Lucene 01 - 初步认识全文检索和Lucene
目录
1 搜索简介
1.1 搜索实现方案
(1) 传统实现方案
根据用户输入的关键词(java), 应用服务器使用SQL语句查询数据库, 将查询到的结果返回给用户.
特点: 如果数据量很大, 用户量大, 数据库服务器压力随之增大, 导致查询速度变慢.
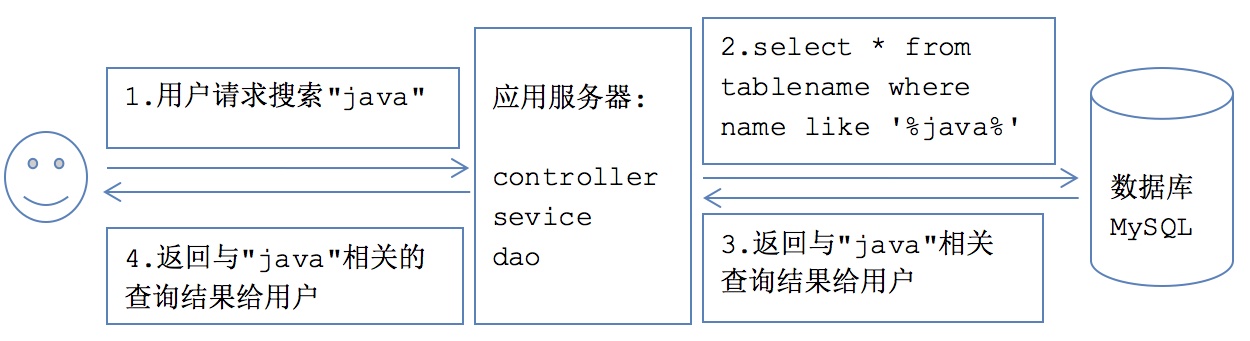
(2) Lucene实现方案
根据用户输入的关键词(java), 应用服务器通过Lucene提供的API查询索引库, 索引库返回搜索结果给应用服务器, 服务器再将查询到的结果返回给用户
特点: 解决数据量大、用户量大、业务系统对查询速度要求高的业务需求(如实时查询).

1.2 数据查询方法
1.2.1 顺序扫描法
举例: 有多个文件A、B、C...要求找出文件内容包含有关键字[java]的所有文件.
顺序扫描法的思路: 从A文件开始扫描查找, 再扫描B文件...一直扫描完最后一个文件, 才能得到所有包含了java内容的文件.
特点: 文件数量越多, 查找起来就很慢.
1.2.2 倒排索引法(反向索引)
举例: 使用新华字典查找汉字, 先找到汉字的偏旁部首, 再根据偏旁部首对应的页码找到目标汉字.
以Lucene为例建立倒排索引:
文件一(编号是1): we like java java java
文件二(编号是2): we like Lucene Lucene Lucene
| term | (doc, freq) | (pos) |
|---|---|---|
| we | (1, 1) (2, 1) | (0) (0) |
| like | (1, 1) (2, 1) | (1) (1) |
| java | (1, 3) | (2, 3, 4) |
| Lucene | (2, 3) | (2, 3, 4) |
说明:
- 倒排索引就是建立词语与文件的对应关系(词语在什么文件出现, 出现了多少次, 在什么位置出现);
- 搜索时, 根据用户输入的关键词, 直接在索引中进行查询, 速度更快.
1.3 搜索技术应用场景
(1) 单机软件搜索(Office, Eclipse...);
(2) 站内搜索(京东, 淘宝);
(3) 垂直搜索(限定行业搜索, 如: 医疗, 教育);
(4) 平台搜索(Google, 百度, 360, 搜狗).
2 Lucene简介
2.1 Lucene是什么
Lucene官网: http://lucene.apache.org/
Lucene是Apache软件基金会下的一个子项目, 是一个成熟、免费、开源的全文检索引擎工具包. 它提供了一套简单易用的API, 方便在目标系统中实现全文检索功能. 目前已有很多应用系统的搜索功能是基于Lucene来实现, 如Eclipse帮助系统的搜索功能.
Lucene能够为文本类型的数据建立索引, 只需要把数据转换成文本格式, Lucene就可以对文档进行索引和搜索. 比如常见的word文档、html文档、pdf文档, 首先将文档内容转换成文本格式, 交给Lucene进行索引, 把建立好的索引保存在硬盘或者内存中. 然后根据用户输入的查询条件, 在索引文件中查找, 将查询结果返回给用户.
2.2 全文检索是什么
计算机通过索引程序扫描文章中的每一个词, 对它们建立索引, 指明该词在文章中出现的次数和位置. 当用户查询时, 检索程序根据建立好的索引进行查找, 并将查询结果返回给用户.
2.3 Lucene与搜索引擎的区别
Lucene是一个用于实现全文检索的工具类库, 相当于汽车的发动机;
搜索引擎是基于全文检索, 独立运行的软件系统, 相当于汽车.
3 全文检索流程
3.1 索引和检索流程图
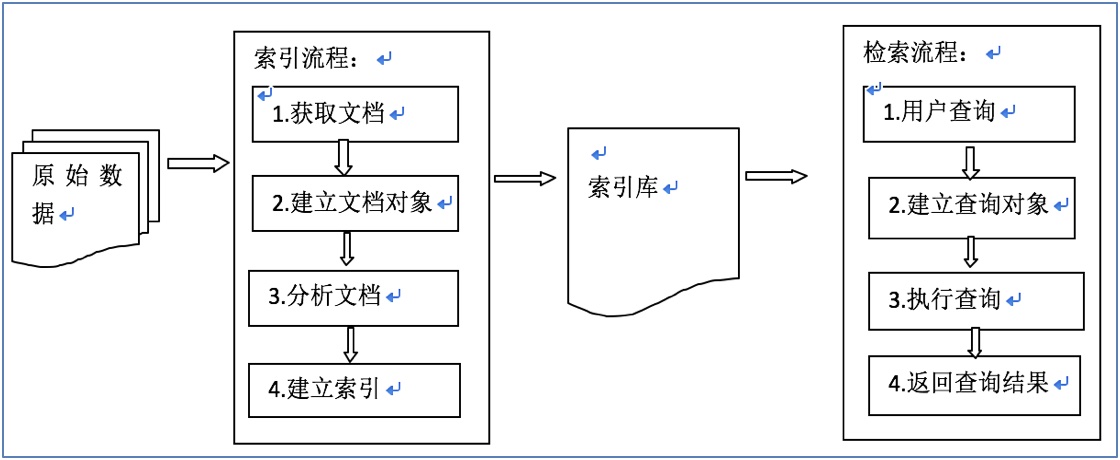
3.2 索引流程
(1) 原始数据
保存在关系数据库中的数据, 存放在硬盘上的文件, 网络上的网页文件等都可作为原始数据.
(2) 获取文档
通过JDBC操作数据库获取关系数据库中的数据, 通过IO操作获取硬盘上的文件, 通过爬虫(蜘蛛)程序获取网络上的网页文件.
信息采集开源软件
Solr, 是Apache的一个子项目, 是一个独立的企业级搜索应用服务器, 对外提供类似于Web-service的API, 用户可通过HTTP请求, 向搜索引擎服务器提交一定格式的XML文件, 也可通过HTTP的Get操作提出查询请求, 并得到XML格式的返回结果 -- 支持从关系数据库、xml文档中提取原始数据.
Nutch, 是Apache的一个子项目, 包括大规模爬虫工具, 能够抓取和分辨Web网站数据.
jsoup, 是一款Java编写的HTML解析器, 可直接解析某个URL地址、HTML文本内容. 它提供了一套非常省力的API, 可通过DOM, CSS以及类似于jQuery的操作方法来获取和操作数据.
(3) 建立文档对象
文档(Document)对象, 相当于关系型数据库中的一条记录;
一个文档对象可以包含多个域(Field), 域相当于数据库表中的一个字段.

(4) 分析文档取得关键词
将原始数据转换成文档对象, 使用分析器(分词器)对文档对象的域中的内容切分成一个个词语, 方便后续建立索引.
(5) 建立倒排索引
建立词语与文档的对应关系(词语在什么文档出现, 出现了多少次, 在什么位置出现), 将其保存到索引库中.
3.3 检索流程
(1) 用户
用户可以是自然人, 也可以是程序.
(2) 用户查询
说明: 需要为用户提供一个输入关键词的界面, 如:

(3) 建立查询对象
说明: 根据用户输入的关键词, 建立查询对象(Query), Query对象会生成查询的语法.
如: bookName:Java, 表示查询图书名称域中含有Java相关的内容.
(4) 执行查询
说明: 根据建立的查询对象, 以及生成的查询语法, 在索引库中查找目标内容, 将查询结果返回给用户.
(5) 返回查询结果
说明: 提供一个友好的搜索结果显示页面(如对搜索结果进行排序显示,关键词高亮显示等).
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Lucene 01 - 初步认识全文检索和Lucene的更多相关文章
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- 【手把手教你全文检索】Lucene索引的【增、删、改、查】
前言 搞检索的,应该多少都会了解Lucene一些,它开源而且简单上手,官方API足够编写些小DEMO.并且根据倒排索引,实现快速检索.本文就简单的实现增量添加索引,删除索引,通过关键字查询,以及更新索 ...
- Lucene学习总结:全文检索的基本原理
一.总论 根据http://lucene.apache.org/java/docs/index.html定义: Lucene是一个高效的,基于Java的全文检索库. 所以在了解Lucene之前要费一番 ...
- Lucene:信息检索与全文检索
目录 信息检索的概念 信息检索技术的分类 全文检索与数据库查询对比 全文检索工具一般由三部分构成 全文检索中建立索引和进行检索的流程 索引里面究竟存什么 如何创建索引 如何对索引进行检索 Lucene ...
- 大型运输行业实战_day15_1_全文检索之Lucene
1.引入 全文检索简介: 非结构化数据又一种叫法叫全文数据.从全文数据(文本)中进行检索就叫全文检索. 2.数据库搜索的弊端 案例 : select * from product whe ...
- 全文检索技术---Lucene
1 Lucene介绍 1.1 什么是Lucene Lucene是apache下的一个开源的全文检索引擎工具包.它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现 ...
- 全文检索(Lucene&Solr)
全文检索(Lucene&Solr) 1)什么是全文检索?为什么需要全文检索? 结构化数据(mysql等)方便查询,而非结构化数据(如多篇文章)是难以查询到自己需要的,所以要使用全文检索. 全文 ...
- 全文检索框架---Lucene
一.什么是全文检索 1.数据分类 我们生活中的数据总体分为两种:结构化数据和非结构化数据. 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等. 非结构化数据:指不定长或无固定格式 ...
- 全文检索以及Lucene的应用
全文检索 一.什么是全文检索? 就是在检索数据,数据的分类: 在计算机当中,比如说存在磁盘的文本文档,HTML页面,Word文档等等...... 1.结构化数据 格式固定,长度固定,数据类型固定等等, ...
随机推荐
- swool配置ssl
1 yum install openssl --enable-openssl -y 2 切换在swoole 安装目录 cd /usr/local/swoole 3 ./configure --en ...
- 我的 FPGA 学习历程(13)—— 电子钟项目
在秒表上一些其他模块就可以变成电子钟了,使用以下约定: 使用 KEY[0] 作为复位按键,复位后显示 00:00. 使用 KEY[1] 作为调整/暂停按键,暂停时电子钟调整的两个灯管保持 1Hz 的频 ...
- go 统计目录大小
文件大小获取 // 这里获取的是 FileInfo 对象 fi, _ := os.Stat(filepath) FileInfo 定义如下: type FileInfo interface { Nam ...
- dubbo+zookeeper报错:com.alibaba.dubbo.rpc.RpcException: Failed to invoke the method
com.alibaba.dubbo.rpc.RpcException: Failed to invoke the method可能的错误原因有三个前两个是从网上摘得, 第三个是自己解决的 1.需要进行 ...
- using Sysyem.Net.Http命名空间引用不了的解决方案
1.查看.Net Framework的框架是否是在4.5之上,如果不是要下载4.5之上的目标框架. 2.在引用器里面添加using System.Net.Http命名空间 选择项目列表中的“引用”-- ...
- 漏测BUG借鉴
2. websocket: 用户频繁刷新,后台每次请求新的排队,内存溢出 1. websocket: 北京中心连接正常,外地中心,连接超时,应考虑到外地延迟问题
- tyflow雨滴在物体上滑落测试
http://docs.tyflow.com/download/
- prometheus — 基于文件的服务发现
基于文件的服务发现方式不需要依赖其他平台与第三方服务,用户只需将要新的target信息以yaml或json文件格式添加到target文件中 ,prometheus会定期从指定文件中读取target信息 ...
- python爬虫第三天
DebugLog实战 有时候我们需要在程序运行时,一边运行一边打印调试日志.此时需要开启DebugLog. 如何开启: 首先将debugleve ...
- What is volatile?
What is volatile? 一次偶然的机会(java多线程电梯作业寻求多个进程分享变量的方法),接触到了volatile,因此我查阅了相关的材料,对这部分做了一些了解,在这里和大家分享一下. ...