深度学习与NLP简单应用
在深度学习中,文本分类的主要原型:Text label,坐边是输入端“X”,右边是输出端“Y”。行业baseline:用BoW(bag of words)表示sentences(如何将文本表达成一个数字的形式),然后用LR或者SVM做回归。
中英文做自然语言处理主要区别,中文需要分词(启发式Heuristic, 机器学习、统计方法HMM、CRF))
深度学习:从端到端的方式,以不掺和人为的计算,从X到Y暴力粗暴的学习。通过很隐层(包含大量线性和非线性的计算)试图模拟数据的内在结构。
新手推荐用kreas,它下面有两个底层,一个是theano,一个是tensorflow,可以自由转换backend也就是说可以让它跑在theano底下,也可以跑在tensorflow底下,它把其他几个深度学习框架综合起来成一种。
关于自然语言相关的库,gensim https://radimrehurek.com/gensim/
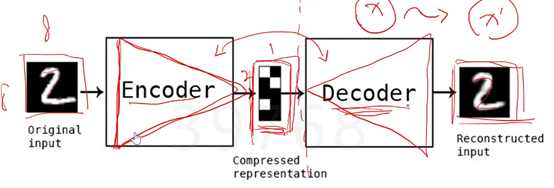
一、 Auto-Encoder自编码器
应用场景:无标签的时候需要使用;就算有标签的情况下一本书的内涵太多太大,你希望降维,使得其在后面模型处理中能够接受;
自编码是自己学习自己,通过encoder压缩成一个中继量,目的是希望这个中继量可以通过下一把完全反向的encoder,返回成原本的Input。这里面没有用到任何的label,而是照片2本身和照片2本身,中间加了两个对立漏斗形的神经网络。最后我们可以取中间那个更小的中继量代替原来的图片(因为它可以decoder回原来的图片)。
实现了不用人为提取特征向量。
只能达到局部最优点,无法达到全局最优点。
距离的计算,文本上常用列文斯坦距离,从A变B需要多少步。或者把整个文本表达为矩阵向量,词向量的距离可以用cosine距离等。
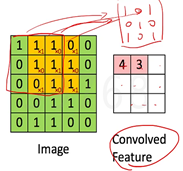
二、 CNN4Text(卷积+text)
卷积神经网络,用简单的例子解释,就是手机上的修图软件,拍的照片给个滤镜,照片是不是就长得不一样了,cnn就是用很多滤镜给我原始的图片,进行照耀,照完之后会得到在不同滤镜下的显示形式,这些显示形式也许就暗含这些图片的一些特征。 通过滤镜扫过之后得到新的featureMap我们称为convolved feature。滤镜是怎么得到的呢,是人为初始化一个滤镜,通过之后无数次的学习来更新这个滤镜值,使得这个滤镜值是最好的能提取出fetureMap的滤镜。(加号老师讲)右下图,左边是模糊,右边是边缘化。

如何迁移到文字处理?
1.把每个单词处理成一个横向的向量,就把句子拓展成了类似图片的表达式,
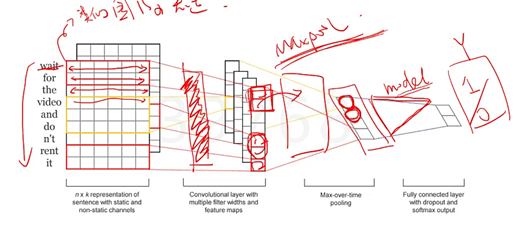
2.把sentence变成1维的,

案例

三、 RNN(带记忆)
Rnn的目的是让有sequential关系的信息得到考虑,St是基于这一个时间点的input和上一个时间点的记忆,然后St再乘以output weight V得到最终输出。
如果Rnn的长度不能记忆几天前的S的话,它的上下文处理能力还是为0,因为它还是不知道你的上下文前提是什么,因此需要LSTM。
四、 LSTM(带记忆)
通过各种运算符号和规则使得整个神经网络里面每个神经网络都能记得一点东西,又会及时的忘记一些东西,使得我记忆的距离能够变得够长。(RNN是一个叠加的过程,下一个永远基于上一个,就会变得非常大和慢)
长效记忆网络,把记忆长效的保留下来。

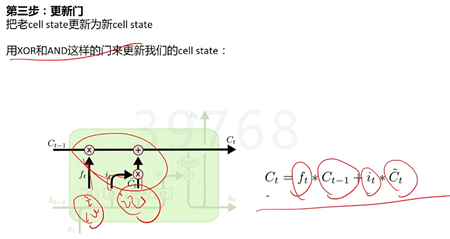
LSTM中最重要的就是Cell State(记忆纽带) S,它一路向下,贯穿整个时间线,代表了记忆的纽带。它会被XOR(遗忘层处理)和AND(记忆处理)运算符搞一搞来更新记忆,通过这两个运算来知道要记得什么和忘掉什么。

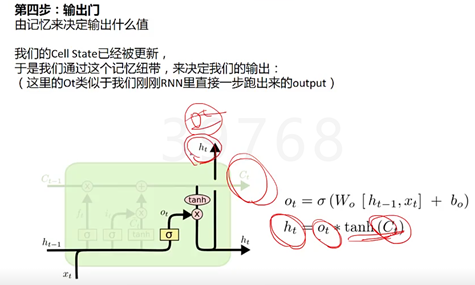
而控制信息的增加和减少的,就是靠这些阀门:Gate,阀门就是输出一个1和0之间的值,1代表把这一趟的信息记着,0代表这一趟的信息可以忘记了。有些记忆比较久的还需不需要留着。
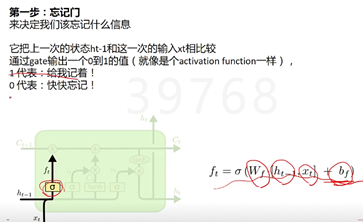
最后得到记忆纽带Ct
五、 案例
可以用在不同的维度上:
维度1:下一个字母是什么?
维度2:下一个单词是什么?
维度3:下一个句子是什么?
维度4:下一个图片、音符是什么?
LSTM案例
深度学习与NLP简单应用的更多相关文章
- 转载:深度学习在NLP中的应用
之前研究的CRF算法,在中文分词,词性标注,语义分析中应用非常广泛.但是分词技术只是NLP的一个基础部分,在人机对话,机器翻译中,深度学习将大显身手.这篇文章,将展示深度学习的强大之处,区别于之前用符 ...
- 回望2017,基于深度学习的NLP研究大盘点
回望2017,基于深度学习的NLP研究大盘点 雷锋网 百家号01-0110:31 雷锋网 AI 科技评论按:本文是一篇发布于 tryolabs 的文章,作者 Javier Couto 针对 2017 ...
- 斯坦福深度学习与nlp第四讲词窗口分类和神经网络
http://www.52nlp.cn/%E6%96%AF%E5%9D%A6%E7%A6%8F%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B8%8Enlp%E7%A ...
- 深度学习解决NLP问题:语义相似度计算
在NLP领域,语义相似度的计算一直是个难题:搜索场景下query和Doc的语义相似度.feeds场景下Doc和Doc的语义相似度.机器翻译场景下A句子和B句子的语义相似度等等.本文通过介绍DSSM.C ...
- Sony深度学习框架 - Neural Network Console - 教程(1)- 原来深度学习可以如此简单
“什么情况!?居然不是黑色背景+白色文字的命令行.对,今天要介绍的是一个拥有白嫩的用户界面的深度学习框架.” 人工智能.神经网络.深度学习,这些概念近年已经涌入每个人的生活中,我想很多人早就按捺不住想 ...
- 深度学习之NLP维基百科数据模型
知识点 """ 1) from gensim.model import Word2Vec import jieba 2) opencc :将繁体字转换为简体字 转换命令: ...
- 关于深度学习之TensorFlow简单实例
1.对TensorFlow的基本操作 import tensorflow as tf import os os.environ[" a=tf.constant(2) b=tf.constan ...
- NLP 第10章 基于深度学习的NLP 算法
- DSSM 深度学习解决 NLP 问题:语义相似度计算
https://cloud.tencent.com/developer/article/1005600
随机推荐
- angularjs html 转义
angularjs html 转义 默认情况下,AngularJS对会对插值指令求职表达式(模型)中的任何HTML标记都进行转义,例如以下模型: $scope.msg = “hello,<b&g ...
- 【spring源码分析】IOC容器初始化(八)
前言:在上文bean加载过程中还要一个非常重要的方法没有分析createBean,该方法非常重要,因此特意提出来单独分析. createBean方法定义在AbstractBeanFactory中: 该 ...
- jenkins自动化部署vue
一.nodejs配置 首先加入nodejs插件 在配置里面配置这个插件 这样我们就能在自动构建发布的配置里看到nodejs的编译选项了 二.发布配置 首先新建一个自由风格的项目 然后配置构建保留天数和 ...
- 分析dhcp.lease文件,统计DHCP服务器IP自动分配
#!/usr/bin/env python # coding=utf-8 import string import time,datetime class TIMEFORMAT: def __init ...
- Springcloud zuul和shiro结合
一.目标1.外部请求统一从网关zuul进入,并且服务内部互相调用接口要校验权限 2.cloud和shiro结合,达到单点登录,和集中一个服务完成权限管理,其他业务服务不需要关注权限如何实现 3.其他服 ...
- Fedora中安装VMtools步骤
第一次玩Fedora的系统,通过VMware工具安装的一个虚拟机,由于公司要求尽可能的留有足够空间,所以安装的时候就没选开发环境选项.安装成功后,又要准备安装VMware--tools工具,在此记录安 ...
- 【keras】用tensorboard监视CNN每一层的输出
from keras.models import Sequential from keras.layers import Dense, Dropout from keras.layers import ...
- .netcore2.0发送邮件
SmtpClient smtpClient = new SmtpClient(); smtpClient.DeliveryMethod = SmtpDeliveryMethod.Network;//指 ...
- 将root 当成arraylist放入数据sturts2 入门笔记
刚启动idea 就报出错误 [-- ::,] Artifact -sturts2:war exploded: Error during artifact deployment. See server ...
- 2019-04-10 集成JasperReport
1. 报表的制作过程为 ① 制作.jrxml报表模板文件,并编译成.jasper ② 代码处理.jasper文件并填充数据进行输出 2. 一开始是打算使用iReport作为模板制作工具的,但是有以下局 ...