关于ML.NET v0.8的发布说明

ML.NET允许您创建和使用针对场景的机器学习模型,以实现常见任务,如情绪分析,问题分类,预测,推荐,欺诈检测,图像分类等。您可以使用ML.NET示例在GitHub仓库中查看这些常见任务 。ML.NET 0.8发布之际,我们可以解释为什么到目前为止它是最好的版本!此版本侧重于为推荐方案添加改进的支持,以特征重要性的形式添加模型可解释性,通过预览内存数据集提供可调试性,API缓存(如缓存,过滤等)。
以下是此版本的一些亮点。
- 全新推荐方案
- 改进了可调试性
- 模型可解释性
- 其他API改进
全新推荐方案

推荐系统可以为产品目录,歌曲,电影等中的产品生成推荐列表。像Netflix,亚马逊,Pinterest这样的产品在过去十年中已经保持公平合理原则使用类似推荐的方案。
ML.NET使用Matrix Factorization和Field Aware Factorization基于机器的推荐方法来实现以下场景。通常,Field Aware Factorization机器是矩阵分解的更一般化的情况,并允许传递额外的元数据。
使用ML.NET 0.8,我们为Matrix Factorization添加了另一种方案,可以提供建议。
| 推荐场景 | 推荐解决方案 | 链接到示例 |
|---|---|---|
| 产品建议基于产品ID,评级,用户ID和其他元数据,如产品描述,用户人口统计(年龄,国家等) | 现场感知分解机器 | ML.NET 0.3(此处示例) |
| 产品建议仅基于产品ID,评级和用户ID | 矩阵分解 | ML.NET 0.7(此处示例) |
| 基于产品ID和共同购买的产品ID的产品建议 | 一类矩阵分解 | ML.NET 0.8中的新功能(此处示例) |
即使您只有商店的历史订单购买数据,仍然可以提供产品建议。
这是一种流行的场景,因为在许多情况下您可能没有可用的评级。
使用历史购买数据,您仍然可以通过向用户提供“经常购买”产品列表来构建建议。
以下快照来自Amazon.com,其中推荐基于用户选择的产品的一组产品。

我们现在在ML.NET 0.8中支持这种情况,您可以尝试这个基于亚马逊共同购买数据集执行产品推荐的示例。
通过预览数据提高可调试性

在大多数情况下,当开始使用管道并加载数据集时,查看加载到ML.NET DataView中的数据非常有用,甚至正如所料在经过一些中间转换步骤后查看它以确保数据转换。
首先,您可以检查DataView的架构。
您需要做的就是将鼠标悬停在IDataView对象上,展开它,然后查找Schema属性。
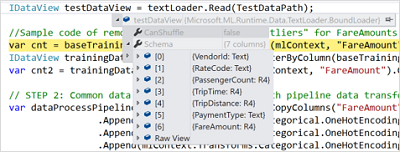
如果要查看DataView中加载的实际数据,可以执行动画下方显示的步骤。
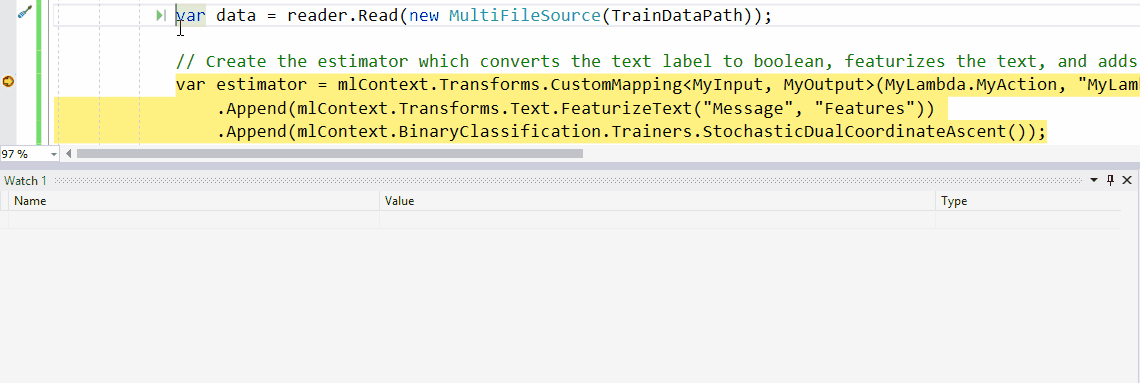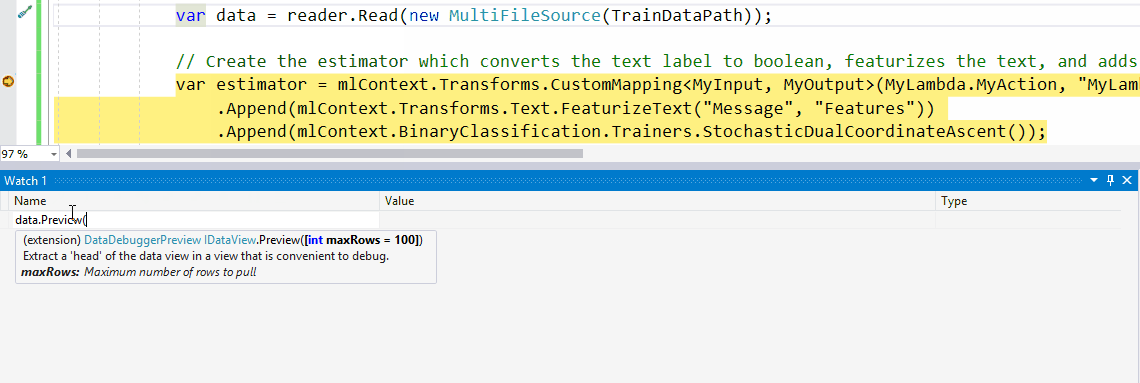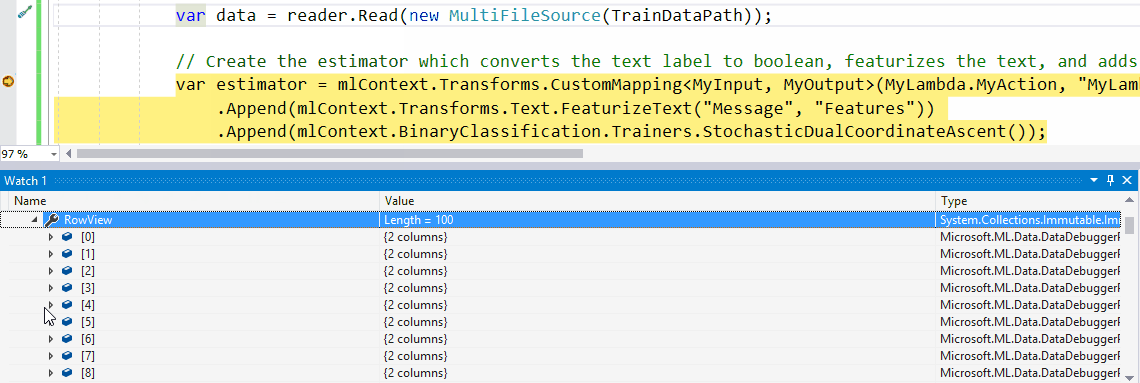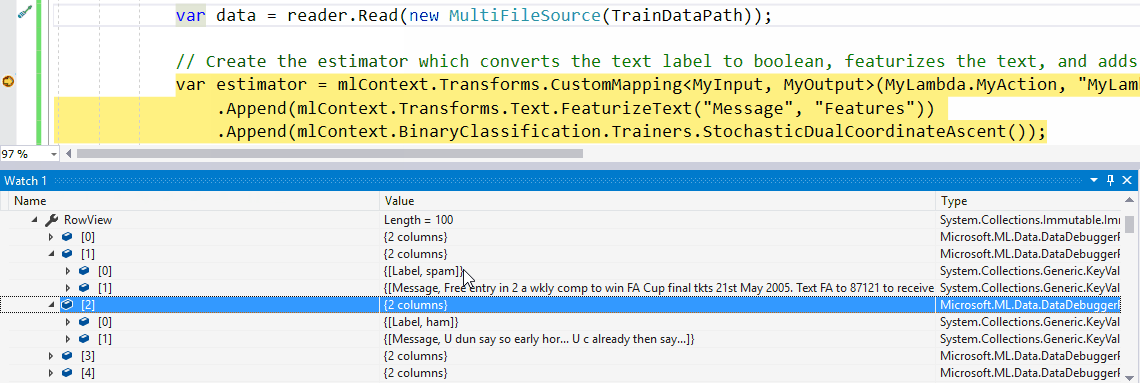
具体步骤是:
- 在调试时,打开Watch窗口。
- 输入您的DataView对象的变量名称(在本例中
testDataView)并Preview()为其调用方法。 - 现在,单击要检查的行。这将显示DataView中加载的实际数据。
默认情况下,我们在ColumnView和RowView中输出前100个值。但是可以通过将您感兴趣的行数传递给Preview()函数作为参数来改变,例如Preview(500)。
模型可解释性
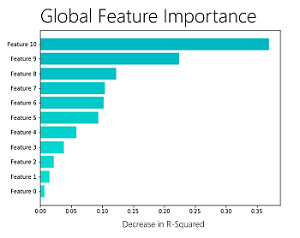
在ML.NET 0.8版本中,我们已经包含了我们在Microsoft内部使用的模型可解释性API,以帮助机器学习开发人员更好地理解模型的功能重要性(“整体功能重要性”)并创建可以解释的高容量模型其他(“广义附加模型”)。
总体特征重要性使人们了解哪些特征对于模型而言总体上最重要。在创建机器学习模型时,通常不足以简单地进行预测并评估其准确性。如上图所示,功能重要性可帮助您了解哪些数据特征对模型最有价值,以便进行良好预测。例如,在预测汽车价格时,某些功能更重要,如里程和品牌/品牌,而其他功能可能会影响较少,如汽车的颜色。
通过名为“置换特征重要性”(PFI)的技术实现模型的“整体特征重要性”。PFI通过询问“如果特征的值被设置为随机值(在整个示例中置换)对模型有什么影响来测量特征的重要性?”。
PFI方法的优点在于它与模型无关 - 它适用于任何可以评估的模型 - 它可以使用任何数据集而不仅仅是训练集来计算特征重要性。
您可以像这样使用PFI来生成功能导入,其代码如下所示:
// Compute the feature importance using PFI
var permutationMetrics = mlContext.Regression.PermutationFeatureImportance(model, data); // Get the feature names from the training set
var featureNames = data.Schema.GetColumns()
.Select(tuple => tuple.column.Name) // Get the column names
.Where(name => name != labelName) // Drop the Label
.ToArray(); // Write out the feature names and their importance to the model's R-squared value
for (int i = ; i < featureNames.Length; i++)
Console.WriteLine($"{featureNames[i]}\t{permutationMetrics[i].rSquared:G4}");
您将在控制台中获得与以下指标相似的输出:
Console output:
Feature Model Weight Change in R - Squared
--------------------------------------------------------
RoomsPerDwelling 50.80 -0.3695
EmploymentDistance -17.79 -0.2238
TeacherRatio -19.83 -0.1228
TaxRate -8.60 -0.1042
NitricOxides -15.95 -0.1025
HighwayDistance 5.37 -0.09345
CrimesPerCapita -15.05 -0.05797
PercentPre40s -4.64 -0.0385
PercentResidental 3.98 -0.02184
CharlesRiver 3.38 -0.01487
PercentNonRetail -1.94 -0.007231
请注意,在当前的ML.NET v0.8中,PFI仅适用于基于二进制分类和回归的模型,但我们将在即将发布的版本中扩展到其他ML任务。
有关使用PFI分析模型的功能重要性的完整示例,请参阅ML.NET存储库中的示例。
广义附加模型或(GAM)具有非常可解释的预测。它们在易于理解方面类似于线性模型,但更灵活,可以具有更好的性能,并且还可以进行可视化/绘图以便于分析。
可在此处找到如何训练GAM模型,检查和解释结果的示例用法。
ML.NET 0.8中的其他API改进
在此版本中,我们还为API添加了其他增强功能,这些增强功能有助于过滤DataViews中的行,缓存数据,允许用户将数据保存为IDataView(IDV)二进制格式。您可以在此处了解这些功能。
过滤DataView中的行

有时您可能需要过滤用于训练模型的数据。例如,由于任何原因(如“异常值”数据),您可能需要删除特定列的值低于或高于某些边界的行。
现在可以使用FilterByColumn()API之类的其他过滤器来完成此操作,例如在ML.NET示例中此示例应用程序的以下代码中,我们希望仅保留介于1美元和150美元之间的付款行,因为对于此特定情况,因为考虑高于150美元“异常值”(极端数据扭曲模型)和低于1美元可能是数据错误:
IDataView trainingDataView = mlContext.Data.FilterByColumn(baseTrainingDataView, "FareAmount", lowerBound: , upperBound: );
得益于上面提到的Visual Studio中添加的DataView预览,您现在可以检查DataView中的过滤数据。
其他示例代码可在此处获取。

一些估算器多次迭代数据。您可以选择缓存数据,以便有时加快训练执行速度,而不是始终从文件中读取数据。
当训练使用针对相同数据运行多次迭代的OVA(One Versus All)训练器时,以下是一个很好的示例。通过消除多次从磁盘读取数据的需要,您可以将模型培训时间减少多达50%:
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("Area", "Label")
.Append(mlContext.Transforms.Text.FeaturizeText("Title", "TitleFeaturized"))
.Append(mlContext.Transforms.Text.FeaturizeText("Description", "DescriptionFeaturized"))
.Append(mlContext.Transforms.Concatenate("Features", "TitleFeaturized", "DescriptionFeaturized"))
//Example Caching the DataView
.AppendCacheCheckpoint(mlContext)
.Append(mlContext.BinaryClassification.Trainers.AveragedPerceptron(DefaultColumnNames.Label,
DefaultColumnNames.Features,
numIterations: ));
实现此示例代码,并在ML.NET Samples repo 中的此示例应用程序中测量执行时间。
可在此处找到其他测试示例。
启用以IDataView(IDV)二进制格式保存和加载数据以提高性能

在转换数据后保存数据有时很有用。例如,您可能已将所有文本特征化为稀疏向量,并希望使用不同的预训练模型执行重复实验,而无需不断重复数据转换。
IDV格式是ML.NET提供的二进制数据视图文件格式。
以IDV格式保存和加载文件通常比使用文本格式快得多,因为它是压缩的。
另外,因为它已经在“文件内”进行了模式化,所以您不需要像使用常规TextLoader那样指定列类型,因此除了更快之外,使用的代码也更简单。
可以使用以下简单的代码行读取二进制数据文件:
mlContext.Data.ReadFromBinary("pathToFile");
可以使用以下代码编写二进制数据文件:
mlContext.Data.SaveAsBinary("pathToFile");
为异常检测等时间序列问题启用状态预测引擎

ML.NET 0.7基于时间序列启用了异常检测方案。但是,预测引擎是无状态的,这意味着每次要确定最新数据点是否是异常时,您还需要提供历史数据。这是不自然的。
预测引擎现在可以保持到目前为止看到的时间序列数据的状态,因此您现在可以通过提供最新的数据点来获得预测。这是通过使用CreateTimeSeriesPredictionFunction()而不是使用CreatePredictionFunction()。
可以在此处找到示例用法。
开始吧!

如果你还没有开始使用ML.NET。这些资源对你或许有帮助:
- Microsoft Docs ML.NET指南中的教程和资源
- 机器学习GitHub仓库中的代码示例
- 这里介绍了用于理解新API的重要ML.NET概念
- 可以在此处找到“如何”指南,其中显示了如何将这些API用于各种场景
关于ML.NET v0.8的发布说明的更多相关文章
- 关于ML.NET v0.6的发布说明
ML.NET 0.6版本提供了几项令人兴奋的新增功能: 用于构建和使用机器学习模型的新API 我们主要关注的是发布用于构建和使用模型的新ML.NET API的第一次迭代.这些新的,更灵活的API支持新 ...
- 关于ML.NET v0.5的发布说明
适逢.NET Conf 2018举办,ML.NET v0.5也正式宣布发布了.作为面向.NET开发人员的跨平台开源机器学习框架,新的预览版本在不断演变,每次发布除了有新的功能添加,API也会进行调整, ...
- 关于ML.NET v0.7的发布说明
我们很高兴宣布推出ML.NET 0.7--面向.NET开发人员的最新版本的跨平台和开源机器学习框架(ML.NET 0.1发布于// Build 2018).此版本侧重于为基于推荐的ML任务提供更好的支 ...
- jQuery WeUI V0.4.2 发布
http://www.oschina.net/news/71590/jquery-weui-v0-4-2 jQuery WeUI V0.4.2 发布了! jQuery WeUI 中使用的是官方WeUI ...
- [译]基于ASP.NET Core 3.0的ABP v0.21已发布
基于ASP.NET Core 3.0的ABP v0.21已发布 在微软发布仅仅一个小时后, 基于ASP.NET Core 3.0的ABP v0.21也紧跟着发布了. v0.21没有新功能.它只是升级到 ...
- 关于ML.NET v1.0 的发布说明
今天,我们很高兴宣布发布 ML.NET 1.0.ML.NET 是一个免费的.跨平台的开源机器学习框架,旨在将机器学习(ML)的强大功能引入.NET 应用程序. ML.NET GitHub:https: ...
- Visual Studio Code v0.9.1 发布
微软的跨平台编辑器 Visual Studio Code v0.9.1 已经发布,官方博客上发布文章Visual Studio Code – October Update (0.9.1):http:/ ...
- 轻量级模块化开发框架 Hasor 核心模块 v0.0.2 发布
首先引用Wiki的介绍一下Hasor: “Hasor是一款开源框架.它是为了解决企业模块化开发中复杂性而创建的.Hasor遵循简单的依赖.单一职责,在开发多模块企业项目中更加有调理.然 而Ha ...
- LAL v0.32.0发布,更好的支持纯视频流
Go语言流媒体开源项目 LAL 今天发布了v0.32.0版本.距离上个版本刚好一个月时间,LAL 依然保持着高效迭代的状态. LAL 项目地址:https://github.com/q19120177 ...
随机推荐
- 使用Kazoo操作ZooKeeper服务治理
单机服务的可靠性及可扩展性有限,某台服务宕机可能会影响整个系统的正常使用:分布式服务能够有效地解决这一问题,但同时分布式服务也会带来一些新的问题,如:服务发现(新增或者删除了服务如何确保能让客户端知道 ...
- .Karma+Jasmine+karma-coverage
单元测试(模块测试)是开发者编写的一小段代码,用于检验被测代码的一个很小的.很明确的功能是否正确.通常而言,一个单元测试是用于判断某个特定条件(或者场景)下某个特定函数的行为. Karma是一个基于N ...
- Use try-with-resources
public void doQueries() throws MyException{ // First try-with-resources. try ( Connection con = Driv ...
- git 的常用命令(未完待补充)
一.初始化 git git init 这样会默认创建 master 分支 二.查看当前状态 git status 查看 git 的默认状态 三.创建一个文件,并把它添加到 git 仓库,使用 git ...
- 磁共振成像SENSE 并行加速重建 g-factor计算方法(待更新)
MRI SENSE 并行图像加速重建 g-factor计算方法: Matlab代码如下: function g=gfactor_noise(map,LOSS,Rx,Ry) % map -> se ...
- [JZOJ3588]【中山市选2014】J语言(表达式解析+栈)
Description J语言作为一门编程语言,诞生于20世纪90年代.............. 好学的小H今天又学到了一种新东西——J语言.显然,J语言的背景已经被小H忘得一干二净了,但是小H仍然 ...
- wait event & wake up
在linux驱动中一个常用的场景, 驱动需要等待中断的响应, 才得以执行后续的代码,达到一个原子操作的目的 /* 静态申请队列 */ static DECLARE_WAIT_QUEUE_HEAD(s_ ...
- Python3定时短信获得天气
getWeather 脚本链接:https://github.com/Mrlshadows/getWeather Python环境为 python3 两个API 注册后即可使用免费版本的服务 心知天气 ...
- linux下tomcat服务器的启动和关闭以及查看实时打印日志
本页面中的操作都在tomcat的bin目录下 <一> 一般我都是使用: ./shutdom.sh //关闭tomcat ./startup.sh //开启tomcat服务 <二> ...
- Mysql postgresql 行列转换
一.第一种 原数据表 转换后 DROP TABLE IF EXISTS tempdynamic; CREATE TEMPORARY TABLE tempdynamic ( SELECT p.fsPay ...