.top == 0){
return 'scroll-and-on-the-top';
}else{
var size_array = new Array(4);
size_array[0] = rect_obj.x;
size_array[1] = rect_obj.y;
size_array[2] = rect_obj.right;
size_array[3] = rect_obj.bottom;
return size_array;
}
}else{
return 'no-scroll';
}
''', ele)
driver.execute_script('arguments[0].scrollIntoView();', ele)
if driver.save_screenshot(path):
img = Image.open(path)
_x = ele.location['x']
_y = ele.location['y']
_h = ele.size['height']
_w = ele.size['width']
if js_ret == 'scroll-and-on-the-top':
size = (_x, 0, _x + _w, _h)
elif js_ret == 'no-scroll':
size = (_x, _y, _x + _w, _y + _h)
else:
print(js_ret)
size = tuple(js_ret)
cropped = img.crop(size)
cropped.save(path)
del img, cropped
print('Image is cropped successfully and saved to %s.' % path)
return True
else:
print('Image not saved due to invalid file path. Screen shot failed.')
return False
参考
关于js中getBoundingClientRect()方法的说明,戳这里:
https://www.cnblogs.com/Songyc/p/4458570.html
利用PIL和Selenium实现页面元素截图的更多相关文章
- Selenium操作页面元素
转自:http://blog.sina.com.cn/s/blog_6966650401012a7q.html 一.输入框(text field or textarea) //找到输入框元素: Web ...
- selenium定位页面元素的一件趣事
PS:本博客selenium分类不会记载selenium打开浏览器,定位元素,操作页面元素,切换到iframe,处理alter.confirm和prompt对话框这些在网上随处可见的信息:本博客此分类 ...
- Selenium 定位页面元素 以及总结页面常见的元素 以及总结用户常见的操作
1. Selenium常见的定位页面元素 2.页面常见的元素 3. 用户常见的操作 1. Selenium常见的定位页面元素 driver.findElement(By.id());driver.fi ...
- [Selenium] 操作页面元素等待时间
WebDriver 在操作页面元素等待时间时,提供2种等待方式:一个为显式等待,一个为隐式等待,其区别在于: 1)显式等待:明确地告诉 WebDriver 按照特定的条件进行等待,条件未达到就一直等待 ...
- Selenium解决页面元素不在视野范围内的问题
当需要使用滚动条才能使页面元素显示在视野范围内时,必须用代码处理下,才能对其进行操作. 处理其实也很简单,就是调用JS函数. driver.executeScript("arguments[ ...
- selenium找到页面元素click没反应
问题描述:通过调试可以看到控制台已经找到了起诉入口页面元素,可是点击“我是原告”没有反应了,也没有报错 解决办法:登录时是跳进了两层的iframe中,需要跳出iframe才能找到我是原告.
- 【selenium学习笔记一】python + selenium定位页面元素的办法。
1.什么是Selenium,为什么web测试,大家都用它? Selenium设计初衷就是为web项目的验收测试再开发.内核使用的是javaScript语言编写,几乎支持所以能运行javaScript的 ...
- python + selenium定位页面元素的办法
1.什么是Selenium,为什么web测试,大家都用它? Selenium设计初衷就是为web项目的验收测试再开发.内核使用的是javaScript语言编写,几乎支持所以能运行javaScript的 ...
- centos下利用phantomjs来完成网站页面快照截图
最近研究了下phantomjs,感觉还是非常不错的. 首先到官网下载一个源码包 http://phantomjs.org/download.html 点击源码包下载如图: 然后在linux下将必要的一 ...
随机推荐
- HDU 1584(蜘蛛牌 DFS)
题意是在蜘蛛纸牌的背景下求 10 个数的最小移动距离. 在数组中存储 10 个数字各自的位置,用深搜回溯的方法求解. 代码如下: #include <bits/stdc++.h> usin ...
- oldboy s21day09
#!/usr/bin/env python# -*- coding:utf-8 -*- # 1.将函数部分知识点,整理到自己笔记中.(搞明白课上讲的案例.) # 2.写函数,检查获取传入列表或元组对象 ...
- 散度、旋度与 Laplacian
$$\bex -\lap {\bf u}=\rot \rot {\bf u}-\n \Div {\bf u}. \eex$$
- python之使用单元测试框架unittest执行自动化测试
Python中有一个自带的单元测试框架是unittest模块,用它来做单元测试,它里面封装好了一些校验返回的结果方法和一些用例执行前的初始化操作. 单元测试框架即一堆工具的集合. 在说unittest ...
- Python中应该使用%还是format来格式化字符串?
转载自http://www.cnblogs.com/liwenzhou/p/8570701.html %的特点是,前面有几个%,后面的括号里就得有几个参数,如果只有一个%,括号可以省略 基本格式 'a ...
- Stm32复习之时钟系统
地点:南图 这部分的内容是整个STM32学习知识的核心,不管是什么微控制器处理器,时钟系统都是其核心类似于人之心脏,因此学好理解这一章节至关重要. 为了便于理解这一系统,将从以下几个层次来讲.(忘了是 ...
- 萌新的IDEA_web开发笔记(未完)
萌新IDEA_web开发笔记 按兴趣自己搞的网页: http://47.94.140.98:8080/ow_web/my_web/web/ 暂时还没做完. 部署在租的服务器上面,背景视频加载可能有点慢 ...
- k64 datasheet学习笔记25--Multipurpose Clock Generator (MCG)
0.前言 MCG模块为MCU提供了几种可选时钟源.模块包含一个FLL和一个PLL.FLL使用内部或外部参考时钟是可控的,PLL受外部参考时钟控制 模块可以选择FLL或PLL输出时钟,或内/外部参考时钟 ...
- Python-form表单标签
语义:标记表单 #1.什么是表单? 表单就是专门用来接收用户输入或采集用户信息的 #2.表单的格式 <form> <表单元素> </form> 链接:https:/ ...
- greenplum加密
--如下为greenplum5.0数据库加解密--加密函数select encrypt('123456','aa','aes');--加解密函数select convert_from(decrypt( ...