基于spark实现并行化Apriori算法
详细代码我已上传到github:click me
一、 实验要求
在 Spark2.3 平台上实现 Apriori 频繁项集挖掘的并行化算法。要求程序利用 Spark 进行并行计算。
二、算法设计
2.1 设计思路
变量定义
- D为数据集,设Lk是k项频繁项集,Ck是k项候选集,每一行数据定义为一笔交易(transaction),交易中的每个商品为项item。
- 支持度: support, 即该项集在数据集D中出现的次数
算法流程
- 单机Apriori算法的主要步骤如下:
- 获取输入数据,产生频繁1项集,以及和I作为候选集,扫描数据集D,获取候选集C1的支持度,并找出最小支持度min_sup的元素作为频繁1项集L1.
- 扫描数据集D,获取候选集Ck的支持度,并找出其中满足最小支持度的元素作为频繁k项集Lk
- 通过频繁k项集Lk产生k+1候选集Ck+1
- 通过迭代步骤2和3,直到找不到k+1项集结束
- 单机Apriori算法的主要步骤如下:
并行化设计的思路主要是考虑将对于支持度计数的过程使用wordcount来进行统计。
2.2 并行化算法设计
Apriori算法产生频繁项集有两个特点:第一,它是逐层的,即从频繁1-项集到频繁k-项集;第二,它使用产生-测试的策略来发现频繁项,每次迭代后都由前一次产生的频繁项来产生新的候选项,然后对新产生的候选项集进行支持度计数得到新的频繁项集。根据算法的特点,我们将算法分为两个阶段:
如下图1.1算法的并行化框架图,主节点每次迭代时需要将候选项集以广播的形式分发到每个从节点,每个从节点收到之后进行一些列的操作得到新的频繁项集,如此反复直至求得最大频繁项集。
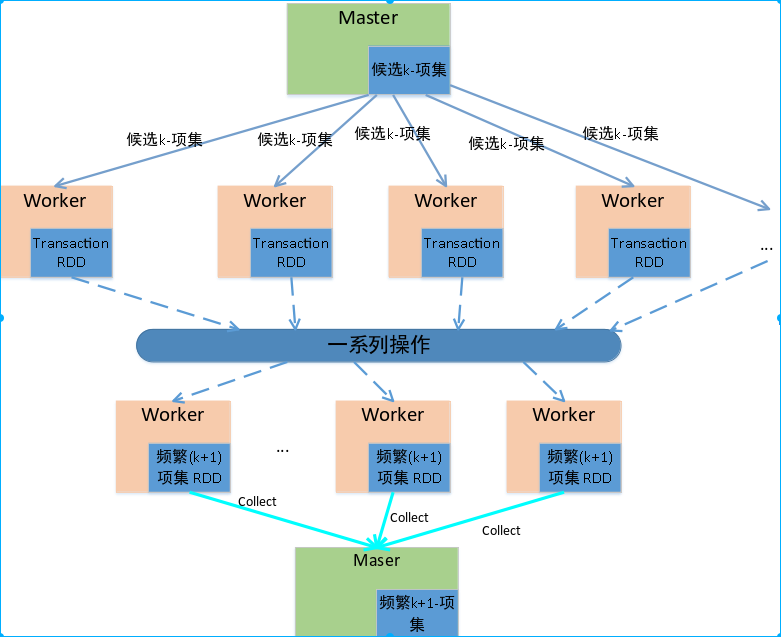
图1.1 并行化框架图
阶段1:从HDFS上获取原始的数据集SparkRDD,加载到分布式内存中。扫描所有的RDD事务,进行支持度计数,产生频繁1-项集;如图1.2所示为Ap算法并行化第一阶段的Lineage图。
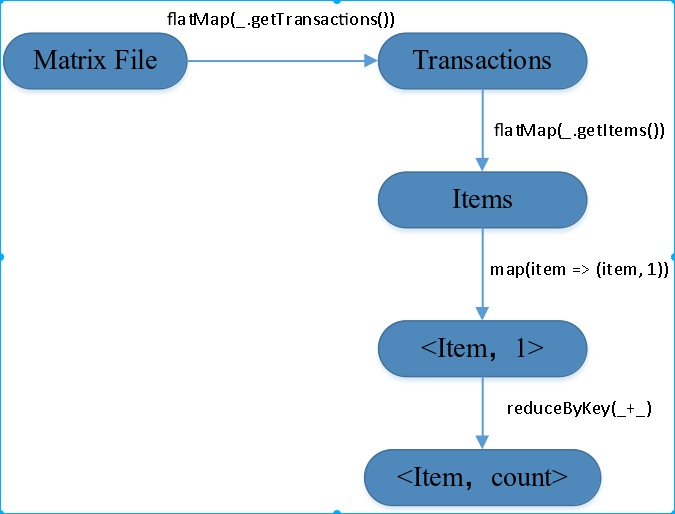
图1.2 Apriori算法并行化第一阶段的Lineage图
原始事务集由flatMap函数去读取事务,并将所有的事务转化为Spark RDD并cache到分布式内存中。接下来,在每一个事务中执行flatMap函数来获取所有的Items项集,之后执行map函数,发射<Item, 1>的key/value形式,接下来执行reduceByKey函数统计每一个候选1-项集的支持度,最后并利用事先设好的支持度阈值进行剪枝,所有超过支持度阈值的项集将会生成频繁1-项集,下面给出了第一阶段的算法伪代码

阶段2:在这个阶段,不断迭代使用频繁k-项集去产生频繁k+1项集
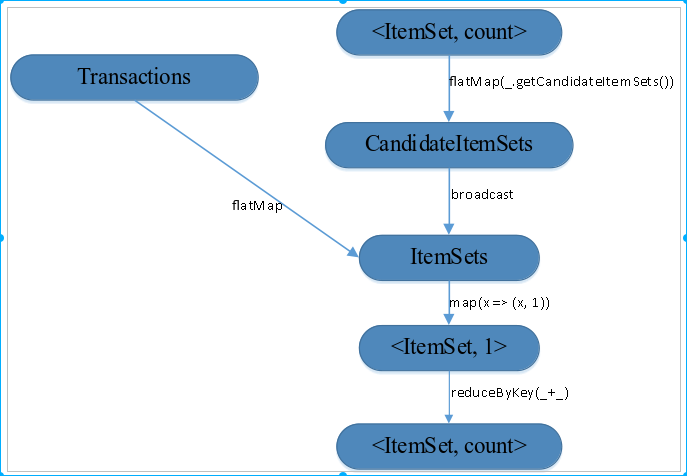
图1.3 Apriori算法并行化第二阶段的Lineage图
如图1.3所示,首先读取频繁k-项集并且以<itemSet, Count>的形式将其存储为Spark RDD。接下来,从频繁k-项集得到候选(k+1)-项集。为加速从候选项集中查找(k+1)-项集的过程,将候选(k+1)-项集存放在哈希表中,并将其broadcast到每个worker节点。接下来,通过flatMap函数获取每个候选项集在原始事务集中的支持度,进一步对每个候选项使用map函数得到<ItemSet, 1>,之后通过reduceBykey函数搜集每个事务的最终的支持度计数,最后利用实现设定好的支持度阈值剪枝,支持度大于等于最小阈值的频繁项集将会以key/value的形式输出,作为频繁(k+1)-项集,下面给出了算法第二阶段的伪代码。

2.3 程序设计与性能分析
读取数据集,按空格划分每行内容,并用HashSet存储,方便后期求子集以及一些集合操作
// 将输入数据分区,由于后面要频繁使用。因此缓存起来
val transations = sc.textFile(input, num)
.map(x => {
val content = x.split("\\s+")
val tmp = new HashSet[String]
for (i <- 0 until content.length) {
tmp.add(content(i))
}
tmp
}).cache()
根据支持度和数据总量计算频繁项阈值,便于后期统计集合频度后直接对比
// 计算频繁项阈值
val numRecords = transations.count().toDouble
val freqThre = numRecords * support
println("frequency threshold:" + freqThre)
计算频繁1项集用于后续的循环迭代计算
// 计算频繁1项集
val oneFreqSet = transations
.flatMap(_.seq)
.map(x => (x, 1))
.reduceByKey(_ + _)
.filter(x => x._2 >= freqThre)
.map(x => (HashSet(x._1), x._2 / numRecords))
利用上一轮迭代计算生成的频繁k项集来构造候选k+1项集,然后通过比频繁项阈值比对筛选出频繁k+1项集。这里有一点要注意的,由于从文件读入的源数据transaction被划分在各个partition上,而候选集candidates要与transaction中每条记录比对来统计频度,因此需要spark调用broadcast将候选集广播到每个partition上
// 生成频繁项的候选集
val candidates = generateCandidates(preFreSets, round)
// 将候选项集广播到各个分区
val broadcastCandidates = sc.broadcast(candidates) //复杂度:len(transactions) * len(candidates) * round * transaction项的平均长度
//这里的len(transaction)是指各个partition上transaction的平均长度
val curFreqSet = transations
.flatMap(x => verifyCandidates(x, broadcastCandidates.value))
.reduceByKey(_ + _)
.filter(x => x._2 >= freqThre) // 写入频繁round项集结果到hdfs
curFreqSet.map(a => {
val out = a._1.mkString(",") + ":" + (a._2 / numRecords).toString
out
}).saveAsTextFile(output + "/" + infileName + "freqset-" + round) // 生成频繁round-Itemsets,用于下一轮迭代生成候选集
preFreSets = curFreqSet.collect().map(x => x._1)
第round轮迭代,由候选项集生成频繁项集的复杂度:len(transactions) * len(candidates) * round * transaction项的平均长度,这里的len(transaction)是指各个partition上transaction的平均长度,尽管我们通过提高并发度的方式将复杂度的稍微将了一些,可是算法的整体复杂度还是很高,特别是当源数据集很大时,这样查表式地验证候选集很费时,有考虑将项集索引,但是如果全部项集都存那这个存储开销太大了,目前没有很好的优化思路,时间有限也没有进一步深入怎么优化这一步了。
对于候选集生成方法generateCandidates的具体实现,我们首先拆分上一轮频繁项集preFreSets中的每个项再合并成一个元素集,相当于一个词汇表,然后遍历preFreSets中每个项,如果该项中不包含元素表中的某个元素,则将该元素与该项合并成一个候选项。具体实现如下:
def generateCandidates(preFreSets : Array[HashSet[String]], curRound: Int): Array[HashSet[String]] = {
// 复杂度:len(elements) * len(preFrestats)^2 * curRound^2
val elements = preFreSets.reduce((a,b) => a.union(b))
val canSets = preFreSets.flatMap( t => for (ele <- elements if(!t.contains(ele))) yield t.+(ele) ).distinct
canSets.filter( set => {
val iter = set.subsets(curRound - 1)
var flag = true
while (iter.hasNext && flag){
flag = preFreSets.contains(iter.next())
}
flag
})
}
但是这个过程复杂度太高:len(elements) * len(preFrestats)^2 * curRound^2,当数据源中元素过多,迭代更深以后,这个复杂度将变得让人难以接受,花了大量的时间再前一轮的候选项集中验证候选项,需要想一个办法来避免顺序式的查表,但限于时间有限,这个地方没有深入展开研究怎么优化。
2.4 关联规则的实现
利用当前这一轮迭代生成的频繁项集curFreqSet来计算关联规则,利用curFreqSet建立频繁项索引freqSetIndex,同统计候选项频度的原因一样,我们需要将freqSetIndex广播到各个partition以统计规则A->B左项A的频度,再利用freqSetIndex索引AB频繁项的频度即可计算规则A->B的置信度,然后与设定的置信度对比即可筛选出需要的关联规则,代码实现如下:
// 生成关联规则
val asst1 = System.nanoTime()
// 建立频繁round-Itemsets的索引Map
val freqSetIndex = HashMap[HashSet[String], Int]()
curFreqSet.collect().foreach(fs => freqSetIndex.put(fs._1, fs._2))
// 将频繁round-Itemsets的索引Map广播到各个partition
val broadcastCurFreqSet = sc.broadcast(freqSetIndex)
// 生成所有可能的关联规则,然后筛选出置信度>=confidence的关联规则
val associationRules = transations
.flatMap(x => verifyRules(x, broadcastCurFreqSet.value.keys.toArray, round))
.reduceByKey(_ + _)
.map(x => ((x._1._1, x._1._2), broadcastCurFreqSet.value.get(x._1._1.union(x._1._2)).getOrElse(0) * 1.0 / x._2))
.filter(x => x._2 >= confidence)
对于规则构造verifyRules的具体实现,我们通过遍历规则左项的长度来构造,具体实现如下:
def verifyRules(transaction: HashSet[String], candidates: Array[HashSet[String]], curRound: Int): Array[((HashSet[String], HashSet[String]), Int)] = {
// yield会根据第一个循环类型返回对应的类型,这里的candidates是Array,因此返回的也是Array类型
for {
set <- candidates i <- 1 until curRound iter = set.subsets(i)
l <- iter
if (l.subsetOf(transaction))
r = set.diff(l)
} yield ((l, r), 1)
}
三、实验环境、运行方式及结果
3.1 环境
spark分布式环境的安装
在本地配置好java,scala,hadoop(Spark会用到hadoop的hdfs)
版本: jdk 1.8.0_161, scala 2.11.8, hadoop 2.7.5在spark官网下载spark-2.3.0-bin-hadoop2.7,解压安装
tar -zxvf spark-2.3.0-bin-hadoop2.7 -C ~/bigdata/spark
- 配置环境变量,并使环境变量生效
$ vim ~/.bashrc
# Spark Environment Variables
export JAVA_HOME=~/bigdata/java/jdk1.8.0_161
export JRE_HOME=${JAVA_HOME}/jre
export SCALA_HOME=~/bigdata/scala/scala-2.11.8
export HADOOP_HOME=~/bigdata/hadoop/hadoop-2.7.5
export SPARK_HOME=~/bigdata/spark/spark-2.3.0-bin-hadoop2.7
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
$ source /etc/profile
- 配置,spark的配置文件位于$SPARK_HOME/conf目录下,需要修改的文件有spark-env.sh, spark-defaluts.conf和slaves。
$ cd ~/bigdata/spark/spark-2.3.0-bin-hadoop2.7/conf
$ cp spark-env.sh.template spark-env.sh
$ vim spark-env,sh
# spark-env.sh configuration
export JAVA_HOME=~/bigdata/java/jdk1.8.0_161
export SCALA_HOME=~/bigdata/scala/scala-2.11.8
export SPARK_HOME=~/bigdata/spark/spark-2.3.0-bin-hadoop2.7
export HADOOP_HOME=~/bigdata/hadoop/hadoop-2.7.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HADOOP_HOME/bin
export SPARK_MASTER_IP=slave103
$ cp spark-defaluts.conf.template spark-defaults.conf
$ vim saprk-defaults.conf
# spark-defaults.conf configuration
spark.executor.extraJavaOptions -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
spark.eventLog.enabled true
spark.eventLog.dir hdfs://slave103:9000/spark_event
spark.yarn.historyServer.address slave103:18080
spark.history.fs.logDirectory hdfs://slave103:9000/history_log
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.memory 2g
spark.executor.cores 2
spark.driver.memory 2g
spark.driver.cores 2
spark.yarn.am.memory 2g
spark.yarn.am.cores 2
spark.local.dir /tmp/sparklocaldir
spark.yarn.jars hdfs://slave103:9000/spark/jars/*
$ cp slaves.template slaves
$ vim slaves
# slaves configuration(主机名在/etc/hosts中配置)
slave101
slave103
- 启动和停止
# 启动
$ bash $SPARK_HOME/sbin/start-all.sh
# 停止
$ bash $SPARK_HOME/sbin/stop-all.sh
- 启动hadoop和spark执行jps命令,显示的进程如下图3.1和3.2所示:
图3.1 主节点jvm进程
图3.2 从节点jvm进程
3.2 jar包运行方式
假设输入数据文件为chess.dat,shell下运行方式如下:
spark-submit --class main.scala.Apriori.distributed.Apriori --master spark://slave103:7077 --conf spark.driver.memory=4g --conf spark.executor.cores=2 original-MapReduce-1.0.jar input/apriori/chess.dat output 0.8 20 24 0.9
# jar后面的参数说明:输入文件 输出目录 支持度 迭代轮数 并发度即partition数目 置信度
3.3 结果
- 测试connect.dat数据集生成频繁项集的运行时间,图3.3是单机版的,图3.4是并行版的:
.png)
图3.3 单机版运行时间
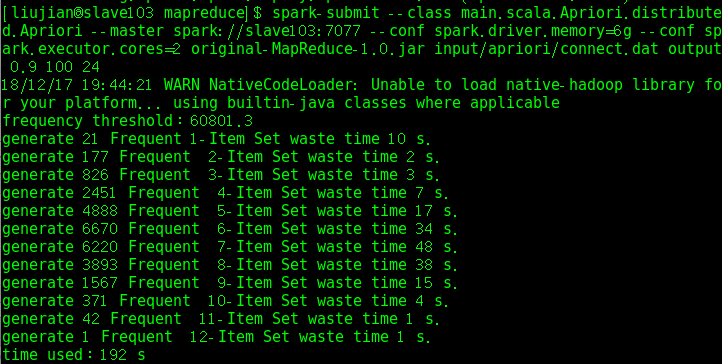
图3.4 并行版运行时间
在chess.dat数据集上测试并行版本的频繁项集生成和关联规则挖掘的运行时间如下:
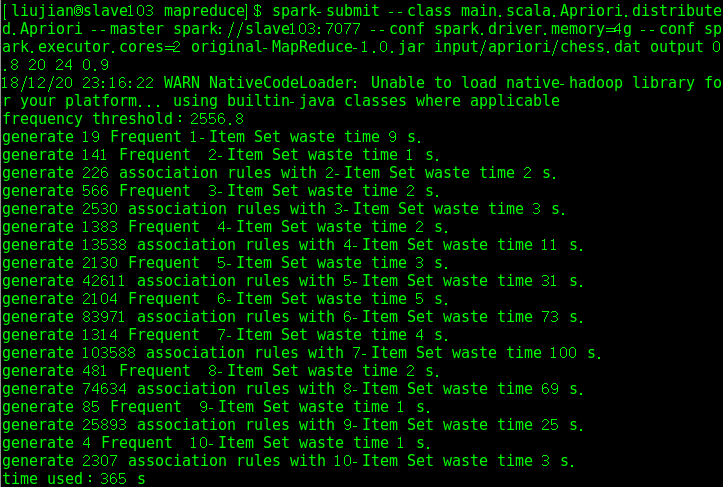
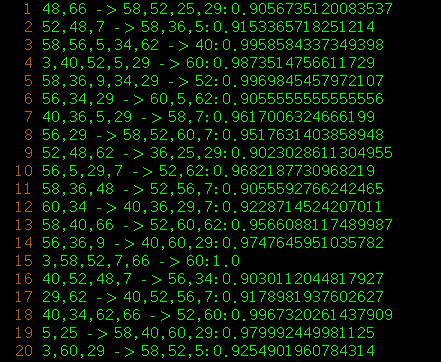
chess.dat频繁项集生成结果
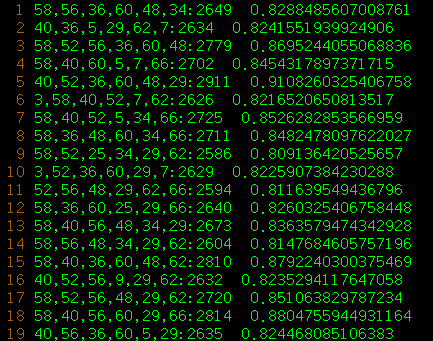
- chess.dat关联规则挖掘结果
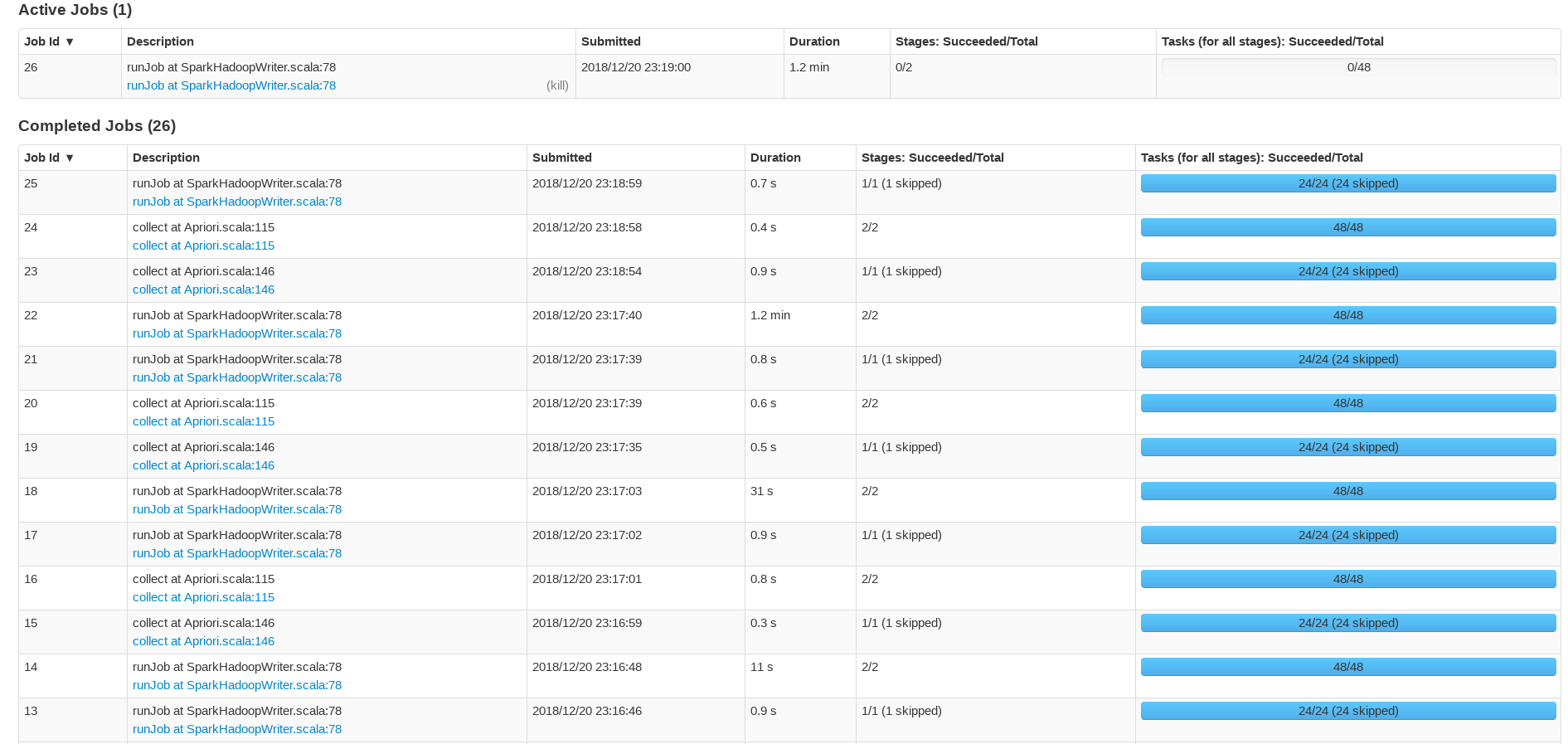
四、WebUI执行报告
基于spark实现并行化Apriori算法的更多相关文章
- 基于Hadoop的改进Apriori算法
一.Apriori算法性质 性质一: 候选的k元组集合Ck中,任意k-1个项组成的集合都来自于Lk. 性质二: 若k维数据项目集X={i1,i2,-,ik}中至少存在一个j∈X,使得|L(k-1)(j ...
- #研发解决方案#基于Apriori算法的Nginx+Lua+ELK异常流量拦截方案
郑昀 基于杨海波的设计文档 创建于2015/8/13 最后更新于2015/8/25 关键词:异常流量.rate limiting.Nginx.Apriori.频繁项集.先验算法.Lua.ELK 本文档 ...
- 基于Apriori算法的Nginx+Lua+ELK异常流量拦截方案 郑昀 基于杨海波的设计文档(转)
郑昀 基于杨海波的设计文档 创建于2015/8/13 最后更新于2015/8/25 关键词:异常流量.rate limiting.Nginx.Apriori.频繁项集.先验算法.Lua.ELK 本文档 ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 推荐系统第4周--- 基于频繁模式的推荐系统和关联规则挖掘Apriori算法
数据挖掘:关联规则挖掘
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- StreamDM:基于Spark Streaming、支持在线学习的流式分析算法引擎
StreamDM:基于Spark Streaming.支持在线学习的流式分析算法引擎 streamDM:Data Mining for Spark Streaming,华为诺亚方舟实验室开源了业界第一 ...
- 基于Spark ALS构建商品推荐引擎
基于Spark ALS构建商品推荐引擎 一般来讲,推荐引擎试图对用户与某类物品之间的联系建模,其想法是预测人们可能喜好的物品并通过探索物品之间的联系来辅助这个过程,让用户能更快速.更准确的获得所需 ...
- 利用Apriori算法对交通路况的研究
首先简单描述一下Apriori算法:Apriori算法分为频繁项集的产生和规则的产生. Apriori算法频繁项集的产生: 令ck为候选k-项集的集合,而Fk为频繁k-项集的集合. 1.首先通过单遍扫 ...
随机推荐
- 计蒜客 等边三角形 dfs
题目: https://www.jisuanke.com/course/2291/182238 思路: 1.dfs(int a,int b,int c,int index)//a,b,c三条边的边长, ...
- 深入理解CPP与C中bsearch函数的用法
·使用besearch函数的前提(一些废话) 首先让我们先亮出二分法的定义: https://baike.baidu.com/item/二分法/1364267 以及二分法实现的方法: https:// ...
- (转)CentOS7中防火墙的基本操作
目录 1.firewalld简介 2.安装firewalld 3.运行.停止.禁用firewalld 4.配置firewalld 5 打开端口 学习apache安装的时候需要打开80端口,由于cent ...
- VB.NET或C#报错:You must hava a license to use this ActiveX control.
VB.NET或者C# winform开发时,如果使用了Microsoft Visual Basic 6.0 ActiveX,并动态创建该控件实例,那么程序移植到没有安装Visual Basic 6.0 ...
- Caused by: org.apache.ibatis.builder.BuilderException: Parsing error was found in mapping #{}. Check syntax #{property|(expression), var1=value1, var2=value2, ...}
解决办法:查看与该项目中的所有#{},应该是 #{}的中间没有写值
- 封装redis
封装redis import redis # r = redis.Redis() class MyRedis(): def __init__(self,ip,password,port=6379,db ...
- 3-1.Hadoop单机模式安装
Hadoop单机模式安装 一.实验介绍 1.1 实验内容 hadoop三种安装模式介绍 hadoop单机模式安装 测试安装 1.2 实验知识点 下载解压/环境变量配置 Linux/shell 测试Wo ...
- Python学习:类和实例
Python学习:类和实例 本文作者: 玄魂工作室--热热的蚂蚁 类,在学习面向对象我们可以把类当成一种规范,这个思想就我个人的体会,感觉很重要,除了封装的功能外,类作为一种规范,我们自己可以定制的规 ...
- .NET Core多平台开发体验[4]: Docker
对于一个 .NET开发人员,你可能没有使用过Docker,但是你不可能没有听说过Docker.Docker是Github上最受欢迎的开源项目之一,它号称要成为所有云应用的基石,并把互联网升级到下一代. ...
- 在线生成透明ICO图标神器
此神器的链接为:http://ico.duduxuexi.com/ 大家可以将这个网址收藏好,本人亲测十分好用!对我们的ios,安卓以及windows开发都有极大的好处.