Kafka入门之生产者消费者
一、Kafka安装与使用 ( kafka介绍 )
1. 下载Kafka
官网 http://kafka.apache.org/ 以及各个版本的下载地址 http://archive.apache.org/dist/kafka/
2. 安装
Kafka是使用scala编写的运行与jvm虚拟机上的程序,虽然也可以在windows上使用,但是kafka基本上是运行在linux服务器上,(也可以运行在windows上)因此我们这里也使用linux来开始今天的实战。首先确保你的机器上安装了jdk,kafka需要java运行环境,以前的kafka还需要zookeeper,新版的kafka已经内置了一个zookeeper环境,所以我们可以直接使用。说是安装,如果只需要进行最简单的尝试的话我们只需要解压到任意目录即可,这里我们将kafka压缩包解压到/home目录
直接解压缩即可使用(不管在linux上,还是windows上)
Kafka目录如下:
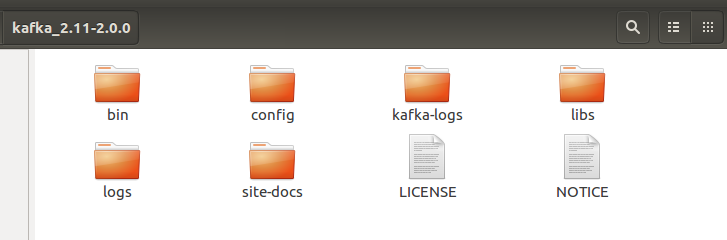
其中bin是执行文件目录,包括linux下的执行文件,以及bin/window目录下包含windows执行的批处理命令;
config中包含kafka的配置文件;
libs中是kafka的各种依赖包。
3. 配置 ( Linux下Kafka单机安装配置方法(图文))
配置Kafka文件(不配置也能在本地机上执行,不配置默认主机是localhost )
命令行输入: vi server.properties #编辑修改相应的参数
broker.id= port= #端口号 host.name=192.168.0.11 #服务器IP地址,修改为自己的服务器IP log.dirs=/usr/local/kafka/log/kafka #日志存放路径,上面创建的目录 (改成自己的目录) zookeeper.connect=localhost: #zookeeper地址和端口,单机配置部署,localhost:
4. 命令行运行
4.1 启动zookeeper
cd进入kafka解压目录,输入
bin/zookeeper-server-start.sh config/zookeeper.properties
启动zookeeper成功后会看到如下的输出

4.2 启动kafka
cd进入kafka解压目录,输入
bin/kafka-server-start.sh config/server.properties
启动kafka成功后会看到如下的输出

5. 第一个消息(Linux)
5.1 创建一个topic
Kafka通过topic对同一类的数据进行管理,同一类的数据使用同一个topic可以在处理数据时更加的便捷
在kafka解压目录打开终端,输入
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
创建一个名为test的topic

在创建topic后可以通过输入
bin/kafka-topics.sh --list --zookeeper localhost:2181
来查看已经创建的topic
5.2 创建一个消息消费者
在kafka解压目录打开终端,输入
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
可以创建一个用于消费topic为test的消费者

消费者创建完成之后,因为还没有发送任何数据,因此这里在执行后没有打印出任何数据
不过别着急,不要关闭这个终端,打开一个新的终端,接下来我们创建第一个消息生产者
5.3 创建一个消息生产者
在kafka解压目录打开一个新的终端,输入
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
在执行完毕后会进入的编辑器页面

在发送完消息之后,可以回到我们的消息消费者终端中,可以看到,终端中已经打印出了我们刚才发送的消息

第4步可以通过脚本文件进行实现:
1) 创建启动脚本,假设我们的Kafka在/usr/local/目录下
cd /usr/local/kafka #创建启动脚本
vi kafkastart.sh #编辑,添加以下代码
#!/bin/sh
#创建启动脚本
#启动zookeeper
/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
sleep #等3秒后执行 #启动kafka
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
2) 创建关闭脚本
vi kafkastop.sh #编辑,添加以下代码
#!/bin/sh
#创建关闭脚本
#关闭kafka
/usr/local/kafka/bin/kafka-server-stop.sh /usr/local/kafka/config/server.properties &
sleep #等3秒后执行 #关闭zookeeper
/usr/local/kafka/bin/zookeeper-server-stop.sh /usr/local/kafka/config/zookeeper.properties &
3)命令行添加执行权限
#添加脚本执行权限
chmod +x kafkastart.sh
chmod +x kafkastop.sh
4)命令行执行脚本
sh /usr/local/kafka/kafkastart.sh #启动kafka sh /usr/local/kafka/kafkastop.sh #关闭kafka
6. 第一个消息(windows) https://www.cnblogs.com/flower1990/p/7466882.html
进入Kafka安装目录D:\Kafka\kafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
6.1 启动zookeeper
.\bin\windows\zookeeper-server-start.bat .\config\server.properties
6.2 启动Kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties
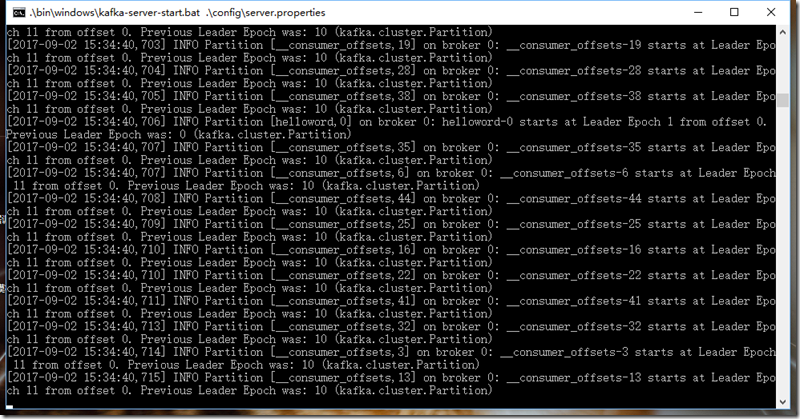
注意:注意:不要关了这个窗口,启用Kafka前请确保ZooKeeper实例已经准备好并开始运行
6.3 创建主题
进入Kafka安装目录D:\Kafka\kafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
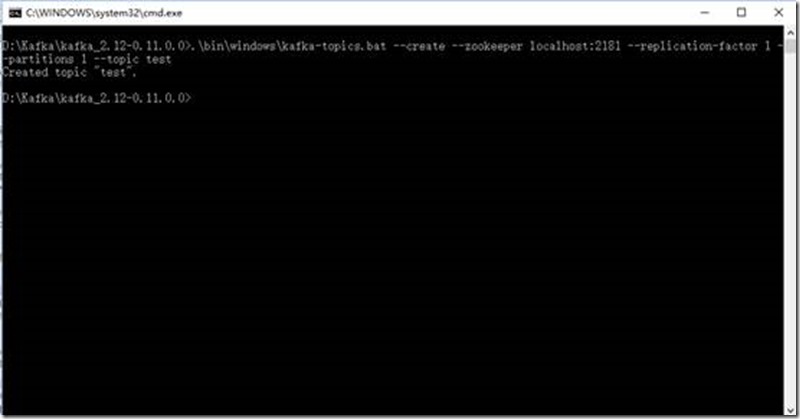
注意:不要关了这个窗口
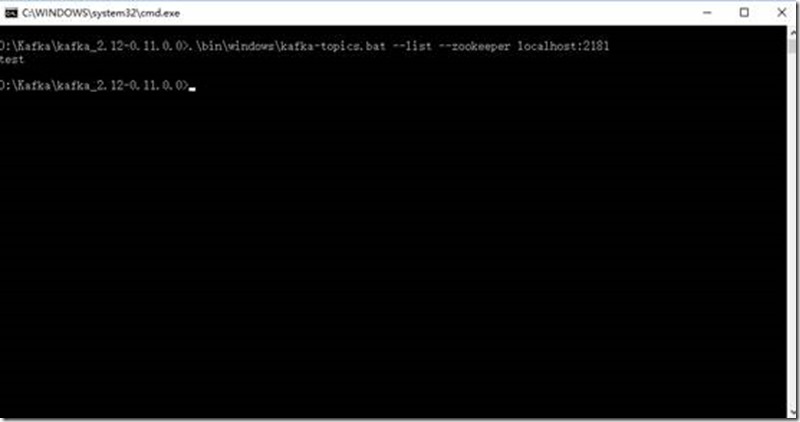
查看主题输入:
.\bin\windows\kafka-topics.bat --list --zookeeper localhost:2181
6.4 创建生产者
进入Kafka安装目录D:\Kafka\kafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
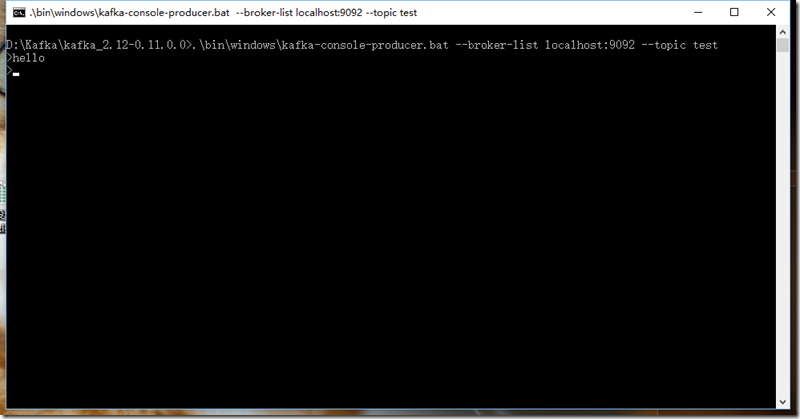
注意:不要关了这个窗口
6.5 创建消费者
进入Kafka安装目录D:\Kafka\kafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
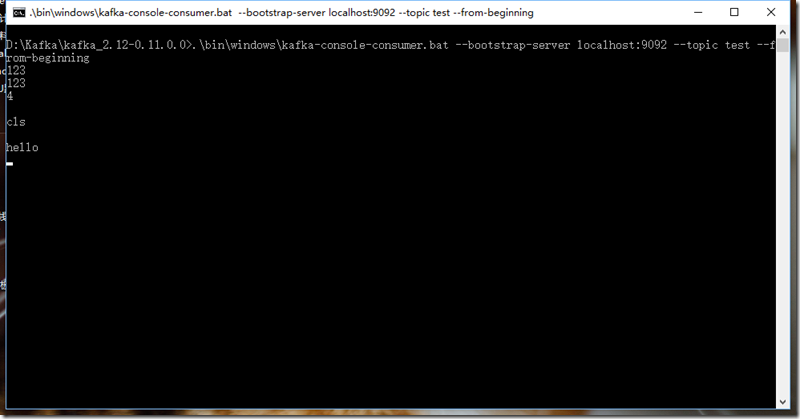
其中6.1和6.2可以使用批处理文件
1) 创建启动脚本,假设我们的Kafka在D:\Kafka\kafka_2.12-0.11.0.0目录下
切换到 D:\Kafka\kafka_2.12-0.11.0.0目录下 #创建启动脚本
用文本编辑器编辑kafkastart.bat #编辑,添加以下代码
#创建启动脚本
# ...自己添加
vi kafkastop.sh #编辑,添加以下代码
#创建关闭脚本
# 自己添加
双击即可运行。
7. 使用Java程序(模拟真实生产环境;生产者在Kafka服务器上,消费者在客户端; 可以推广到分布式环境中)
如果是生产者以及消费者都在本机进行测试,则Kafka中配置文件不需要改变;且生产者和消费者都在同一台机器上。
否则:
7.1 创建Topic
7.2 生产者
eclipse中创建一个名为KafkaProduce的Java Project;接着右击该项目new一个名为lib的Folder;然后将我们部署的kafka的libs中的所有Jar包拷贝到该项目的lib目录下;接着右击该项目,build Path,然后选择configure build path中的Libraries,接着Add Jars;将本项目lib下的所有Jar包添加进来。
package com.zc.kafka.producer.main; import java.util.Properties; import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord; /**
* Kafka生产者
* 先启动生产者,发送消息到broker,这里简单发送了10条从0-9的消息,再启动消费者,控制台输出如下:
*/
public class SimpleKafkaProducer { public static void main(String[] args) {
// TODO Auto-generated method stub Properties props = new Properties(); //broker地址
props.put("bootstrap.servers", "192.168.0.11:9092"); // "localhost:9092" //请求时候需要验证
props.put("acks", "all"); //请求失败时候需要重试
props.put("retries", 0); //内存缓存区大小
props.put("buffer.memory", 33554432); //指定消息key序列化方式
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer"); //指定消息本身的序列化方式
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 10; i++) { //i < 10
// 生产一条消息的时间有点长
producer.send(new ProducerRecord<>("test", Integer.toString(i), Integer.toString(i)));
//System.out.println(i);
}
System.out.println("Message sent successfully");
producer.close();
} }
7.3 消费者
eclipse中创建一个名为KafkaConsumer的Java Project;接着右击该项目new一个名为lib的Folder;然后将我们部署的kafka的libs中的所有Jar包拷贝到该项目的lib目录下;接着右击该项目,build Path,然后选择configure build path中的Libraries,接着Add Jars;将本项目lib下的所有Jar包添加进来。
package com.zc.kafka.consumer.main; import java.util.Collections;
import java.util.Properties; import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; /**
* kafka消费者
*/
public class SimpleKafkaConsumer { @SuppressWarnings({ "deprecation", "resource" })
public static void main(String[] args) {
// TODO Auto-generated method stub
Properties props = new Properties(); props.put("bootstrap.servers", "192.168.0.11:9092"); // "localhost:9092"
//每个消费者分配独立的组号
props.put("group.id", "test"); //如果value合法,则自动提交偏移量
props.put("enable.auto.commit", "true"); //设置多久一次更新被消费消息的偏移量
props.put("auto.commit.interval.ms", "1000"); //设置会话响应的时间,超过这个时间kafka可以选择放弃消费或者消费下一条消息
props.put("session.timeout.ms", "30000"); //
//props.put("auto.offset.reset", "earliest"); props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Collections.singletonList("test")); //核心函数1:订阅topic System.out.println("Subscribed to topic " + "test");
//int i = 0; while (true) {
//System.out.println(i++);
//核心函数2:long poll,一次拉取回来多个消息
/* 读取数据,读取超时时间为100ms */
ConsumerRecords<String, String> records = consumer.poll(100);
//System.out.println(records.count());
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
} }
7.4 打Jar包执行
1)打Jar包
右击该项目,选择Export;之后选择Runnable JAR file,接着next; 然后在Launch configuration中选择主类(含main方法),如果没有,则需要先运行该主类,接着Export destination选择Jar包的存放位置和名称,接着Library handling 选择第二个,Finish;会生成相应Jar包。
通过 java -jar XXX.jar 运行该Jar包。
2)执行
将生产者与消费者都打成相应Jar包;都可以在服务器(有Kafka环境)和客户机(没有Kafka环境)上执行;并且生产者和消费者可以在不同客户机上也可以在相同客户机上执行。
就是我们编程以及运行的kafka项目,跟有没有Kafka环境是无关的。
1. 服务器上先启动Kafka
2. 服务器或者客户机上启动生产者 java -jar KafkaProducer.jar
3. 服务器或者客户机上启动消费者 java -jar KafkaConsumer.jar
Kafka入门之生产者消费者的更多相关文章
- Kafka入门之生产者消费者测试
目录: kafka启动脚本以及关闭脚本 1. 同一个生产者同一个Topic,两个相同的消费者相同的Group 2. 同一个生产者同一个Topic,两个消费者不同Group 3. 两个生产者同一个Top ...
- centos7单机安装kafka,进行生产者消费者测试
[转载请注明]: 原文出处:https://www.cnblogs.com/jstarseven/p/11364852.html 作者:jstarseven 码字挺辛苦的..... 一.k ...
- kafka集群搭建和使用Java写kafka生产者消费者
1 kafka集群搭建 1.zookeeper集群 搭建在110, 111,112 2.kafka使用3个节点110, 111,112 修改配置文件config/server.properties ...
- Python 使用python-kafka类库开发kafka生产者&消费者&客户端
使用python-kafka类库开发kafka生产者&消费者&客户端 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper- ...
- Hadoop生态圈-Kafka的新API实现生产者-消费者
Hadoop生态圈-Kafka的新API实现生产者-消费者 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Kafka的旧API实现生产者-消费者
Hadoop生态圈-Kafka的旧API实现生产者-消费者 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.旧API实现生产者-消费者 1>.开启kafka集群 [yinz ...
- Kafka入门(4):深入消费者
摘要 在这一篇文章中,我将向你介绍消费者的一些参数. 这些参数影响了每次poll()请求的数据量,以及等待时间. 在这之后,我将向你介绍Kafka用来保证消费者扩展性以及可用性的设计--消费者组. 在 ...
- Golang 入门系列(十七)几个常见的并发模型——生产者消费者模型
前面已经讲过很多Golang系列知识,包括并发,锁等内容,感兴趣的可以看看以前的文章,https://www.cnblogs.com/zhangweizhong/category/1275863.ht ...
- 并发编程入门(二):分析Boost对 互斥量和条件变量的封装及实现生产者消费者问题
请阅读上篇文章<并发编程实战: POSIX 使用互斥量和条件变量实现生产者/消费者问题>.当然不阅读亦不影响本篇文章的阅读. Boost的互斥量,条件变量做了很好的封装,因此比" ...
随机推荐
- 小胖学PHP总结4-----PHP的字符串操作
1.字符串连接 字符串是通过半角句号"."来连接的.能够把两个或两个以上的字符串连接成一个字符串. 2.去除字符串首尾空格和特殊字符 PHP中提供了trim()函数去除字符串左右两 ...
- Unity光滑与粗糙的材质——相似于生锈的金属表面
纹理是在Photoshop中制作的,终于效果则是在Unity里得到的.这样的类型的材质.在3D游戏中非经常见.
- 将UIBezierPath存为自己定义格式的字符串,再将字符串转为UIBezierPath
<pre name="code" class="objc">自己定义字符串格式为:@"123.02,234.23|321.23,432.0 ...
- MySQL 更新和删除
更新和删除的操作SQL语句比較简单,只是要注意使用UPDATE的时候.要注意WEHER条件的限制,以下的语句是仅仅更新id为10005的email地址,假设不加WHERE语句限制,那么将表中全部的em ...
- IOS下SQLite的简单使用
本文转载至 http://www.cnblogs.com/cokecoffe/archive/2012/05/31/2537105.html 看着国外网站的教程,写了一个小例子,一个联系人的程序,包括 ...
- xcode升级到6.0以后遇到的警告错误 原帖链接http://www.cocoachina.com/bbs/simple/?t112432.html
Xcode 升级后,常常遇到的遇到的警告.错误,解决方法 从sdk3.2.5升级到sdk 7.1中间废弃了很多的方法,还有一些逻辑关系更加严谨了.1,警告:“xoxoxoxo” is depreca ...
- 初识kbmmw 中的smartbind功能
关于kbmmw smartbind 的开发原因及思路,大家可以参见官方的博客说明和红鱼儿的翻译. 今天我就实例操作一下,给大家演示一下具体实现. 我们新建一个工程 放几个基本的控件 在单元里面加上引用 ...
- 清理yum 缓存
两条命令 yum clean all 以及 rm -rf /var/cache/yum/* 如何有效的清理yum缓存 - CSDN博客 https://blog.csdn.net/nsrainbow/ ...
- [eMMC]eMMC读写性能测试
读写速率(dd) https://www.shellhacks.com/disk-speed-test-read-write-hdd-ssd-perfomance-linux/ eMMC健康情况(mm ...
- CSU - 1530 Gold Rush —— 二进制
题目链接:http://acm.csu.edu.cn/csuoj/problemset/problem?pid=1530 对于一块2^n质量的gold.需要把它分成a质量和b质量(a+b=2^n),且 ...