pyspider 爬虫教程(一):HTML 和 CSS 选择器
虽然以前写过 如何抓取WEB页面 和 如何从 WEB 页面中提取信息。但是感觉还是需要一篇 step by step 的教程,不然没有一个总体的认识。不过,没想到这个教程居然会变成一篇译文,在这个爬虫教程系列文章中,会以实际的例子,由浅入深讨论爬取(抓取和解析)的一些关键问题。
在 教程一 中,我们将要爬取的网站是豆瓣电影:http://movie.douban.com/
你可以在: http://demo.pyspider.org/debug/tutorial_douban_movie 获得完整的代码,和进行测试。
开始之前
由于教程是基于 pyspider 的,你可以安装一个 pyspider(Quickstart,也可以直接使用 pyspider 的 demo 环境: http://demo.pyspider.org/。
你还应该至少对万维网是什么有一个简单的认识:
所以,爬网页实际上就是:
- 找到包含我们需要的信息的网址(URL)列表
- 通过 HTTP 协议把页面下载回来
- 从页面的 HTML 中解析出需要的信息
- 找到更多这个的 URL,回到 2 继续
选取一个开始网址
既然我们要爬所有的电影,首先我们需要抓一个电影列表,一个好的列表应该:
- 包含足够多的电影的 URL
- 通过翻页,可以遍历到所有的电影
- 一个按照更新时间排序的列表,可以更快抓到最新更新的电影
我们在 http://movie.douban.com/ 扫了一遍,发现并没有一个列表能包含所有电影,只能退而求其次,通过抓取分类下的所有的标签列表页,来遍历所有的电影: http://movie.douban.com/tag/
创建一个项目
在 pyspider 的 dashboard 的右下角,点击 "Create" 按钮
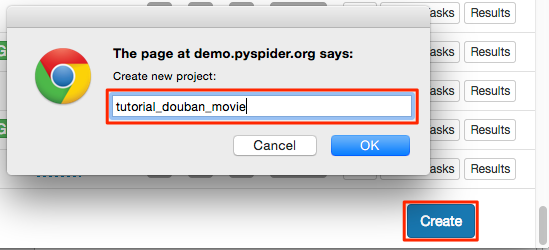
替换 on_start 函数的 self.crawl 的 URL:
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)
self.crawl告诉 pyspider 抓取指定页面,然后使用callback函数对结果进行解析。@every修饰器,表示on_start每天会执行一次,这样就能抓到最新的电影了。
点击绿色的 run 执行,你会看到 follows 上面有一个红色的 1,切换到 follows 面板,点击绿色的播放按钮:
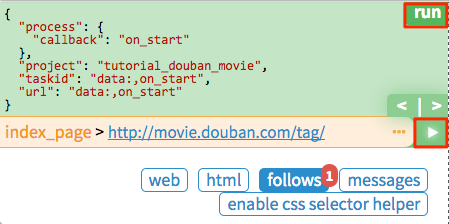
Tag 列表页
在 tag 列表页 中,我们需要提取出所有的 电影列表页 的 URL。你可能已经发现了,sample handler 已经提取了非常多大的 URL,所有,一种可行的提取列表页 URL 的方法就是用正则从中过滤出来:
import re
...
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)
- 由于 电影列表页和 tag列表页长的并不一样,在这里新建了一个
callback为self.list_page@config(age=10 * 24 * 60 * 60)在这表示我们认为 10 天内页面有效,不会再次进行更新抓取
由于 pyspider 是纯 Python 环境,你可以使用 Python 强大的内置库,或者你熟悉的第三方库对页面进行解析。不过更推荐使用 CSS选择器。
电影列表页
再次点击 run 让我们进入一个电影列表页(list_page)。在这个页面中我们需要提取:
- 电影的链接,例如,http://movie.douban.com/subject/1292052/
- 下一页的链接,用来翻页
CSS选择器
CSS选择器,顾名思义,是 CSS 用来定位需要设置样式的元素 所使用的表达式。既然前端程序员都使用 CSS选择器 为页面上的不同元素设置样式,我们也可以通过它定位需要的元素。你可以在 CSS 选择器参考手册 这里学习更多的 CSS选择器 语法。
在 pyspider 中,内置了 response.doc 的 PyQuery 对象,让你可以使用类似 jQuery 的语法操作 DOM 元素。你可以在 PyQuery 的页面上找到完整的文档。
CSS Selector Helper
在 pyspider 中,还内置了一个 CSS Selector Helper,当你点击页面上的元素的时候,可以帮你生成它的 CSS选择器 表达式。你可以点击 Enable CSS selector helper 按钮,然后切换到 web 页面:
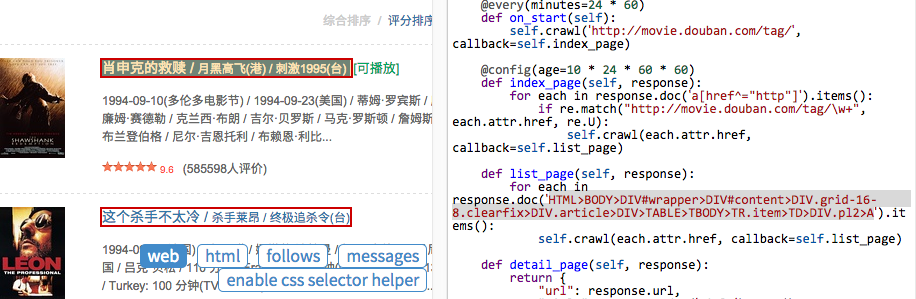
开启后,鼠标放在元素上,会被黄色高亮,点击后,所有拥有相同 CSS选择器 表达式的元素会被高亮。表达式会被插入到 python 代码当前光标位置。创建下面的代码,将光标停留在单引号中间:
def list_page(self, response):
for each in response.doc('').items():
点击一个电影的链接,CSS选择器 表达式将会插入到你的代码中,如此重复,插入翻页的链接:
def list_page(self, response):
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 翻页
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items():
self.crawl(each.attr.href, callback=self.list_page)
- 翻页是一个到自己的
callback回调
电影详情页
再次点击 run,follow 到详情页。使用 css selector helper 分别添加电影标题,打分和导演:
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('HTML>BODY>DIV#wrapper>DIV#content>H1>SPAN').text(),
"rating": response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.indent.clearfix>DIV.subjectwrap.clearfix>DIV#interest_sectl>DIV.rating_wrap.clearbox>P.rating_self.clearfix>STRONG.ll.rating_num').text(),
"导演": [x.text() for x in response.doc('a[rel="v:directedBy"]').items()],
}
注意,你会发现 css selector helper 并不是总是能提取到合适的 CSS选择器 表达式。你可以在 Chrome Dev Tools 的帮助下,写一个合适的表达式:
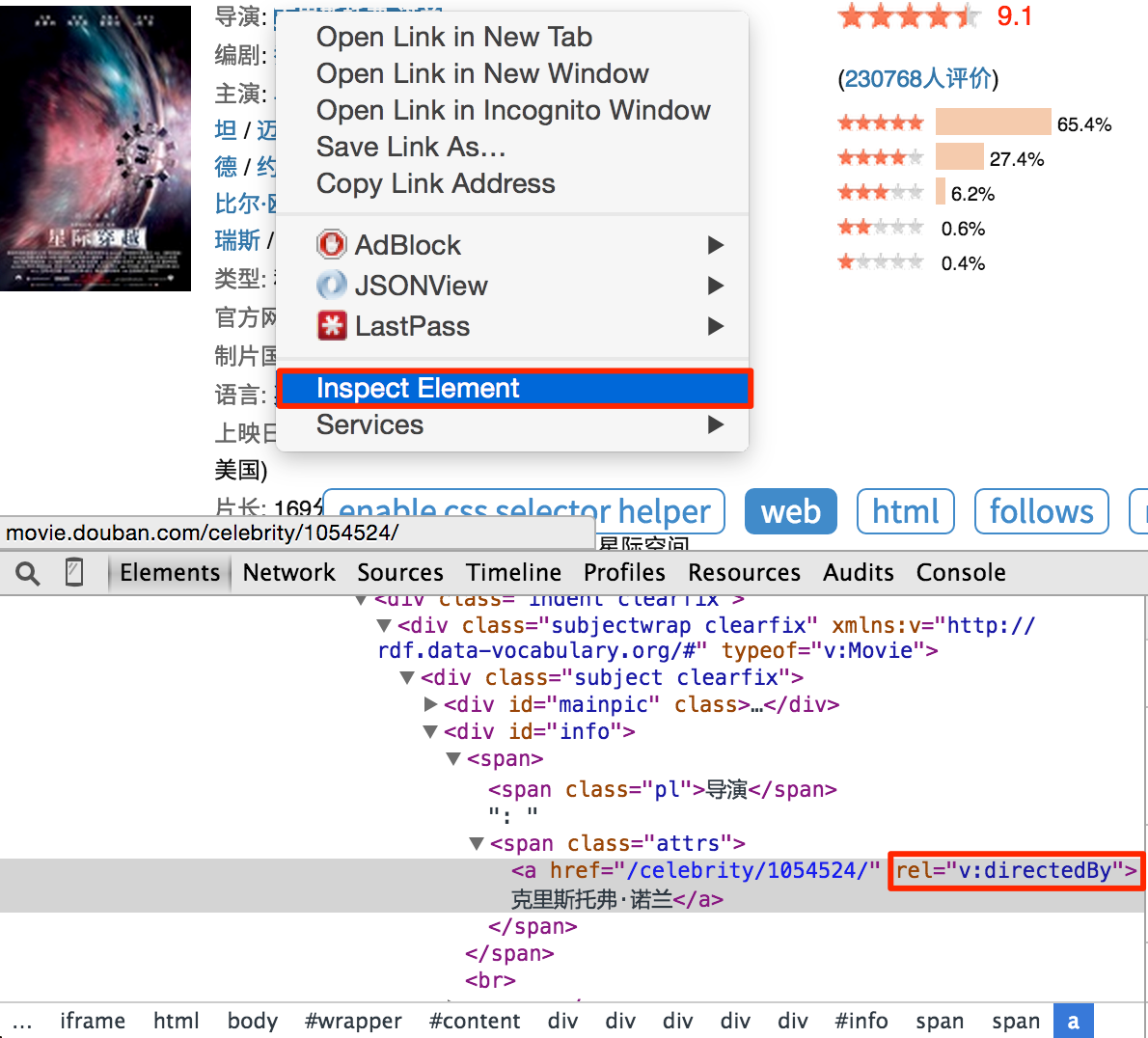
右键点击需要提取的元素,点击审查元素。你并不需要像自动生成的表达式那样写出所有的祖先节点,只要写出那些能区分你不需要的元素的关键节点的属性就可以了。不过这需要抓取和网页前端的经验。所以,学习抓取的最好方法就是学会这个页面/网站是怎么写的。
你也可以在 Chrome Dev Tools 的 Javascript Console 中,使用 $$(a[rel="v:directedBy"]) 测试 CSS Selector。
开始抓取
- 使用
run单步调试你的代码,对于用一个callback最好使用多个页面类型进行测试。然后保存。 - 回到 Dashboard,找到你的项目
- 将
status修改为DEBUG或RUNNING - 按
run按钮
pyspider 爬虫教程(一):HTML 和 CSS 选择器的更多相关文章
- Pyspider爬虫教程
Pyspider爬虫教程 一.安装 1. 安装pip (1)准备工作 yum install –y make gcc-c++ python-devel libxml2-devel libxslt-de ...
- 爬虫入门【11】Pyspider框架入门—使用HTML和CSS选择器下载小说
开始之前 首先我们要安装好pyspider,可以参考上一篇文章. 从一个web页面抓取信息的过程包括: 1.找到页面上包含的URL信息,这个url包含我们想要的信息 2.通过HTTP来获取页面内容 3 ...
- 【网络爬虫入门04】彻底掌握BeautifulSoup的CSS选择器
[网络爬虫入门04]彻底掌握BeautifulSoup的CSS选择器 广东职业技术学院 欧浩源 2017-10-21 1.引言 目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup ...
- 第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器 css选择器 1. 2. 3. ::attr()获取元素属性,css选择器 ::text获取标签文本 举例: extr ...
- 十九 Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
css选择器 1. 2. 3. ::attr()获取元素属性,css选择器 ::text获取标签文本 举例: extract_first('')获取过滤后的数据,返回字符串,有一个默认参数,也就是如 ...
- 爬虫学习笔记(2)--创建scrapy项目&&css选择器
一.手动创建scrapy项目---------------- 安装scrapy: pip install -i https://pypi.douban.com/simple/ scrapy 1 ...
- IT兄弟连 HTML5教程 CSS3揭秘 CSS选择器1
要使用CSS对HTML页面中的元素实现一对一.一对多或者多对一的控制,就需要用到CSS选择器.选择器是CSS3中一个重要的内容,使用它可以大幅度地提高开发人员书写或修改样式表的效率.在大型网站中,样式 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
随机推荐
- jsp页面:一个form,不同请求提交form
需求:一个表单中有一个请求 action="url"发送数据地址: 在表单外有一个请求,请求form表单提交的数据 我们用js来写:通过每次请求传不同的action=url; 例如 ...
- 生产环境LAMP搭建 - 基于 fastcgi
生产环境LAMP搭建 - 基于 fastcgi 由于在module模式,php只是已http的模块形式存在,无形中加重了http的服务负载,通常在企业架构中,使用fastcgi的模式,将所有的服务都设 ...
- 添加SQL字段
通用式: alter table [表名] add [字段名] 字段属性 default 缺省值 default 是可选参数增加字段: alter table [表名] add 字段名 smallin ...
- 解析XML格式数据
学习解析XML格式的数据前,搭建一个简单的web服务器,在这个服务器上提供xml文本用于练习. 一.搭建Apache服务器 在Apache官网下载编译好的服务器程序,安装.对于Windows来说127 ...
- Codeforces Round #456 (Div. 2) A. Tricky Alchemy
传送门:http://codeforces.com/contest/912/problem/A A. Tricky Alchemy time limit per test1 second memory ...
- 动态规划、记忆化搜索:HDU1978-How many ways
Problem Description 这是一个简单的生存游戏,你控制一个机器人从一个棋盘的起始点(1,1)走到棋盘的终点(n,m).游戏的规则描述如下: 1.机器人一开始在棋盘的起始点并有起始点所标 ...
- Asp.net自定义控件开发任我行(1)-笑傲江湖
1.引言 参加工作5个月了,来到一家小公司,有几只老鸟带我,但不是我公司的,几个礼拜才来一次.来到公司做的第一个项目是web项目,里面有很多的重复代码,页面代码都是千篇一律,你这人也太水了吧,垃圾代码 ...
- 【Swap Nodes in Pairs】cpp
题目: Given a linked list, swap every two adjacent nodes and return its head. For example,Given 1-> ...
- leetcode 【 Set Matrix Zeroes 】python 实现
题目: Given a m x n matrix, if an element is 0, set its entire row and column to 0. Do it in place. cl ...
- Python+Selenium练习篇之10-刷新当前页面
本文介绍如何调用webdriver中刷新页面的方法. 相关脚本代码如下: # coding=utf-8import timefrom selenium import webdriver driver ...