Elasticsearch从入门到精通之Elasticsearch集群内的原理
上一章节我介绍了Elasticsearch安装与运行,本章节及后续章节将全方位介绍 Elasticsearch 的工作原理
在这个章节中,我将会再进一步介绍 cluster 、 node 、 shard 等常用术语,Elastisearch 的扩容机制, 以及如何处理硬件故障的内容。
1、分布式特性
Elasticsearch 可以横向扩展至数百(甚至数千)的服务器节点,同时可以处理PB级数据。Elasticsearch 天生就是分布式的,并且在设计时屏蔽了分布式的复杂性。
Elasticsearch 在分布式方面几乎是透明的。教程中并不要求了解分布式系统、分片、集群发现或其他的各种分布式概念。可以使用笔记本上的单节点轻松地运行教程里的程序,但如果你想要在 100 个节点的集群上运行程序,一切依然顺畅。
Elasticsearch 尽可能地屏蔽了分布式系统的复杂性。这里列举了一些在后台自动执行的操作:
- 分配文档到不同的容器 或 分片 中,文档可以储存在一个或多个节点中
- 按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
- 复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
- 将集群中任一节点的请求路由到存有相关数据的节点
- 集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
2、集群原理
ElasticSearch 的主旨是随时可用和按需扩容。 而扩容可以通过购买性能更强大( 垂直扩容 ,或 纵向扩容) 或者数量更多的服务器( 水平扩容 ,或 横向扩容 )来实现。
虽然 Elasticsearch 可以获益于更强大的硬件设备,但是垂直扩容是有极限的。 真正的扩容能力是来自于水平扩容--为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中。
对于大多数的数据库而言,通常需要对应用程序进行非常大的改动,才能利用上横向扩容的新增资源。 与之相反的是,ElastiSearch天生就是 分布式的 ,它知道如何通过管理多节点来提高扩容性和可用性。 这也意味着你的应用无需关注这个问题。
2.1、空集群
如果我们启动了一个单独的节点,里面不包含任何的数据和 索引,那我们的集群看起来就像下图1一样。
图 1. 包含空内容节点的集群

一个运行中的 Elasticsearch 实例称为一个 节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为 主 节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
2.2、集群健康
lasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健康 , 它在 status 字段中展示为 green 、 yellow 或者 red 。
GET /_cluster/health
在一个不包含任何索引的空集群中,它将会有一个类似于如下所示的返回内容:
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green- 所有的主分片和副本分片都正常运行。
yellow- 所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red- 有主分片没能正常运行。
2.3、新增索引
我们往 Elasticsearch 添加数据时需要用到索引 —— 保存相关数据的地方。 索引实际上是指向一个或者多个物理分片 的逻辑命名空间 。
一个分片 是一个底层的工作单元 ,它仅保存了 全部数据中的一部分。 在分片内部机制中,我们将详细介绍分片是如何工作的,而现在我们只需知道一个分片是一个 Lucene 的实例,以及它本身就是一个完整的搜索引擎文件。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是 主 分片或者 副本 分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。
技术上来说,一个主分片最大能够存储 Integer.MAX_VALUE - 128 个文档,但是实际最大值还需要参考你的使用场景:包括你使用的硬件, 文档的大小和复杂程度,索引和查询文档的方式以及你期望的响应时长。
一个副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
让我们在包含一个空节点的集群内创建名为 shops 的索引。 索引在默认情况下会被分配5个主分片, 但是为了演示目的,我们将分配3个主分片和一份副本(每个主分片拥有一个副本分片):
PUT /shops
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
我们的集群现在是图 2 “拥有一个索引的单节点集群”。所有3个主分片都被分配在 Node 1 。
图 2. 拥有一个索引的单节点集群

如果我们现在查看集群健康, 我们将看到如下内容:
{
"cluster_name": "elasticsearch",
"status": "yellow",
![]()
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3,
![]()
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50
}
|
|
集群 |
|
|
没有被分配到任何节点的副本数。 |
集群的健康状况为 yellow 则表示全部主 分片都正常运行(集群可以正常服务所有请求),但是副本 分片没有全部处在正常状态。 实际上,所有3个副本分片都是 unassigned —— 它们都没有被分配到任何节点。 在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。
当前我们的集群是正常运行的,但是在硬件故障时有丢失数据的风险。
2.4、故障转移
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。
启动第二个节点
为了测试第二个节点启动后的情况,你可以在同一个目录内,完全依照启动第一个节点的方式来启动一个新节点(参考安装并运行 Elasticsearch)。多个节点可以共享同一个目录。
当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的 cluster.name 配置,它就会自动发现集群并加入到其中。 但是在不同机器上启动节点的时候,为了加入到同一集群,你需要配置一个可连接到的单播主机列表。 详细信息请查看最好使用单播代替组播
如果启动了第二个节点,我们的集群将会如图 3 “拥有两个节点的集群——所有主分片和副本分片都已被分配”所示。
图 3. 拥有两个节点的集群——所有主分片和副本分片都已被分配
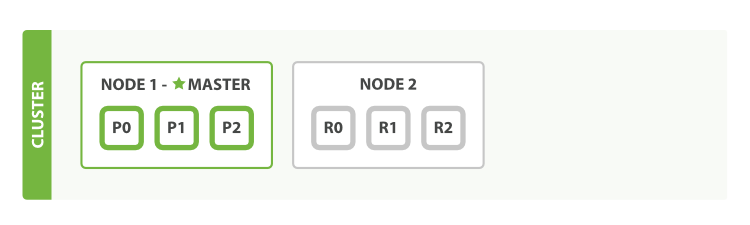
当第二个节点加入到集群后,3个 副本分片 将会分配到这个节点上——每个主分片对应一个副本分片。 这意味着当集群内任何一个节点出现问题时,我们的数据都完好无损。
所有新近被索引的文档都将会保存在主分片上,然后被并行的复制到对应的副本分片上。这就保证了我们既可以从主分片又可以从副本分片上获得文档。
cluster-health 现在展示的状态为 green ,这表示所有6个分片(包括3个主分片和3个副本分片)都在正常运行。
{
"cluster_name": "elasticsearch",
"status": "green",
![]()
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
|
|
集群 |
我们的集群现在不仅仅是正常运行的,并且还处于 始终可用 的状态。
2.5、水平扩容
怎样为我们的正在增长中的应用程序按需扩容呢? 当启动了第三个节点,我们的集群将会看起来如图 4 “拥有三个节点的集群——为了分散负载而对分片进行重新分配”所示。
图 4. 拥有三个节点的集群——为了分散负载而对分片进行重新分配
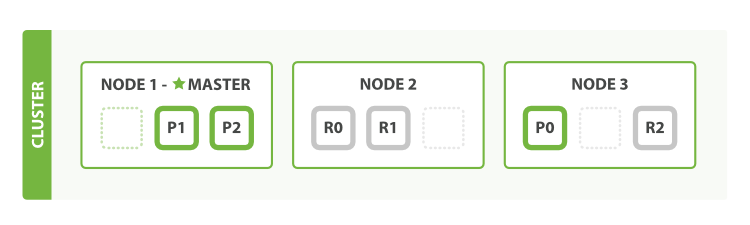
Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥有2个分片,而不是之前的3个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片的性能将会得到提升。
分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 我们这个拥有6个分片(3个主分片和3个副本分片)的索引可以最大扩容到6个节点,每个节点上存在一个分片,并且每个分片拥有所在节点的全部资源。
2.5.1、更多的扩容
但是如果我们想要扩容超过6个节点怎么办呢?
主分片的数目在索引创建时 就已经确定了下来。实际上,这个数目定义了这个索引能够存储 的最大数据量。(实际大小取决于你的数据、硬件和使用场景。) 但是,读操作——搜索和返回数据——可以同时被主分片或 副本分片所处理,所以当你拥有越多的副本分片时,也将拥有越高的吞吐量。
在运行中的集群上是可以动态调整副本分片数目的 ,我们可以按需伸缩集群。让我们把副本数从默认的 1增加到 2 :
PUT /shops/_settings
{
"number_of_replicas" : 2
}
如图 5 “将参数 number_of_replicas 调大到 2”所示, shops 索引现在拥有9个分片:3个主分片和6个副本分片。 这意味着我们可以将集群扩容到9个节点,每个节点上一个分片。相比原来3个节点时,集群搜索性能可以提升 3 倍。
图 5. 将参数 number_of_replicas 调大到 2
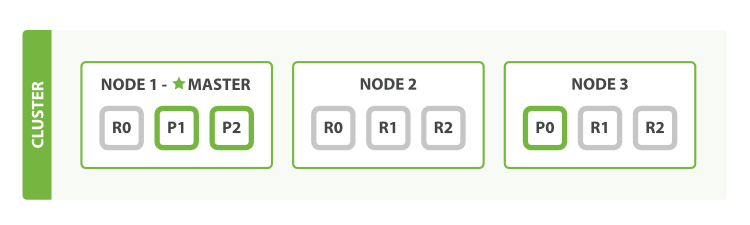
当然,如果只是在相同节点数目的集群上增加更多的副本分片并不能提高性能,因为每个分片从节点上获得的资源会变少。 你需要增加更多的硬件资源来提升吞吐量。
但是更多的副本分片数提高了数据冗余量:按照上面的节点配置,我们可以在失去2个节点的情况下不丢失任何数据。
2.6、应对故障
我们之前说过 Elasticsearch 可以应对节点故障,接下来让我们尝试下这个功能。 如果我们关闭第一个节点,这时集群的状态为图 6 “关闭了一个节点后的集群”
图 6. 关闭了一个节点后的集群
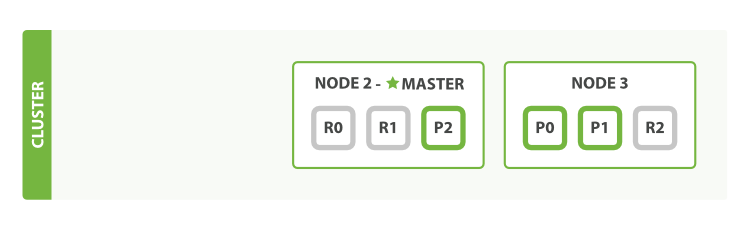
我们关闭的节点是一个主节点。而集群必须拥有一个主节点来保证正常工作,所以发生的第一件事情就是选举一个新的主节点: Node 2 。
在我们关闭 Node 1 的同时也失去了主分片 1 和 2 ,并且在缺失主分片的时候索引也不能正常工作。 如果此时来检查集群的状况,我们看到的状态将会为 red :不是所有主分片都在正常工作。
幸运的是,在其它节点上存在着这两个主分片的完整副本, 所以新的主节点立即将这些分片在 Node 2 和 Node 3 上对应的副本分片提升为主分片, 此时集群的状态将会为 yellow 。 这个提升主分片的过程是瞬间发生的,如同按下一个开关一般。
为什么我们集群状态是 yellow 而不是 green 呢? 虽然我们拥有所有的三个主分片,但是同时设置了每个主分片需要对应2份副本分片,而此时只存在一份副本分片。 所以集群不能为 green 的状态,不过我们不必过于担心:如果我们同样关闭了 Node 2 ,我们的程序 依然 可以保持在不丢任何数据的情况下运行,因为 Node 3 为每一个分片都保留着一份副本。
如果我们重新启动 Node 1 ,集群可以将缺失的副本分片再次进行分配,那么集群的状态也将如图 5 “将参数 number_of_replicas 调大到 2”所示。 如果 Node 1 依然拥有着之前的分片,它将尝试去重用它们,同时仅从主分片复制发生了修改的数据文件。
到目前为止,你应该对分片如何使得 Elasticsearch 进行水平扩容以及数据保障等知识有了一定了解
Elasticsearch从入门到精通之Elasticsearch集群内的原理的更多相关文章
- Elasticsearch集群内的原理
一个运行中的 Elasticsearch 实例称为一个 节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力.当有节点加入集群中或者从 ...
- Elasticsearch从入门到精通之Elasticsearch基本概念
导读 在上一章节我们介绍Elasticsearch前世今生,今天我们继续进行本章内容,Elasticsearch的核心概念.从一开始就理解这些概念将极大地帮助简化学习过程. 近实时(NRT) Elas ...
- ElasticSearch入门 第二篇:集群配置
这是ElasticSearch 2.4 版本系列的第二篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- 通过VMware的PowerCLI配置集群内指定主机的vMotion功能
PowerCLI是VMware开发的基于微软(MSFT)的PowerShell的命令行管理vSphere的实现,因此在批量化操作方面CLI会减轻很多GUI环境下的繁琐重复劳作. 现有场景中有大量的物理 ...
- Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之ORACLE集群概念和原理(二)
ORACLE集群概念和原理(二) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- Linux之为集群内的机器设定主机名
作业二:为集群内的机器设定主机名,利用/etc/hosts文件来解析自己的集群中所有的主机名,相应的,集群的配置应该改成使用主机名的方式 1.主机信息配置并解析 [root@localhost ~]# ...
- service几种访问类型(集群外负载均衡访问LoadBalancer , 集群内访问ClusterIP,VPC内网负载均衡LoadBalancer ,集群外访问NodePort)
一.集群外访问(负载均衡) kind: ServiceapiVersion: v1spec: ports: - protocol: TCP port: 4341 targetPort: 8080 no ...
- Hive环境的安装部署(完美安装)(集群内或集群外都适用)(含卸载自带mysql安装指定版本)
Hive环境的安装部署(完美安装)(集群内或集群外都适用)(含卸载自带mysql安装指定版本) Hive 安装依赖 Hadoop 的集群,它是运行在 Hadoop 的基础上. 所以在安装 Hive 之 ...
- Linux基础-配置网络、集群内主机名设定、ssh登入、bash命令、通配符(元字符)
作业一:临时配置网络(ip,网关,dns)+永久配置 设置临时网络配置: 配置IP ifcongfig ens33 192.168.16.177/24 (ifconfig 网卡 ip地址 /24 ...
随机推荐
- centos6.5安装nginx+python+uwsgi+django
nginx+uwsgi+django环境部署及测试 默认系统自带的python2.6.6 第一步(安装setuptools) wget https://pypi.python.org/packages ...
- DWM1000 测距原理简单分析 之 SS-TWR代码分析2 -- [蓝点无限]
蓝点DWM1000 模块已经打样测试完毕,有兴趣的可以申请购买了,更多信息参见 蓝点论坛 正文: 首先将SS 原理介绍中的图片拿过来,将图片印在脑海里. 对于DeviceA 和 DeviceB来说,初 ...
- 08-Python入门学习-文件与函数
一.文件 1.控制文件内指针的移动 文件内指针移动,只有t模式下的read(n),n代表的字符的个数除此以外文件内指针的移动都是以字节为单位 with open('a.txt',mode='rt',e ...
- HBase RegionServer Pause for hours 卡顿几小时 故障
关键词:hbase jvm gc regionserver wal pause 背景: HBase 1.1.2 客户的hbase集群最近出现RegionServer宕机情况.跟踪了master和RS日 ...
- __x__(8)0906第三天__乱码问题
需要知道: 计算机只认 0 1 任何内容,计算机都会以 0 1 去存储 所以 0 1 与内容的编码方式/解码方式需要依照一定的规则,实现 0 1 与内容之间的转换. 字符集:一定的规则,由编码/解码采 ...
- 英特尔神经棒使用入门-NCS2 & NCS1 -OpenVino
|--背景: NCS1使用的NCSDK1和NCSDK2,速度一般,没有想象中的速度,能有TX2一半的速度吧.跟大佬又申请了个NCS2来试一试. 环境配置到跑通自己写的MNIST分类网络花了2天不到吧. ...
- ThinkPHP5 添加多个文字水印及疑难解答
public function imageload() { $imgpath = ROOT_PATH . 'public' . DS . 'static' . DS . 'www' . DS . 'i ...
- Spring Session event事件分析
1. org.apache.catalina.session.StandardSession 这是servlet-api jar包中的一个类.是session接口的标准实现.当session创建的时候 ...
- ARE 212 - Problem Set 5
ARE 212 - Problem Set 5Due May 1stPart I: Theory (Optional)1. Show that the parameter estimates for ...
- WinAPI 字符及字符串函数(15): CharNext、CharPrev
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, For ...