Python3获取大量电影信息:调用API
实验室这段时间要采集电影的信息,给出了一个很大的数据集,数据集包含了4000多个电影名,需要我写一个爬虫来爬取电影名对应的电影信息。
其实在实际运作中,根本就不需要爬虫,只需要一点简单的Python基础就可以了。
前置需求:
Python3语法基础
HTTP网络基础
===================================
第一步,确定API的提供方。IMDb是最大的电影数据库,与其相对的,有一个OMDb的网站提供了API供使用。这家网站的API非常友好,易于使用。
http://www.omdbapi.com/
第二步,确定网址的格式。
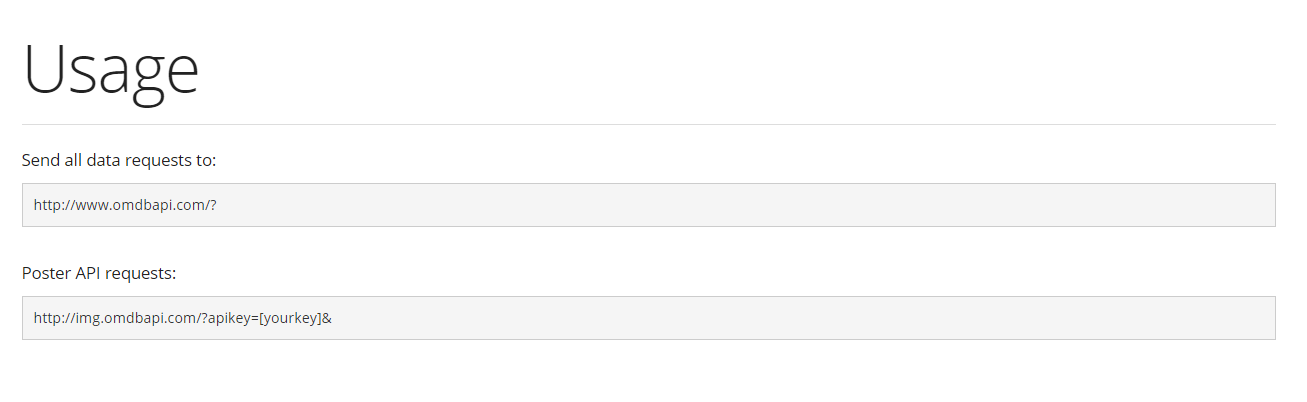
第三步,了解基本的Requests库的使用方法。
http://cn.python-requests.org/zh_CN/latest/

为什么我要使用Requests,不使用urllib.request呢?
因为Python的这个库容易出各种各样的奇葩问题,我已经受够了……
第四步,编写Python代码。
我想做的是,逐行读取文件,然后用该行的电影名去获取电影信息。因为源文件较大,readlines()不能完全读取所有电影名,所以我们逐行读取。
import requests
for line in open("movies.txt"):
s=line.split('%20\n')
urll='http://www.omdbapi.com/?t='+s[0]
result=requests.get(urll)
if result:
json=result.text
print(json)
p=open('result0.json','a')
p.write(json)
p.write('\n')
p.close()
我预先把电影名文件全部格式化了一遍,将所有的空格替换成了"%20",便于使用API(否则会报错)。这个功能可以用Visual Studio Code完成。
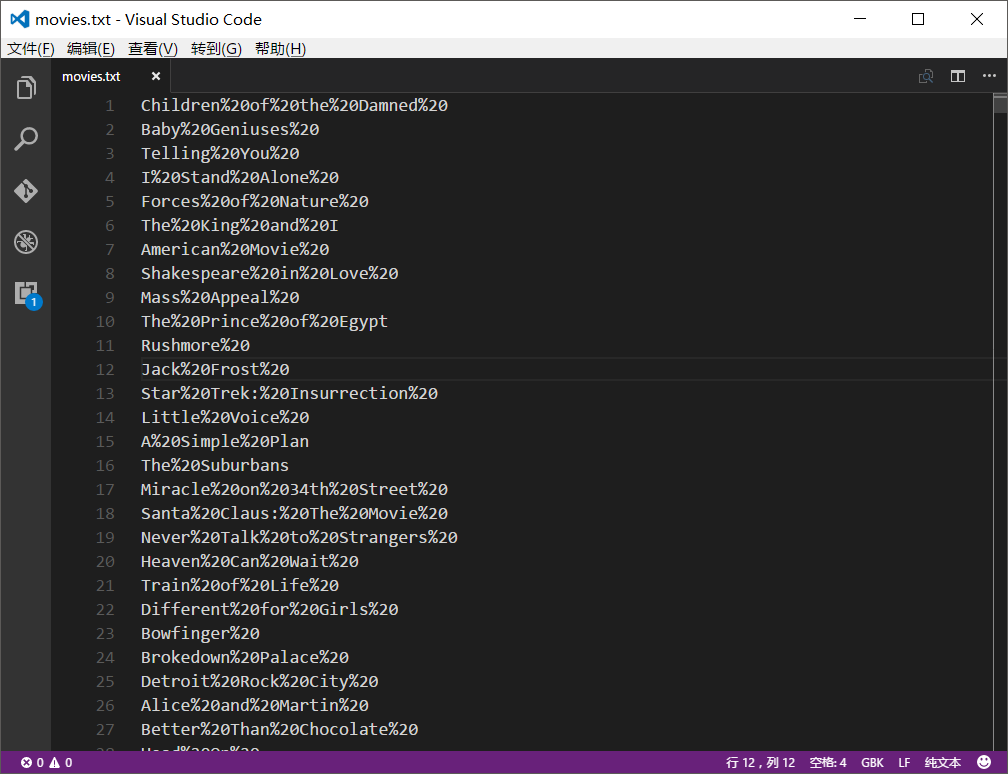
注意,编码的时候选择GBK编码,不然会出现下面错误:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: illegal multibyte sequence
第五步,做优化和异常处理。
主要做三件事,第一件事,控制API速度,防止被服务器屏蔽;
第二件事,获取API key(甚至使用多个key)
第三件事:异常处理。
import requests
key=[‘’] for line in open("movies.txt"):
try:
#……
except TimeoutError:
continue
except UnicodeEncodeError:
continue
except ConnectionError:
continue
下面贴出完整代码:
# -*- coding: utf-8 -*- import requests
import time key=['xxxxx','yyyyy',zzzzz','aaaaa','bbbbb']
i=0 for line in open("movies.txt"):
try:
i=(i+1)%5
s=line.split('%20\n')
urll='http://www.omdbapi.com/?t='+s[0]+'&apikey='+key[i]
result=requests.get(urll)
if result:
json=result.text
print(json)
p=open('result0.json','a')
p.write(json)
p.write('\n')
p.close()
time.sleep(1)
except TimeoutError:
continue
except UnicodeEncodeError:
continue
except ConnectionError:
continue
接下来喝杯茶,看看自己的程序跑得怎么样吧!
Python3获取大量电影信息:调用API的更多相关文章
- 一个 C# 获取高精度时间类(调用API QueryP*)
如果你觉得用 DotNet 自带的 DateTime 获取的时间精度不够,解决的方法是通过调用 QueryPerformanceFrequency 和 QueryPerformanceCounter这 ...
- python3获取网页天气预报信息并打印
查到一个可以提供区域天气预报的url, https://www.sojson.com/open/api/weather/json.shtml?city=%E6%88%90%E9%83%BD打算用pyt ...
- Python3获取拉勾网招聘信息
为了了解跟python数据分析有关行业的信息,大概地了解一下对这个行业的要求以及薪资状况,我决定从网上获取信息并进行分析.既然想要分析就必须要有数据,于是我选择了拉勾,冒着危险深入内部,从他们那里得到 ...
- 获取app安装信息私有api
@class LSApplicationProxy, NSArray, NSDictionary, NSProgress, NSString, NSURL, NSUUID; @interface LS ...
- iOS 获取APP相关信息 私有API
/* Generated by RuntimeBrowser Image: /System/Library/Frameworks/MobileCoreServices.framework/Mobile ...
- 爬虫实战【11】Python获取豆瓣热门电影信息
之前我们从猫眼获取过电影信息,而且利用分析ajax技术,获取过今日头条的街拍图片. 今天我们在豆瓣上获取一些热门电影的信息. 页面分析 首先,我们先来看一下豆瓣里面选电影的页面,我们默认选择热门电影, ...
- Vue 电影信息影评(豆瓣,猫眼)
Vue电影信息影评网站 此网站是我的毕业设计,题目是"基于HTML5的电影信息汇总弄网站",由于最近在看Vue.js,所以就想用Vue.js来构建一个前端网站,这里code就不大篇 ...
- 80 行代码爬取豆瓣 Top250 电影信息并导出到 CSV 及数据库
一.下载页面并处理 二.提取数据 观察该网站 html 结构 可知该页面下所有电影包含在 ol 标签下.每个 li 标签包含单个电影的内容. 使用 XPath 语句获取该 ol 标签 在 ol 标签中 ...
- Android 获取手机信息,设置权限,申请权限,查询联系人,获取手机定位信息
Android 获取手机信息,设置权限,申请权限,查询联系人,获取手机定位信息 本文目录: 获取手机信息 设置权限 申请权限 查询联系人 获取手机定位信息 调用高德地图,设置显示2个坐标点的位置,以及 ...
随机推荐
- php+redis实现高并发模拟下单、秒杀、抢购操作
对于高并发下的场景,一般都是采用redis缓存机制来处理. 当然也不是只有redis可以处理.还有利用mysql事务操作锁住操作的行.文件锁. 不过这些方式都没有redis缓存高效.可靠. 模拟的过程 ...
- javascript数组对象
constructor属性 返回数组对象原型 var arr = [1,2,3,4,5]; arr.constructor //输出 function Array() { [native code] ...
- 【转】mysql数据库的数据类型
一.数值类型 Mysql支持所有标准SQL中的数值类型,其中包括: 严格数据类型(INTEGER,SMALLINT,DECIMAL,NUMBERIC ...
- Vue拖拽组件列表实现动态页面配置
需求描述 最近在做一个后台系统,有一个功能产品需求是页面分为左右两部分,通过右边的组件列表来动态配置左边的页面视图,并且左边由组件拼装起来的视图,可以实现上下拖拽改变顺序,也可以删除. 根据这个需求我 ...
- 伪类选择器 :nth-child(even) :nth-child(odd) :nth-of-type
属性 描述 CSS :active 向被激活的元素添加样式. 1 :focus 向拥有键盘输入焦点的元素添加样式. 2 :hover 当鼠标悬浮在元素上方时,向元素添加样式. 1 :link 向未被访 ...
- 51nod1154(dp)
题目链接:http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1154 题意:中文题目诶- 思路:字符串长度不大于5e3,O(n ...
- 洛谷P3172 [CQOI2015]选数(容斥)
传送门 首先,进行如下处理 如果$L$是$K$的倍数,那么让它变成$\frac{L}{K}$,否则变成$\frac{L}{K}+1$ 把$H$变成$\frac{H}{K}$ 那么,现在的问题就变成了在 ...
- Luogu P2257 YY的GCD 莫比乌斯反演
第一道莫比乌斯反演...$qwq$ 设$f(d)=\sum_{i=1}^n\sum_{j=1}^m[gcd(i,j)==d]$ $F(n)=\sum_{n|d}f(d)=\lfloor \frac{N ...
- [NWPU2016][寒假作业][正常版第三组]I
素数环,简单的dfs,但这道题我有个小地方写错了半天发现不了..就是flag数组的位置.一定要放在if里面,刚开始没注意,一不小心写到外面了. #include <iostream> #i ...
- java实现access数据上传
一. --springMvc实现上传 https://blog.csdn.net/qian_ch/article/details/69258465 --转换成spring64位上传 https://b ...