python爬虫知识点总结(二)爬虫的基本原理
一、什么是爬虫?
答:请求网页并提取数据的自动化程序。
二、爬虫的基本流程
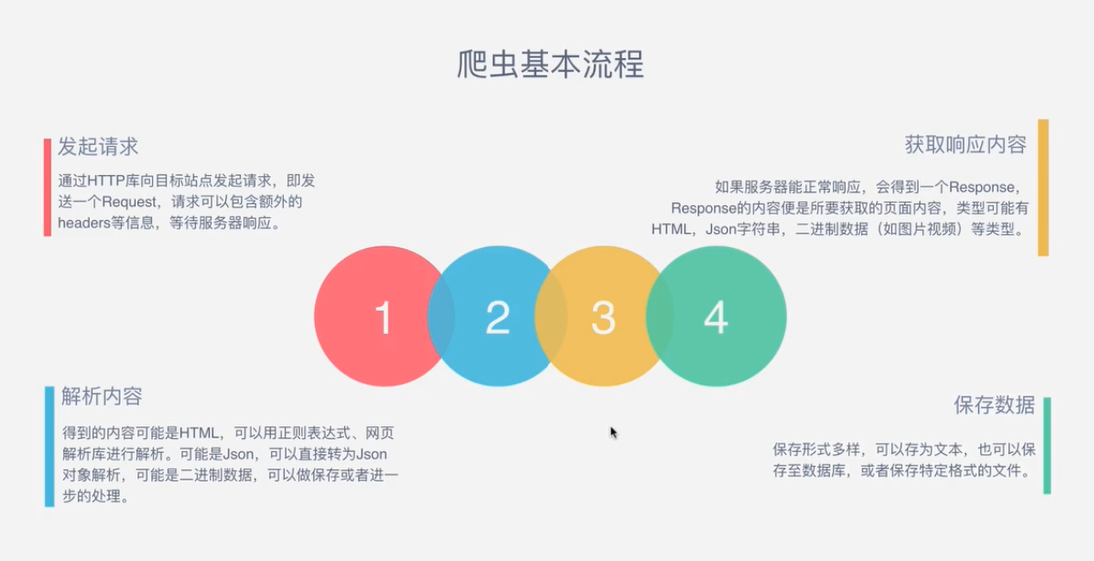
三、什么是Request和Response?

1、Request

2、Response

四、能抓取怎样的数据

五、解析方式

六、怎么解决JavaScript渲染的问题?

七、怎么保存数据?

测试代码:
import requests
response = requests.get('http://www.baidu.com')
print(response.text)
print(response.headers)
print(response.status_code) headers = {'User-Agent':' Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Mobile Safari/537.36}
response = requests.get('http://www.baidu.com',headers=headers)
print(response.status_code) response = requests.get('https://gss0.bdstatic.com/5bd1bjqh_Q23odCf/static/newtab/img/fetch_ing_8_0.png')
print(response.content) with open('/var/tmp/1.png','wb') //写到本地的文件
fwrite(response.content)
f.close()
python爬虫知识点总结(二)爬虫的基本原理的更多相关文章
- Python爬虫学习二------爬虫基本原理
爬虫是什么?爬虫其实就是获取网页的内容经过解析来获得有用数据并将数据存储到数据库中的程序. 基本步骤: 1.获取网页的内容,通过构造请求给服务器端,让服务器端认为是真正的浏览器在请求,于是返回响应.p ...
- python爬虫知识点详解
python爬虫知识点总结(一)库的安装 python爬虫知识点总结(二)爬虫的基本原理 python爬虫知识点总结(三)urllib库详解 python爬虫知识点总结(四)Requests库的基本使 ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- Python爬虫初学(二)—— 爬百度贴吧
Python爬虫初学(二)-- 爬百度贴吧 昨天初步接触了爬虫,实现了爬取网络段子并逐条阅读等功能,详见Python爬虫初学(一). 今天准备对百度贴吧下手了,嘿嘿.依然是跟着这个博客学习的,这次仿照 ...
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- Python 爬虫3——第一个爬虫脚本的创建
在进行真正的爬虫工程创建之前,我们先要明确我们所要操作的对象是什么?完成所有操作之后要获取到的数据或信息是什么? 首先是第一个问题:操作对象,爬虫全称是网络爬虫,顾名思义,它所操作的对象当然就是网页, ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- 月薪45K的Python爬虫工程师告诉你爬虫应该怎么学,太详细了!
想用Python做爬虫,而你却还不会Python的话,那么这些入门基础知识必不可少.很多小伙伴,特别是在学校的学生,接触到爬虫之后就感觉这个好厉害的样子,我要学.但是却完全不知道从何开始,很迷茫,学的 ...
- Python 网络爬虫 001 (科普) 网络爬虫简介
Python 网络爬虫 001 (科普) 网络爬虫简介 1. 网络爬虫是干什么的 我举几个生活中的例子: 例子一: 我平时会将 学到的知识 和 积累的经验 写成博客发送到CSDN博客网站上,那么对于我 ...
随机推荐
- java mysql自定义函数UDF之调用c函数
正如sqlite可以定义自定义函数,它是通过API定义c函数的,不像其他,如这里的mysql.sqlite提供原生接口就可以方便的调用其他语言的方法,同样的mysql也支持调用其它语言的方法. goo ...
- android 怎样加速./mk snod打包
mm命令高速编译一个模块之后,一般用adb push到手机看效果,假设环境不同意用adb push或模块不常常改.希望直接放到image里,则能够用./mk snod,这个命令只将system文件夹打 ...
- java中异或加密
static String simple_xor(String base_data, String encrypt_key) throws UnsupportedEncodingException { ...
- coreos 安装
一.挂载coreos 镜像 引导live-cd 配置初始化coreos 系统 网卡和密码 进入live版系统后呈现这个状态 #任意编辑一个.network 文件,文件名随意,该文件不存在需自己创建 s ...
- Unix环境高级编程—进程控制(三)
一.解释器文件 解释器文件属于文本文件,起始行形式为: #! pathname[optional-argument] 我们创建一个只有一行的文件如下: #!/home/webber/test/echo ...
- Linuxt图形界面安装
通常安装图形界面需要安装Xorg.桌面环境(Gnome.KDE.xfce等).字体等.你的Linux是什么版本?具体要看你的linux来决定用什么命令来安装. #yum grouplist 自己看看列 ...
- python _、__和__xx__的区别(转)
本位转载自:http://www.cnblogs.com/coder2012/p/4423356.html "_"单下划线 Python中不存在真正的私有方法.为了实现类似于c++ ...
- 使用Scrapy采集
1.有些站点通过robot协议,防止scrapy爬取,就会出现如下问题: DEBUG: Forbidden by robots.txt: <GET http://baike.baidu.com/ ...
- js闭包实际用途
闭包例:防止双击 在线商店的购物车里,为防止“多重购买”,需要防止按钮被双击. 下面用“jQuery + 闭包”来实现这一功能. HTML <form name="frm" ...
- 九度OJ 1011:最大连续子序列 (DP)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:5615 解决:2668 题目描述: 给定K个整数的序列{ N1, N2, ..., NK },其任意连续子序列可表示为{ Ni, N ...