02-再探MySQL数据库
一、数据类型
1、数值类型
a、整数类型
整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT
作用:存储年龄,等级,id,各种号码等。
- ========================================
- tinyint[(m)] [unsigned] [zerofill]
- 小整数,数据类型用于保存一些范围的整数数值范围:
- 有符号:
- -128 ~ 127
- 无符号:
- 0 ~ 255
- PS: MySQL中无布尔值,使用tinyint(1)构造。
- ========================================
- int[(m)][unsigned][zerofill]
- 整数,数据类型用于保存一些范围的整数数值范围:
- 有符号:
- -2147483648 ~ 2147483647
- 无符号:
- 0 ~ 4294967295
- ========================================
- bigint[(m)][unsigned][zerofill]
- 大整数,数据类型用于保存一些范围的整数数值范围:
- 有符号:
- -9223372036854775808 ~ 9223372036854775807
- 无符号:
- 0 ~ 18446744073709551615
验证一下:
- =========有符号和无符号tinyint==========
- # tinyint默认为有符号
- mysql> create table t1(num tinyint); # 创建t1表,默认为有符号,即数字前有正负号
- mysql> desc t1; # 查看表信息
- +-------+------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+------------+------+-----+---------+-------+
- | num | tinyint(4) | YES | | NULL | |
- +-------+------------+------+-----+---------+-------+
- mysql> insert into t1 values(-128),(127); # 注意:当插入的值超过这个范围,会报1264错误。
- mysql> select * from t1;
- +------+
- | num |
- +------+
- | -128 |
- | 127 |
- +------+
- # 设置无符号tinyint
- mysql> create table t2(num tinyint unsigned); # 创建t2,指定没有符号。
- mysql> desc t2;
- +-------+---------------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+---------------------+------+-----+---------+-------+
- | num | tinyint(3) unsigned | YES | | NULL | |
- +-------+---------------------+------+-----+---------+-------+
- mysql> insert into t2 values(0),(255); # 注意:当插入的值超过这个范围,会报1264错误。
- mysql> select * from t2;
- +------+
- | num |
- +------+
- | 0 |
- | 255 |
- +------+
- ============有符号和无符号int=============
- # int默认为有符号
- mysql> create table t3(num int);
- mysql> desc t3;
- +-------+---------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+---------+------+-----+---------+-------+
- | num | int(11) | YES | | NULL | |
- +-------+---------+------+-----+---------+-------+
- mysql> insert into t3 values(-2147483648),(2147483647);
- mysql> select * from t3;
- +-------------+
- | num |
- +-------------+
- | -2147483648 |
- | 2147483647 |
- +-------------+
- # 设置无符号int
- mysql> create table t4(num int unsigned); # 指定没有符号。
- mysql> desc t4;
- +-------+------------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+------------------+------+-----+---------+-------+
- | num | int(10) unsigned | YES | | NULL | |
- +-------+------------------+------+-----+---------+-------+
- mysql> insert into t4 values(0),(4294967295);
- mysql> select * from t4;
- +------------+
- | num |
- +------------+
- | 0 |
- | 4294967295 |
- +------------+
- ==============有符号和无符号bigint=============
- # bigint默认为有符号
- mysql> create table t5(num bigint);
- mysql> desc t5;
- +-------+------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+------------+------+-----+---------+-------+
- | num | bigint(20) | YES | | NULL | |
- +-------+------------+------+-----+---------+-------+
- mysql> insert into t5 values(-9223372036854775808),(9223372036854775807);
- mysql> select * from t5;
- +----------------------+
- | num |
- +----------------------+
- | -9223372036854775808 |
- | 9223372036854775807 |
- +----------------------+
- # 设置无符号bigint
- mysql> create table t6(num bigint unsigned);
- mysql> desc t6;
- +-------+---------------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+---------------------+------+-----+---------+-------+
- | num | bigint(20) unsigned | YES | | NULL | |
- +-------+---------------------+------+-----+---------+-------+
- mysql> insert into t6 values(0),(18446744073709551615);
- mysql> select * from t6;
- +----------------------+
- | num |
- +----------------------+
- | 0 |
- | 18446744073709551615 |
- +----------------------+
- ==========用zerofill测试整数类型的显示宽度=============
- mysql> create table t7(num int(3) zerofill);
- mysql> desc t7;
- +-------+--------------------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+--------------------------+------+-----+---------+-------+
- | num | int(3) unsigned zerofill | YES | | NULL | |
- +-------+--------------------------+------+-----+---------+-------+
- mysql> insert into t7 values(1),(11),(111),(1111);
- mysql> select * from t7;
- +------+
- | num |
- +------+
- | 001 |
- | 011 |
- | 111 |
- | 1111 | # 超过宽度限制仍然可以存
- +------+
- 注意:为该类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关,存储范围如下图。

int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的。
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok。
b、浮点型
定点数类型 DEC等同于DECIMAL
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、体重、体质参数等。
- ======================================
- #FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
- 定义:
- 单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
- 有符号:
- -3.402823466E+38 to -1.175494351E-38,
- 1.175494351E-38 to 3.402823466E+38
- 无符号:
- 1.175494351E-38 to 3.402823466E+38
- 精确度:
- **** 随着小数的增多,精度变得不准确 ****
- ======================================
- #DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
- 定义:
- 双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
- 有符号:
- -1.7976931348623157E+308 to -2.2250738585072014E-308
- 2.2250738585072014E-308 to 1.7976931348623157E+308
- 无符号:
- 2.2250738585072014E-308 to 1.7976931348623157E+308
- 精确度:
- ****随着小数的增多,精度比float要高,但也会变得不准确 ****
- ======================================
- decimal[(m[,d])] [unsigned] [zerofill]
- 定义:
- 准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
- 精确度:
- **** 随着小数的增多,精度始终准确 ****
- 对于精确数值计算时需要用此类型
- decaimal能够存储精确值的原因
2、日期类型
DATE TIME DATETIME TIMESTAMP YEAR
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等。
- YEAR
- YYYY(1901/2155)
- DATE
- YYYY-MM-DD(1000-01-01/9999-12-31)
- TIME
- HH:MM:SS('-838:59:59'/'838:59:59')
- DATETIME
- YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59)
- TIMESTAMP
- YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
验证一下:
- ============year===========
- mysql> create table t8(born_year year); # 无论year指定何种宽度,最后都默认是year(4)
- mysql> desc t8;
- +-----------+---------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-----------+---------+------+-----+---------+-------+
- | born_year | year(4) | YES | | NULL | |
- +-----------+---------+------+-----+---------+-------+
- mysql> insert into t8 values(1901),(2155); # 超出这个范围会报1264错误。
- mysql> select * from t8;
- +-----------+
- | born_year |
- +-----------+
- | 1901 |
- | 2155 |
- +-----------+
- ============date,time,datetime===========
- mysql> create table t9(d date,t time,dt datetime);
- mysql> desc t9;
- +-------+----------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+----------+------+-----+---------+-------+
- | d | date | YES | | NULL | |
- | t | time | YES | | NULL | |
- | dt | datetime | YES | | NULL | |
- +-------+----------+------+-----+---------+-------+
- mysql> insert into t9 values(now(),now(),now());
- mysql> select * from t9;
- +------------+----------+---------------------+
- | d | t | dt |
- +------------+----------+---------------------+
- | 2019-04-10 | 12:26:12 | 2019-04-10 12:26:12 |
- +------------+----------+---------------------+
- ============timestamp===========
- mysql> create table t10(time timestamp);
- mysql> desc t10;
- mysql> insert into t10 values();
- mysql> insert into t10 values(null);
- mysql> select * from t10;
- +---------------------+
- | time |
- +---------------------+
- | 2018-01-10 11:50:52 |
- | 2018-01-10 11:51:07 |
- +---------------------+
- ============注意啦,注意啦,注意啦===========
- 1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入
- 2. 插入年份时,尽量使用4位值
- 3. 插入两位年份时,<=69,以20开头,比如50, 结果2050
- >=70,以19开头,比如71,结果1971
- mysql> create table t11(y year);
- mysql> desc t11;
- +-------+---------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+---------+------+-----+---------+-------+
- | y | year(4) | YES | | NULL | |
- +-------+---------+------+-----+---------+-------+
- mysql> insert into t11 values(50),(69),(70),(99);
- mysql> select * from t11;
- +------+
- | y |
- +------+
- | 2050 |
- | 2069 |
- | 1970 |
- | 1999 |
- +------+
datetime与timestamp的区别:
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。
下面就来总结一下两种日期类型的区别:
- DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2037年。
- DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,操作系统以及客户端连接都有时区的设置。
- DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。
- DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP)。
如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
3、字符串类型
字符串类型主要为char与varchar类型,字符串类型在生产场景中,主要存储像姓名、邮箱、地址等一些描述信息。
- #注意:char和varchar括号内的参数指的都是字符的长度
- #char类型:定长,简单粗暴,浪费空间,存取速度快
- 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
- 存储:
- 存储char类型的值时,会往右填充空格来满足长度
- 例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储
- 检索:
- 在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';)
- #varchar类型:变长,精准,节省空间,存取速度慢
- 字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html)
- 存储:
- varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来
- 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
- 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
- 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535)
- 检索:
- 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
官网解释如下:

测试前了解两个函数
- length:查看字节数
- char_length:查看字符数
我们实践来了解一下:
- mysql> create table t14(c char(5),v varchar(5));
- mysql> desc t14;
- +-------+------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+------------+------+-----+---------+-------+
- | c | char(5) | YES | | NULL | |
- | v | varchar(5) | YES | | NULL | |
- +-------+------------+------+-----+---------+-------+
- mysql> insert into t14 values("苍老师 ","苍老师 ");
- mysql> select c,char_length(c),v,char_length(v) from t14;
- +--------+----------------+---------+----------------+
- | c | char_length(c) | v | char_length(v) |
- +--------+----------------+---------+----------------+
- | 苍老师 | 3 | 苍老师 | 4 |
- +--------+----------------+---------+----------------+
- mysql> select c,length(c),v,length(v) from t14;
- +--------+-----------+---------+-----------+
- | c | length(c) | v | length(v) |
- +--------+-----------+---------+-----------+
- | 苍老师 | 9 | 苍老师 | 10 |
- +--------+-----------+---------+-----------+
- # char填充空格来满足固定长度,但是在查询时却会很不要脸地删除尾部的空格(装作自己好像没有浪费过空间一样),然后修改sql_mode让其现出原形。
- # 略施小计,让char现出原形
- mysql> SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';
- mysql> select c,char_length(c),v,char_length(v) from t14;
- +----------+----------------+---------+----------------+
- | c | char_length(c) | v | char_length(v) |
- +----------+----------------+---------+----------------+
- | 苍老师 | 5 | 苍老师 | 4 |
- +----------+----------------+---------+----------------+
- mysql> select c,length(c),v,length(v) from t14;
- +----------+-----------+---------+-----------+
- | c | length(c) | v | length(v) |
- +----------+-----------+---------+-----------+
- | 苍老师 | 11 | 苍老师 | 10 |
- +----------+-----------+---------+-----------+
- # 跟上面相比char_length(c)和length(c)的值就原形毕露了。
- # 虽然 CHAR 和 VARCHAR 的存储方式不太相同,但是对于两个字符串的比较,都只比 较其值,忽略 CHAR 值存在的右填充,即使将 SQL_MODE 设置为 PAD_CHAR_TO_FULL_LENGTH 也一样,,但这不适用于like。
总结:
- #常用字符串系列:char与varchar
- 注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡
- #其他字符串系列(效率:char>varchar>text)
- TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT
- BLOB 系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB
- BINARY系列 BINARY VARBINARY
- text:text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
- mediumtext:A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters.
- longtext:A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters.
4、枚举类型与集合类型
字段的值只能在给定范围中选择,如:单选框,多选框。
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
- mysql> create table t15(id int,
- name varchar(32),
- sex enum('male','female'),
- level enum('vip1','vip2','vip3','vip4'),
- hobby set('music','read','run','movie')
- );
- mysql> insert into t15 values
- -> (1,'alex','female','vip3','music,movie'),
- -> (2,'egon','male','vip1','read,run,music');
- mysql> select * from t15;
- +------+------+--------+-------+----------------+
- | id | name | sex | level | hobby |
- +------+------+--------+-------+----------------+
- | 1 | alex | female | vip3 | music,movie |
- | 2 | egon | male | vip1 | music,read,run |
- +------+------+--------+-------+----------------+
- # 插入值不在枚举与集合类型时,值为空。
- mysql> insert into t15 values
- -> (3,'yuan','female1','vip31','music1,movie1');
- mysql> select * from t15;
- +------+------+--------+-------+----------------+
- | id | name | sex | level | hobby |
- +------+------+--------+-------+----------------+
- | 1 | alex | female | vip3 | music,movie |
- | 2 | egon | male | vip1 | music,read,run |
- | 3 | yuan | | | |
- +------+------+--------+-------+----------------+
二、完整性约束
1、介绍
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
- PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
- FOREIGN KEY (FK) 标识该字段为该表的外键
- NOT NULL 标识该字段不能为空
- UNIQUE KEY (UK) 标识该字段的值是唯一的
- AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
- DEFAULT 为该字段设置默认值
- UNSIGNED 无符号
- ZEROFILL 使用0填充
说明:
- 1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值
- 2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值
- sex enum('male','female') not null default 'male'
- age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20
- 3. 是否是key
- 主键 primary key
- 外键 foreign key
- 索引 (index,unique...)
2、not null 与 default
是否可空,null表示空,非字符串
not null - 不可空
null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值。
- mysql> create table t16(id int,
- -> name varchar(32),
- -> sex enum('male','female') not null default 'male');
- mysql> desc t16;
- +-------+-----------------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+-----------------------+------+-----+---------+-------+
- | id | int(11) | YES | | NULL | |
- | name | varchar(32) | YES | | NULL | |
- | sex | enum('male','female') | NO | | male | |
- +-------+-----------------------+------+-----+---------+-------+
- mysql> insert into t16(id,name) values(1,'egon');
- mysql> select * from t16;
- +------+------+------+
- | id | name | sex |
- +------+------+------+
- | 1 | egon | male |
- +------+------+------+
3、unique
对字段值进行唯一性约束。可以对单列设置,也可以为多列设置联合唯一。
- # 单列唯一
- # 方式一:
- mysql> create table t17(id int unique,name varchar(32) unique);
- mysql> desc t17;
- +-------+-------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+-------------+------+-----+---------+-------+
- | id | int(11) | YES | UNI | NULL | |
- | name | varchar(32) | YES | UNI | NULL | |
- +-------+-------------+------+-----+---------+-------+
- mysql> insert into t17 values(1, 'IT'),(2,'IT'); # 插入相同的值会报错。
- ERROR 1062 (23000): Duplicate entry 'IT' for key 'name'
- # 方式二:
- mysql> create table t18(id int,
- -> name varchar(32),
- -> unique(id),
- -> unique(name));
- mysql> desc t18;
- +-------+-------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+-------------+------+-----+---------+-------+
- | id | int(11) | YES | UNI | NULL | |
- | name | varchar(32) | YES | UNI | NULL | |
- +-------+-------------+------+-----+---------+-------+
- mysql> insert into t18 values(1, 'IT'),(2,'IT');
- ERROR 1062 (23000): Duplicate entry 'IT' for key 'name'
- # 联合唯一
- mysql> create table t19(
- -> id int,
- -> ip char(15),
- -> port int,
- -> unique(id),
- -> unique(ip,port)
- -> );
- mysql> desc t19;
- +-------+----------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+----------+------+-----+---------+-------+
- | id | int(11) | YES | UNI | NULL | |
- | ip | char(15) | YES | MUL | NULL | |
- | port | int(11) | YES | | NULL | |
- +-------+----------+------+-----+---------+-------+
- mysql> insert into t19 values
- -> (1,'192.168.11.11',80),
- -> (2,'192.168.11.11',88),
- -> (3,'192.168.11.12',80);
- mysql> select * from t19;
- +------+---------------+------+
- | id | ip | port |
- +------+---------------+------+
- | 1 | 192.168.11.11 | 80 |
- | 2 | 192.168.11.11 | 88 |
- | 3 | 192.168.11.12 | 80 |
- +------+---------------+------+
- # 咱们接下来重新插入第一条IP和端口
- mysql> insert into t19 values(4,'192.168.11.11',80);
- ERROR 1062 (23000): Duplicate entry '192.168.11.11-80' for key 'ip'
4、primary key
primary key字段的值不为空且唯一(非空且唯一 ,not null unique)
一个表中可以:
单列做主键
多列做主键(复合主键)
但一个表内只能有一个主键primary key
- # 默认的存储引擎为InnoDB:一张表内必须要有一个主键。
- # 单列主键
- mysql> create table t20(
- -> id int primary key,
- -> name varchar(32)
- -> );
- mysql> desc t20;
- +-------+-------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+-------------+------+-----+---------+-------+
- | id | int(11) | NO | PRI | NULL | |
- | name | varchar(32) | YES | | NULL | |
- +-------+-------------+------+-----+---------+-------+
- mysql> insert into t20 values
- -> (1,'alex'),
- -> (2,'egon');
- mysql> select * from t20;
- +----+------+
- | id | name |
- +----+------+
- | 1 | alex |
- | 2 | egon |
- +----+------+
- mysql> insert into t20 values(2,'yuan');
- ERROR 1062 (23000): Duplicate entry '' for key 'PRIMARY'
- mysql> insert into t20(name) values('yuan');
- ERROR 1364 (HY000): Field 'id' doesn't have a default value
- # 复合主键
- mysql> create table t22(
- -> ip char(15),
- -> port int,
- -> primary key(ip,port)
- -> );
- mysql> desc t22;
- +-------+----------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+----------+------+-----+---------+-------+
- | ip | char(15) | NO | PRI | NULL | |
- | port | int(11) | NO | PRI | NULL | |
- +-------+----------+------+-----+---------+-------+
- mysql> insert into t22 values
- -> ('192.168.11.11',80),
- -> ('192.168.11.11',81),
- -> ('192.168.11.12',80);
- mysql> select * from t22;
- +---------------+------+
- | ip | port |
- +---------------+------+
- | 192.168.11.11 | 80 |
- | 192.168.11.11 | 81 |
- | 192.168.11.12 | 80 |
- +---------------+------+
- # 插入重复的值
- mysql> insert into t22 values
- -> ('192.168.11.11',80);
- ERROR 1062 (23000): Duplicate entry '192.168.11.11-80' for key 'PRIMARY'
5、auto_increment
约束字段为自动增长,被约束的字段必须同时被key约束。
- mysql> create table t23(
- -> id int primary key auto_increment,
- -> name varchar(32)
- -> );
- mysql> desc t23;
- +-------+-------------+------+-----+---------+----------------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+-------------+------+-----+---------+----------------+
- | id | int(11) | NO | PRI | NULL | auto_increment |
- | name | varchar(32) | YES | | NULL | |
- +-------+-------------+------+-----+---------+----------------+
- mysql> insert into t23(name) values
- -> ('alex'),
- -> ('egon');
- mysql> select * from t23;
- +----+------+
- | id | name |
- +----+------+
- | 1 | alex |
- | 2 | egon |
- +----+------+
- mysql> insert into t23 values(5,'yuan'); # 自己指定id只要不违反约束条件即可。
- # 关于起始偏移量和步长(了解)
- # 1. 查看默认值
- mysql> show variables like 'auto_inc%';
- +--------------------------+-------+
- | Variable_name | Value |
- +--------------------------+-------+
- | auto_increment_increment | 1 | # 默认步长为1
- | auto_increment_offset | 1 | # 默认起始偏移量为1
- +--------------------------+-------+
- # 2. 设置步长
- mysql> set session auto_increment_increment=5; # 当前会话级别
- mysql> set global auto_increment_increment=5; # 设置全局,需要退出重新加载才能生效。
- # 3.设置起始偏移量
- mysql> set session auto_increment_offset=3;
- mysql> set global auto_increment_offset=3;
- # 注意:起始偏移量要<=步长,否则设置无效。
- # 对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长,一般情况下,delete后面会接where条件,对指定的内容进行删除。
- mysql> delete from t23; # 清空表
- mysql> insert into t23(name) values('alex');
- mysql> select * from t23;
- +----+------+
- | id | name |
- +----+------+
- | 16 | alex |
- +----+------+
- # truncate是直接清空表,在删除大表时用它。它会将起始偏移量重置至初始状态。
- mysql> truncate table t23;
6、foreign key
foreign key,建立表之间的关系。
下面我们通过一个例子来说明,比如我们现在有一张员工表:
|
employee |
||||
|
id |
name |
age |
department |
comment |
|
1 |
任盈盈 |
18 |
公关部 |
公关能力有限部门 |
|
2 |
张无忌 |
23 |
销售部 |
销售能力有限部门 |
|
3 |
令狐冲 |
25 |
销售部 |
销售能力有限部门 |
|
4 |
小龙女 |
24 |
公关部 |
公关能力有限部门 |
|
5 |
灭绝师太 |
56 |
公关部 |
公关能力有限部门 |
|
6 |
欧阳锋 |
53 |
技术部 |
靠技术吃饭部门 |
大家通过观察这张表,能不能找出两个问题:
1、新增员工时,部门和部门描述重复,浪费空间;
2、后期部门信息发生变更,不便于维护。
为了解决上面的问题,就引出了foreign key 的知识点了。先通过一张图,我们来了解一下。
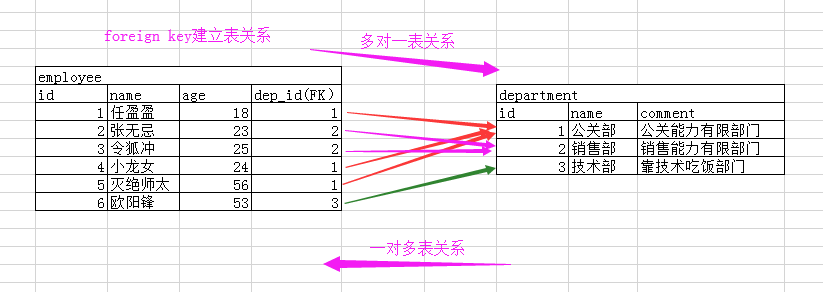
大家看一下这样是不是就完美的解决了上面的问题了。有思路了,我们来动手实现一下。
- # 1、建立表关系
- # a、先建被关联的表,且保证被关联的字段唯一
- mysql> create table department(
- -> id int primary key,
- -> name varchar(32),
- -> comment varchar(128)
- -> );
- # b、再建关联的表
- mysql> create table employee(
- -> id int primary key,
- -> name varchar(32),
- -> age tinyint unsigned,
- -> dep_id int,
- -> foreign key(dep_id) references department(id) # 指定外建字段,跟哪张表哪个字段建立关系。
- -> );
- # 2、插入数据
- a、先往被关联表插入记录
- mysql> insert into department values
- -> (1,'公关部','公关能力有限部门'),
- -> (2,'销售部','销售能力有限部门'),
- -> (3,'技术部','靠技术吃饭部门');
- mysql> select * from department;
- +----+--------+------------------+
- | id | name | comment |
- +----+--------+------------------+
- | 1 | 公关部 | 公关能力有限部门 |
- | 2 | 销售部 | 销售能力有限部门 |
- | 3 | 技术部 | 靠技术吃饭部门 |
- +----+--------+------------------+
- b、再往关联表插入记录
- mysql> insert into employee values
- -> (1,'任盈盈',18,1),
- -> (2,'张无忌',23,2),
- -> (3,'令狐冲',25,2),
- -> (4,'小龙女',24,1),
- -> (5,'灭绝师太',56,1),
- -> (6,'欧阳锋',53,3);
- mysql> select * from employee;
- +----+----------+------+--------+
- | id | name | age | dep_id |
- +----+----------+------+--------+
- | 1 | 任盈盈 | 18 | 1 |
- | 2 | 张无忌 | 23 | 2 |
- | 3 | 令狐冲 | 25 | 2 |
- | 4 | 小龙女 | 24 | 1 |
- | 5 | 灭绝师太 | 56 | 1 |
- | 6 | 欧阳锋 | 53 | 3 |
- +----+----------+------+--------+
- # 3、删除数据和更新数据
- # a、先删除关联的数据
- mysql> delete from employee where dep_id=2;
- # b、再删除被关联的数据
- mysql> delete from department where id=2;
- # c、因为有外建约束,无法进行更新操作。
- # 4、解决上面的问题,只需在建关联表的时候,指定一下同步即可。
- # a、建立关联表
- mysql> create table employee(
- -> id int primary key,
- -> name varchar(32),
- -> age tinyint unsigned,
- -> dep_id int,
- -> foreign key(dep_id) references department(id)
- on delete cascade # 删除时同步
- on update cascade # 更新时同步
- -> );
- # b、插入记录
- mysql> insert into employee values
- -> (1,'任盈盈',18,1),
- -> (2,'张无忌',23,2),
- -> (3,'令狐冲',25,2),
- -> (4,'小龙女',24,1),
- -> (5,'灭绝师太',56,1),
- -> (6,'欧阳锋',53,3);
- # c、删除部门
- mysql> delete from department where id=1;
- mysql> select * from department;
- +----+--------+------------------+
- | id | name | comment |
- +----+--------+------------------+
- | 2 | 销售部 | 销售能力有限部门 |
- | 3 | 技术部 | 靠技术吃饭部门 |
- +----+--------+------------------+
- mysql> select * from employee; # 与之关联的员工一并删除了。
- +----+--------+------+--------+
- | id | name | age | dep_id |
- +----+--------+------+--------+
- | 2 | 张无忌 | 23 | 2 |
- | 3 | 令狐冲 | 25 | 2 |
- | 6 | 欧阳锋 | 53 | 3 |
- +----+--------+------+--------+
- # d、更新部门
- mysql> update department set id=222 where id=2;
- mysql> select * from department;
- +-----+--------+------------------+
- | id | name | comment |
- +-----+--------+------------------+
- | 3 | 技术部 | 靠技术吃饭部门 |
- | 222 | 销售部 | 销售能力有限部门 |
- +-----+--------+------------------+
- mysql> select * from employee;
- +----+--------+------+--------+
- | id | name | age | dep_id |
- +----+--------+------+--------+
- | 2 | 张无忌 | 23 | 222 |
- | 3 | 令狐冲 | 25 | 222 |
- | 6 | 欧阳锋 | 53 | 3 |
- +----+--------+------+--------+
三、单表查询
1、单表查询语法
- SELECT 字段1,字段2... FROM 表名
- WHERE 条件
- GROUP BY field
- HAVING 筛选
- ORDER BY field
- LIMIT 限制条数
2、关键字的执行优先级(重点)
- 重点中的重点:关键字的执行优先级
- from
- where
- group by
- having
- select
- distinct
- order by
- limit
- 注解:
- 1.找到表:from
- 2.拿着where指定的约束条件,去文件/表中取出一条条记录
- 3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
- 4.将分组的结果进行having过滤
- 5.执行select
- 6.去重
- 7.将结果按条件排序:order by
- 8.限制结果的显示条数
看一下在SQL语句中如何体现。
- (7) SELECT
- (8) DISTINCT <select_list>
- (1) FROM <left_table>
- (3) <join_type> JOIN <right_table>
- (2) ON <join_condition>
- (4) WHERE <where_condition>
- (5) GROUP BY <group_by_list>
- (6) HAVING <having_condition>
- (9) ORDER BY <order_by_condition>
- (10) LIMIT <limit_number>
3、简单查询
a、建立表
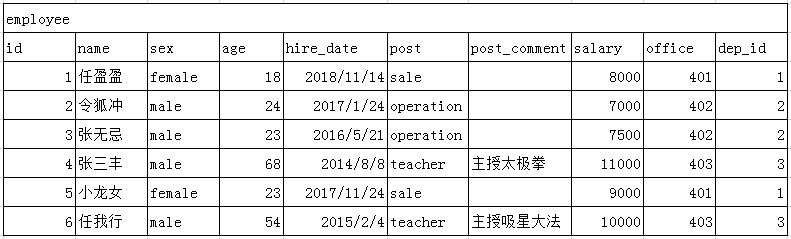
- mysql> create table employee(
- -> id int primary key auto_increment,
- -> name varchar(32) not null,
- -> sex enum('male','female') not null default 'male',
- -> age tinyint unsigned not null default 28,
- -> hire_date date not null,
- -> post varchar(32),
- -> post_comment varchar(128),
- -> salary decimal(9,2),
- -> office int, # 一个部门一个屋子
- -> dep_id int
- -> );
- mysql> desc employee;
- +--------------+-----------------------+------+-----+---------+----------------+
- | Field | Type | Null | Key | Default | Extra |
- +--------------+-----------------------+------+-----+---------+----------------+
- | id | int(11) | NO | PRI | NULL | auto_increment |
- | name | varchar(32) | NO | | NULL | |
- | sex | enum('male','female') | NO | | male | |
- | age | tinyint(3) unsigned | NO | | 28 | |
- | hire_date | date | NO | | NULL | |
- | post | varchar(32) | YES | | NULL | |
- | post_comment | varchar(128) | YES | | NULL | |
- | salary | decimal(9,2) | YES | | NULL | |
- | office | int(11) | YES | | NULL | |
- | dep_id | int(11) | YES | | NULL | |
- +--------------+-----------------------+------+-----+---------+----------------+
b、插入数据
- insert into employee(name,sex,age,hire_date,post,post_comment,salary,office,dep_id)
- values
- ('任盈盈','female',18,'2018-11-14','sale',null,8000,401,1),
- ('小龙女','female',23,'2017-11-24','sale',null,9000,401,1),
- ('王语嫣','female',22,'2016-1-14','sale',null,7000,401,1),
- ('黄蓉','female',21,'2018-12-14','sale',null,8000,401,1),
- ('秋香','female',19,'2019-1-11','sale',null,8000,401,1),
- ('周芷若','female',20,'2018-11-11','sale',null,7000,401,1),
- ('赵敏','female',21,'2017-2-18','sale',null,8000,401,1),
- ('令狐冲','male',24,'2017-1-24','operation',null,7000,402,2),
- ('张无忌','male',23,'2016-5-21','operation',null,7500,402,2),
- ('郭靖','male',25,'2016-7-28','operation',null,8000,402,2),
- ('杨康','male',24,'2016-8-28','operation',null,7000,402,2),
- ('杨铁心','male',54,'2015-4-18','operation',null,9000,402,2),
- ('杨过','male',27,'2017-5-28','operation',null,7000,402,2),
- ('张三丰','male',68,'2014-8-8','teacher','主授太极拳',11000,403,3),
- ('任我行','male',54,'2015-2-4','teacher','主授吸星大法',10000,403,3),
- ('岳不群','male',50,'2016-12-24','teacher','主授华山剑法',9000,403,3);
c、简单查询
- # 1、简单查询
- select id,name,sex,age,hire_date,post,post_comment,salary,office,dep_id from employee;
- select * from employee;
- select id,name,salart from employee;
- # 避免重复distinct
- select distinct post from employee;
- # 通过四则运算查询
- select name,salary * 12 from employee;
- select name,salary * 12 as annual_salary from employee; # 取别名方式一
- select name,salary * 12 annual_salary from employee; # 取别名方式二
d、小练习
- # 1、查出所有员工的name和薪资;
- # 2、查出所有的岗位(去重);
- # 3、查出所有员工的name和年薪(指定别名为annual_salary);
4、where约束
where字句中可以使用:
- 比较运算符:><>= <= <> !=
- between 80 and 100 值在10到20之间
- in(80,90,100) 值是80或90或100
- like '杨%'pattern可以是%或_,%表示任意多字符, _表示一个字符
- 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
- # 1、单条件查询
- # 查询销售的所有员工
- select name from employee where post='sale';
- # 2、多条件查询
- # 查询销售中工资大于等于8000的员工姓名和薪资
- select name,salary from employee where post='sale' and salary >=8000;
- # 3、关键字between and
- # 查询工资在8000到10000的员工姓名
- select name from employee where salary between 8000 and 10000;
- # 查询工资不在8000到10000的员工姓名
- select name from employee where salary not between 8000 and 10000;
- # 4、关键字is null(判断某个字段是否为null不能用等号,需要用is)
- # 查询职位描述为空的员工
- select name,post_comment from employee where post_comment is null;
- # 查询职位描述不为空的员工
- select name,post_comment from employee where post_comment is not null;
- # 注意''是空字符串,不是null
- select name,post_comment from employee where post_comment=''; # 查询没有结果。
- # 执行下面这条SQL,再用上条查看,就会有结果了
- update employee set post_comment='' where id=1;
- # 5、关键字IN集合查询
- # 查询工资为8000或9000或10000的员工姓名和工资
- select name,salary from employee where salary=8000 or salary=9000 or salary=10000;
- select name,salary from employee where salary in (8000,9000,10000);
- # 查询工资不为8000或9000或10000的员工姓名和工资
- select name,salary from employee where salary not in (8000,9000,10000);
- # 6、关键字LIKE模糊查询
- # a、通配符"%"
- mysql> select name from employee where name like '杨%';
- +--------+
- | name |
- +--------+
- | 杨康 |
- | 杨铁心 |
- | 杨过 |
- +--------+
- # b、通配符"_"
- mysql> select name from employee where name like '杨_';
- +------+
- | name |
- +------+
- | 杨康 |
- | 杨过 |
- +------+
- mysql> select name from employee where name like '杨__';
- +--------+
- | name |
- +--------+
- | 杨铁心 |
- +--------+
小练习:
- 1. 查看岗位是teacher的员工姓名、年龄
- 2. 查看岗位是teacher且年龄大于30岁的员工姓名、年龄
- 3. 查看岗位是teacher且薪资在9000-10000范围内的员工姓名、年龄、薪资
- 4. 查看岗位描述不为NULL的员工信息
- 5. 查看岗位是teacher且薪资是10000或9000或30000的员工姓名、年龄、薪资
- 6. 查看岗位是teacher且薪资不是10000或9000或30000的员工姓名、年龄、薪资
- 7. 查看岗位是teacher且名字是“杨”开头的员工姓名、年薪
5、分组查询 group by
- # 什么是分组,为什么要分组?
- #1、首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的;
- #2、分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等;
- #3、为何要分组呢?
- 取每个部门的最高工资
- 取每个部门的员工数
- 取男人数和女人数
- 小窍门:‘每’这个字后面的字段,就是我们分组的依据
- #4、大前提:
- 可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数。
- # 小试牛刀
- select * from employee group by post; # 注意:会报1055错误,下面会详细说明
- # 单独使用GROUP BY关键字分组
- SELECT post FROM employee GROUP BY post;
- 注意:我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数。
- # GROUP BY关键字和GROUP_CONCAT()函数一起使用
- # 按照岗位分组,并查看组内成员名
- SELECT post,GROUP_CONCAT(name) FROM employee GROUP BY post;
- SELECT post,GROUP_CONCAT(name) as emp_members FROM employee GROUP BY post;
- # GROUP BY与聚合函数一起使用
- # 按照岗位分组,并查看每个组有多少人
- select post,count(id) as count from employee group by post;
- # 强调:
- # 如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义。
- # 多条记录之间的某个字段值相同,该字段通常用来作为分组的依据。
- # 聚合函数
- # MAX:最大值
- # MIN:最小值
- # AVG:平均值
- # SUM:求和
- # COUNT:计数
- # 查询每个职位最高的薪资
- select post,max(salary) from employee group by post;
- # 查询每个职位共有多少员工
- select post,count(id) from employee group by post;
小练习:
- 1. 查询岗位名以及岗位包含的所有员工名字
- 2. 查询岗位名以及各岗位内包含的员工个数
- 3. 查询公司内男员工和女员工的个数
- 4. 查询岗位名以及各岗位的平均薪资
- 5. 查询岗位名以及各岗位的最高薪资
- 6. 查询岗位名以及各岗位的最低薪资
- 7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
6、having过滤
- # HAVING与WHERE不一样的地方在于:
- #!!!执行优先级从高到低:where > group by > having
- #1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
- #2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
- # 查询各岗位内包含的员工个数小于4的岗位名、岗位内包含员工名字、个数
- select post,group_concat(name),count(id) from employee group by post having count(id) < 4;
小练习:
- # 1、查询各岗位平均薪资大于7800的岗位名、平均工资
- # 2、查询各岗位平均薪资大于8000且小于10000的岗位名、平均工资
7、查询排序 order by
- 按单列排序
- SELECT * FROM employee ORDER BY salary; # 默认为升序
- SELECT * FROM employee ORDER BY salary ASC; # 升序
- SELECT * FROM employee ORDER BY salary DESC; # 降序
- 按多列排序:先按照age排序,如果年纪相同,则按照薪资排序
- SELECT * from employee
- ORDER BY age,
- salary DESC;
小练习:
- 1. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序
- 2. 查询各岗位平均薪资大于7000的岗位名、平均工资,结果按平均薪资升序排列
- 3. 查询各岗位平均薪资大于7000的岗位名、平均工资,结果按平均薪资降序排列
8、限制查询的记录数 limit
- 示例:
- SELECT * FROM employee ORDER BY salary DESC LIMIT 3; #默认初始位置为0
- SELECT * FROM employee ORDER BY salary DESC
- LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
- SELECT * FROM employee ORDER BY salary DESC
- LIMIT 5,5; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
小练习:
- # 分页显示,每页5条
- select * from employee limit 0,5; # 1---5条记录
- select * from employee limit 5,5; # 6---10条记录
- select * from employee limit 10,5; # 11---15条记录
9、使用正则表达式查询
- SELECT * FROM employee WHERE name REGEXP '^任';
- SELECT * FROM employee WHERE name REGEXP '女$';
- 小结:对字符串匹配的方式
- WHERE name = '任盈盈';
- WHERE name LIKE '杨%';
- WHERE name REGEXP '女$';
小练习:
- 查看所有员工中名字是“杨”开头,“过”或者“康”结果的员工信息
02-再探MySQL数据库的更多相关文章
- 解决Linux系统下Mysql数据库中文显示成问号的问题
当我们将开发好的javaWEB项目部署到linux系统上,操作数据库的时候,会出现中文乱码问题,比如做插入操作,发现添加到数据库的数据中文出现论码,下面就将解决linux下mysql中文乱码问题! 打 ...
- Eclipse中利用JSP把mysql-connector-java-8.0.13.jar放到WebContent\WEB-INF\lib中连接MySQL数据库时Connection conn = DriverManager.getConnection(url,username,password)报错的解决办法
开发环境: 1.系统:windows 7/8/10均可 2.jdk:1.8.0_144 3.服务器:apache-tomcat-9.0.8 4.IDE:eclipse+jsp 0.网页代码如下: &l ...
- Emoji表情符号在MySQL数据库中的存储
文章转自https://www.jianshu.com/p/20740071d854 在Android手机或者iPhone的各种输入法键盘中,会自带一些Emoji表情符号,如IPhone手机系统键盘包 ...
- CentOS下MYSQL数据库的安装
关于在Centos系统下安装MYSQL数据库,网络上资料有很多,在此主要感谢该文章的博主:http://www.cnblogs.com/zhoulf/archive/2013/01/25/zhoulf ...
- Mysql学习总结(41)——MySql数据库基本语句再体会
1.数据定义语言(DDL):定义和管理数据对象,比如建立数据库.数据表 数据操作语言(DML):用于操作数据库对象中的包含的数据. 数据查询语言(DQL):用于查询数据库对象中包含的数据,能够对表进行 ...
- 配置mysql数据库时出再错误:LookupError: No installed app with label 'admin'.
版本: windows10+py37+django2.2 错误: 项目启动时出现,No installed app with label 'admin' 解决办法: 安装最新的 pip install ...
- 【再探backbone 02】集合-Collection
前言 昨天我们一起学习了backbone的model,我个人对backbone的熟悉程度提高了,但是也发现一个严重的问题!!! 我平时压根没有用到model这块的东西,事实上我只用到了view,所以昨 ...
- 爬虫再探之mysql简单使用
在爬取数据量比较大时,用EXCEL存取就不太方便了,这里简单介绍一下python操作mysql数据库的一些操作.本人也是借助别人的博客学习的这些,但是找不到原来博客链接了,就把自己的笔记写在这里,这里 ...
- MySQL数据库学习: 02 —— 数据库的安装与配置
MySQL安装图解 一.MYSQL的安装 1.打开下载的mysql安装文件mysql-5.0.27-win32.zip,双击解压缩,运行“setup. ...
随机推荐
- gogs git代码管理
Gogs 是一个基于 Go语言的开源的 Git 服务端.非常轻量,安装也很简单.官网https://gogs.io/docs/installation/install_from_binary 下载后解 ...
- 「译」图解 ArrayBuffers 和 SharedArrayBuffers
作者:Lin Clark 译者:Cody Chan 原帖链接:A cartoon intro to ArrayBuffers and SharedArrayBuffers 这是图解 SharedArr ...
- v-for 循环element-ui菜单
vue 使用了element-ui的菜单组件, 这个组件的el-menu-item项上,有一个属性index,值是字符串类型, 在使用v-for的index时,它是一个数值型,所以如果直接写index ...
- WD与地图 解题报告
WD与地图 哎,我好傻啊,看了题解还弄错了一遍,靠着lbw指点才董 题意:给一个带点权有向图,要求支持删边,查询一个scc前\(k\)大权值,修改点权,不强制在线. 显然倒序处理变成加边 考虑求出每条 ...
- <div>标签仿<textarea>。contentEditable=‘true’,赋予非表单标签内容可以编辑
需求:web页面需要一个文本输入框.1.该文本输入框默认状态下有个仿‘placeholder’的默认文本提示信息,2.文本框输入状态下其高度会随文本内容自动撑开. 方案选择:1.使用<texta ...
- 分布式锁与实现(一)——基于Redis实现 【比较靠谱】
转: 分布式锁与实现(一)——基于Redis实现 概述 目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题.分布式的CAP理论告诉我们“任何一个分布式系统 ...
- java的数组
作用:存储相同类型的一组数组,相当于一个容器,存放数据的.对同种数据类型集中存储.管理.便于遍历 数组类型:就是数组中存储的数据的类型 特点:数组中的所有元素必须属于相同的数据类型,数组中所有元素在内 ...
- jsp:include动作功能
jsp:plugin动作:连接客户端的Applet或Bean插件 jsp:useBean动作:应用javaBean组件 jsp:setProperty动作:设置javaBean属性 jsp:getPr ...
- windows下网络编程UDP
转载 C++ UDP客户端服务器Socket编程 UDPServer.cpp #include<winsock2.h>#include<stdio.h>#include< ...
- (二叉树 BFS) leetcode993. Cousins in Binary Tree
In a binary tree, the root node is at depth 0, and children of each depth knode are at depth k+1. Tw ...