KNN算法的实现
K近邻(KNN)算法简介
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。

由此也说明了KNN算法的结果很大程度取决于K的选择。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

L1是曼哈顿距离:顾名思义,在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
L2是我们的欧氏距离:欧氏距离是最容易直观理解的距离度量方法,我们小学、初中和高中接触到的两个点在空间中的距离一般都是指欧氏距离。
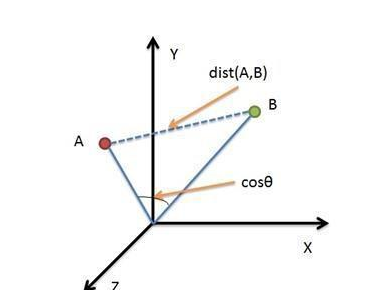
我们一般都常用欧氏距离。
同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
概述:
KNN 算法本身简单有效,它是一种 lazy-learning 算法。
分类器不需要使用训练集进行训练,训练时间复杂度为0。
KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为n,那么KNN 的分类时间复杂度为O(n)。
总结:
K 值的选择,距离度量和分类决策规则是该算法的三个基本要素
问题:该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,
该样本的K 个邻居中大容量类的样本占多数。
解决:不同的样本给予不同权重项。
另外,KNN算法的超参数只有K一个,如果有其他超参数,该怎么确定呢?事实上,模型的好坏跟参数的设定有很大的关系,当我们需要调整参数时,最常用的额方式就是交叉验证。
1.选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现
最好那个
2.如果训练数据量不够,使用交叉验证方法,它能帮助我们在选取最优超参数的时候减少噪音。
3.一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
另外,KNN实现的时候注意点:
1.预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。
2.如果数据是高维数据,考虑使用降维方法,比如PCA
3.将数据随机分入训练集和验证集。按照一般规律,70%-90% 数据作为训练集
4.在验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。
Python实现
# -*- coding: utf-8 -*- """
@Datetime: 2018/11/23
@Author: Zhang Yafei
"""
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler def maxminNormalization(data):
"""标准化
data = (data - data.mean) / data.std
:return data
"""
mean_vals = data.mean(axis=0)
std_val = data.std(axis=0)
data = (data - mean_vals) / std_val
return data class KNN():
def __init__(self,k=1):
self.k = k def fit(self,x_train,y_train):
self.x_train = x_train
self.y_train = y_train def predict(self,x_test):
dis_squar = (x_train - x_test)**2
dis_squar_sum = dis_squar.sum(axis=1)
distances = dis_squar_sum**0.5
sortedIndics = distances.argsort()
indices = sortedIndics[:self.k]
labelCount = {} # 存储每个label的出现次数
for i in indices:
label = self.y_train[i]
labelCount[label] = labelCount.get(label, 0) + 1 # 次数加一
# 排序方式一
# sortedCount = list(zip(labelCount.values(),labelCount.keys()))
# 对label出现的次数从大到小进行排序
# sortedCount.sort()
# return sortedCount[0][1] # 返回出现次数最大的label
# 排序方式二
sortedCount = sorted(labelCount.items(), key=lambda k:k[1], reverse=True)
return sortedCount[0][0] # 返回出现次数最大的label if __name__ == '__main__':
# data = np.arange(24).reshape(4,6)
train = pd.DataFrame({'age':[23,33,45],'income':[5000,12000,13000],'work':[1,2,3]})
test = pd.DataFrame({'age':[22,30,40],'income':[9000,13000,14000],'work':[2,1,2]})
x_train = maxminNormalization(train[['age','work']])
y_train = train['income']
x_test = maxminNormalization(test[['age','work']])
y_test = test['income']
knn = KNN()
knn.fit(x_train,y_train)
y_predict = knn.predict(x_test)
print(y_predict)
底层代码实现
from sklearn.datasets import load_iris,fetch_20newsgroups,load_boston
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import pandas as pd
from sklearn.metrics import classification_report def knncls():
"""
k-近邻预测用户签到位置
:return None
"""
#读取数据
data = pd.read_csv('./data/FBlocation/train.csv')
print(data.head(10)) #处理数据
#1.缩小数据,查询数据筛选
data = data.query('x>1.0 & x<1.25 & y>2.5 & y<2.75') #处理时间的数据
time_value = pd.to_datetime(data.time,unit='s')
print(time_value) #把日期格式转化为字典参数
time_value = pd.DatetimeIndex(time_value) #构造一些特征
data.loc[:,'day'] = time_value.day
data.loc[:,'hour'] = time_value.hour
data.loc[:,'weekday'] = time_value.weekday #时间戳特征删除
data.drop(['time'],axis=1)
print(data) #把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').aggregate(np.count_nonzero)
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)] # 2.4 清理无效特征
data = data.drop(['row_id'], axis=1)
data = data.drop(['accuracy'], axis=1) #取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'],axis=1) #进行数据的分割 训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25) #特征工程(标准化)
std = StandardScaler() #对训练集和测试机的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.fit_transform(x_test) #特征工程('标准化‘) #进行算法流程 #超参数
knn = KNeighborsClassifier()
# # fit,perdict,score
# knn.fit(x_train,y_train)
#
# #得到预测结果
# y_predict = knn.predict(x_test)
# print('预测的目标签到位置为:',y_predict)
# # #得到准确率
# print('预测的准确率:',knn.score(x_test,y_test)) #构造一些参数的值进行搜索
param = {'n_neighbors':[3,5,10]} gc = GridSearchCV(knn,param_grid=param,cv=2)
gc.fit(x_train,y_train) #预测准确率
print('在测试集上的准确率:',gc.score(x_test,y_test)) print('在交叉验证中最好的结果:',gc.best_score_)
print('选择最好的模型是:',gc.best_estimator_)
print('每个超参数每次交叉验证的结果:',gc.cv_results_) return None def knncls_iris():
li = load_iris() x_train,x_test,y_train,y_test = train_test_split(li.data,li.target,test_size=0.25)
"""
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
y_predict = knn.predict(x_test)
print('鸢尾花种类预测值为:',y_predict)
print('准确率为:',knn.score(x_test,y_test))
print('每个分类的精确率和召回率是:',classification_report(y_test,y_predict,target_names=li.target_names))
"""
#模型选择与调优
knn = KNeighborsClassifier()
param = {'n_neighbors':[3,5,10]}
gc = GridSearchCV(knn,param_grid=param,cv=10)
gc.fit(x_train,y_train) print('在测试集中的准确率:',gc.score(x_test,y_test))
print('在交叉验证中的最好的结果:',gc.best_score_)
print('最好的模型是:',gc.best_estimator_)
print('每个超参数每次交叉验证的结果:',gc.cv_results_) if __name__ == '__main__':
# knncls()
knncls_iris()
sklearn实现
KNN算法是一个经典的机器学习算法,同时也是最简单的一个算法,应用它可以解决一些很常见的分类问题。但是对于一个复杂的分类问题,比如图像识别,它的效果就不是很好了,不过这也是机器学习算法和深度学习的分水岭,深度学习可以解决更复杂的分类问题,比如自然语言处理和计算机视觉中的图像识别。所以,人工智能的快速发展得益于深度学习的突破,这也是未来额一个趋势。我们应该好好加油,我们赶上了这个时代,使我们的幸运,而能够投身于学习与这个世界上最前沿的技术,更是我们的荣幸,我们更应该好好加油!
KNN算法的实现的更多相关文章
- KNN算法的实现(R语言)
一 . K-近邻算法(KNN)概述 最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类.但是怎么可能所有测试对象都会找到 ...
- Bug2算法的实现(RobotBASIC环境中仿真)
移动机器人智能的一个重要标志就是自主导航,而实现机器人自主导航有个基本要求--避障.之前简单介绍过Bug避障算法,但仅仅了解大致理论而不亲自动手实现一遍很难有深刻的印象,只能说似懂非懂.我不是天才,不 ...
- Canny边缘检测算法的实现
图像边缘信息主要集中在高频段,通常说图像锐化或检测边缘,实质就是高频滤波.我们知道微分运算是求信号的变化率,具有加强高频分量的作用.在空域运算中来说,对图像的锐化就是计算微分.由于数字图像的离散信号, ...
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析 ...
- SSE图像算法优化系列十三:超高速BoxBlur算法的实现和优化(Opencv的速度的五倍)
在SSE图像算法优化系列五:超高速指数模糊算法的实现和优化(10000*10000在100ms左右实现) 一文中,我曾经说过优化后的ExpBlur比BoxBlur还要快,那个时候我比较的BoxBlur ...
- 详解Linux内核红黑树算法的实现
转自:https://blog.csdn.net/npy_lp/article/details/7420689 内核源码:linux-2.6.38.8.tar.bz2 关于二叉查找树的概念请参考博文& ...
- 详细MATLAB 中BP神经网络算法的实现
MATLAB 中BP神经网络算法的实现 BP神经网络算法提供了一种普遍并且实用的方法从样例中学习值为实数.离散值或者向量的函数,这里就简单介绍一下如何用MATLAB编程实现该算法. 具体步骤 这里 ...
- Python学习(三) 八大排序算法的实现(下)
本文Python实现了插入排序.基数排序.希尔排序.冒泡排序.高速排序.直接选择排序.堆排序.归并排序的后面四种. 上篇:Python学习(三) 八大排序算法的实现(上) 1.高速排序 描写叙述 通过 ...
- C++基础代码--20余种数据结构和算法的实现
C++基础代码--20余种数据结构和算法的实现 过年了,闲来无事,翻阅起以前写的代码,无意间找到了大学时写的一套C++工具集,主要是关于数据结构和算法.以及语言层面的工具类.过去好几年了,现在几乎已经 ...
随机推荐
- 从0开始的Python学习003序列
sequence 序列 序列是一组有顺序数据的集合.不知道怎么说明更贴切,因为python的创建变量是不用定义类型,所以在序列中(因为有序我先把它看作是一个有序数组)的元素也不会被类型限制. 序列可以 ...
- hadoop 分析
Hadoop源代码分析(一) Google的核心竞争技术是它的计算平台.Google的大牛们用了下面5篇文章,介绍了它们的计算设施. GoogleCluster:http://research.goo ...
- 1.1 NCE21 Daniel Mendoza
1.text translation Two hundred years ago, boxing matches were very popular in England. At that time/ ...
- 爬虫系列---selenium详解
一 安装 pip install Selenium 二 安装驱动 chrome驱动文件:点击下载chromedriver (yueyu下载) 三 配置chromedrive的路径(仅添加环境变量即可) ...
- grep -v、-e、-E
在Linux的grep命令中如何使用OR,AND,NOT操作符呢? 其实,在grep命令中,有OR和NOT操作符的等价选项,但是并没有grep AND这种操作符.不过呢,可以使用patterns来模拟 ...
- windows做代理服务器让内部linux上网
fiddler代理上网 1 下载安装:http://www.telerik.com/fiddl er 2 设置代理,如下图 3 代理服务器信息 代理服务器的IP : 10.1.44.11 代理服务器的 ...
- Spring Security(三十六):12. Spring MVC Test Integration
Spring Security provides comprehensive integration with Spring MVC Test Spring Security提供与Spring MVC ...
- springboot项目利用Swagger2生成在线接口文档
Swagger简介. Swagger2是一款restful接口文档在线生成和在线调试工具.很多项目团队利用Swagger自动生成接口文档,保证接口文档和代码同步更新.在线调试.简单地说,你可以利用这个 ...
- keepalived--小白博客
一.HA集群中的相关术语 1.节点(node) 运行HA进程的一个独立主机,称为节点,节点是HA的核心组成部分,每个节点上运行着操作系统和高可用软件服务,在高可用集群中,节点有主次之分,分别称之为主节 ...
- websocket作用及意义
Browser已经支持http协议,为什么还要开发一种新的WebSocket协议呢?我们知道http协议是一种单向的网络协议,在建立连接后,它只允许Browser/UA(UserAgent)向WebS ...