召回率(Recall),精确率(Precision),平均正确率
https://blog.csdn.net/yanhx1204/article/details/81017134
摘要
在训练YOLO v2的过程中,系统会显示出一些评价训练效果的值,如Recall,IoU等等。为了怕以后忘了,现在把自己对这几种度量方式的理解记录一下。
这一文章首先假设一个测试集,然后围绕这一测试集来介绍这几种度量方式的计算方法。
大雁与飞机
假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,如下图所示:

假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
现在做如下的定义:
True positives : 飞机的图片被正确的识别成了飞机。
True negatives: 大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives: 大雁的图片被错误地识别成了飞机。
False negatives: 飞机的图片没有被识别出来,系统错误地认为它们是大雁。
假设你的分类系统使用了上述假设识别出了四个结果,如下图所示:
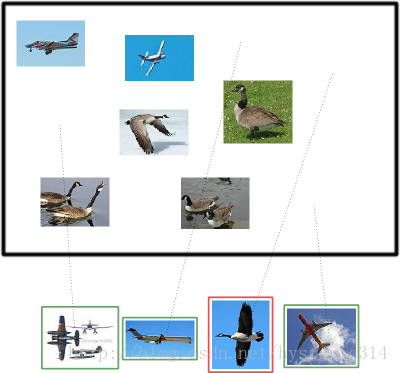
那么在识别出的这四张照片中:
True positives : 有三个,画绿色框的飞机。
False positives: 有一个,画红色框的大雁。
没被识别出来的六张图片中:
True negatives : 有四个,这四个大雁的图片,系统正确地没有把它们识别成飞机。
False negatives: 有两个,两个飞机没有被识别出来,系统错误地认为它们是大雁。
Precision
与 Recall
Precision其实就是在识别出来的图片中,True positives所占的比率:
其中的n代表的是(True positives + False positives),也就是系统一共识别出来多少照片 。
在这一例子中,True positives为3,False positives为1,所以Precision值是 3/(3+1)=0.75。
意味着在识别出的结果中,飞机的图片占75%。
Recall 是被正确识别出来的飞机个数与测试集中所有飞机的个数的比值:
Recall的分母是(True positives + False
negatives),这两个值的和,可以理解为一共有多少张飞机的照片。
在这一例子中,True positives为3,False negatives为2,那么Recall值是 3/(3+2)=0.6。
意味着在所有的飞机图片中,60%的飞机被正确的识别成飞机.。
调整阈值
你也可以通过调整阈值,来选择让系统识别出多少图片,进而改变Precision 或 Recall 的值。
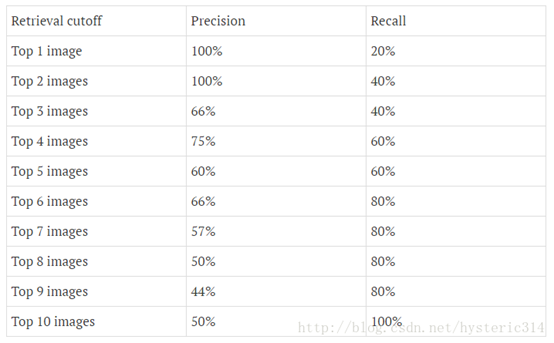
在某种阈值的前提下(蓝色虚线),系统识别出了四张图片,如下图中所示:

分类系统认为大于阈值(蓝色虚线之上)的四个图片更像飞机。
我们可以通过改变阈值(也可以看作上下移动蓝色的虚线),来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与Recall值发生变化。比如,把蓝色虚线放到第一张图片下面,也就是说让系统只识别出最上面的那张飞机图片,那么Precision的值就是100%,而Recall的值则是20%。如果把蓝色虚线放到第二张图片下面,也就是说让系统只识别出最上面的前两张图片,那么Precision的值还是100%,而Recall的值则增长到是40%。
下图为不同阈值条件下,Precision与Recall的变化情况:
Precision-recall
曲线
如果你想评估一个分类器的性能,一个比较好的方法就是:观察当阈值变化时,Precision与Recall值的变化情况。如果一个分类器的性能比较好,那么它应该有如下的表现:被识别出的图片中飞机所占的比重比较大,并且在识别出大雁之前,尽可能多地正确识别出飞机,也就是让Recall值增长的同时保持Precision的值在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
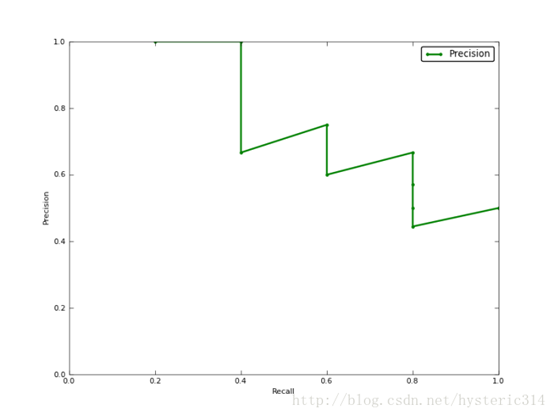
上图就是分类器的Precision-recall 曲线,在不损失精度的条件下它能达到40%Recall。而当Recall达到100%时,Precision 降低到50%。
Approximated
Average precision
相比较与曲线图,在某些时候还是一个具体的数值能更直观地表现出分类器的性能。通常情况下都是用 Average
Precision来作为这一度量标准,它的公式为:
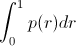
在这一积分中,其中p代表Precision ,r代表Recall,p是一个以r为参数的函数,That is equal to taking
the area under the curve.
实际上这一积分极其接近于这一数值:对每一种阈值分别求(Precision值)乘以(Recall值的变化情况),再把所有阈值下求得的乘积值进行累加。公式如下:
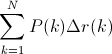
在这一公式中,N代表测试集中所有图片的个数,P(k)表示在能识别出k个图片的时候Precision的值,而 Delta r(k) 则表示识别图片个数从k-1变化到k时(通过调整阈值)Recall值的变化情况。
在这一例子中,Approximated
Average Precision的值
=(1 * (0.2-0)) + (1 * (0.4-0.2)) + (0.66 * (0.4-0.4)) + (0.75 * (0.6-0.4)) +
(0.6 * (0.6-0.6)) + (0.66 * (0.8-0.6)) + (0.57 * (0.8-0.8)) + (0.5 * (0.8-0.8))
+ (0.44 * (0.8-0.8)) + (0.5 * (1-0.8)) = 0.782.
=(1 * 0.2) + (1 * 0.2) + (0.66 * 0) + (0.75 * 0.2) + (0.6 * 0) + (0.66 *
0.2) + (0.57 * 0) + (0.5 * 0) + (0.44 * 0) + (0.5 * 0.2)
= 0.782.
通过计算可以看到,那些Recall值没有变化的地方(红色数值),对增加Average Precision值没有贡献。
Interpolated
average precision
不同于Approximated
Average Precision,一些作者选择另一种度量性能的标准:Interpolated
Average Precision。这一新的算法不再使用P(k),也就是说,不再使用当系统识别出k个图片的时候Precision的值与Recall变化值相乘。而是使用
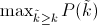
也就是每次使用在所有阈值的Precision中,最大值的那个Precision值与Recall的变化值相乘。公式如下:
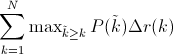
下图的图片是Approximated
Average Precision 与 Interpolated Average
Precision相比较。
需要注意的是,为了让特征更明显,图片中使用的参数与上面所说的例子无关。
很明显 Approximated Average
Precision与精度曲线挨的很近,而使用Interpolated
Average Precision算出的Average Precision值明显要比Approximated Average Precision的方法算出的要高。
一些很重要的文章都是用Interpolated
Average Precision 作为度量方法,并且直接称算出的值为Average
Precision 。PASCAL Visual Objects
Challenge从2007年开始就是用这一度量制度,他们认为这一方法能有效地减少Precision-recall 曲线中的抖动。所以在比较文章中Average Precision 值的时候,最好先弄清楚它们使用的是那种度量方式。
IoU
IoU这一值,可以理解为系统预测出来的框与原来图片中标记的框的重合程度。
计算方法即检测结果Detection Result与 Ground Truth 的交集比上它们的并集,即为检测的准确率:
如下图所示:
蓝色的框是:GroundTruth
黄色的框是:DetectionResult
绿色的框是:DetectionResult ⋂ GroundTruth
红色的框是:DetectionResult ⋃ GroundTruth
要说的
1,本文参考了以下博客
https://sanchom.wordpress.com/tag/average-precision/
http://blog.csdn.net/eddy_zheng/article/details/52126641
2,在训练YOLO v2中,会出现这几个参数,所以在这总结一下,省得以后忘了。
3,本文只是一个学习笔记,内容可能会有错误,仅供参考。
4,如果你发现文中的错误,欢迎留言指正,谢谢!
5,之后会继续把训练YOLO过程中出现的问题写在博客上。
最近一直在做相关推荐方面的研究与应用工作,召回率与准确率这两个概念偶尔会遇到,知道意思,但是有时候要很清晰地向同学介绍则有点转不过弯来。
召回率和准确率是数据挖掘中预测、互联网中的搜索引擎等经常涉及的两个概念和指标。
召回率:Recall,又称“查全率”——还是查全率好记,也更能体现其实质意义。
准确率:Precision,又称“精度”、“正确率”。
以检索为例,可以把搜索情况用下图表示:
如果我们希望:被检索到的内容越多越好,这是追求“查全率”,即A/(A+C),越大越好。
如果我们希望:检索到的文档中,真正想要的、也就是相关的越多越好,不相关的越少越好,这是追求“准确率”,即A/(A+B),越大越好。
“召回率”与“准确率”虽然没有必然的关系(从上面公式中可以看到),在实际应用中,是相互制约的。要根据实际需求,找到一个平衡点。
往往难以迅速反应的是“召回率”。我想这与字面意思也有关系,从“召回”的字面意思不能直接看到其意义。“召回”在中文的意思是:把xx调回来。“召回率”对应的英文“recall”,recall除了有上面说到的“order sth to return”的意思之外,还有“remember”的意思。
Recall:the ability to remember sth. that you have
learned or sth. that has happened in the past.
当我们问检索系统某一件事的所有细节时(输入检索query查询词),Recall指:检索系统能“回忆”起那些事的多少细节,通俗来讲就是“回忆的能力”。“能回忆起来的细节数” 除以 “系统知道这件事的所有细节”,就是“记忆率”,也就是recall——召回率。简单的,也可以理解为查全率。
不妨举这样一个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2
/ (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) =
70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2
/ (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
召回率(Recall),精确率(Precision),平均正确率的更多相关文章
- 召回率,精确率,mAP如何计算
首先用训练好的模型得到所有测试样本的confidence score,每一类(如car)的confidence score保存到一个文件中(如comp1_cls_test_car.txt).假设 ...
- Recall(召回率)and Precision(精确率)
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7668501.html 前言 机器学习中经过听到" ...
- 分类的性能评估:准确率、精确率、Recall召回率、F1、F2
import numpy as np import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer f ...
- 准确率、精确率、召回率、F1
在搭建一个AI模型或者是机器学习模型的时候怎么去评估模型,比如我们前期讲的利用朴素贝叶斯算法做的垃圾邮件分类算法,我们如何取评估它.我们需要一套完整的评估方法对我们的模型进行正确的评估,如果模型效果比 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure(对于二分类问题)
首先我们可以计算准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比.也就是损失函数是0-1损失时测试数据集上的准确率. 下面在介绍时使用一下例子: 一个 ...
- (转载)准确率(accuracy),精确率(Precision),召回率(Recall)和综合评价指标(F1-Measure )-绝对让你完全搞懂这些概念
自然语言处理(ML),机器学习(NLP),信息检索(IR)等领域,评估(evaluation)是一个必要的工作,而其评价指标往往有如下几点:准确率(accuracy),精确率(Precision),召 ...
- 准确率(accuracy),精确率(Precision),召回率(Recall)和综合评价指标(F1-Measure )----转
原文:http://blog.csdn.net/t710smgtwoshima/article/details/8215037 Recall(召回率);Precision(准确率);F1-Meat ...
- 机器学习常见的几种评价指标:精确率(Precision)、召回率(Recall)、F值(F-measure)、ROC曲线、AUC、准确率(Accuracy)
原文链接:https://blog.csdn.net/weixin_42518879/article/details/83959319 主要内容:机器学习中常见的几种评价指标,它们各自的含义和计算(注 ...
- 准确率(Accuracy) 精确率(Precision) 与 召回率(Recall)
准确率(Accuracy)—— 针对整个模型 精确率(Precision) 灵敏度(Sensitivity):就是召回率(Recall) 参考:https://blog.csdn.net/Orange ...
随机推荐
- vCenter Server 6 Standard
准备环境和工具: 三台 ESXi 6.0主机: 准备一台Windows Server 2008 R2系统的虚拟机: VMware-VIM-all-6.0.0.iso 软件下载地址 链接: https: ...
- 002_soa_zk处理经验总结
一. 遇到这种情况直接把当前目录下的acceptedEpoch和currentEpoch挪走,重启publisher即可. cat /data/zookeeper/data/version-2/acc ...
- Lnmp下pureftpd新建FTP账户权限不足解决方法
解决办法: 登录服务器.执行以下命令 chattr -i /home/wwwroot/default/.user.ini chown www:www -R /home/wwwroot/你的lnmp安 ...
- innodb表碎片处理
本次测试环境是 mysql 5.7.23,表空间为每个表单独表空间 mysql> sHOW VARIABLES LIKE 'innodb_file_per_tabl%'; +---------- ...
- Bootstrap modal常用参数、方法和事件
Bootstrap modal(模态窗)常用参数.方法和事件: 参数: 名称 类型 默认值 描述 Backdrop Boolean或字符串“static” True True:有背景,点击modal外 ...
- SpringBoot图片上传(四) 一个input上传N张图,支持各种类型
简单介绍:需求上让实现,图片上传,并且可以一次上传9张图,图片格式还有要求,网上找了一个测试了下,好用,不过也得改,仅仅是实现了功能,其他不尽合理的地方,还需自己打磨. 代码: //html<d ...
- python实现简单的登录管理
import json,timeusername=[]userpasswd=[]def login_success_file(name): try: f=open(r"F:/login_su ...
- [原创]基于Zynq Linux环境搭建(一)
安装VMWare版本12 Ubuntu版本 12.04.5 64bit 系统安装完成后,登陆系统,在sotfware中心安装konsole.gvim.software source等基本软件 在sof ...
- Python调用selenium
import time from selenium import webdriver from selenium.webdriver.common.touch_actions import Touch ...
- Yii2中mongodb使用ActiveRecord的数据操作
概况 Yii2 一个高效安全的高性能PHP框架.mongodb 一个高性能分布式文档存储NOSQL数据库. 关于mongodb与mysql的优缺点,应该都了解过. mysql传统关系数据库,安全稳定 ...