Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了。现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中。需求有了,剩下的就是实现了。
在开始之前,保证已经安装好了MySQL并需要启动本地MySQL数据库服务。提到安装MySQL数据库,前两天在一台电脑上安装MySQL5.7时,死活装不上,总是提示缺少Visual Studio 2013 Redistributable,但是很疑惑,明明已经安装了呀,原来问题出在版本上,更换一个版本后就可以了。小问题大苦恼,不知道有没有人像我一样悲催。
言归正传,启动本地数据库服务:
用管理员身份打开“命令提示符(管理员)”,然后输入“net start mysql57”(我把数据库服务名定义为mysql57了,安装MySQL时可以修改)就可以开启服务了。注意使用管理员身份打开小黑框,如果不是管理员身份,我这里会提示没有权限,大家可以试试。
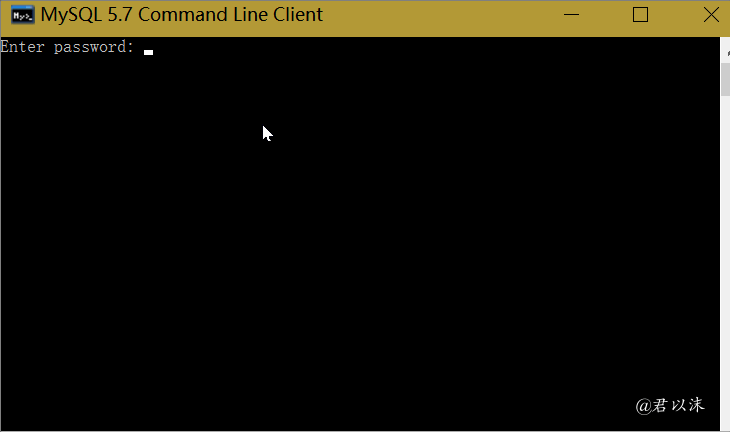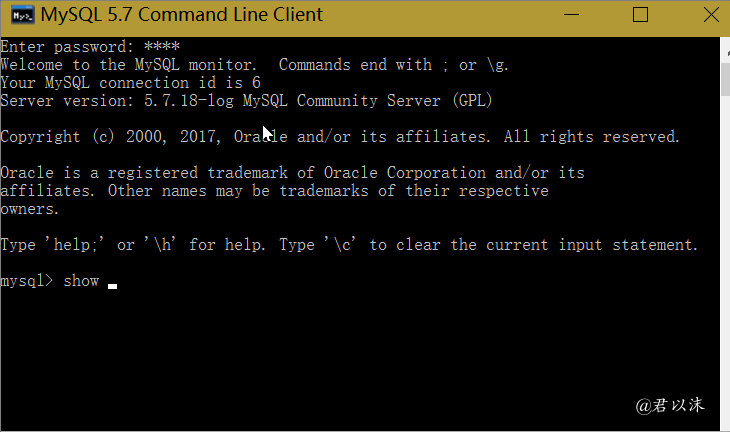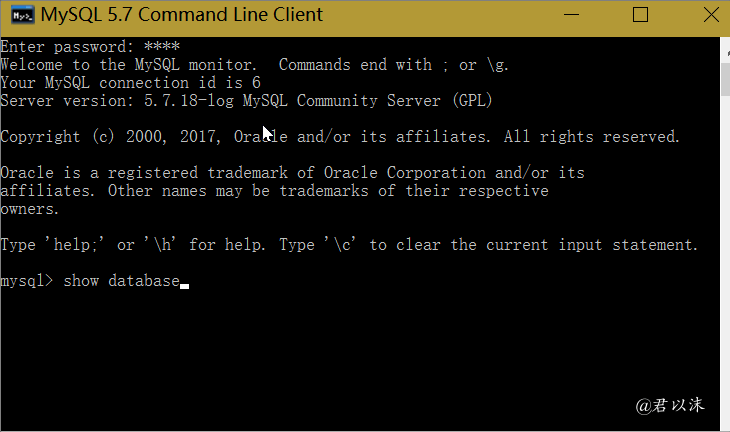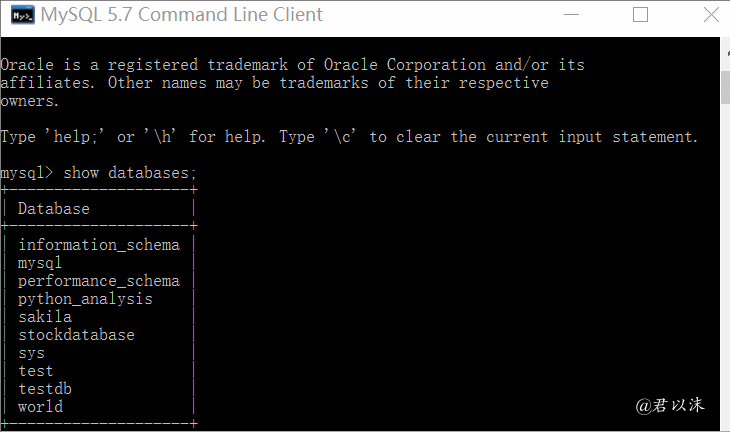
启动服务之后,我们可以选择打开“MySQL 5.7 Command Line Client”小黑框,需要先输入你的数据库的密码,安装的时候定义过,在这里可以进行数据库操作。
下面开始上正餐。
一、Python爬虫抓取网页数据并保存到本地数据文件中
首先导入需要的数据模块,定义函数:
#导入需要使用到的模块
import urllib
import re
import pandas as pd
import pymysql
import os #爬虫抓取网页函数
def getHtml(url):
html = urllib.request.urlopen(url).read()
html = html.decode('gbk')
return html #抓取网页股票代码函数
def getStackCode(html):
s = r'<li><a target="_blank" href="http://quote.eastmoney.com/\S\S(.*?).html">'
pat = re.compile(s)
code = pat.findall(html)
return code
真正干活的代码块:
Url = 'http://quote.eastmoney.com/stocklist.html'#东方财富网股票数据连接地址
filepath = 'D:\\data\\'#定义数据文件保存路径
#实施抓取
code = getStackCode(getHtml(Url))
#获取所有股票代码(以6开头的,应该是沪市数据)集合
CodeList = []
for item in code:
if item[0]=='':
CodeList.append(item)
#抓取数据并保存到本地csv文件
for code in CodeList:
print('正在获取股票%s数据'%code)
url = 'http://quotes.money.163.com/service/chddata.html?code=0'+code+\
'&end=20161231&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
urllib.request.urlretrieve(url, filepath+code+'.csv')
以上代码实现了爬虫网页抓取股票数据,并保存到本地文件中。关于爬虫的东西,有很多资料可以参考,大都是一个套路,不再多说。同时,本文实现过程中也参考了很多的网页资源,在此对所有原创者表示感谢!
先看下抓取的结果。CodeList是抓取到的所有股票代码的集合,我们看到它共包含1416条元素,即1416支股票数据。因为股票太多,所以抓取的是以6开头的,貌似是沪市股票数据(原谅我不懂金融)。
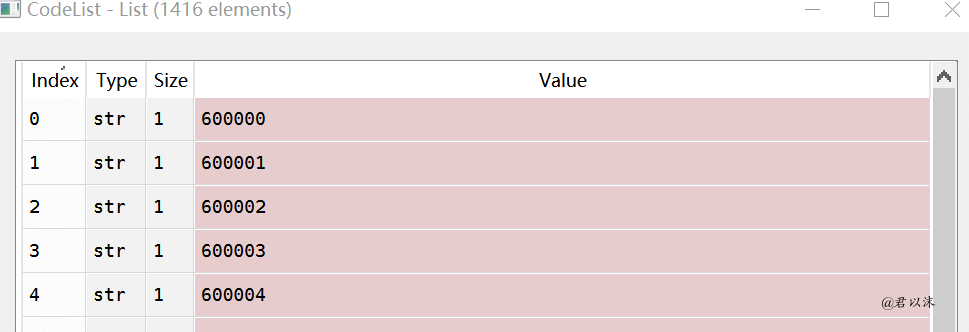
抓取到的股票数据会分别存储到csv文件中,一只股票数据一个文件。理论上会有1416个csv文件,和股票代码数一致。但原谅我的渣网速,下载一个都费劲,也是呵呵了。
打开一个本地数据文件看一下抓取的数据长什么样子:
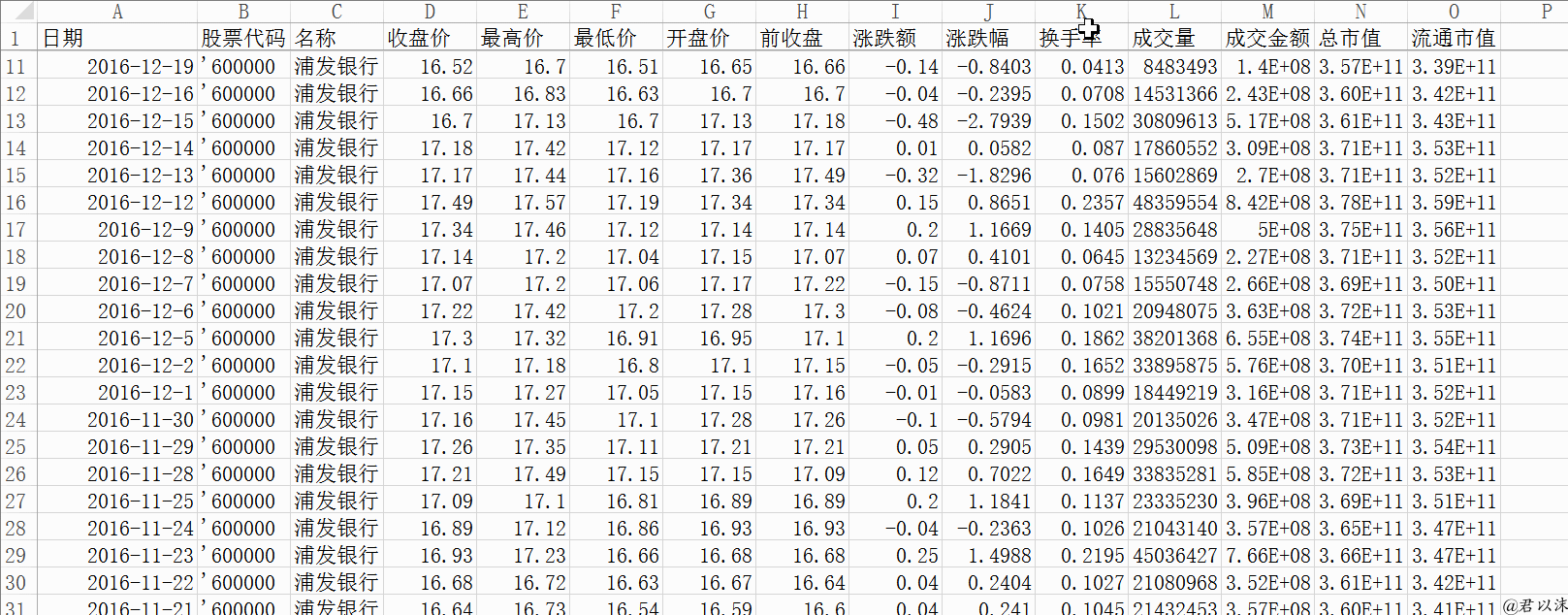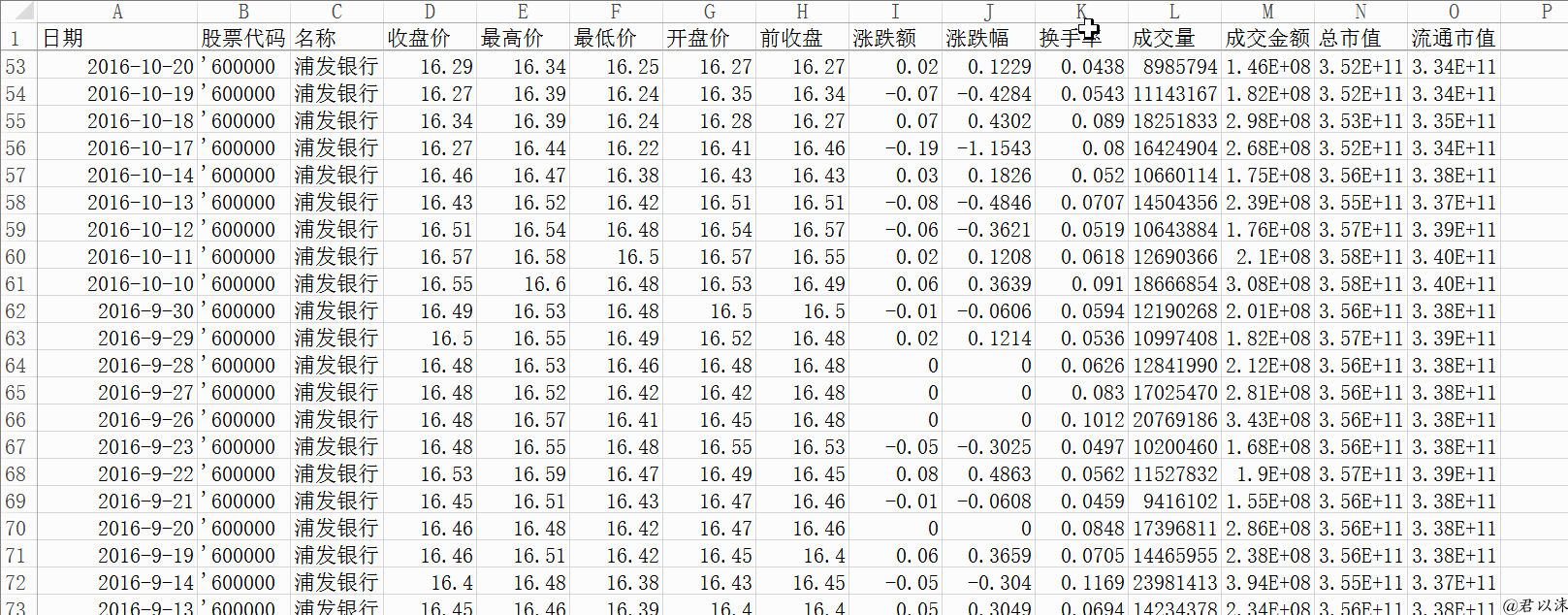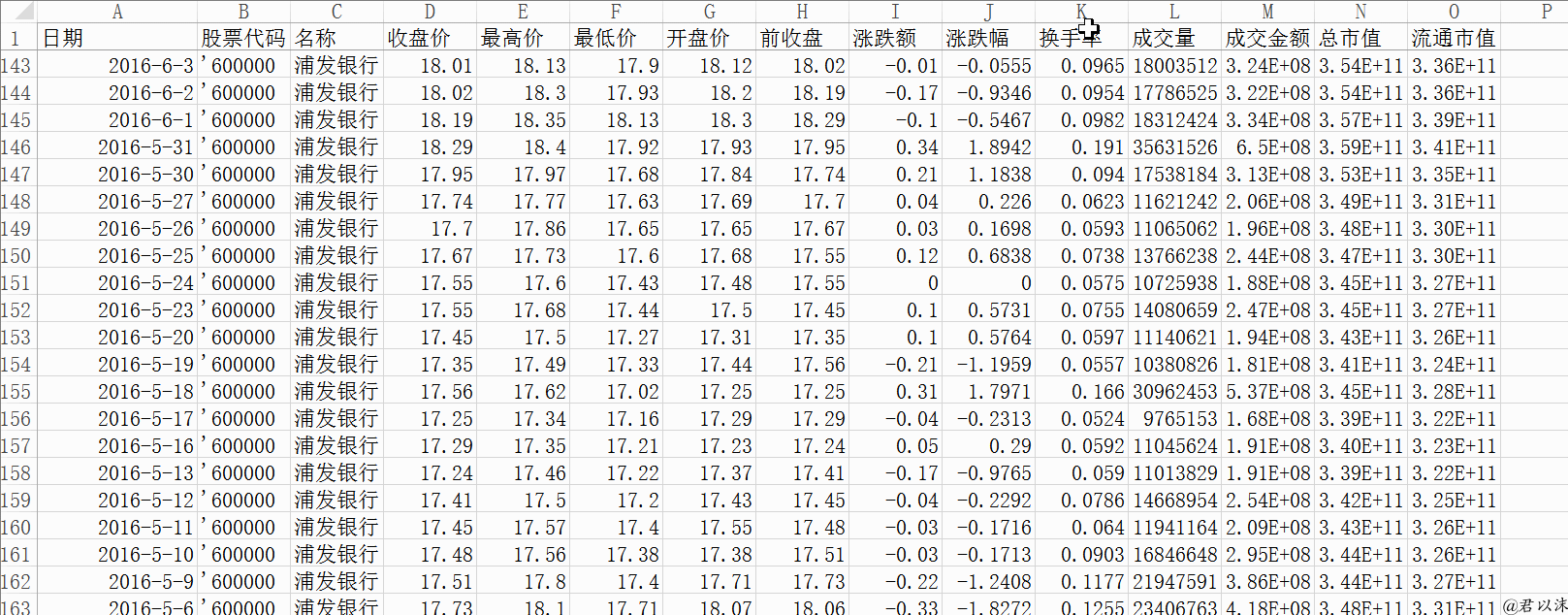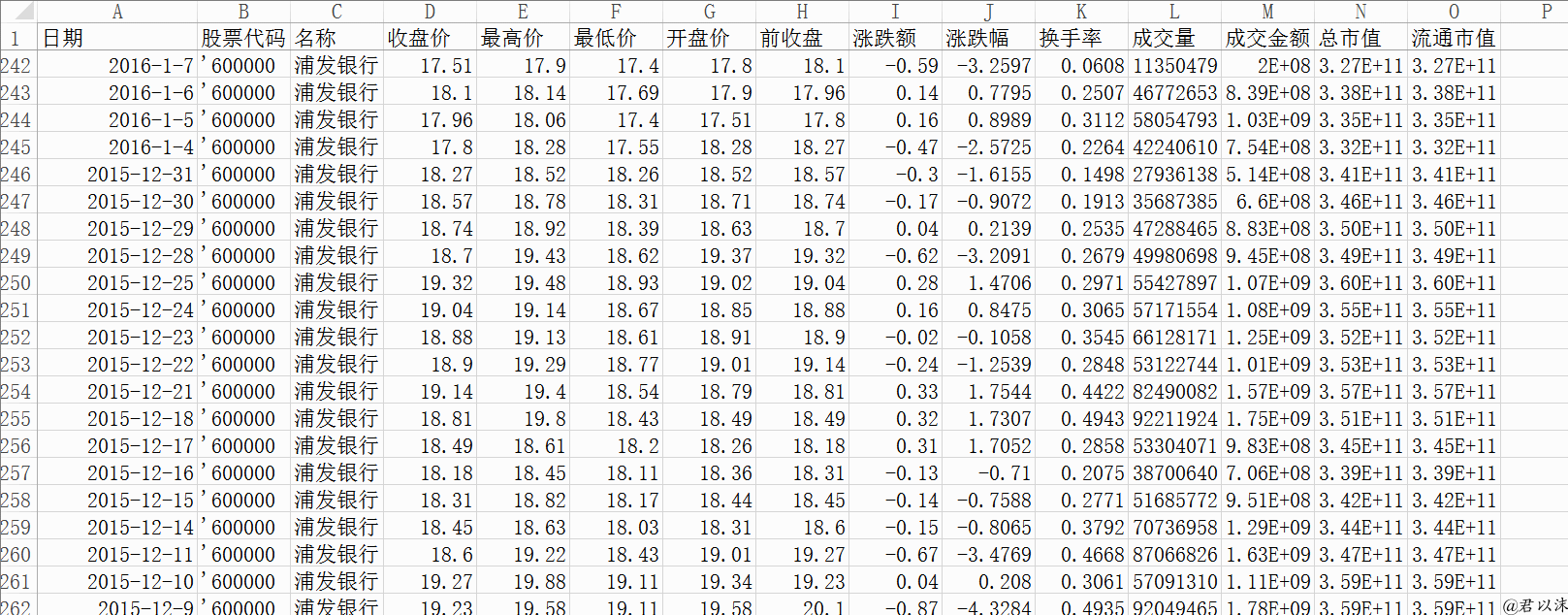
其实和人工手动下载也没什么区别了,硬要说区别,那就是解放了劳动力,提高了生产力(怎么听起来像政治?)。
二、将数据存储到MySQL数据库
首先建立本地数据库连接:
#数据库名称和密码
name = 'xxxx'
password = 'xxxx' #替换为自己的用户名和密码
#建立本地数据库连接(需要先开启数据库服务)
db = pymysql.connect('localhost', name, password, charset='utf8')
cursor = db.cursor()
其中,数据库名称(name)和密码(password)是安装MySQL时设置的。
创建数据库,专门用来存储本次股票数据:
#创建数据库stockDataBase,如果存在则跳过
sqlSentence1 = "create database if not exists stockDataBase"
cursor.execute(sqlSentence1)#选择使用当前数据库
sqlSentence2 = "use stockDataBase;"
cursor.execute(sqlSentence2)
在首次运行的时候一般都会正常创建数据库,但如果再次运行,因数据库已经存在,那么跳过创建,继续往下执行。创建好数据库后,选择使用刚刚创建的数据库,在该数据库中存储数据表。
下面看具体的存储代码:
#获取本地文件列
fileList = os.listdir(filepath)
#依次对每个数据文件进行存储
for fileName in fileList:
data = pd.read_csv(filepath+fileName, encoding="gbk")
#创建数据表,如果数据表已经存在,会跳过继续执行下面的步骤print('创建数据表stock_%s'% fileName[0:6])
sqlSentence3 = "create table if not exists stock_%s" % fileName[0:6] + "(日期 date, 股票代码 VARCHAR(10), 名称 VARCHAR(10), 收盘价 float,\
最高价 float, 最低价 float, 开盘价 float, 前收盘 float, 涨跌额 float, 涨跌幅 float, 换手率 float,\
成交量 bigint, 成交金额 bigint, 总市值 bigint, 流通市值 bigint)"
cursor.execute(sqlSentence3)#迭代读取表中每行数据,依次存储(整表存储还没尝试过)
print('正在存储stock_%s'% fileName[0:6])
length = len(data)
for i in range(0, length):
record = tuple(data.loc[i])
#插入数据语句
try:
sqlSentence4 = "insert into stock_%s" % fileName[0:6] + "(日期, 股票代码, 名称, 收盘价, 最高价, 最低价, 开盘价,\
前收盘, 涨跌额, 涨跌幅, 换手率, 成交量, 成交金额, 总市值, 流通市值) \
values ('%s',%s','%s',%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" % record
#获取的表中数据很乱,包含缺失值、Nnone、none等,插入数据库需要处理成空值
sqlSentence4 = sqlSentence4.replace('nan','null').replace('None','null').replace('none','null')
cursor.execute(sqlSentence4)
except:#如果以上插入过程出错,跳过这条数据记录,继续往下进行
break
代码并不复杂,只要注意其中几个点就好了。
1.逻辑层次:
包含两层循环,外层循环是对股票代码的循环,内层循环是对当前股票的每一条记录的循环。说白了就是按照股票一支一支的存储,对于每一支股票,按照它每日的记录一条一条的存储。是不是很简单很暴力?是的!完全没有考虑更加优化的方式。
2.读取本地数据文件的编码方式:
使用'gbk'编码,默认应该是'utf8',但好像不支持中文。
3.创建数据表:
同样的,如果数据表已经存在(判断是否存在if not exists),则跳过创建,继续执行下面的步骤(会继续存储)。有个问题是,有可能数据重复存储,可以选择跳过存储或者只存储最新数据。我在这里没有考虑太多额外的处理。其次,指定字段格式,后边几个字段成交量、成交金额、总市值、流通市值,因为数据较大,选择使用bigint类型。
4.没有指定数据表的主键:
最初是打算使用日期作为主键的,后来发现获取到的数据中竟然包含重复日期的数据,这就打破了主键的唯一性,会出bug的,然后我也没有多去思考数据文件的内容,也不会进一步使用这些个数据,也就图省事直接不设置主键了。
5.构造sql语句sqlSentence4:
该过程实现中,直接把股票数据记录tuple了,然后使用字符串格式化(%操作符)。造成的精度问题没有多考虑,不知道会不会产生什么样的影响。%s有的上边带着' ',是为了在sql语句中表示字符串。其中有一个%s',只有右边有单引号,匹配的是股票代码,只有一边单引号,这是因为从数据文件中读取到的字符串已经包含了左边的单引号,左边不需要再添加了。这是数据文件格式的问题,为了表示文本形式预先使用了单引号。
6.异常值处理:
文本文件中,包含有空值、None、none等不标准化数据,这里全部替换为null了,即数据库的空值。
完成MySQL数据库数据存储后,需要关闭数据库连接:
#关闭游标,提交,关闭数据库连接
cursor.close()
db.commit()
db.close()
不关闭数据库连接,就无法在MySQL端进行数据库的查询等操作,相当于数据库被占用。
三、MySQL数据库查询
#重新建立数据库连接
db = pymysql.connect('localhost', name, password, 'stockDataBase')
cursor = db.cursor()
#查询数据库并打印内容
cursor.execute('select * from stock_600000')
results = cursor.fetchall()
for row in results:
print(row)
#关闭
cursor.close()
db.commit()
db.close()
以上逐条打印,会凌乱到死的。也可以在MySQL端查看,先选中数据库:use stockDatabase;,然后查询:select * from stock_600000;,结果大概就是下面这个样子了:
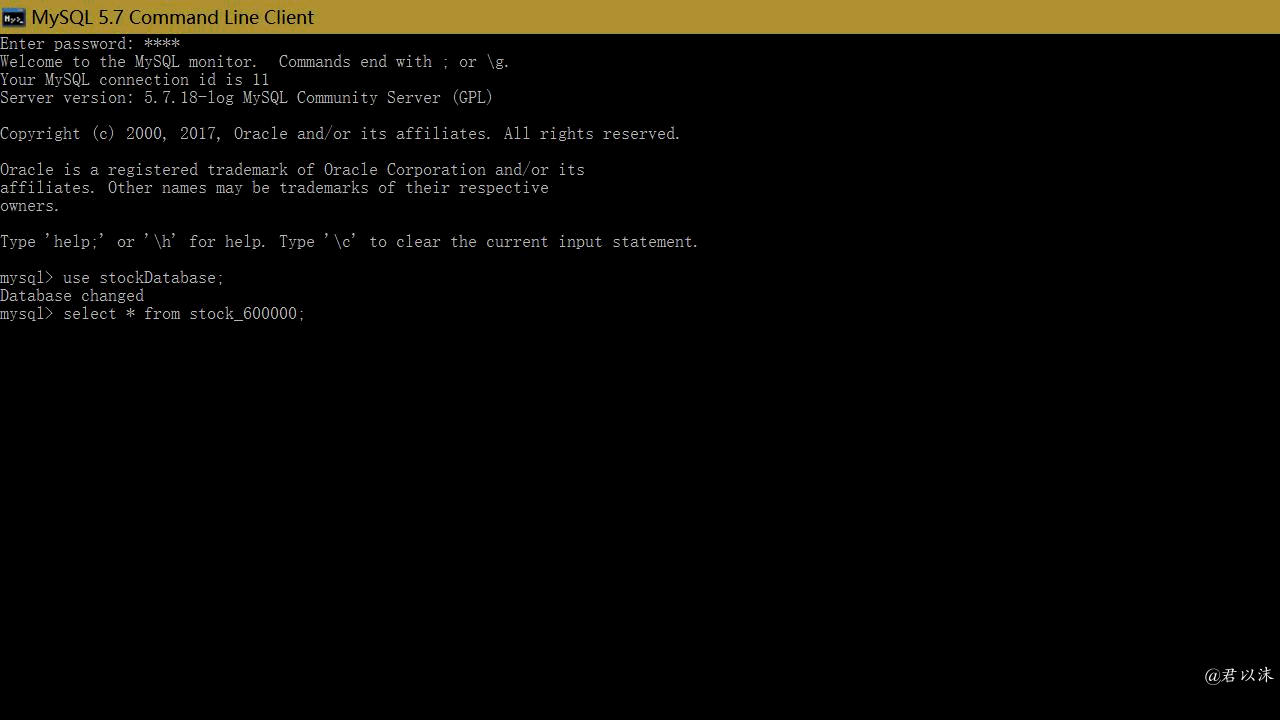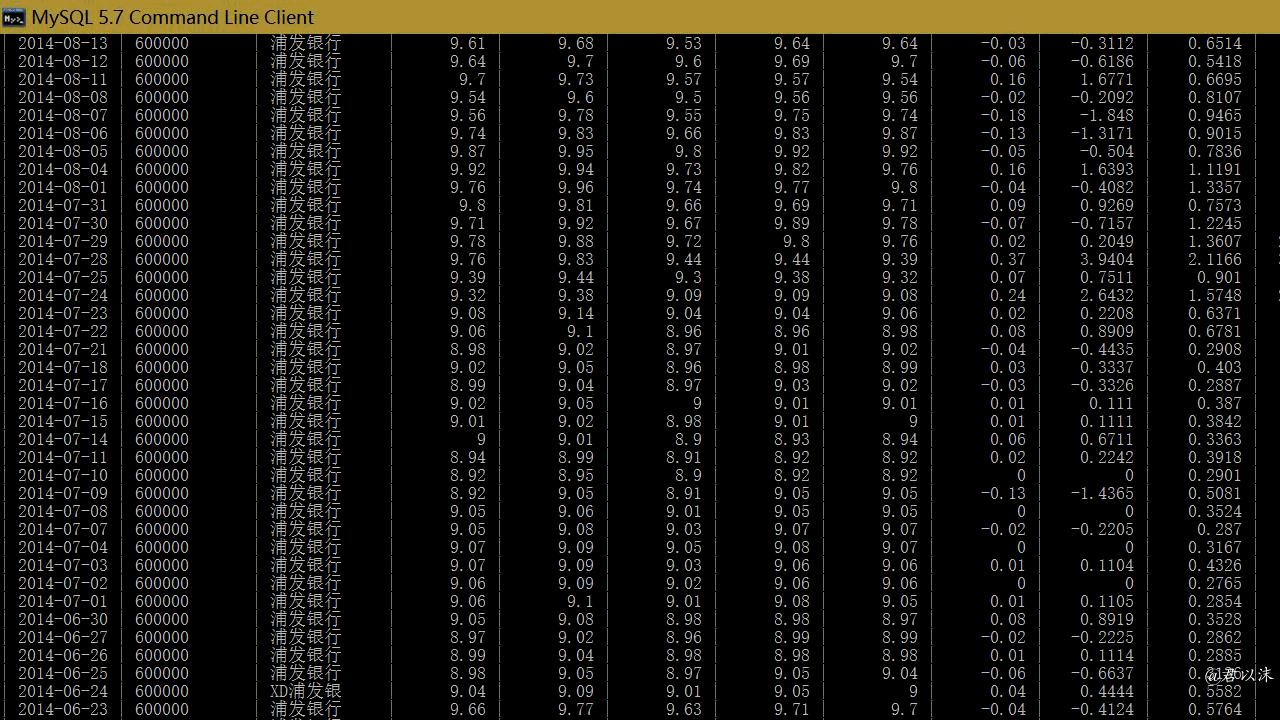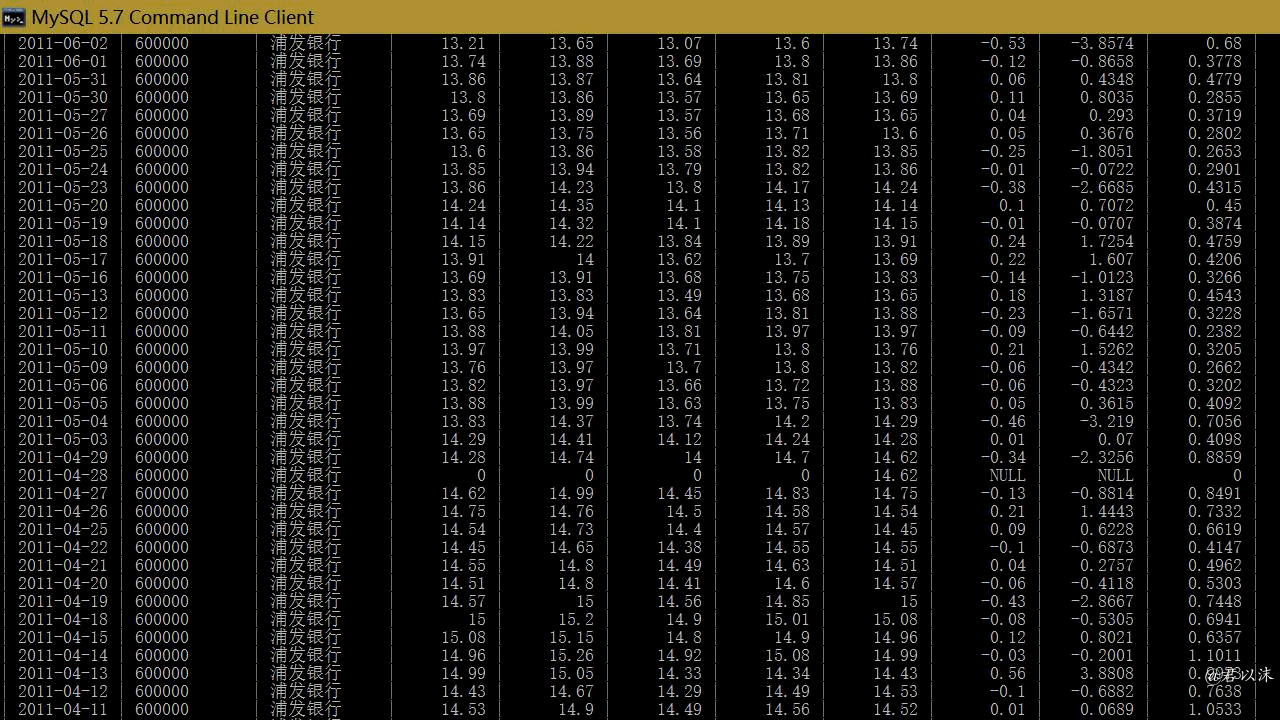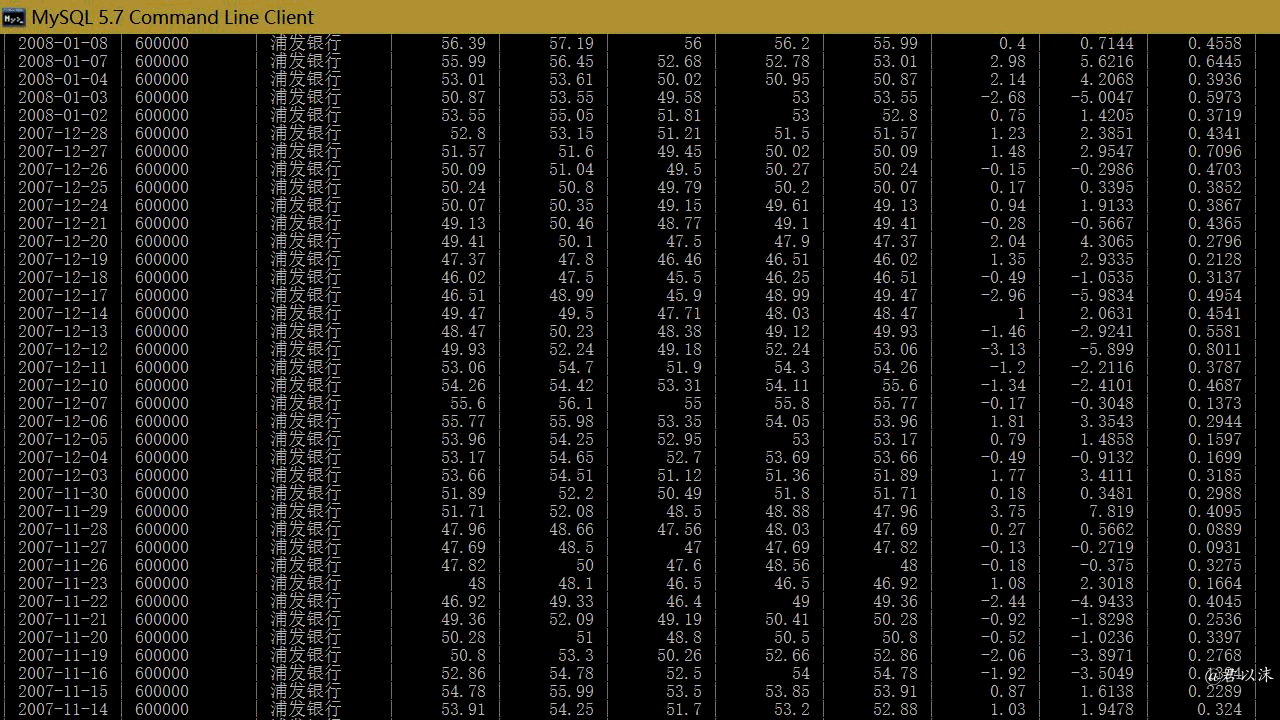
四、完整代码
实际上,整个事情完成了两个相对独立的过程:1.爬虫获取网页股票数据并保存到本地文件;2.将本地文件数据储存到MySQL数据库。并没有直接的考虑把从网页上抓取到的数据实时(或者通过一个临时文件)扔进数据库,跳过本地数据文件这个过程。这里只是尝试着去实现了一下这件事情,代码没有做任何的优化考虑。本身不实际去使用,只是乐趣而已,差不多先这样。哈哈~~
#导入需要使用到的模块
import urllib
import re
import pandas as pd
import pymysql
import os #爬虫抓取网页函数
def getHtml(url):
html = urllib.request.urlopen(url).read()
html = html.decode('gbk')
return html #抓取网页股票代码函数
def getStackCode(html):
s = r'<li><a target="_blank" href="http://quote.eastmoney.com/\S\S(.*?).html">'
pat = re.compile(s)
code = pat.findall(html)
return code #########################开始干活############################
Url = 'http://quote.eastmoney.com/stocklist.html'#东方财富网股票数据连接地址
filepath = 'C:\\Users\\Lenovo\\Desktop\\data\\'#定义数据文件保存路径
#实施抓取
code = getStackCode(getHtml(Url))
#获取所有股票代码(以6开头的,应该是沪市数据)集合
CodeList = []
for item in code:
if item[0]=='':
CodeList.append(item)
#抓取数据并保存到本地csv文件
for code in CodeList:
print('正在获取股票%s数据'%code)
url = 'http://quotes.money.163.com/service/chddata.html?code=0'+code+\
'&end=20161231&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
urllib.request.urlretrieve(url, filepath+code+'.csv') ##########################将股票数据存入数据库########################### #数据库名称和密码
name = 'xxxx'
password = 'xxxx' #替换为自己的账户名和密码
#建立本地数据库连接(需要先开启数据库服务)
db = pymysql.connect('localhost', name, password, charset='utf8')
cursor = db.cursor()
#创建数据库stockDataBase
sqlSentence1 = "create database stockDataBase"
cursor.execute(sqlSentence1)#选择使用当前数据库
sqlSentence2 = "use stockDataBase;"
cursor.execute(sqlSentence2) #获取本地文件列表
fileList = os.listdir(filepath)
#依次对每个数据文件进行存储
for fileName in fileList:
data = pd.read_csv(filepath+fileName, encoding="gbk")
#创建数据表,如果数据表已经存在,会跳过继续执行下面的步骤print('创建数据表stock_%s'% fileName[0:6])
sqlSentence3 = "create table stock_%s" % fileName[0:6] + "(日期 date, 股票代码 VARCHAR(10), 名称 VARCHAR(10),\
收盘价 float, 最高价 float, 最低价 float, 开盘价 float, 前收盘 float, 涨跌额 float, \
涨跌幅 float, 换手率 float, 成交量 bigint, 成交金额 bigint, 总市值 bigint, 流通市值 bigint)"
cursor.execute(sqlSentence3)
except:
print('数据表已存在!') #迭代读取表中每行数据,依次存储(整表存储还没尝试过)
print('正在存储stock_%s'% fileName[0:6])
length = len(data)
for i in range(0, length):
record = tuple(data.loc[i])
#插入数据语句
try:
sqlSentence4 = "insert into stock_%s" % fileName[0:6] + "(日期, 股票代码, 名称, 收盘价, 最高价, 最低价, 开盘价, 前收盘, 涨跌额, 涨跌幅, 换手率, \
成交量, 成交金额, 总市值, 流通市值) values ('%s',%s','%s',%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" % record
#获取的表中数据很乱,包含缺失值、Nnone、none等,插入数据库需要处理成空值
sqlSentence4 = sqlSentence4.replace('nan','null').replace('None','null').replace('none','null')
cursor.execute(sqlSentence4)
except:
#如果以上插入过程出错,跳过这条数据记录,继续往下进行
break #关闭游标,提交,关闭数据库连接
cursor.close()
db.commit()
db.close() ###########################查询刚才操作的成果################################## #重新建立数据库连接
db = pymysql.connect('localhost', name, password, 'stockDataBase')
cursor = db.cursor()
#查询数据库并打印内容
cursor.execute('select * from stock_600000')
results = cursor.fetchall()
for row in results:
print(row)
#关闭
cursor.close()
db.commit()
db.close()
Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储的更多相关文章
- Python 爬虫: 抓取花瓣网图片
接触Python也好长时间了,一直没什么机会使用,没有机会那就自己创造机会!呐,就先从爬虫开始吧,抓点美女图片下来. 废话不多说了,讲讲我是怎么做的. 1. 分析网站 想要下载图片,只要知道图片的地址 ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
随机推荐
- IOS开发---菜鸟学习之路--(二十)-二维码扫描功能的实现
本章将讲解如何实现二维码扫描的功能 首先在github上下载ZBar SDK地址https://github.com/bmorton/ZBarSDK 然后将如下的相关类库添加进去 AVFoundati ...
- 68、TSPL指令集(标签打印机)
0.开发者pdf.sdk等资料详见: http://download.csdn.net/detail/kunyashaw/9376694 1.测试代码 包含文字打印.条形码打印.二维码打印 packa ...
- CentOS下安装netcat
CentOS下安装netcat 使用zookeeper过程中,需要监控集群状态.在使用四字命令时(echo conf | nc localhost 2181),报出如下错误:-bash: netcat ...
- Gym 100971B 水&愚
Description standard input/output Announcement Statements A permutation of n numbers is a sequence ...
- Memcache缓存用好了,性能有了很大的提高
web服务器1 web服务器2 web服务器3如果每台web服务器都向mysql服务器表插入信息并且要做出相应最新编号反馈出现这样的高并发时候怎么减少服务器压力,同时用户体验还要好 可以使用Memca ...
- COGS 2485. [HZOI 2016]从零开始的序列
2485. [HZOI 2016]从零开始的序列 ★★ 输入文件:sky_seq.in 输出文件:sky_seq.out 简单对比时间限制:1 s 内存限制:256 MB [题目描述] ...
- cmp 指令
(lldb) disassemble -n comp2 untitled6`comp2: 0x10d065f40 <+>: pushq %rbp 0x10d065f41 <+> ...
- BZOJ【1625】宝石手镯
1625: [Usaco2007 Dec]宝石手镯 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 1007 Solved: 684[Submit][St ...
- javascript屏蔽脏字
原文发布时间为:2009-04-16 -- 来源于本人的百度文章 [由搬家工具导入] <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Tran ...
- svn没有"对号"等符号
[问题描述]调整svn建立好了服务端.安装客户端也检出成功了.但是就是没有对号符号. [解决方案]右键菜单,设置,里面有“图标覆盖”这个选项,把你的文件夹加入进去,然后注销windows用户重新登陆