TensorBoard计算加速
TensorBoard计算加速
0. 写在前面
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
工具
python3.5.1,pycharm
1. TensorFlow使用GPU
1. 如何使用log_device_placement参数来打印运行每一个运算的设备。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test1.py
@time: 2019/5/14 19:40
@desc: 如何使用log_device_placement参数来打印运行每一个运算的设备
"""
import tensorflow as tf
a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')
b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
c = a + b
# 通过log_device_placement参数来输出运行每一个运算的设备。
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
运行结果:
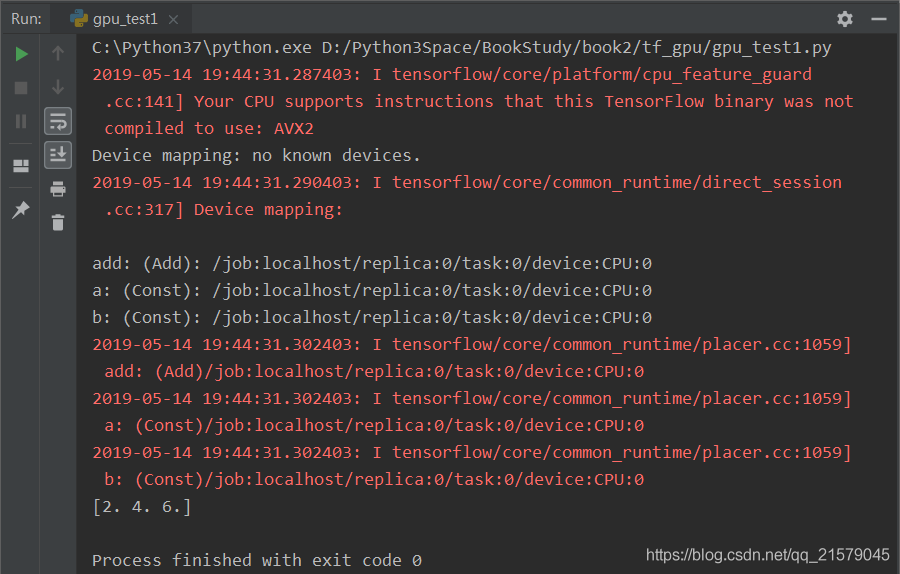
2. 通过tf.device手工指定运行设备的样例。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test2.py
@time: 2019/5/14 19:54
@desc: 通过tf.device手工指定运行设备的样例。
"""
import tensorflow as tf
# 通过tf.device将运行指定到特定的设备上。
with tf.device('/cpu:0'):
a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')
b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
with tf.device('/gpu:1'):
c = a + b
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
由于我并没有GPU,所以只是尬码代码。。。
3. 不是所有的操作都可以被放在GPU上,如果强行将无法放在GPU上的操作指定到GPU上,那么程序将会报错。
4. 为了避免这个问题,TensorFlow在生成会话时,可以指定allow_soft_placement参数,当这个参数为True时,如果运算无法由GPU执行,那么TensorFlow会自动将它放到CPU上执行。
2. 深度学习训练并行模式
- 常用的并行化深度学习模型训练方式有两种,同步模式和异步模式。
- 可以简单的认为异步模式就是单机模式复制了多份,每一份使用不同的训练数据进行训练。
- 在异步模式下,不同设备之间是完全独立的。
- 使用异步模式训练的深度学习模型有可能无法达到较优的训练结果。
- 在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。
- 总结来说就是,异步模式达到全局最优要难一些,但是速度快;同步模式更能达到全局最优,但墨迹。两者都有应用。
3. 多GPU并行
在多GPU上训练深度学习模型解决MNIST问题。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test3.py
@time: 2019/5/15 10:35
@desc: 在多GPU上训练深度学习模型解决MNIST问题。
"""
from datetime import datetime
import os
import time
import tensorflow as tf
import BookStudy.book2.mnist_inference as mnist_inference
# 定义训练神经网络时需要用到的模型。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.001
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 1000
MOVING_AVERAGE_DECAY = 0.99
N_GPU = 2
# 定义日志和模型输出的路径
MODEL_SAVE_PATH = 'logs_and_models/'
MODEL_NAME = 'model.ckpt'
# 定义数据存储的路径。因为需要为不同的GPU提供不同的训练数据,所以通过placeholder的方式
# 就需要手动准备多份数据。为了方便训练数据的获取过程,可以采用前面介绍的Dataset的方式从
# TFRecord中读取数据。于是在这里提供的数据文件路径为将MNIST训练数据转化为TFRecord格式
# 之后的路径。如何将MNIST数据转化为TFRecord格式在前面有详细介绍,这里不再赘述。
DATA_PATH = 'output.tfrecords'
# 定义输入队列得到的训练数据,具体细节可以参考前面。
def get_input():
dataset = tf.data.TFRecordDataset([DATA_PATH])
# 定义数据解析格式。
def parser(record):
features = tf.parse_single_example(
record,
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'pixels': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
}
)
# 解析图片和标签信息。
decoded_image = tf.decode_raw(features['image_raw'], tf.uint8)
reshaped_image = tf.reshape(decoded_image, [784])
retyped_image = tf.cast(reshaped_image, tf.float32)
label = tf.cast(features['label', tf.int32])
return retyped_image, label
# 定义输入队列
dataset = dataset.map(parser)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.repeat(10)
dataset = dataset.batch(BATCH_SIZE)
iterator = dataset.make_one_shot_iterator()
features, labels = iterator.get_next()
return features, labels
# 定义损失函数。对于给定的训练数据、正则化损失计算规则和命名空间,计算在这个命名空间下的总损失。
# 之所以需要给定命名空间就是因为不同的GPU上计算得出的正则化损失都会加入名为loss的集合,如果不
# 通过命名空间就会将不同GPU上的正则化损失都加进来。
def get_loss(x, y_, regularizer, scope, reuse_variables=None):
# 沿用前面定义的函数来计算神经网络的前向传播结果。
with tf.variable_scope(tf.get_variable_scope(), reuse=reuse_variables):
y = mnist_inference.inference(x, regularizer)
# 计算交叉熵损失。
cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=y_))
# 计算当前GPU上计算得到的正则化损失。
regularization_loss = tf.add_n(tf.get_collection('losses', scope))
# 计算最终的总损失。
loss = cross_entropy + regularization_loss
return loss
# 计算每一个变量梯度的平均值。
def average_gradients(tower_grads):
average_grads = []
# 枚举所有的变量和变量在不同GPU上计算得出的梯度。
for grad_and_vars in zip(*tower_grads):
# 计算所有GPU上的梯度平均值
grads = []
for g, _ in grad_and_vars:
expanded_g = tf.expand_dims(g, 0)
grads.append(expanded_g)
grad = tf.concat(grads, 0)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
# 将变量和它的平均梯度对应起来。
average_grads.append(grad_and_var)
# 返回所有变量的平均梯度,这个将被用于变量的更新。
return average_grads
# 主训练过程。
def main(argv=None):
# 将简单的运算放在CPU上,只有神经网络的训练过程在GPU上。
with tf.Graph().as_default(), tf.device('/cpu:0'):
# 定义基本的训练过程
x, y_ = get_input()
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
global_step = tf.get_variable('global_step', [], initializer=tf.constant_initializer(0), trainable=False)
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, 60000/BATCH_SIZE, LEARNING_RATE_DECAY)
opt = tf.train.GradientDescentOptimizer(learning_rate)
tower_grads = []
reuse_variables = False
# 将神经网络的优化过程跑在不同的GPU上。
for i in range(N_GPU):
# 将优化过程指定在一个GPU上
with tf.device('/gpu:%d' % i):
with tf.name_scope('GPU_%d' % i) as scope:
cur_loss = get_loss(x, y_, regularizer, scope, reuse_variables)
# 在第一次声明变量之后,将控制变量重用的参数设置为True。这样可以让不同的GPU更新同一组参数
reuse_variables = True
grads = opt.compute_gradients(cur_loss)
tower_grads.append(grads)
# 计算变量的平均梯度
grads = average_gradients(tower_grads)
for grad, var in grads:
if grad is not None:
tf.summary.histogram('gradients_on_average/%s' % var.op.name, grad)
# 使用平均梯度更新参数。
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
for var in tf.trainable_variables():
tf.summary.histogram(var.op.name, var)
# 计算变量的滑动平均值。
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_to_average = (tf.trainable_variables() + tf.moving_average_variables())
variable_averages_op = variable_averages.apply(variable_to_average)
# 每一轮迭代需要更新变量的取值并更新变量的滑动平均值
train_op = tf.group(apply_gradient_op, variable_averages_op)
saver = tf.train.Saver()
summary_op = tf.summary.merge_all()
init = tf.global_variables_initializer()
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)) as sess:
# 初始化所有变量并启动队列。
init.run()
summary_writer = tf.summary.FileWriter(MODEL_SAVE_PATH, sess.graph)
for step in range(TRAINING_STEPS):
# 执行神经网络训练操作,并记录训练操作的运行时间。
start_time = time.time()
_, loss_value = sess.run([train_op, cur_loss])
duration = time.time() - start_time
# 每隔一段时间输出当前的训练进度,并统计训练速度
if step != 0 and step % 10 == 0:
# 计算使用过的训练数据个数。因为在每一次运行训练操作时,每一个GPU都会使用一个batch的训练数据,
# 所以总共用到的训练数据个数为batch大小 X GPU个数。
num_examples_per_step = BATCH_SIZE * N_GPU
# num_example_per_step为本次迭代使用到的训练数据个数,duration为运行当前训练过程使用的时间,
# 于是平均每秒可以处理的训练数据个数为num_examples_per_step / duration
examples_per_sec = num_examples_per_step / duration
# duration为运行当前训练过程使用的时间,因为在每一个训练过程中,每一个GPU都会使用一个batch的
# 训练数据,所以在单个batch上的训练所需要的时间为duration / GPU个数
sec_per_batch = duration / N_GPU
# 输出训练信息。
format_str = '%s: step %d, loss = %.2f (%.1f examples/sec; %.3f sec/batch)'
print(format_str % (datetime.now(), step, loss_value, examples_per_sec, sec_per_batch))
# 通过TensorBoard可视化训练过程。
summary = sess.run(summary_op)
summary_writer.add_summary(summary, step)
# 每隔一段时间保存当前的模型。
if step % 1000 == 0 or (step + 1) == TRAINING_STEPS:
checkpoint_path = os.path.join(MODEL_SAVE_PATH, MODEL_NAME)
saver.save(sess, checkpoint_path, global_step=step)
if __name__ == '__main__':
tf.app.run()
由于我依然没有GPU,所以只是尬码代码。。。
4. 分布式TensorFlow
4.1 分布式TensorFlow原理
- 创建一个最简单的TensorFlow集群。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test4.py
@time: 2019/5/15 22:19
@desc: 创建一个最简单的TensorFlow集群
"""
import tensorflow as tf
c = tf.constant("Hello, distributed TensorFlow!")
# 创建一个本地的TensorFlow集群
server = tf.train.Server.create_local_server()
# 在集群上创建一个会话。
sess = tf.Session(server.target)
# 输出Hello,distributed TensorFlow!
print(sess.run(c))
输出得到:
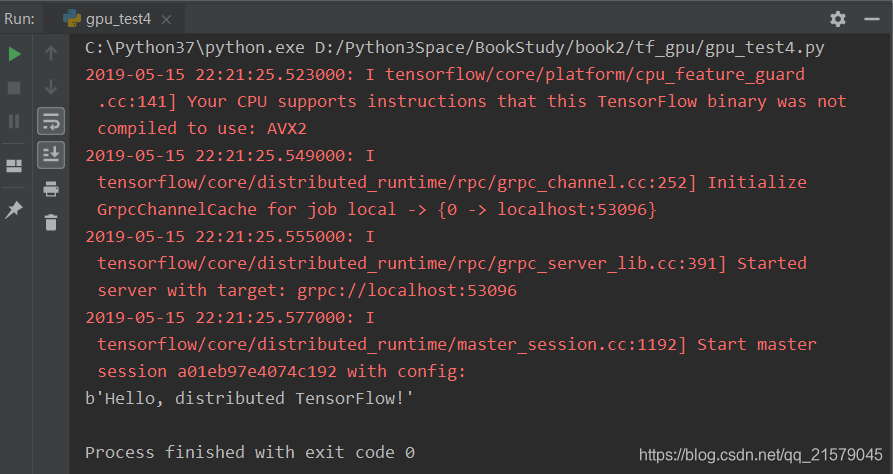
- 在本地运行有两个任务的TensorFlow集群。
第一个任务代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test5.py
@time: 2019/5/15 22:27
@desc: 在本地运行有两个任务的TensorFlow集群。第一个任务的代码。
"""
import tensorflow as tf
c = tf.constant("Hello from server1!")
# 生成一个有两个任务的集群,一个任务跑在本地2222端口,另外一个跑在本地2223端口。
cluster = tf.train.ClusterSpec({"local": ["localhost: 2222", "localhost: 2223"]})
# 通过上面生成的集群配置生成Server,并通过job_name和task_index指定当前所启动的任务。
# 因为该任务是第一个任务,所以task_index为0.
server = tf.train.Server(cluster, job_name="local", task_index=0)
# 通过server.target生成会话来使用TensorFlow集群中的资源。通过设置
# log_device_placement可以看到执行每一个操作的任务。
sess = tf.Session(server.target, config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
server.join()
第二个任务代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test6.py
@time: 2019/5/16 10:14
@desc: 在本地运行有两个任务的TensorFlow集群。第二个任务的代码。
"""
import tensorflow as tf
c = tf.constant("Hello from server2!")
# 和第一个程序一样的集群配置。集群中的每一个任务需要采用相同的配置。
cluster = tf.train.ClusterSpec({"local": ["localhost: 2222", "localhost: 2223"]})
# 指定task_index为1,所以这个程序将在localhost: 2223启动服务。
server = tf.train.Server(cluster, job_name="local", task_index=1)
# 剩下的代码都和第一个任务的代码一致。
# 通过server.target生成会话来使用TensorFlow集群中的资源。通过设置
# log_device_placement可以看到执行每一个操作的任务。
sess = tf.Session(server.target, config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
server.join()
启动第一个任务后,可以得到类似下面的输出:
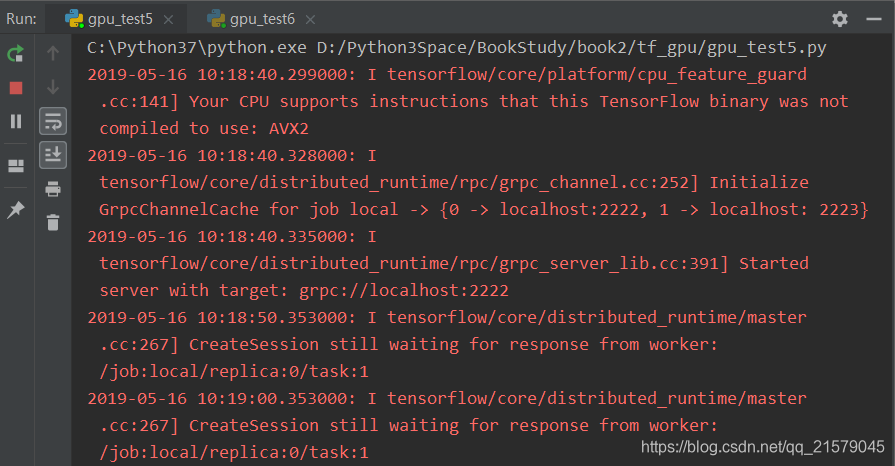
从第一个任务的输出中可以看到,当只启动第一个任务时,程序会停下来等待第二个任务启动。当第二个任务启动后,可以得到如下输出:
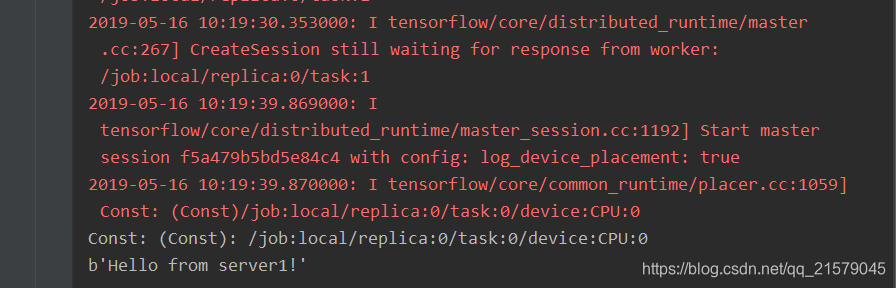
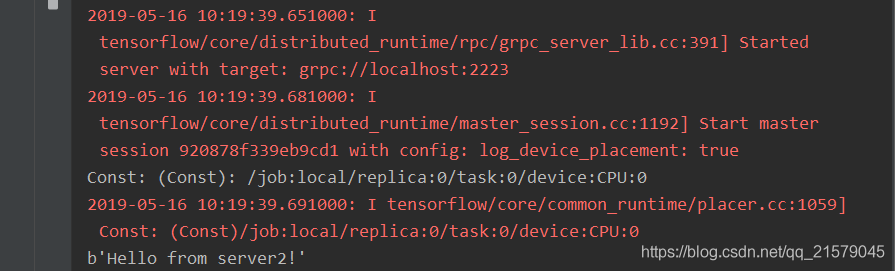
值得注意的是:第二个任务中定义的计算也被放在了同一个设备上,也就是说这个计算将由第一个任务来执行。
使用分布式TensorFlow训练深度学习模型一般有两种方式:
- 一种方式叫做计算图内分布式(in-graph replication)。优点:同步更新参数比较容易控制。缺点:当数据量太大时,中心节点容易造成性能瓶颈。
- 另外一种叫做计算图之间分布式(between-graph replication)。优点:并行程度更高。缺点:同步更新困难。
4.2 分布式TensorFlow模型训练
异步模式样例程序
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test7.py
@time: 2019/5/16 14:01
@desc: 实现异步模式的分布式神经网络训练过程。
"""
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
# 配置神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.001
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 20000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径。
MODEL_SAVE_PATH = "./log1"
# MNIST数据路径。
DATA_PATH = "D:/Python3Space/BookStudy/book2/MNIST_data"
# 通过flags指定运行的参数。在前面对于不同的任务(task)给出了不同的程序。
# 但这不是一种可扩展的方式。在这一节中将使用运行程序时给出的参数来配置在
# 不同任务中运行的程序。
FLAGS = tf.app.flags.FLAGS
# 指定当前运行的是参数服务器还是计算服务器。参数服务器只负责TensorFlow中变量的维护
# 和管理,计算服务器负责每一轮迭代时运行反向传播过程。
tf.app.flags.DEFINE_string('job_name', 'worker', ' "ps" or "worker" ')
# 指定集群中的参数服务器地址。
tf.app.flags.DEFINE_string(
'ps_hosts', ' tf-ps0:2222,tf-ps1:1111',
'Comma-separated list of hostname:port for the parameter server jobs.'
' e.g. "tf-ps0:2222,tf-ps1:1111" '
)
# 指定集群中的计算服务器地址。
tf.app.flags.DEFINE_string(
'worker_hosts', ' tf-worker0:2222, tf-worker1:1111',
'Comma-separated list of hostname:port for the worker jobs. '
'e.g. "tf-worker0:2222,tf-worker1:1111" '
)
# 指定当前程序的任务ID。TensorFlow会自动根据参数服务器/计算服务器列表中的端口号来启动服务。
# 注意参数服务器和计算服务器的编号都是从0开始的。
tf.app.flags.DEFINE_integer(
'task_id', 0, 'Task ID of the worker/replica running the training.'
)
# 定义TensorFlow的计算图,并返回每一轮迭代时需要运行的操作。这个过程和前面的主函数基本一致,
# 但为了使处理分布式计算的部分更加突出,这里将此过程整理为一个函数。
def build_model(x, y_, is_chief):
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
# 通过前面给出的mnist_inference计算神经网络前向传播的结果。
y = mnist_inference.inference(x, regularizer)
global_step = tf.train.get_or_create_global_step()
# 计算损失函数并定义反向传播的过程。
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
60000 / BATCH_SIZE,
LEARNING_RATE_DECAY
)
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 定义每一轮迭代需要运行的操作。
if is_chief:
# 计算变量的滑动平均值。
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([variable_averages_op, train_op]):
train_op = tf.no_op()
return global_step, loss, train_op
def main(argv=None):
# 解析flags并通过tf.train.ClusterSpe配置TensorFlow集群。
ps_hosts = FLAGS.ps_hosts.split(',')
worker_hosts = FLAGS.worker_hosts.split(',')
cluster = tf.train.ClusterSpec({'ps': ps_hosts, 'worker': worker_hosts})
# 通过tf.train.ClusterSpec以及当前任务创建tf.train.Server。
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_id)
# 参数服务器只需要管理TensorFlow中的变量,不需要执行训练的过程。server.join()会一直停在这条语句上。
if FLAGS.job_name == 'ps':
with tf.device("/cpu:0"):
server.join()
# 定义计算服务器需要运行的操作。
is_chief = (FLAGS.task_id == 0)
mnist = input_data.read_data_sets(DATA_PATH, one_hot=True)
# 通过tf.train.replica_device_setter函数来指定执行每一个运算的设备。
# tf.train.replica_device_setter函数会自动将所有的参数分配到参数服务器上,将
# 计算分配到当前的计算服务器上。
device_setter = tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_id,
cluster=cluster
)
with tf.device(device_setter):
# 定义输入并得到每一轮迭代需要运行的操作。
x = tf.placeholder(
tf.float32,
[None, mnist_inference.INPUT_NODE],
name='x-input'
)
y_ = tf.placeholder(
tf.float32,
[None, mnist_inference.OUTPUT_NODE],
name='y-input'
)
global_step, loss, train_op = build_model(x, y_, is_chief)
hooks = [tf.train.StopAtStepHook(last_step=TRAINING_STEPS)]
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
# 通过tf.train.MonitoredTrainingSession管理训练深度学习模型的通用功能。
with tf.train.MonitoredTrainingSession(
master=server.target,
is_chief=is_chief,
checkpoint_dir=MODEL_SAVE_PATH,
hooks=hooks,
save_checkpoint_secs=60,
config=sess_config
) as mon_sess:
print("session started.")
step = 0
start_time = time.time()
# 执行迭代过程。在迭代过程中tf.train.MonitoredTrainingSession会帮助完成初始化、
# 从checkpoint中加载训练过的模型、输出日志并保存模型,所以以下程序中不需要再调用
# 这些过程。tf.train.StopAtStepHook会帮忙判断是否需要退出。
while not mon_sess.should_stop():
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, global_step_value = mon_sess.run(
[train_op, loss, global_step],
feed_dict={x: xs, y_: ys}
)
# 每隔一段时间输出训练信息,不同的计算服务器都会更新全局的训练轮数,
# 所以这里使用global_step_value得到在训练中使用过的batch的总数。
if step > 0 and step % 100 == 0:
duration = time.time() - start_time
sec_per_batch = duration / global_step_value
format_str = "After %d training steps (%d global steps), loss on training batch is %g. (%.3f sec/batch)"
print(format_str % (step, global_step_value, loss_value, sec_per_batch))
step += 1
if __name__ == '__main__':
try:
tf.app.run()
except Exception as e:
print(e)
要启动一个拥有一个参数服务器、两个计算服务器的集群,需要现在运行参数服务器的机器上启动以下命令。
python gpu_test7.py --job_name=ps --task_id=0 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224
然后再运行第一个计算服务器的机器上启动以下命令:
python gpu_test7.py --job_name=worker --task_id=0 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224
最后再运行第二个计算服务器的机器上启动以下命令:
python gpu_test7.py --job_name=worker --task_id=1 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224
注意:如果你报错了:
1. UnknownError: Could not start gRPC server
一定是你的参数问题!检查你的task_id有没有写成taske_id等等,类似的,一定是这样!!!一定要跟程序中的参数名保持一致!!!
2. 跑的过程中python搞不清楚崩了,两个计算服务器都会崩,跟时间无关,随机的那种。。。直接弹出python已停止的那种
听我的换台电脑或者重装系统。
3. 报错‘ps’不存在的,没定义的注意了!
在cmd(windows系统)中启动上面三个命令的时候,参数的内容不要加引号!!!书上面加引号真的是坑死了好吗!
我就是解决了上述三个问题,换了台macbook,才总算功德圆满了跑出了结果。
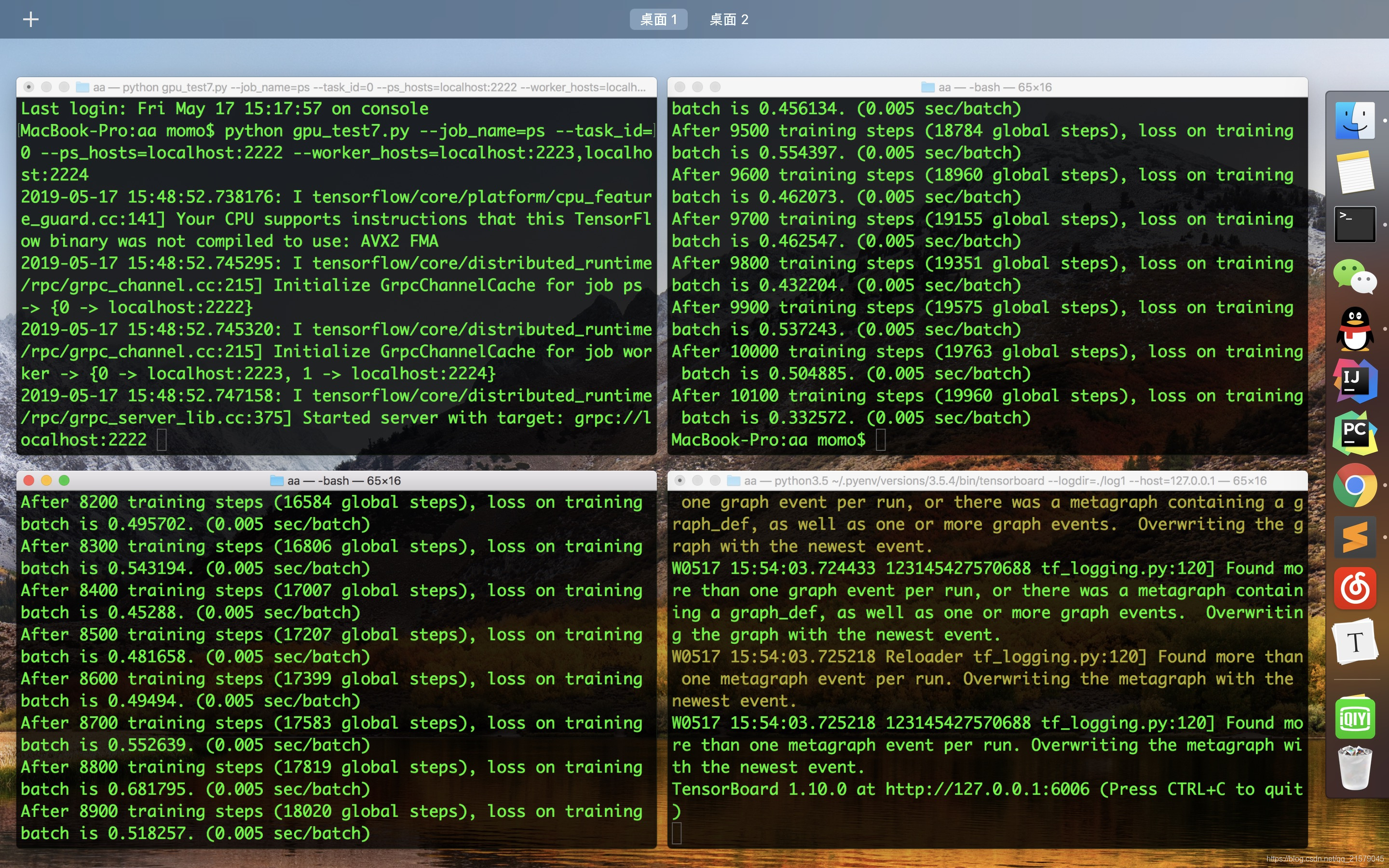
左上:参数服务器
右上:计算服务器0
左下:计算服务器1
右下:运行tensorboard,结果如下:
同步模式样例程序
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test8.py
@time: 2019/5/17 13:52
@desc: 实现同步模式的分布式神经网络训练过程。
"""
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
# 配置神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.001
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 20000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径。
MODEL_SAVE_PATH = "./log2"
# MNIST数据路径。
DATA_PATH = "D:/Python3Space/BookStudy/book2/MNIST_data"
# 和异步模式类似的设置flags。
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('job_name', 'worker', ' "ps" or "worker" ')
tf.app.flags.DEFINE_string(
'ps_hosts', ' tf-ps0:2222, tf-ps1:1111',
'Comma-separated list of hostname:port for the parameter server jobs.'
' e.g. "tf-ps0:2222,tf-ps1:1111" '
)
tf.app.flags.DEFINE_string(
'worker_hosts', ' tf-worker0:2222, tf-worker1:1111',
'Comma-separated list of hostname:port for the worker jobs. '
'e.g. "tf-worker0:2222,tf-worker1:1111" '
)
tf.app.flags.DEFINE_integer(
'task_id', 0, 'Task ID of the worker/replica running the training.'
)
# 和异步模式类似的定义TensorFlow的计算图。唯一的区别在于使用。
# tf.train.SyncReplicasOptimizer函数处理同步更新。
def build_model(x, y_, n_workers, is_chief):
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.train.get_or_create_global_step()
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
60000 / BATCH_SIZE,
LEARNING_RATE_DECAY
)
# 通过tf.train.SyncReplicasOptimizer函数实现同步更新。
opt = tf.train.SyncReplicasOptimizer(
tf.train.GradientDescentOptimizer(learning_rate),
replicas_to_aggregate=n_workers,
total_num_replicas=n_workers
)
sync_replicas_hook = opt.make_session_run_hook(is_chief)
train_op = opt.minimize(loss, global_step=global_step)
if is_chief:
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([variable_averages_op, train_op]):
train_op = tf.no_op()
return global_step, loss, train_op, sync_replicas_hook
def main(argv=None):
# 和异步模式类似地创建TensorFlow集群。
ps_hosts = FLAGS.ps_hosts.split(',')
worker_hosts = FLAGS.worker_hosts.split(',')
n_workers = len(worker_hosts)
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_id)
if FLAGS.job_name == 'ps':
with tf.device("/cpu:0"):
server.join()
is_chief = (FLAGS.task_id == 0)
mnist = input_data.read_data_sets(DATA_PATH, one_hot=True)
device_setter = tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_id,
cluster=cluster
)
with tf.device(device_setter):
# 定义输入并得到每一轮迭代需要运行的操作。
x = tf.placeholder(
tf.float32,
[None, mnist_inference.INPUT_NODE],
name='x-input'
)
y_ = tf.placeholder(
tf.float32,
[None, mnist_inference.OUTPUT_NODE],
name='y-input'
)
global_step, loss, train_op, sync_replicas_hook = build_model(x, y_, n_workers, is_chief)
# 把处理同步更新的hook也加进来
hooks = [sync_replicas_hook, tf.train.StopAtStepHook(last_step=TRAINING_STEPS)]
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
# 训练过程和异步一致。
with tf.train.MonitoredTrainingSession(
master=server.target,
is_chief=is_chief,
checkpoint_dir=MODEL_SAVE_PATH,
hooks=hooks,
save_checkpoint_secs=60,
config=sess_config
) as mon_sess:
print("session started.")
step = 0
start_time = time.time()
while not mon_sess.should_stop():
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, global_step_value = mon_sess.run(
[train_op, loss, global_step],
feed_dict={x: xs, y_: ys}
)
if step > 0 and step % 100 == 0:
duration = time.time() - start_time
sec_per_batch = duration / global_step_value
format_str = "After %d training steps (%d global steps), loss on training batch is %g. (%.3f sec/batch)"
print(format_str % (step, global_step_value, loss_value, sec_per_batch))
step += 1
if __name__ == '__main__':
tf.app.run()
同上运行出来得到:
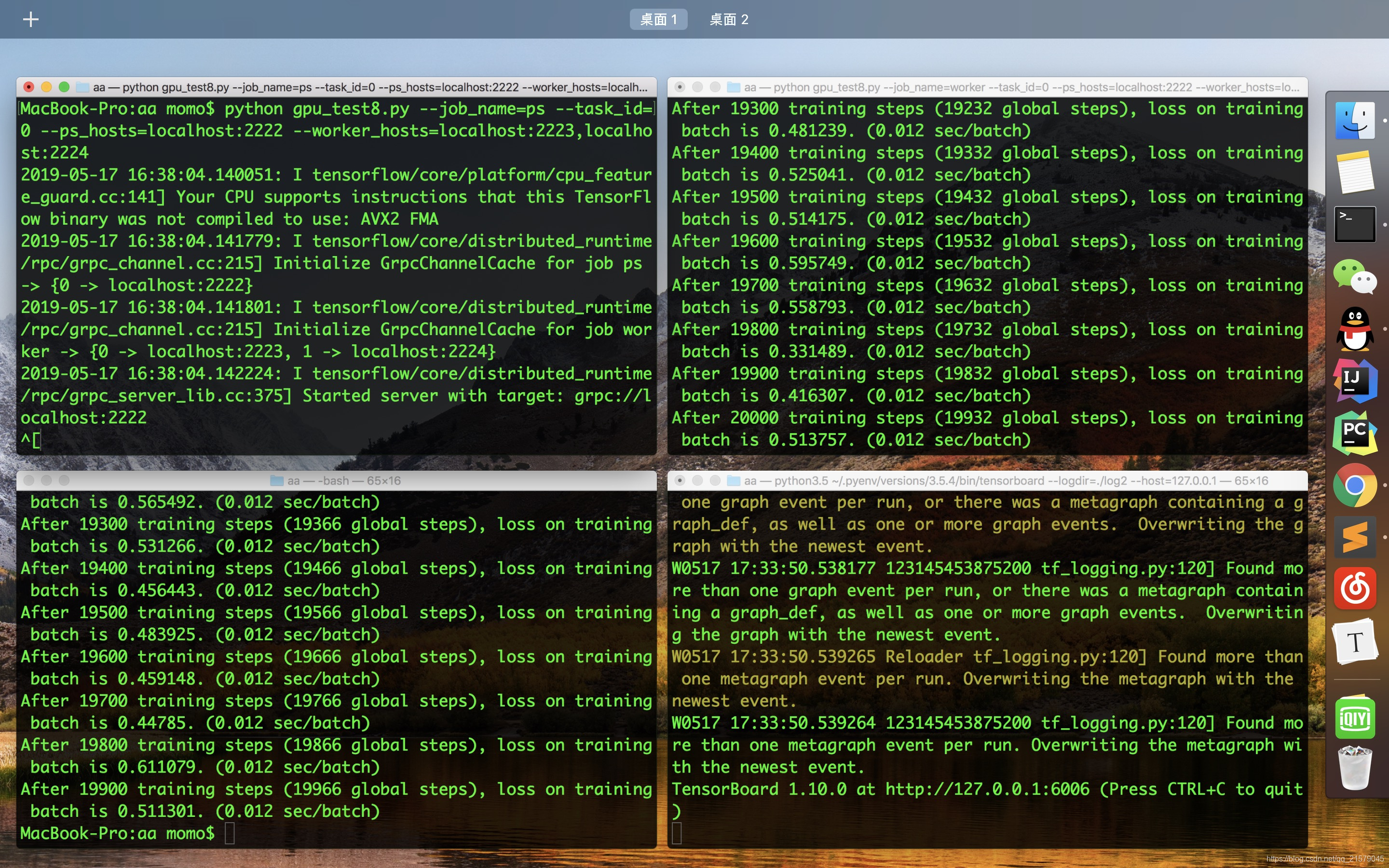
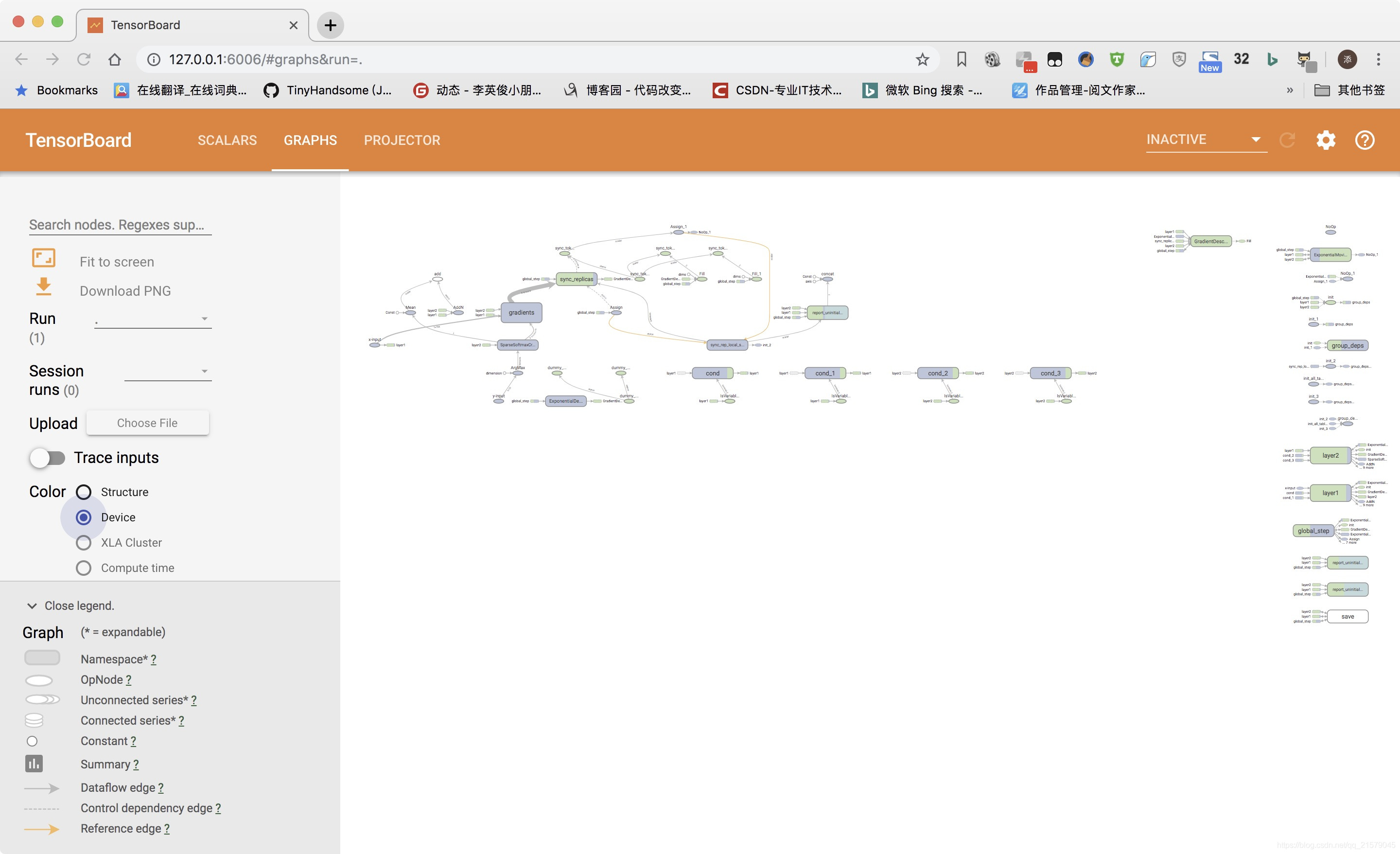
和异步模式不同,在同步模式下,global_step差不多是两个计算服务器local_step的平均值。比如在第二个计算服务器还没有开始之前,global_step是第一个服务器local_step的一般。这是因为同步模式要求收集replicas_to_average份梯度才会开始更新(注意这里TensorFlow不要求每一份梯度来自不同的计算服务器)。同步模式不仅仅是一次使用多份梯度,tf.train.SyncReplicasOptimizer的实现同时也保证了不会出现陈旧变量的问题,该函数会记录每一份梯度是不是由最新的变量值计算得到的,如果不是,那么这一份梯度将会被丢弃。
5. 写在最后
总算是把这本书一步一步的实现,一步一步的修改,从头认认真真的刷了一遍。取其精华,弃其糟粕。学习TensorFlow真的是一件不容易,也是一件很有成就感的过程。还有黑皮书《TensorFlow实战》和圣经花书《深度学习》要学,希望后面的书不会让我失望吧。
我的CSDN:https://blog.csdn.net/qq_21579045
我的博客园:https://www.cnblogs.com/lyjun/
我的Github:https://github.com/TinyHandsome
纸上得来终觉浅,绝知此事要躬行~
欢迎大家过来OB~
by 李英俊小朋友
TensorBoard计算加速的更多相关文章
- 学习笔记TF067:TensorFlow Serving、Flod、计算加速,机器学习评测体系,公开数据集
TensorFlow Serving https://tensorflow.github.io/serving/ . 生产环境灵活.高性能机器学习模型服务系统.适合基于实际数据大规模运行,产生多个模型 ...
- 云知声 Atlas 超算平台: 基于 Fluid + Alluxio 的计算加速实践
Fluid 是云原生基金会 CNCF 下的云原生数据编排和加速项目,由南京大学.阿里云及 Alluxio 社区联合发起并开源.本文主要介绍云知声 Atlas 超算平台基于 Fluid + Alluxi ...
- TensorFlow学习笔记(七)TesnorFlow实现计算加速
目录: 一.TensorFlow使用GPU 二.深度学习训练与并行模式 三.多GPU并行 四.分布式TensorFlow 4.1分布式TensorFlow的原理 4.2分布式TensorFlow模型训 ...
- Tensorflow计算加速
在tensorflow里可以通过tf.device函数来指定每个运行的设备,可以是GPU也可以是CPU,比如CPU在tensorflow里的名称为/cpu:0,即便电脑里有多个CPU,tensorfl ...
- neuFlow&CNP-卷积计算加速器&神经网络加速芯片生态系统
上周看到韩松毕业论文,扯出神经网络加速器EIE,刚好这周调研了一下neuFlow,扯出09年的一篇做卷积加速的文章,大牛Lecun Yan的学生做的,一晃眼,快十年了.也记录之. 这一套还没研究透,又 ...
- Desktop Ubuntu 14.04LTS/16.04科学计算环境配置
Desktop Ubuntu 14.04LTS/16.04科学计算环境配置 计算机硬件配置 cpu i5 6代 内存容量 8G gpu GTX960 显存容量 2G(建议显存在4G以上,否则一些稍具规 ...
- 应用AI芯片加速 Hadoop 3.0 纠删码的计算性能
本文由云+社区发表 做为大数据生态系统中最重要的底层存储文件系统HDFS,为了保证系统的可靠性,HDFS通过多副本的冗余来防止数据的丢失.通常,HDFS中每一份数据都设置两个副本,这也使得存储利用率仅 ...
- CNN 模型压缩与加速算法综述
本文由云+社区发表 导语:卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,CNN模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一. 前言 自从AlexNet一举夺得 ...
- Intel DAAL AI加速——支持从数据预处理到模型预测,数据源必须使用DAAL的底层封装库
数据源加速见官方文档(必须使用DAAL自己的库): Data Management Numeric Tables Tensors Data Sources Data Dictionaries Data ...
随机推荐
- Delphi编写WebService体会
源:Delphi编写WebService体会 Dispatch: 派遣,分派 Invoke: 调用 Invokable: 可调用接口 TReomtable: WebService中自定义类都是继承自该 ...
- 51Nod 1515 明辨是非 —— 并查集 + 启发式合并
题目链接:http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1515 1515 明辨是非 题目来源: 原创 基准时间限制:1 ...
- TopCoder SRM420 Div1 RedIsGood —— 期望
题目链接:https://vjudge.net/problem/TopCoder-9915 (论文上的题) 题解: 更正:, i>0, j>0 代码如下: #include <ios ...
- linux下安装svn服务
环境centos6.8 64位: 1.安装svn yum install subversion yum install mod_dav_svn 2.创建svn仓库 mkdie /home/svn 3. ...
- 尚学堂xml学习笔记
1.打开eclipse,文件-新建java project,输入文件的名字,比如输入20181112. 2.对着src右键,选择new-file,输入文件名字,比如:book.xml. 3.开始写.x ...
- BZOJ 1629 [Usaco2005 Nov]Cow Acrobats:贪心【局部证明】
题目链接:http://begin.lydsy.com/JudgeOnline/problem.php?id=1332 题意: 有n头牛在“叠罗汉”. 第i头牛的体重为w[i],力量为s[i]. 一头 ...
- Java 并发 —— Java 标准库对并发的支持及 java.util.concurrent 包
0. Collections.synchronizedXxx() Java 中常用的集合框架中的实现类:HashSet/TreeSet.ArrayList/LinkedList.HashMap/Tre ...
- python 案例之老王开枪
- Ubuntu Java环境变量配置
# java homeJAVA_HOME=/usr/local/jdk/jdk1.8.0_121JRE_HOME=JAVA_HOME/jreCLASSPATH=.:$JAVA_HOME/lib:$JR ...
- Polygon
用当前的笔绘制一个由两个或多个点(顶点)连接的多边形. BOOL Polygon( LPPOINT lpPoints, int nCount ); lpPoints 指向一个指定多边形顶点的点.数组中 ...