python全栈开发day113-DBUtils(pymysql数据连接池)、Request管理上下文分析
1.DBUtils(pymysql数据连接池)
import pymysql
from DBUtils.PooledDB import PooledDB POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3,
# 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。
# 如:0 = None = never,
# 1 = default = whenever it is requested,
# 2 = when a cursor is created,
# 4 = when a query is executed,
# 7 = always
host='127.0.0.1',
port=3306,
user='root',
password='wcy123',
database='flask',
charset='utf8'
)
sql = "select * from student" def get_conn():
conn = POOL.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
return conn, cursor def reset_conn(conn, cursor):
conn.close()
cursor.close() def fetch_all(sql, *args):
conn, cursor = get_conn()
cursor.execute(sql, args)
ret_ = cursor.fetchall()
reset_conn(conn, cursor)
return ret_ def fetch_one(sql, *args):
conn, cursor = get_conn()
cursor.execute(sql, args)
ret_ = cursor.fetchone()
reset_conn(conn, cursor)
return ret_ ret1 = fetch_all(sql, )
print(ret1)
ret2 = fetch_one(sql, )
print(ret2)
sqlHelper
2.request管理上下文分析
1) 简单werkzeug服务启动:
from werkzeug.serving import run_simple
from werkzeug.wrappers import Request, Response @Request.application
def app(request):
print(request.method)
return Response("200 ok") run_simple("127.0.0.1", 9527, application=app)
werkzeug_demo
2) from threading import local
Python: threading.local是全局变量但是它的值却在当前调用它的线程当中 在threading module中,有一个非常特别的类local。一旦在主线程实例化了一个local,它会一直活在主线程中,并且又主线程启动的子线程调用这个local实例时,它的值将会保存在相应的子线程的字典中。 我们先看看测试代码: #!/usr/bin/python
# -*- coding: utf-8 -*-
# Description: test the threading.local class
# Create: 2008-6-4
# Author: MK2[fengmk2@gmail.com]
from threading import local, enumerate, Thread, currentThread local_data = local()
local_data.name = 'local_data' class TestThread(Thread):
def run(self):
print currentThread()
print local_data.__dict__
local_data.name = self.getName()
local_data.add_by_sub_thread = self.getName()
print local_data.__dict__ if __name__ == '__main__':
print currentThread()
print local_data.__dict__ t1 = TestThread()
t1.start()
t1.join() t2 = TestThread()
t2.start()
t2.join() print currentThread()
print local_data.__dict__
运行结果:
<_MainThread(MainThread, started)>
{'name': 'local_data'}
<TestThread(Thread-1, started)>
{}
{'add_by_sub_thread': 'Thread-1', 'name': 'Thread-1'}
<TestThread(Thread-2, started)>
{}
{'add_by_sub_thread': 'Thread-2', 'name': 'Thread-2'}
<_MainThread(MainThread, started)>
{'name': 'local_data'} 主线程中的local_data并没有被改变,而子线程中的local_data各自都不相同。 怎么这么神奇?local_data具有全局访问权,主线程,子线程都能访问它,但是它的值却是各当前线程有关,究竟什么奥秘在这里呢? 查看了一下local的源代码,发现就神奇在_path()方法中: def _patch(self):
key = object.__getattribute__(self, '_local__key')
d = currentThread().__dict__.get(key)
if d is None:
d = {}
currentThread().__dict__[key] = d
object.__setattr__(self, '__dict__', d) # we have a new instance dict, so call out __init__ if we have
# one
cls = type(self)
if cls.__init__ is not object.__init__:
args, kw = object.__getattribute__(self, '_local__args')
cls.__init__(self, *args, **kw)
else:
object.__setattr__(self, '__dict__', d) 每次调用local实例的属性前,local都会调用这个方法,找到它保存值的地方. d = currentThread().__dict__.get(key) 就是这个地方,确定了local_data值的保存位置。所以子线程访问local_data时,并不是获取主线程的local_data的值,在子线程第一次访问它是,它是一个空白的字典对象,所以local_data.__dict__为 {},就像我们的输出结果一样。 如果想在当前线程保存一个全局值,并且各自线程互不干扰,使用local类吧。
Python: threading.local是全局变量但是它的值却在当前调用它的线程当中
3)
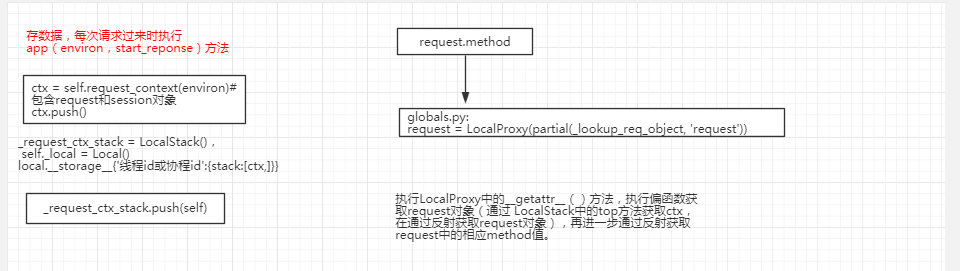
4) 什么时候执行的app.__call__函数,怎么把WSGIRequestHandler初始化传进入的从socket接收的内容request传给app处理函数的?
1.什么时候执行的app.__call__函数
run_simple(host, port, self, **options)中
通过inner()函数:
srv = make_server(hostname, port, application, threaded,
processes, request_handler,
passthrough_errors, ssl_context,
fd=fd)
# srv为BaseWSGIServer实例:
BaseWSGIServer(host, port, app, request_handler,
passthrough_errors, ssl_context, fd=fd)
request_handler 处理函数为WSGIRequestHandler
WSGIRequestHandler处理函数通过:
1、BaseWSGIServer的__init__,
2、HTTPServer.__init__(self, get_sockaddr(host, int(port),
self.address_family), handler)
3、TCPServer的__init__,
4、传给BaseServer的self.RequestHandlerClass = RequestHandlerClass
srv.serve_forever()
继承关系:BaseWSGIServer-》HTTPServer-》TCPServer-》BaseServer
:
def serve_forever(self, poll_interval=0.5):
self._handle_request_noblock() def _handle_request_noblock(self):
self.process_request(request, client_address)
def process_request(self, request, client_address):
self.finish_request(request, client_address)
def finish_request(self, request, client_address):
self.RequestHandlerClass(request, client_address, self)
# 处理函数实例化,就是WSGIRequestHandler实例化
初始化会执行self.handle()方法:
WSGIRequestHandler-》BaseHTTPRequestHandler-》StreamRequestHandler-》BaseRequestHandler:
def __init__(self, request, client_address, server):
self.request = request
self.client_address = client_address
self.server = server
self.setup()
try:
self.handle()
finally:
self.finish() WSGIRequestHandler:def handle(self):
rv = BaseHTTPRequestHandler.handle(self)
def handle(self):
self.handle_one_request() def handle_one_request(self):
return self.run_wsgi()
execute(self.server.app)
def execute(app):
application_iter = app(environ, start_response) 2. 怎么把WSGIRequestHandler初始化传进入的从socket接收的内容request传给app处理函数的? WSGIRequestHandler的祖辈类StreamRequestHandler,
在setup函数中将request处理后传给self.rfile
def setup(self):
self.connection = self.request
if self.timeout is not None:
self.connection.settimeout(self.timeout)
if self.disable_nagle_algorithm:
self.connection.setsockopt(socket.IPPROTO_TCP,
socket.TCP_NODELAY, True)
self.rfile = self.connection.makefile('rb', self.rbufsize)
if self.wbufsize == 0:
self.wfile = _SocketWriter(self.connection)
else:
self.wfile = self.connection.makefile('wb', self.wbufsize) 在WSGIRequestHandler中将self.rfile传给environ:
environ = {
'wsgi.version': (1, 0),
'wsgi.url_scheme': url_scheme,
'wsgi.input': self.rfile,
'wsgi.errors': sys.stderr,
'wsgi.multithread': self.server.multithread,
'wsgi.multiprocess': self.server.multiprocess,
'wsgi.run_once': False,
'werkzeug.server.shutdown': shutdown_server,
'SERVER_SOFTWARE': self.server_version,
'REQUEST_METHOD': self.command,
'SCRIPT_NAME': '',
'PATH_INFO': wsgi_encoding_dance(path_info),
'QUERY_STRING': wsgi_encoding_dance(request_url.query),
'REMOTE_ADDR': self.address_string(),
'REMOTE_PORT': self.port_integer(),
'SERVER_NAME': self.server.server_address[0],
'SERVER_PORT': str(self.server.server_address[1]),
'SERVER_PROTOCOL': self.request_version
}
通过application_iter = app(environ, start_response)传给app,在通过app传给request实例化:
request = app.request_class(environ)
什么时候执行的app.__call__函数
5)简要流程:
问题一:flask和django的区别:
对于django来说,内部组件特别多,自身功能强大,有点大而全,而flask,内置组件很少,但是它的第三方组件很多,扩展性强,有点短小精悍,而它们之间也有相似之处,
因为它们两个框架都没有写sockte,都是基于wsgi协议做的,在此之外,flask框架中的上下文管理较为耀眼。
相同点:它们两个框架都没有写sockte,都是基于wsgi协议做的
请求相关数据传递的方式不同:django:通过传递request参数取值
flask:见问题二
组件不同:django组件多
flask组件少,第三方组件丰富 问题1.1: flask上下文管理:
简单来说,falsk上下文管理可以分为三个阶段:
1、请求进来时,将请求相关的数据放入上下问管理中
2、在视图函数中,要去上下文管理中取值
3、请求响应,要将上下文管理中的数据清除
详细点来说:
1、请求刚进来,将request,session封装在RequestContext类中,app,g封装在AppContext类中,并通过LocalStack将requestcontext和appcontext放入Local类中
2、视图函数中,通过localproxy--->偏函数--->localstack--->local取值
3、请求相应时,先执行save.session()再各自执行pop(),将local中的数据清除
简要流程
python全栈开发day113-DBUtils(pymysql数据连接池)、Request管理上下文分析的更多相关文章
- Python全栈开发【面向对象进阶】
Python全栈开发[面向对象进阶] 本节内容: isinstance(obj,cls)和issubclass(sub,super) 反射 __setattr__,__delattr__,__geta ...
- Python全栈开发【面向对象】
Python全栈开发[面向对象] 本节内容: 三大编程范式 面向对象设计与面向对象编程 类和对象 静态属性.类方法.静态方法 类组合 继承 多态 封装 三大编程范式 三大编程范式: 1.面向过程编程 ...
- Python全栈开发【模块】
Python全栈开发[模块] 本节内容: 模块介绍 time random os sys json & picle shelve XML hashlib ConfigParser loggin ...
- Python全栈开发【基础三】
Python全栈开发[基础三] 本节内容: 函数(全局与局部变量) 递归 内置函数 函数 一.定义和使用 函数最重要的是减少代码的重用性和增强代码可读性 def 函数名(参数): ... 函数体 . ...
- python 全栈开发之路 day1
python 全栈开发之路 day1 本节内容 计算机发展介绍 计算机硬件组成 计算机基本原理 计算机 计算机(computer)俗称电脑,是一种用于高速计算的电子计算机器,可以进行数值计算,又可 ...
- python全栈开发-Day2 布尔、流程控制、循环
python全栈开发-Day2 布尔 流程控制 循环 一.布尔 1.概述 #布尔值,一个True一个False #计算机俗称电脑,即我们编写程序让计算机运行时,应该是让计算机无限接近人脑,或者说人 ...
- python全栈开发中级班全程笔记(第二模块、第四章(三、re 正则表达式))
python全栈开发笔记第二模块 第四章 :常用模块(第三部分) 一.正则表达式的作用与方法 正则表达式是什么呢?一个问题带来正则表达式的重要性和作用 有一个需求 : 从文件中读取所有联 ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)
python全栈开发中级班全程笔记 第三章:员工信息增删改查作业代码 作业要求: 员工增删改查表用代码实现一个简单的员工信息增删改查表需求: 1.支持模糊查询,(1.find name ,age fo ...
随机推荐
- 在vue中关于element UI 中表格实现下载功能,表头添加按钮,和点击事件失效的解决办法。
因为在element 中表格是使用el-table的形式通过数据来支撑结构,所以,表格的样式没有自己写的灵活,所以有了没法添加按钮的烦恼.下面是解决的方法. 准备工作: 一.下载npm安装包两个 1. ...
- Vue(三)指令
v-text:更新元素的text内容 <template> <div class="about"> <p v-text="msg" ...
- Java:IO流-流的操作规律和转换流
首先我们先来了解一些IO流基本知识. 一,基本知识概括 具体的IO流有很多种,针对不同的应用场景应该使用相应的流对象.但怎么确定应该使用哪个IO流对象呢? 一般要有四个明确: 1)明确源和目的 源:I ...
- RTC及sensor时间同步
https://blog.csdn.net/dai_jing/article/details/38147419 ----------------------------- linux 的系统时间有时跟 ...
- 2018-2019-2 20165232《网络对抗技术》Exp1 缓冲区溢出实验
2018-2019-2 20165232<网络对抗技术>Exp1 缓冲区溢出实验 实验点1:逆向及Bof基础实践 实践任务 用一个pwn1文件. 该程序正常执行流程是:main调用foo函 ...
- 财务平台亿级数据量毫秒级查询优化之elasticsearch原理解析
财务平台进行分录分表以后,随着数据量的日渐递增,业务人员对账务数据的实时分析响应时间越来越长,体验性慢慢下降,之前我们基于mysql的性能优化做了一遍,可以说基于mysql该做的优化已经基本上都做了, ...
- Maven之阿里云镜像仓库配置
方式一:全局配置:修改maven的setting.xml配置 在mirrors节点下面添加子节点: <mirror> <id>nexus-aliyun</id> & ...
- python文本操作—读、写
文本文件存储的数据有很多,我们需要把这些文本里的内容读出来,然后在浏览器上面显示. 1.读取整个文本文件 格式: with open(路径) as 变量: 变量.read() 关键字with作用:在不 ...
- 浏览器将URL变成一个屏幕上显示的网页的过程?
前言 一个浏览器是怎么工作的? 正文 URL变网页过程: 1.浏览器通过http或https协议,向服务端请求页面 2.将请求过来的HEML代码通过解析,构建DOM树 3.计算DOM树上的CSS属性 ...
- PC端判断浏览器类型及移动端判断移动设备类型
浏览器代理检测,可以检测出来用户使用的浏览器类型,也可以检测浏览器所在的操作系统 navigator.userAgent (1).判断浏览器类型 var t = navigator.userAgent ...