web全栈应用【爬取(scrapy)数据 -> 通过restful接口存入数据库 -> websocket推送展示到前台】
作为
https://github.com/fanqingsong/web_full_stack_application
子项目的一功能的核心部分,使用scrapy抓取数据,解析完的数据,使用 python requets库,将数据推送到 webservice接口上, webservice接口负责保存数据到mongoDB数据库。
实现步骤:
1、 使用requests库,与webservice接口对接。
2、 使用scrapy抓取数据。
3、 结合1 2 实现完整功能。
Requests库 (Save to DB through restful api)
库的安装和快速入门见:
http://docs.python-requests.org/en/master/user/quickstart/#response-content
给出测试通过示例代码:
insert_to_db.py
import requests
resp = requests.get('http://localhost:3000/api/v1/summary')
# ------------- GET --------------
if resp.status_code != 200:
# This means something went wrong.
raise ApiError('GET /tasks/ {}'.format(resp.status_code))for todo_item in resp.json():
print('{} {}'.format(todo_item['Technology'], todo_item['Count']))# ------------- POST --------------
Technology = {"Technology": "Django", "Count": "50" }resp = requests.post('http://localhost:3000/api/v1/summary', json=Technology)
if resp.status_code != 201:
raise ApiError('POST /Technologys/ {}'.format(resp.status_code))print("-------------------")
print(resp.text)print('Created Technology. ID: {}'.format(resp.json()["_id"])
Python VirutalEnv运行环境
https://realpython.com/python-virtual-environments-a-primer/
Create a new virtual environment inside the directory:
- # Python 2:
- $ virtualenv env
- # Python 3
- $ python3 -m venv env
Note: By default, this will not include any of your existing site packages.
windows 激活:
env\Scripts\activate
Scrapy(Scratch data)
An open source and collaborative framework for extracting the data you need from websites.
In a fast, simple, yet extensible way.
https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html
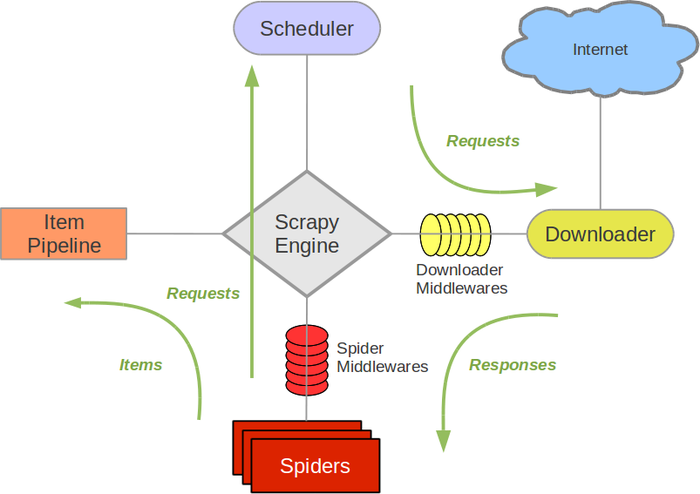
安装和使用参考:
https://www.cnblogs.com/lightsong/p/8732537.html
安装和运行过程报错解决办法:
1、 Scrapy运行ImportError: No module named win32api错误
https://blog.csdn.net/u013687632/article/details/57075514
pip install pypiwin32
https://www.cnblogs.com/baxianhua/p/8996715.html
1. http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载twisted对应版本的whl文件(我的Twisted‑17.5.0‑cp36‑cp36m‑win_amd64.whl),cp后面是python版本,amd64代表64位,
2. 运行命令:
pip install C:\Users\CR\Downloads\Twisted-17.5.0-cp36-cp36m-win_amd64.whl
给出示例代码:
quotes_spider.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.xpath('span/small/text()').extract_first(),
}next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
yield response.follow(next_page, self.parse)
在此目录下,运行
- scrapy runspider quotes_spider.py -o quotes.json
输出结果
[
{"text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d", "author": "Jane Austen"},
{"text": "\u201cA day without sunshine is like, you know, night.\u201d", "author": "Steve Martin"},
{"text": "\u201cAnyone who thinks sitting in church can make you a Christian must also think that sitting in a garage can make you a car.\u201d", "author": "Garrison Keillor"},
{"text": "\u201cBeauty is in the eye of the beholder and it may be necessary from time to time to give a stupid or misinformed beholder a black eye.\u201d", "author": "Jim Henson"},
{"text": "\u201cAll you need is love. But a little chocolate now and then doesn't hurt.\u201d", "author": "Charles M. Schulz"},
{"text": "\u201cRemember, we're madly in love, so it's all right to kiss me anytime you feel like it.\u201d", "author": "Suzanne Collins"},
{"text": "\u201cSome people never go crazy. What truly horrible lives they must lead.\u201d", "author": "Charles Bukowski"},
{"text": "\u201cThe trouble with having an open mind, of course, is that people will insist on coming along and trying to put things in it.\u201d", "author": "Terry Pratchett"},
{"text": "\u201cThink left and think right and think low and think high. Oh, the thinks you can think up if only you try!\u201d", "author": "Dr. Seuss"},
{"text": "\u201cThe reason I talk to myself is because I\u2019m the only one whose answers I accept.\u201d", "author": "George Carlin"},
{"text": "\u201cI am free of all prejudice. I hate everyone equally. \u201d", "author": "W.C. Fields"},
{"text": "\u201cA lady's imagination is very rapid; it jumps from admiration to love, from love to matrimony in a moment.\u201d", "author": "Jane Austen"}
]
业务全流程实例
https://github.com/fanqingsong/web_data_visualization
由于zhipin网站对爬虫有反制策略, 本例子采用scrapy的官方爬取实例quotes为研究对象。
流程为:
1、 爬取数据, scrapy 的两个组件 spider & item pipeline
2、 存数据库, requests库的post方法推送数据到 webservice_quotes服务器的api
3、 webservice_quotes将数据保存到mongoDB
4、 浏览器访问vue页面, 与websocket_quotes服务器建立连接
5、 websocket_quotes定期(每隔1s)从mongoDB中读取数据,推送给浏览器端,缓存为Vue应用的data,data绑定到模板视图
scrapy item pipeline 推送数据到webservice接口
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.htmlimport requests
class ScratchZhipinPipeline(object):
def process_item(self, item, spider):print("--------------------")
print(item['text'])
print(item['author'])
print("--------------------")# save to db through web service
resp = requests.post('http://localhost:3001/api/v1/quote', json=item)
if resp.status_code != 201:
raise ApiError('POST /item/ {}'.format(resp.status_code))
print(resp.text)
print('Created Technology. ID: {}'.format(resp.json()["_id"]))return item
爬虫运行: scrapy crawl quotes
webservice运行: npm run webservice_quotes
websocket运行: npm run websocket_quotes
vue调试环境运行: npm run dev
chrome:
db:
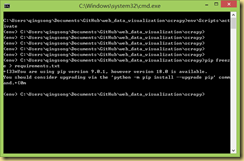
Python生成requirement.text文件
http://www.cnblogs.com/zhaoyingjie/p/6645811.html
- 快速生成requirement.txt的安装文件
- (CenterDesigner) xinghe@xinghe:~/PycharmProjects/CenterDesigner$ pip freeze > requirements.txt
- 安装所需要的文件
- pip install -r requirement.txt
web全栈应用【爬取(scrapy)数据 -> 通过restful接口存入数据库 -> websocket推送展示到前台】的更多相关文章
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- python3爬取百度知道的问答并存入数据库(MySQL)
一.链接分析: 以"Linux"为搜索的关键字为例: 首页的链接为:https://zhidao.baidu.com/search?lm=0&rn=10&pn=0& ...
- web全栈架构师[笔记] — 02 数据交互
数据交互 一.http协议 基本特点 1.无状态的协议 2.连接过程:发送连接请求.响应接受.发送请求 3.消息分两块:头.体 http和https 二.form 基本属性 action——提交到哪儿 ...
- python爬取网页数据并存储到mysql数据库
#python 3.5 from urllib.request import urlopen from urllib.request import urlretrieve from bs4 impor ...
- NodeJs简单七行爬虫--爬取自己Qzone的说说并存入数据库
没有那么难的,嘿嘿,说起来呢其实挺简单的,或者不能叫爬虫,只需要将自己的数据加载到程序里再进行解析就可以了,如果说你的Qzone是向所有人开放的,那么就有一个JSONP的接口,这么说来就简单了,也就不 ...
- python爬虫爬取ip记录网站信息并存入数据库
import requests import re import pymysql #10页 仔细观察路由 db = pymysql.connect("localhost",&quo ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- Web 全栈大会:万维网之父的数据主权革命
大家好,今天我和大家分享一下由万维网之父发起的一场数据主权革命.什么叫数据主权?很容易理解,现在我们的数据是把持在巨头手里的,你的微信通讯录和聊天记录都无法导出,不管是从人权角度还是从法理角度,这些数 ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
随机推荐
- Java11新特性!
Java11又出新版本了,我还在Java8上停着.不过这也挡不住我对他的热爱,忍不住查看了一下他的新性能,由于自己知识有限,只总结了以下八个特性: 1.本地变量类型推断 什么是局部变量类型推断? va ...
- Eclipse编写代码时设置属于自己的注释
翻看硬盘文件,偶然发现以前存的这么一个小操作,给大家分享一下 1.打开Eclipse,按照以下步骤进行设置: Window -->Preferences->Java->Editor- ...
- socket接收大数据流
客户端: import socket client = socket.socket() client.connect(("127.0.0.1", 9999)) while True ...
- 常见设计模式 (python代码实现)
1.创建型模式 单例模式 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在整个系统中,某个类只能出现一个实例时,单例对 ...
- java 常用工具整理
mapUtil map操作工具类 <!-- https://mvnrepository.com/artifact/org.apache.commons/commons-collections4 ...
- CVS简单介绍
版权声明:本文为博主原创文章,转载请注明出处. https://blog.csdn.net/Jerome_s/article/details/27990707 CVS - Concurrent Ver ...
- 等待通知--wait notify
1.简单理解 在jdk1.5之前用于实现简单的等待通知机制,是线程之间通信的一种最原始的方式.考虑这样一种等待通知的场景:A B线程通过一个共享的非volatile的变量flag来实现通信,每当A线程 ...
- 21 python 初学(json pickle shelve)
json: # _author: lily # _date: 2019/1/19 import json my_dict = {'name': 'lily', 'age': 18} f = open( ...
- iOS开发基础-图片切换(4)之懒加载
延续:iOS开发基础-图片切换(3),对(3)里面的代码用懒加载进行改善. 一.懒加载基本内容 懒加载(延迟加载):即在需要的时候才加载,修改属性的 getter 方法. 注意:懒加载时一定要先判断该 ...
- Golang 入门 : 配置代理
由于一些客观原因的存在,我们开发 Golang 项目的过程总会碰到无法下载某些依赖包的问题.这不是一个小问题,因为你的工作会被打断,即便你使用各种神通解决了问题,很可能这时你的线程已经切换到其他的事情 ...