【原创】大叔经验分享(12)如何程序化kill提交到spark thrift上的sql
spark 2.1.1
hive正在执行中的sql可以很容易的中止,因为可以从console输出中拿到当前在yarn上的application id,然后就可以kill任务,
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20181218163113_65da7e1f-b4b8-4cb8-86cc-236c37aea682
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1544593827645_9409, Tracking URL = http://rm1:8088/proxy/application_1544593827645_9409/
Kill Command = /export/App/hadoop-2.6.1/bin/hadoop job -kill job_1544593827645_9409
但是相同的sql,提交到spark thrift之后,想kill就没那么容易了,需要到spark thrift的页面手工找到那个sql然后kill对应的job:
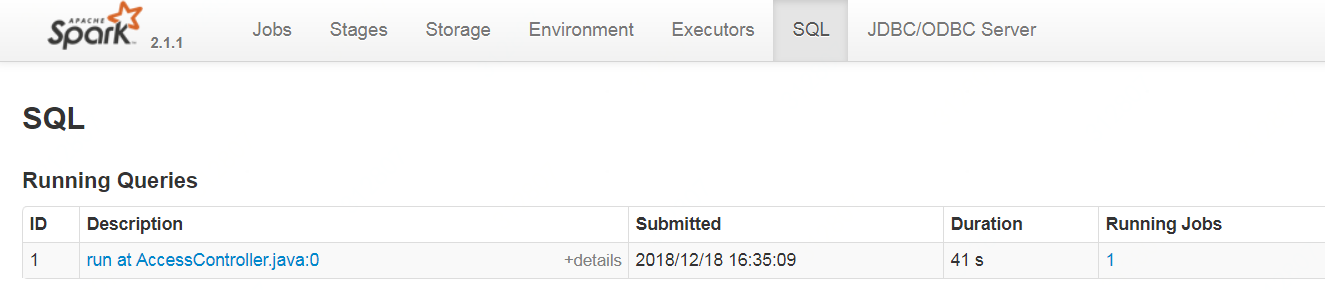
1 找到sql
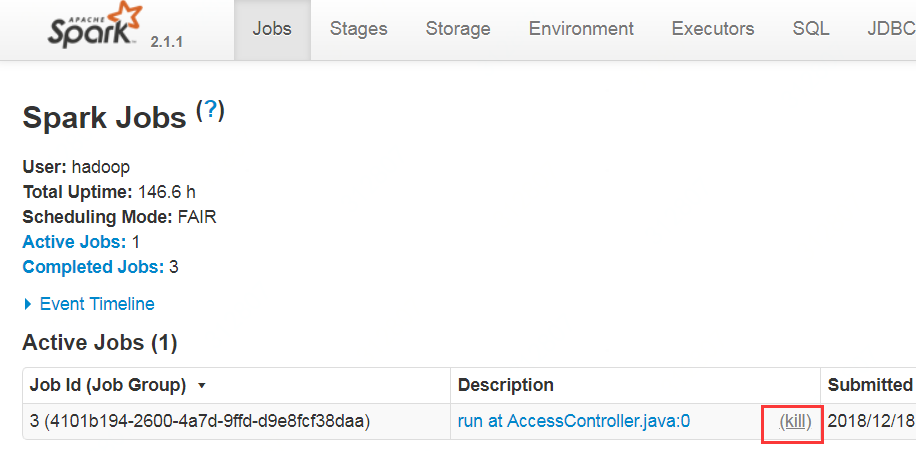
2 kill对应的job
注意到spark thrift页面还可以查看当前所有session,

并且可以查看一个session中所有执行job的情况,
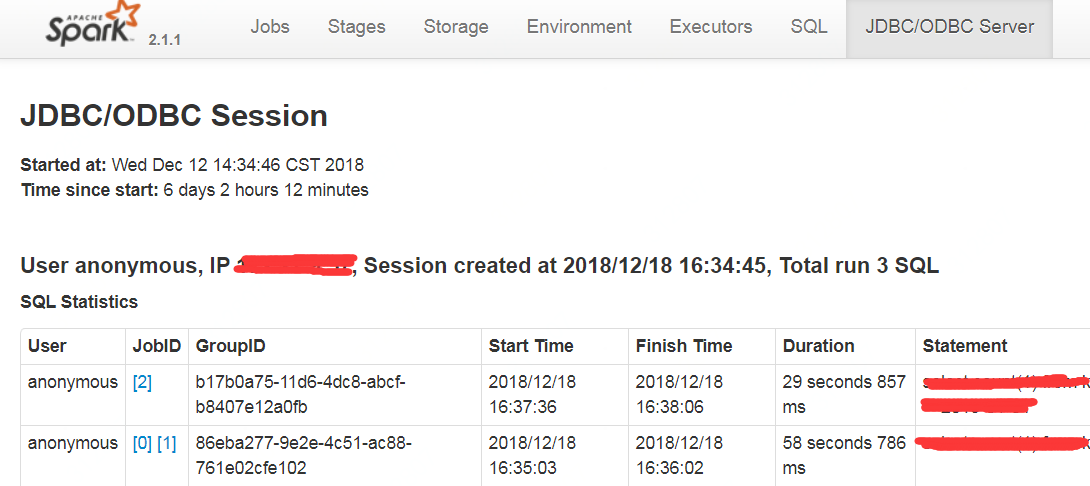
如果能够每次连接spark thrift时记下当前的session id,就可以通过session id找到当前session正在执行的job,查看代码发现,只需要增加一行即可
org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation
private def execute(): Unit = {
statementId = UUID.randomUUID().toString
logInfo(s"Running query '$statement' with $statementId")
//modify here
this.operationLog.writeOperationLog("session id : " + this.getParentSession.getSessionState.getSessionId)
setState(OperationState.RUNNING)
修改后重新打包,用beeline连接spark thrift执行sql效果如下:
0: jdbc:hive2://spark_thrift:11111> select * from test_table;
session id : 0bc63382-a54a-41f8-8c2e-0323f4ebbde6
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (0.277 seconds)
通过session id找到job id后,就可以通过url来kill job
curl http://rm1/proxy/application_1544593827645_0134/jobs/job/kill/?id=3
【原创】大叔经验分享(12)如何程序化kill提交到spark thrift上的sql的更多相关文章
- 【原创】大叔经验分享(5)oozie提交spark任务如何添加依赖
spark任务添加依赖的方式: 1 如果是local方式运行,可以通过--jars来添加依赖: 2 如果是yarn方式运行,可以通过spark.yarn.jars来添加依赖: 这两种方式在oozie上 ...
- 【原创】大叔经验分享(2)为什么hive在大表上加条件后执行limit很慢
问题重现 select id from big_table where name = 'sdlkfjalksdjfla' limit 100; 首先看执行计划: hive> explain se ...
- 【原创】大叔经验分享(46)用户提交任务到yarn报错
用户提交任务到yarn时有可能遇到下面的错误: 1) Requested user anything is not whitelisted and has id 980,which is below ...
- 【原创】经验分享:一个小小emoji尽然牵扯出来这么多东西?
前言 之前也分享过很多工作中踩坑的经验: 一个线上问题的思考:Eureka注册中心集群如何实现客户端请求负载及故障转移? [原创]经验分享:一个Content-Length引发的血案(almost.. ...
- 【原创】大叔经验分享(7)创建hive表时格式如何选择
常用格式 textfile 需要定义分隔符,占用空间大,读写效率最低,非常容易发生冲突(分隔符)的一种格式,基本上只有需要导入数据的时候才会使用,比如导入csv文件: ROW FORMAT DELIM ...
- 【原创】大叔经验分享(81)marathon上app无法重启
通过api调用marathon重启app后出现deployment,但是app不会重启,配置如下: "constraints": [ [ "hostname", ...
- 【原创】大叔经验分享(51)docker报错Exited (137)
docker container启动失败,报错:Exited (137) *** ago,比如 Exited (137) 16 seconds ago 这时通过docker logs查不到任何日志,从 ...
- 【原创】大叔经验分享(27)linux服务器升级glibc故障恢复
redhat6系统默认安装的glibc-2.12,有的软件依赖的是glibc-2.14,这时需要升级glibc,下载安装 http://ftp.gnu.org/gnu/glibc/glibc-2.14 ...
- 【原创】大叔经验分享(18)hive2.0以后通过beeline执行sql没有进度信息
一 问题 在hive1.2中使用hive或者beeline执行sql都有进度信息,但是升级到hive2.0以后,只有hive执行sql还有进度信息,beeline执行sql完全silence,在等待结 ...
随机推荐
- System.Diagnostics.Process 测试案例
1.System.Diagnostics.Process 执行exe文件 创建项目,编译成功后,然后把要运行的exe文件拷贝到该项目的运行工作目录下即可,代码如下: using System; usi ...
- [转帖]Linux中的15个基本‘ls’命令示例
Linux中的15个基本‘ls’命令示例 https://linux.cn/article-5109-1.html ls -lt 和 ls -ltr 来查看文件新旧顺序. list time rese ...
- java异常处理规范
异常处理的优势[存在意义]:异常检测者有检测出异常的能力,但不知道在出现该异常的情况下应该怎么处理.故库方法一般会抛出异常给调用者来处理.所以总结而言,异常处理的优势就是,将处理错误(调用者处理)从检 ...
- flex知识点归纳
1.flex-shrink <div id="content"> <div class="box" style="backgroun ...
- Python——hashilib 模块(哈希模块)
hashilib 模块 摘要算法 import hashlib # 提供摘要算法的模块 md5 = hashlib.md5() md5.update(b'alex3714') print(md5.he ...
- Python——Django目录说明
一.Django安装好后,建立djangosite的开发项目 #django-admin startproject djangosite 二.djangosite目录内容 ''' djangosite ...
- Android NDK(C++) 双进程守护
双进程守护如果从进程管理器观察会发现新浪微博.支付宝和QQ等都有两个以上相关进程,其中一个就是守护进程,由此可以猜到这些商业级的软件都采用了双进程守护的办法. 什么是双进程守护呢?顾名思义就是两个进程 ...
- 基于JavaCv并发读取本地视频流并提取每帧32位dhash特征
1.读取本地视频流,pom依赖 依赖于 org.bytedeco下的javacv/opencv/ffmpeg 包 <dependency> <groupId>org.byted ...
- Swift 之Carthage
1. 安装 $ brew update //更新brew $ brew install carthage //下载carthage $ carthage version ...
- Android查看联系人简单记录
简单实现打印联系人信息,可以作为插入联系人的基础和主要代码块,作为个人记录的小逻辑 package com.lgqrlchinese.contactstest; import android.Mani ...