Spark Java API 计算 Levenshtein 距离
Spark Java API 计算 Levenshtein 距离
在上一篇文章中,完成了Spark开发环境的搭建,最终的目标是对用户昵称信息做聚类分析,找出违规的昵称。聚类分析需要一个距离,用来衡量两个昵称之间的相似度。这里采用levenshtein距离。现在就来开始第一个小目标,用Spark JAVA API 计算字符串之间的Levenshtein距离。
1. 数据准备
样本数据如下:
{"name":"Michael", "nick":"Mich","age":50}
{"name":"Andy", "nick":"Anc","age":30}
{"name":"Anch", "nick":"MmAc","age":19}
把数据保存成文件并上传到hdfs上:./bin/hdfs dfs -put levestein.json /user/panda
2. 代码实现
定义一个类表示样本数据:
public static class User{
private String name;
private String nick;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getNick() {
return nick;
}
public void setNick(String nick) {
this.nick = nick;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
创建SparkSession
SparkSession sparkSession = SparkSession.builder()
.appName("levenshtein example")
.master("spark://172.25.129.170:7077")
.config("spark.some.config.option", "some-value")
.getOrCreate();
在Spark命令行./bin/pyspark 启动Spark时,会默认创建一个名称为 spark 的SparkSession。而这里是写代码,也需要创建SparkSession对象。
The SparkSession instance is the way Spark executes user-defined
manipulations across the cluster. There is a one-to-one correspondence between a SparkSession and
a Spark Application.
定义数据类型
Encoder<User> userEncoder = Encoders.bean(User.class);
JAVA里面定义了一套数据类型,比如java.util.String是字符串类型;类似地,Spark也有自己的数据类型,因此Encoder就定义了如何将Java对象映射成Spark里面的对象。
Used to convert a JVM object of type
Tto and from the internal Spark SQL representation.To efficiently support domain-specific objects, an
Encoderis required. The encoder maps the domain specific typeTto Spark's internal type system. For example, given a classPersonwith two fields,name(string) andage(int), an encoder is used to tell Spark to generate code at runtime to serialize thePersonobject into a binary structure. This binary structure often has much lower memory footprint as well as are optimized for efficiency in data processing (e.g. in a columnar format). To understand the internal binary representation for data, use theschemafunction.
构建Dataset:
Dataset<User> userDataset = sparkSession.read().json(path).as(userEncoder);
说明一下Dataset与DataFrame区别,Dataset是针对Scala和JAVA特有的。Dataset是有类型的,Dataset的每一行是某种类型的数据,比如上面的User类型。
A Dataset is a strongly typed collection of domain-specific objects that can be transformed in parallel using functional or relational operations. Each Dataset also has an untyped view called a
DataFrame, which is a Dataset ofRow.
而DataFrame的每一行的类型是Row(看官方文档,我就这样理解了,哈哈。。)
DataFrame is represented by a Dataset of
Row。While, in Java API, users need to useDataset<Row>to represent aDataFrame.
这个图就很好地解释了DataFrame和Dataset的区别。
计算levenshtein距离,将之 transform 成一个新DataFrame中:
Column lev_res = functions.levenshtein(userDataset.col("name"), userDataset.col("nick"));
Dataset<Row> leveDataFrame = userDataset.withColumn("distance", lev_res);
完整代码
import org.apache.spark.sql.*;
public class LevenstenDistance {
public static class User{
private String name;
private String nick;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getNick() {
return nick;
}
public void setNick(String nick) {
this.nick = nick;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder()
.appName("levenshtein example")
.master("spark://172.25.129.170:7077")
.config("spark.some.config.option", "some-value")
.getOrCreate();
String path = "hdfs://172.25.129.170:9000/user/panda/levestein.json";
Encoder<User> userEncoder = Encoders.bean(User.class);
Dataset<User> userDataset = sparkSession.read().json(path).as(userEncoder);
userDataset.show();
Column lev_res = functions.levenshtein(userDataset.col("name"), userDataset.col("nick"));
Dataset<Row> leveDataFrame = userDataset.withColumn("distance", lev_res);
// userDataset.show();
leveDataFrame.show();
System.out.println(lev_res.toString());
}
}
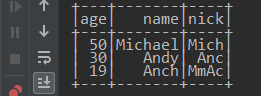
原来的Dataset:
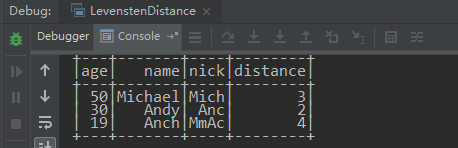
计算Levenshtein距离后的得到的DataFrame:
根据上面的示例,下面来演示一下一个更实际点的例子:计算昵称和签名之间的levenshtein距离,若levenshtein距离相同,就代表该用户的 昵称 和 签名 是相同的:
数据格式如下:
{"nick":"赖求","uid":123456}
{"details":"时尚是一种态度,时尚第一品牌。看我的。","nick":"冰冷世家@蹦蹦","signature":"轻装时代看我的。艾莱依时尚羽绒服。。","uid":123456}
{"nick":"[潗團軍-6]明 明『招 募』","signature":"我是来擂人的,擂死人不偿命!","uid":123456}
加载数据
Dataset<Row> dataset = spark.read().format("json")
.option("header", "false")
.load("hdfs://172.25.129.170:9000/user/panda/profile_noempty.json");
取出昵称和签名
//空字符串 与 null 是不同的
Dataset<Row> nickSign = dataset.filter(col("nick").isNotNull())
.filter(col("signature").isNotNull())
.select(col("nick"), col("signature"), col("uid"));
计算昵称和签名的Levenshtein距离
Column lev_distance = functions.levenshtein(nickSign.col("nick"), nickSign.col("signature"));
Dataset<Row> nickSignDistance = nickSign.withColumn("distance", lev_distance);
按距离进行过滤
Dataset<Row> sameNickSign = nickSignDistance.filter("distance = 0");
这样就能找出昵称和签名完全一样的用户了。
原文:https://www.cnblogs.com/hapjin/p/9954191.html
Spark Java API 计算 Levenshtein 距离的更多相关文章
- Spark Java API 之 CountVectorizer
Spark Java API 之 CountVectorizer 由于在Spark中文本处理与分析的一些机器学习算法的输入并不是文本数据,而是数值型向量.因此,需要进行转换.而将文本数据转换成数值型的 ...
- 在 IntelliJ IDEA 中配置 Spark(Java API) 运行环境
1. 新建Maven项目 初始Maven项目完成后,初始的配置(pom.xml)如下: 2. 配置Maven 向项目里新建Spark Core库 <?xml version="1.0& ...
- spark (java API) 在Intellij IDEA中开发并运行
概述:Spark 程序开发,调试和运行,intellij idea开发Spark java程序. 分两部分,第一部分基于intellij idea开发Spark实例程序并在intellij IDEA中 ...
- spark java API 实现二次排序
package com.spark.sort; import java.io.Serializable; import scala.math.Ordered; public class SecondS ...
- spark java api数据分析实战
1 spark关键包 <!--spark--> <dependency> <groupId>fakepath</groupId> <artifac ...
- 【Spark Java API】broadcast、accumulator
转载自:http://www.jianshu.com/p/082ef79c63c1 broadcast 官方文档描述: Broadcast a read-only variable to the cl ...
- 基于OpenStreetMap计算驾车距离(Java)
最近公司有个项目需要计算6000个点之间的驾车距离,第一时间想到的是利用Google的Distance Matrix API,但是免费Key每天只能计算2500个元素(元素 = 起点数量 * 终点数量 ...
- Elasticsearch 2.3.3 JAVA api说明文档
原文地址:https://www.blog-china.cn/template\documentHtml\1484101683485.html 翻译作者:@青山常在人不老 加入翻译:cdcnsuper ...
- Spark基础与Java Api介绍
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3832405.html 一.Spark简介 1.什么是Spark 发源于AMPLab实验室的分布式内存计 ...
随机推荐
- IO多路复用三种方式select/poll/epoll
select多并发socket例子: #_*_coding:utf-8_*_ __author__ = 'Alex Li' import select import socket import sys ...
- 《JAVA程序设计》_第五周学习总结
一.本周学习内容 1.接口--6.1知识 接口的声明 interface 接口名 接口体 只有常量和抽象方法 (用final.static.public修饰的变量,关键词可省略) (用abstract ...
- 追逐心目中的那个Ta
申明:全篇皆为作者臆想,浪漫主义代表派作品,若有雷同,纯属巧合 人生最难过的不就是在一无所有的年纪里遇到了最想呵护一生的人,而在拥有一切的时候却失去了不顾一切的心. 长夜漫漫,本是相思人,偏听多情曲, ...
- mongoDB操作详细
简介 它和我们使用的关系型数据库最大的区别就是约束性,可以说文件型数据库几乎不存在约束性,理论上没有主外键约束,没有存储的数据类型约束等等 关系型数据库中有一个 "表" 的概念,有 ...
- git方法 GUI here
注:stage changed是将所有修改归集到一次commit,如果要分开commit,则应该使用ctrl+t来一个一个文件的stage
- git中如何撤销部分修改?
以提问中修改了两个文件a.b为例,假设需要撤销文件a的修改,则修改后的两个文件: 1.如果没有被git add到索引区 git checkout a 便可撤销对文件a的修改 2.如果被git add到 ...
- 关于dubbo+zookeeper微服务的一些认识记录
借鉴架构示意图: 实例介绍: 公司某项目架构 服务器A:nginx 服务器BC:tomcat1.tomcat2 服务器D:Dubbo+zookeeper 服务器EF:db1+zookeeper.db2 ...
- rsync 远程拷贝
rsync -vzP win7.qcow2 agu@192.168.1.198:/tmp/
- P1226 【模板】快速幂||取余运算
https://www.luogu.org/problemnew/show/P1226 模板题 直接上代码吧 #include<bits/stdc++.h> using namespace ...
- Lodop打印控件在页面如何使用
Lodop打印控件部署到web服务器简单,在页面的使用方法也简单,是非常容易和方便使用的打印控件.客户端本地打印角色(即用户访问网站后 用自己链接的打印机进行客户端本地打印),步骤很少,部署简单:Lo ...